香橙派 AIpro 根據心情生成專屬音樂
- 一、OrangePi AI pro 開發版參數介紹
- 1.1 接口簡介
- 1.2 OrangePi AI pro 的Linux系統功能適配情況
- 1.3 開發板開機
- 1.4 遠程連接到 OrangePi AIpro
- 二、開發環境搭建
- 2.1 創建環境、代碼部署文件夾
- 2.2 安裝 miniconda
- 2.3 為 miniconda 更新國內源
- 2.4 創建一個 python 3.9 版本的開發環境
- 三、基于MindNLP + MusicGen生成自己的個性化音樂
- 3.1 模型介紹
- 3.2 下載模型
- 3.3 生成音樂
- 3.4 無提示生成
- 3.5 文本提示生成
- 3.6 音頻提示生成
- 四、總結
這篇博客 用 OrangePi AIpro 實現了根據文字、音頻、生成音樂
一、OrangePi AI pro 開發版參數介紹
首先必須要提的一點是 OrangePi AI pro 是 業界首款基于昇騰深度研發的AI開發板,采用昇騰AI技術路線,集成圖形處理器,擁有16GB LPDDR4X,最大可支持外接 256GB eMMC 模塊,支持雙 4K 高清輸出,8/20 TOPS AI算力。
1.1 接口簡介
Orange Pi AIpro 有著強大的可拓展性。包括兩個HDMI輸出、GPIO接口、Type-C電源接口、支持SATA/NVMe SSD 2280的M.2插槽、TF插槽、千兆網口、兩個USB3.0、一個USB Type-C 3.0、一個Micro USB、兩個MIPI攝像頭、一個MIPI屏等,一個預留電池接口。
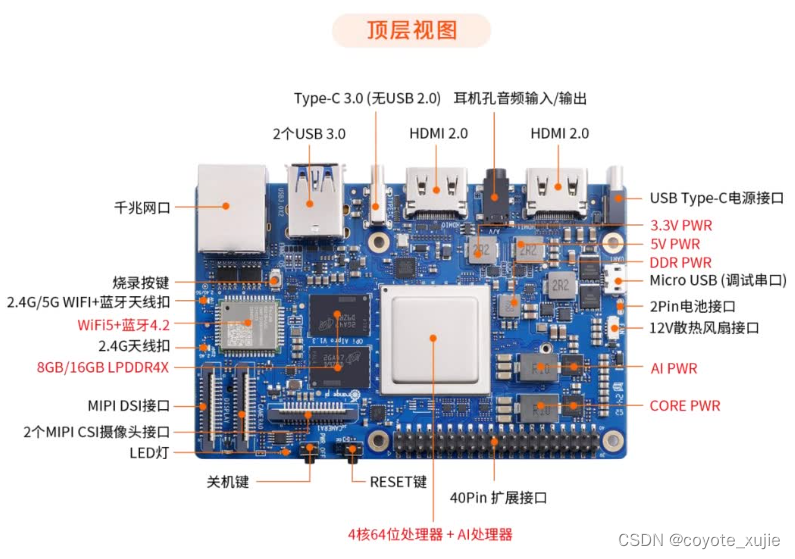
1.2 OrangePi AI pro 的Linux系統功能適配情況
| 功能 | 是否能測試 | Linux 內核驅動 |
|---|---|---|
| HDMI0 1080p 顯示 | OK | OK |
| HDMI0 4K 顯示 | NO | NO |
| HDMI0 音頻 | OK | NO |
| HDMI1 顯示 | OK | NO |
| HDMI1 音頻 | OK | NO |
| 耳機播放 | OK | NO |
| 耳機 MIC 錄音 | OK | NO |
| Type-C USB3.0(無 USB2.0) | OK | OK |
| USB3.0 Host x 2 | OK | OK |
| 千兆網口 | OK | OK |
| 千兆網口燈 | OK | OK |
| WIFI | OK | OK |
| 藍牙 | OK | OK |
| Micro USB 調試串口 | OK | OK |
| 復位按鍵 | OK | OK |
| 關機按鍵(無開機功能) | OK | OK |
| 燒錄按鍵 | OK | OK |
| MIPI 攝像頭 0 | OK | NO |
| MIPI 攝像頭 1 | OK | NO |
| MIPI LCD 顯示 | OK | NO |
| 電源指示燈 | OK | OK |
| 軟件可控的 LED 燈 | OK | OK |
| 風扇接口 | OK | OK |
| 電池接口 | OK | OK |
| TF 卡啟動 | OK | OK |
| TF 卡啟動識別 eMMC | OK | OK |
| TF 卡啟動識別 NVMe SSD | OK | OK |
| TF 卡啟動識別 SATA SSD | OK | OK |
| eMMC 啟動 | OK | OK |
| SATA SSD 啟動 | OK | OK |
| NVMe SSD 啟動 | OK | OK |
| 2 個撥碼開關 | OK | OK |
| 40 pin-GPIO | OK | OK |
| 40 pin-UART | OK | OK |
| 40 pin-SPI | OK | OK |
| 40 pin-I2C | OK | OK |
| 40 pin-PWM | OK | NO |
1.3 開發板開機
這里之所以要拿出來單獨說一下,就是因為我本人開了兩三次沒打開,以為是板子壞了,自己還滿心憤懣,后來發現是自己操作不對(確實沒看說明書)為了避免大家有同樣的錯誤!!!這里重點介紹!
首先 將燒好系統的 TF 卡查到對應位置上,將兩個啟動方式撥碼開關都向右撥(圖示為兩個啟動方式撥碼開關都撥向左)

之后將電源插入電源插口

1.4 遠程連接到 OrangePi AIpro
默認的用戶名:root
默認的密碼:Mind@123
二、開發環境搭建
2.1 創建環境、代碼部署文件夾
# 創建環境目錄
mkdir ~/env# 創建代碼目錄
mkdir ~/workshop
2.2 安裝 miniconda
下載 miniconda 到 ~/env 目錄,這里需要注意的是 OrangePi AIpro 是 arm 架構的
bash ~/env/Miniconda3-py312_24.3.0-0-Linux-aarch64.sh
conda 安裝完成如如圖所示:
2.3 為 miniconda 更新國內源
更新 miniconda 的源,如果有梯子的話這一步可以不做,但是如果梯子的網速感人的話,還是建議將源更新為清華源
# 修改 .condarc 文件
vi ~/.condarc
將 .condarc 文件修改如下
channels:- defaults
show_channel_urls: true
default_channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudmsys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudbioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudmenpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudpytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudpytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudsimpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/clouddeepmodeling: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/
清理之前預留的緩存
conda clean -i
2.4 創建一個 python 3.9 版本的開發環境
通過 conda 創建一個 python 3.9 的開發環境,并安裝 mindspore 框架,以及一些其他必要的庫函數
# 創建一個 python 3.9 的環境
conda create -n py39 python=3.9# 激活環境
conda activate py39
安裝 mindspore 框架,版本必須選擇 2.3.0rc2
conda install mindspore=2.3.0rc2 -c mindspore -c conda-forge# 安裝 mindnlp 包
pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindnlp==0.2.4 jieba
三、基于MindNLP + MusicGen生成自己的個性化音樂
3.1 模型介紹
這里簡單介紹一下 MusicGen 模型。MusicGen 是基于單個語言模型(LM)的音樂生成模型,能夠根據文本描述或音頻提示生成高質量的音樂樣本,相關研究成果參考論文《Simple and Controllable Music Generation》。
MusicGen 模型基于Transformer結構,可以分解為三個不同的階段:
- 用戶輸入的文本描述作為輸入傳遞給一個固定的文本編碼器模型,以獲得一系列隱形狀態表示。
- 訓練 MusicGen 解碼器來預測離散的隱形狀態音頻 token。
- 對這些音頻 token 使用音頻壓縮模型(如 EnCodec)進行解碼,以恢復音頻波形。
MusicGen 直接使用谷歌的 t5-base 及其權重作為文本編碼器模型,并使用EnCodec 32kHz及其權重作為音頻壓縮模型。MusicGen 解碼器是一個語言模型架構,針對音樂生成任務從零開始進行訓練。
MusicGen取消了多層級的多個模型結構,例如分層或上采樣,這使得MusicGen 能夠生成單聲道和立體聲的高質量音樂樣本,同時提供更好的生成輸出控制。因此,MusicGen 不僅能夠生成符合文本描述的音樂,還能夠通過旋律條件控制生成的音調結構。
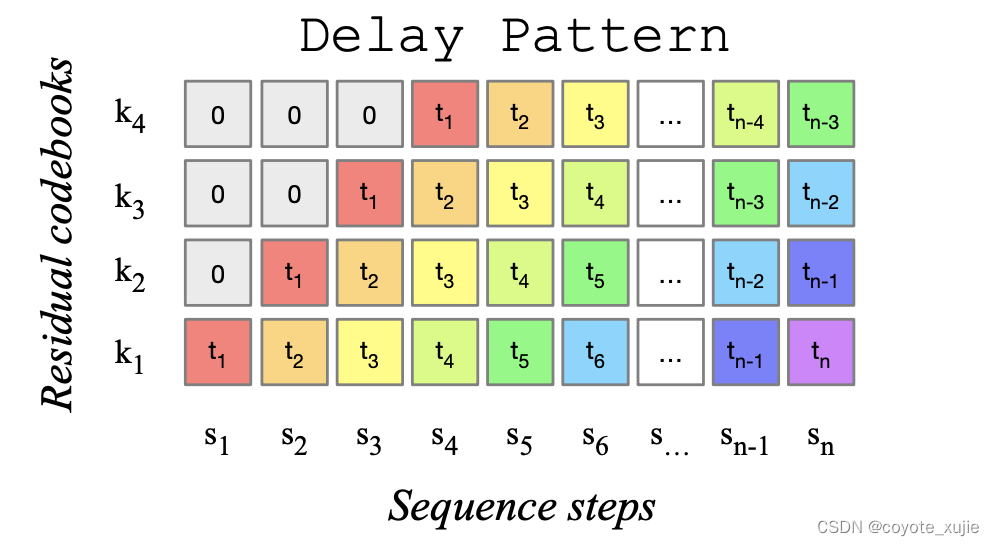
Figure 1: MusicGen使用的碼本延遲模式,來源于 MusicGen paper.
3.2 下載模型
MusicGen提供了small、medium和big三種規格的 預訓練權重文件,本次指南默認使用 small 規格的權重,生成的音頻質量較低,但是生成的速度是最快的(我的板子內存只有 8G大家可以選擇 16G 的板子):
from mindnlp.transformers import MusicgenForConditionalGeneration# 下載并導入模型
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
3.3 生成音樂
MusicGen 支持兩種生成模式:貪心(greedy)和采樣(sampling)。在實際執行過程中,采樣模式得到的結果要顯著優于貪心模式。因此我們默認啟用采樣模式,并且可以在調用 MusicgenForConditionalGeneration.generate 時設置 do_sample=True 來顯式指定使用采樣模式。
3.4 無提示生成
我們可以通過方法 MusicgenForConditionalGeneration.get_unconditional_inputs 獲得網絡的隨機輸入,然后使用 .generate 方法進行自回歸生成,指定 do_sample=True 來啟用采樣模式:
unconditional_inputs = model.get_unconditional_inputs(num_samples=1)audio_values = model.generate(**unconditional_inputs, do_sample=True, max_new_tokens=256)
音頻輸出是格式是: a Torch tensor of shape (batch_size,num_channels,sequence_length)。
使用第三方庫scipy 將輸出的音頻保存為 musicgen_out.wav 文件。
import scipysampling_rate = model.config.audio_encoder.sampling_rate
scipy.io.wavfile.write("musicgen_out.wav", rate=sampling_rate, data=audio_values[0, 0].asnumpy())
3.5 文本提示生成
首先基于文本提示,通過 AutoProcessor 對輸入進行預處理。然后將預處理后的輸入傳遞給 .generate 方法以生成文本條件音頻樣本。同樣,我們通過設置 do_sample=True 來啟用采樣模式。
其中,guidance_scale 用于無分類器指導(CFG),設置條件對數之間的權重(從文本提示中預測)和無條件對數(從無條件或空文本中預測)。guidance_scale 越高表示生成的模型與輸入的文本更加緊密。通過設置guidance_scale > 1 來啟用 CFG。為獲得最佳效果,使用guidance_scale=3(默認值)生成文本提示音頻。
from mindnlp.transformers import AutoProcessorprocessor = AutoProcessor.from_pretrained("facebook/musicgen-small")inputs = processor(text=["80s pop track with bassy drums and synth", "90s rock song with loud guitars and heavy drums"],padding=True,return_tensors="ms",
)audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)scipy.io.wavfile.write("musicgen_out_text.wav", rate=sampling_rate, data=audio_values[0, 0].asnumpy())# from IPython.display import Audio
# # 要收聽生成的音頻樣本,可以使用 Audio 進行播放
# Audio(audio_values[0].asnumpy(), rate=sampling_rate)
3.6 音頻提示生成
AutoProcessor同樣可以對用于音頻預測的音頻提示進行預處理。在以下示例中,我們首先加載音頻文件,然后進行預處理,并將輸入給到網絡模型來進行音頻生成。最后,我們將生成出來的音頻文件保存為musicgen_out_audio.wav
from datasets import load_datasetdataset = load_dataset("sanchit-gandhi/gtzan", split="train", streaming=True)
sample = next(iter(dataset))["audio"]# take the first half of the audio sample
sample["array"] = sample["array"][: len(sample["array"]) // 2]# 使用音視頻提示生成,耗時較久processor = AutoProcessor.from_pretrained("facebook/musicgen-small")inputs = processor(audio=sample["array"],sampling_rate=sample["sampling_rate"],text=["80s blues track with groovy saxophone"],padding=True,return_tensors="ms",
)audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)scipy.io.wavfile.write("musicgen_out_audio.wav", rate=sampling_rate, data=audio_values[0, 0].asnumpy())# from IPython.display import Audio
# # 要收聽生成的音頻樣本,可以使用 Audio 進行播放
# Audio(audio_values[0].asnumpy(), rate=sampling_rate)
四、總結
總體使用下來我將從 用戶友好程度、開發文檔支持程度、性能三個方面 對 Orange Pi AI Pro 進行總結:
- 用戶友好程度:燒錄好的系統和日常經常使用 Unbutu 系統體驗上并無任何不同,更為絢麗的界面、精簡的系統、完整的開發資料都極大的有助于新手快速玩轉開發板。我做的是一個音頻生成的模型,模型參數超過了 2G,在 c 上可以順利的運行、并生成相應風格的音樂。此外,OrangePi AIpro 系統的燒錄和啟動都很為新手著想(我就是新手),可以選擇TF卡、eMMC 或 SSD 作為啟動介質,每種方式都有詳細的官方指南,系統玩出問題了,恢復起來也很簡單。
- 開發文檔支持:作為新手,其實我們最擔心的問題就是文檔全不全、教程多不多、教程詳細不詳細!很幸運,OrangePi AIpro 有著詳盡的教程;用戶手冊內容詳實,從硬件參數到軟件配置,乃至進階功能均有詳細解說(收集到的一些教程我也會附在后面,方便大家查閱)。每個模塊都有單獨的說明,比較豐富的應用示例,一站式找到所有文檔的服務極大的降低了新手在開發中走彎路的可能。
- 性能:Orange Pi AI Pro 主打一個性價比!搭載的華為昇騰AI處理器,以 8TOPS 的INT8 算力和 4 TFLOPS FP16 的浮點運算能力,為復雜AI模型提供了強大的計算支撐。我在 8G 版本的 Orange Pi AI Pro 上 成功的運行了 MusicGen模型,其模型參數大小為 2.2G 這對于 8G 版本的 Orange Pi AI Pro 來說,無疑是一個極大的挑戰。板子在運行時內存使用超 90%,但是散熱真的很好,風扇噪音較小,整塊處理器的問題摸起來并不燙手,即使在滿載的情況下運行半小時左右,處理器的溫度略高于手指溫度。





)









)



