論文:《YOLO-World: Real-Time Open-Vocabulary Object Detection》
代碼:https://github.com/AILab-CVC/YOLO-World
1.Abstract
我們介紹了YOLO World,這是一種創新的方法,通過在大規模數據集上進行視覺語言建模和預訓練,增強YOLO的開放詞匯檢測能力。具體而言,我們提出了一種新的可重新參數化的視覺-語言路徑聚合網絡(RepVL-PAN)和區域文本對比損失,以促進視覺和語言信息之間的交互。我們的方法可以以zero-shot方式高效檢測各種物體。
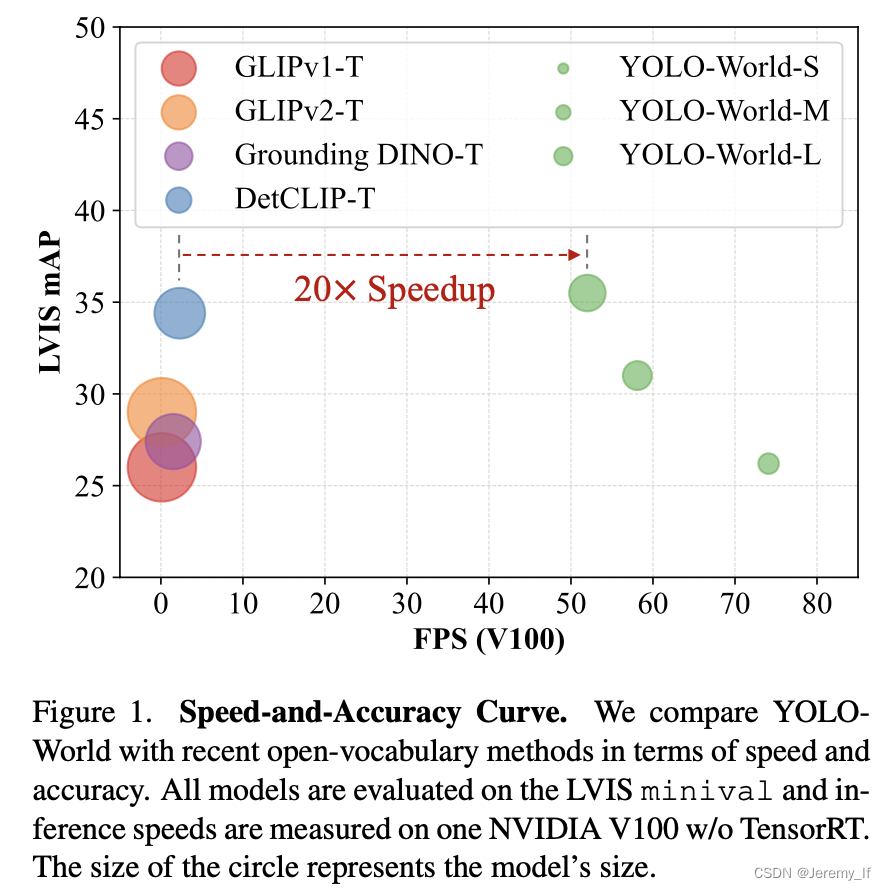
YOLO World遵循標準YOLO架構[20],并利用預先訓練的CLIP[39]文本編碼器對輸入文本進行編碼。我們進一步提出了可重新參數化的視覺語言路徑聚合網絡(RepVL-PAN)來連接文本特征和圖像特征,以獲得更好的視覺語義表示。在推理過程中,可以移除文本編碼器,并將文本嵌入重新參數化為RepVL PAN的權重,以實現高效部署。對于實際應用,一旦我們訓練了檢測器,即YOLO World,我們就可以對提示或類別進行預編碼,以構建離線詞匯表,然后將其無縫集成到檢測器中。

2.Related Work
傳統的目標檢測方法可以簡單地分為三類,即基于區域region-based的方法、基于像素pixel-based的方法和基于查詢query-based的方法。
3. Method
3.1. Pre-training Formulation: Region-Text Pairs
傳統的對象檢測方法,包括YOLO系列[20],使用實例注釋Ω={Bi,ci}Ni=1,其由邊界框{Bi}和類別標簽{ci}組成。在本文中,我們將實例注釋重新表述為區域-文本對Ω={Bi,ti}Ni=1,其中ti是區域Bi的對應文本。具體而言,**文本ti可以是類別名稱、名詞短語或對象描述。**此外,YOLO World采用圖像I和文本T(一組名詞)作為輸入和輸出預測框{B?k}和相應的對象嵌入{ek}(ek∈RD)。
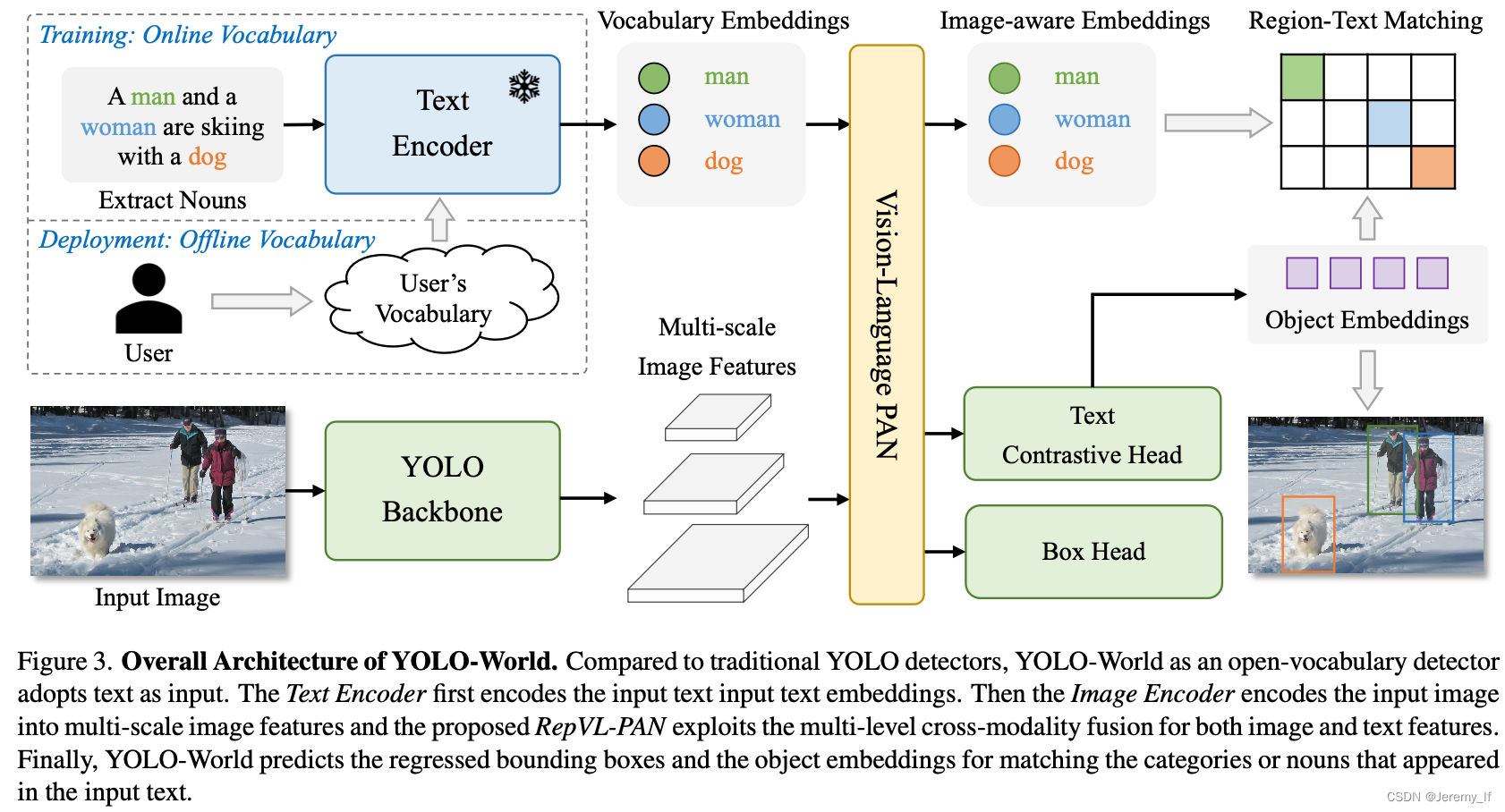
所提出的YOLO World的總體架構如圖所示。3,它由YOLO檢測器、文本編碼器和可重新參數化的視覺語言路徑聚合網絡(RepVL PAN)組成。給定輸入文本,YOLO World中的文本編碼器將文本編碼為文本嵌入。YOLO檢測器中的圖像編碼器從輸入圖像中提取多尺度特征。然后,我們利用RepVL PAN,通過利用圖像特征和文本嵌入之間的跨模態融合來增強文本和圖像表示。
YOLO Detector。YOLO World主要基于YOLOv8[20]開發,其中包含作為圖像編碼器的Darknet backbone[20,43]、用于多尺度特征金字塔的路徑聚合網絡(PAN)以及用于邊界框回歸和object embeddings的head。
Text-Enocder。給定文本T,我們采用CLIP[39]預先訓練的Transformer文本編碼器來提取相應的文本嵌入W=TextEncoder(T)∈RC×D,其中C是名詞的數量,D是embeding維數。與純文本語言編碼器相比,CLIP文本編碼器提供了更好的視覺語義功能,可以將視覺對象與文本連接起來[5]。當輸入的文本是描述或引用表達式時,我們采用簡單的n-gram算法提取名詞短語,然后將其輸入到文本編碼器中。
3.3. Re-parameterizable Vision-Language PAN
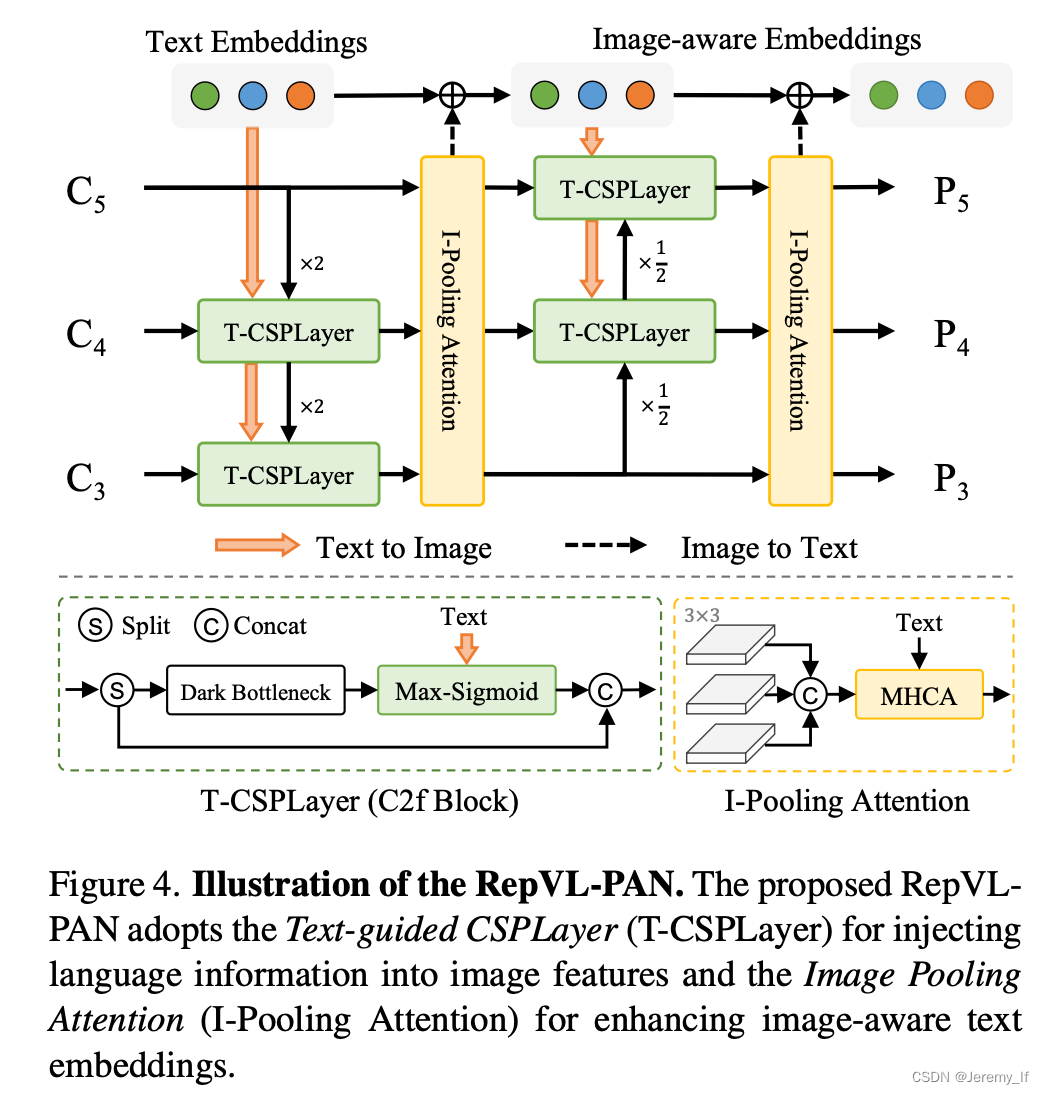
Text-guided CSPLayer. 如圖4所示,跨階段部分層(CSPLayer)是在自上而下或自下而上的融合之后使用的。我們通過將文本引導合并到多尺度圖像特征中來擴展[20]的CSPLayer(也稱為C2f),以形成文本引導的CSPLyer。具體地說,給定文本嵌入W和圖像特征Xl∈RH×W×D(l∈{3,4,5}),我們在最后一個bottleneck之后采用max-sigmoid attention將文本特征聚合為圖像特征: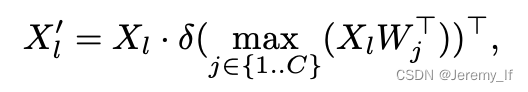
Image-Pooling Attention。為了增強具有圖像感知信息的文本嵌入,我們通過提出圖像池注意來聚合圖像特征以更新文本嵌入。我們不是直接在圖像特征上使用交叉注意力,而是利用多尺度特征上的最大池化來獲得3×3個區域,從而產生總共27個補丁標記X∈R27×D。然后通過以下方式更新文本嵌入:W ′ = W + MultiHead-Attention(W, X ?, X ?)
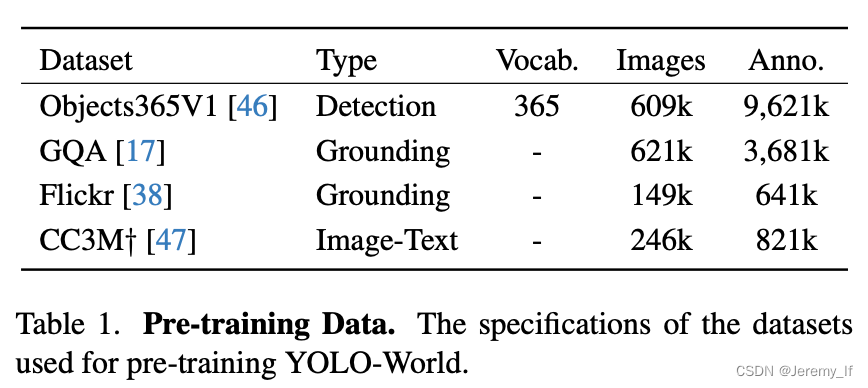
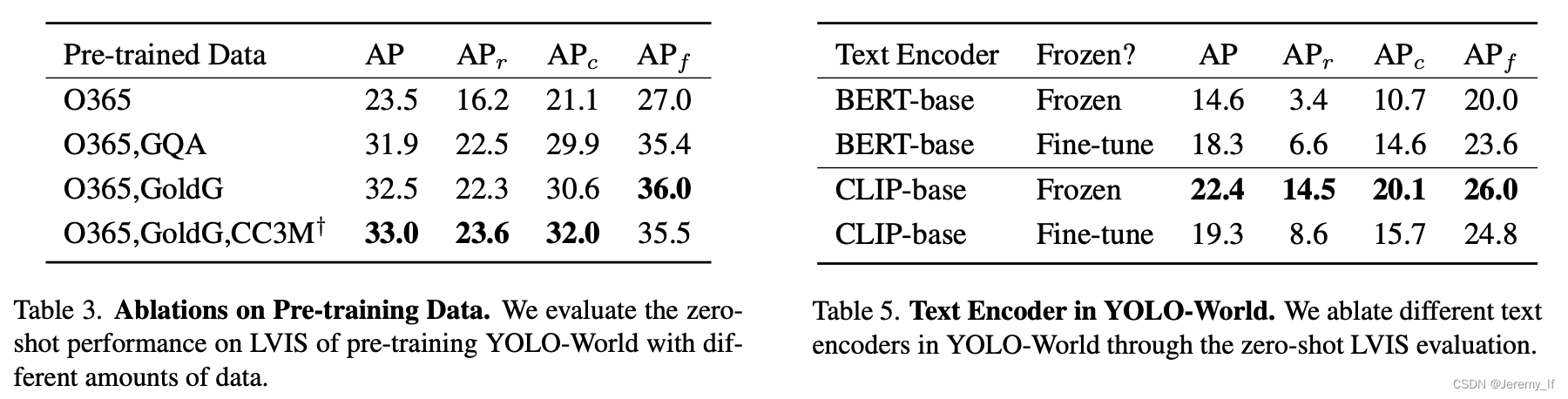
Pre-training data。對于預訓練YOLO-World,我們主要采用檢測或grounding數據集,包括Ob-Projects365(V1)[46]、GQA[17]、Flickr30k[38],如表1所示。根據[24],我們從GoldG[21](GQA和Flickr30k)中的COCO數據集中排除圖像。用于預訓練的檢測數據集的注釋包含邊界框和類別或名詞短語。此外,我們還用圖像-文本對擴展了預訓練數據,即CC3M?[47],我們已經通過第3.4節中討論的偽標記方法標記了246k個圖像。
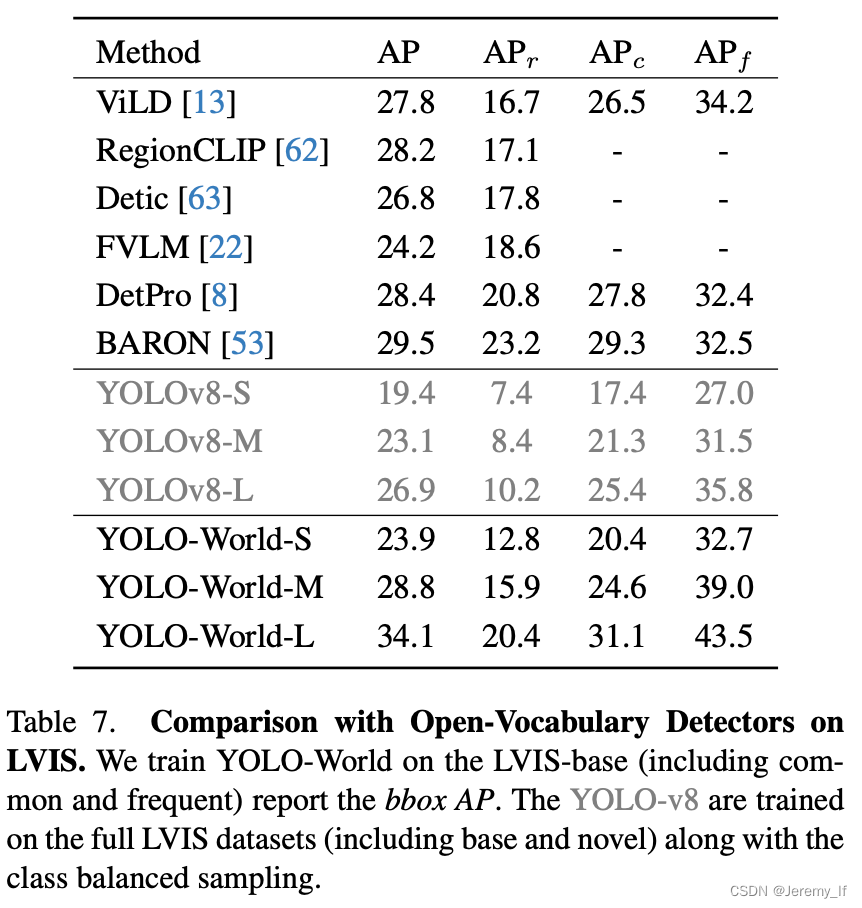
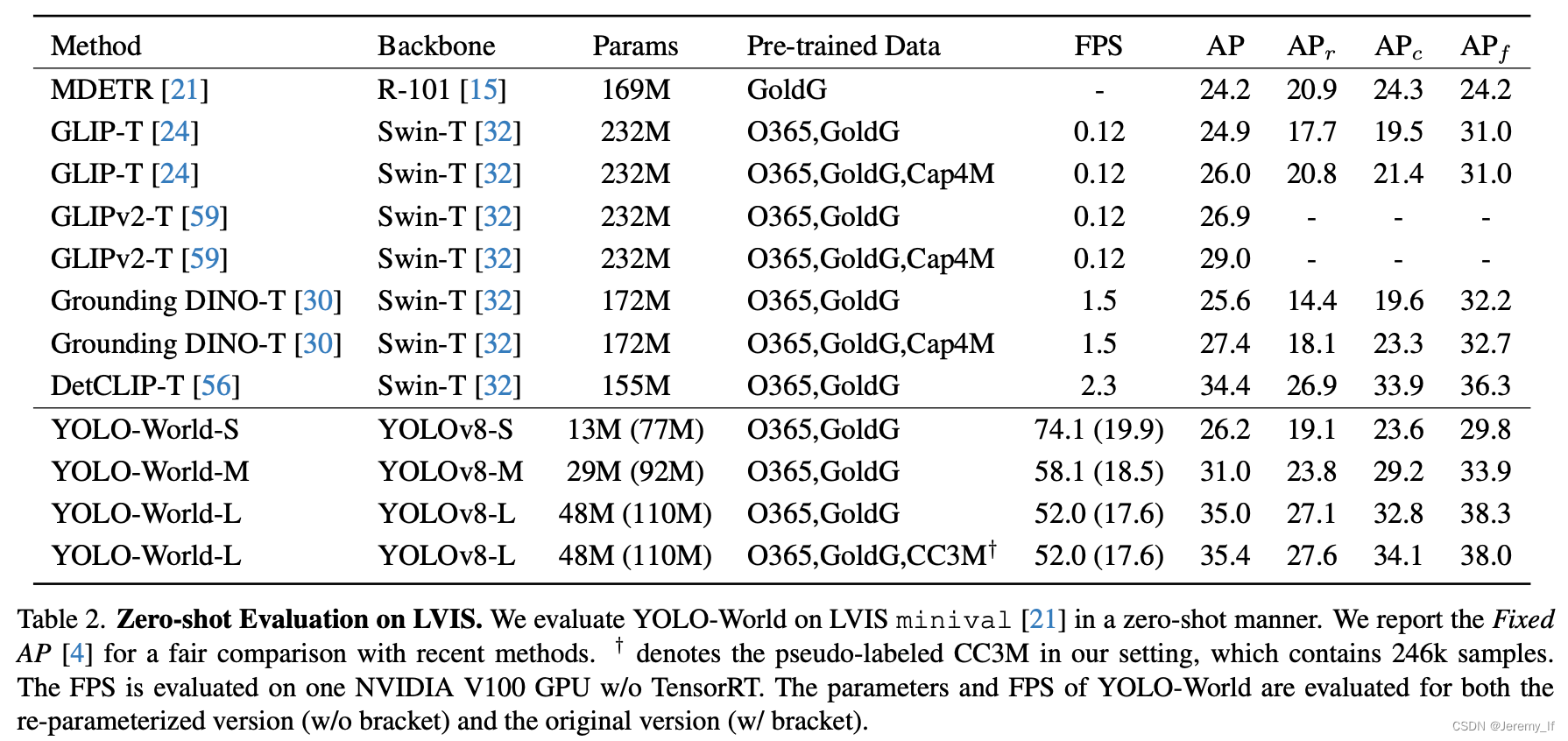
Grounding數據集通常用于計算機視覺和自然語言處理的聯合任務,特別是Visual Grounding任務。這類數據集包含圖像以及與之相關的物體描述,目標是定位描述中提及的物體。以下是Grounding數據集格式的詳細介紹,并通過舉例說明:一、數據集格式Grounding數據集一般由以下幾個部分組成:圖像(Images): 數據集包含一系列圖像,這些圖像中包含了需要被定位的物體。
描述(Descriptions): 針對每張圖像,數據集提供了相應的描述,這些描述可能是一個句子、短語或者是一個物體名稱,用于指明需要定位的物體。
標注框(Bounding Boxes): 對于描述中提及的每個物體,數據集都提供了一個或多個標注框,這些標注框用坐標表示物體在圖像中的位置。
類別標簽(Category Labels) (可選): 某些數據集還可能包含物體的類別標簽,以便于分類和識別。
二、舉例說明以Flickr30k Entities數據集為例,這是一個常用的Visual Grounding數據集:圖像: 數據集包含31783張圖像。
描述: 每張圖像對應5個不同的caption(描述),總共有158915個caption。
標注框: 數據集提供了244035個phrase-box標注,即針對特定短語的標注框。例如,如果一個caption是“A man in a red shirt is riding a bike”,那么“man”、“red shirt”和“bike”都可能有對應的標注框。
類別標簽: 數據集中的phrase還會被細分為people, clothing, body parts, animals, vehicles, instruments, scene, other等八個不同的類別。
在RefCOCO、RefCOCO+、RefCOCOg等數據集中,格式類似,但可能包含更多的交互性和復雜性,例如在RefCOCO+中,查詢不包含絕對的方位詞,要求模型更智能地理解上下文來定位物體。總的來說,Grounding數據集的格式是為了訓練模型能夠準確理解語言描述,并在圖像中定位相應物體的能力。通過大量的圖像、描述和標注框的組合,模型可以學習到如何從復雜的視覺和語言信息中提取關鍵特征,實現準確的物體定位。


![洛谷 [SNCPC2024] 寫都寫了,交一發吧 題解](http://pic.xiahunao.cn/洛谷 [SNCPC2024] 寫都寫了,交一發吧 題解)






)




- Drools規則語言(DRL))




