作者及發刊詳情
鄧晗珂,華南理工大學
摘要
正文
實驗平臺
選取模型: T r a n s f o r m e r b a s e Transformer_{base} Transformerbase?
訓練數據集:WMT-2014 英語-德語翻譯數據集、IWSLT-2014 英語-德語互譯數據集
Transformer模型壓縮
網絡模型計算中的輸入數據、權重數據和偏置數據都采取線性量化
量化過程:
- 獲取訓練后的得到的浮點 Transformer 模型,通過百分比校準獲取各線性層權重數據的初始量化系數,而后通過均方誤差校準獲取各線性層的權重數據的量化系數。
- 選取訓練集中一部分在上述訓練后模型基礎上多次前向推理,獲取該浮點模型中各層矩陣運算輸入數據的分布情況,從而根據百分比校準核均方誤差校準獲取各層矩陣運算的輸入數據的量化系數,利用這些系數計算每層矩陣運算輸入數據的量化系數
- 將第1點和第2點得到的系數相乘得到各層偏置數據的量化系數
采用偏移對角矩陣剪枝方法減少神經網絡的模型參數量
偏移對角矩陣結構化規則稀疏剪枝的訓練策略:
- 載入已訓練好的模型參數
- 對分類的權重進行基于偏移對角矩陣的結構化剪枝,整體過程遵循“訓練-剪枝-再訓練”和分批剪枝相結合的策略
Transformer硬件加速器
加速器硬件架構
包括片內全局緩存(包括輸入緩存、權重緩存和中間結果/輸出緩存)、運算單元陣列、softmax 計算單元、層歸一化計算單元(Layer norm)和控制模塊。
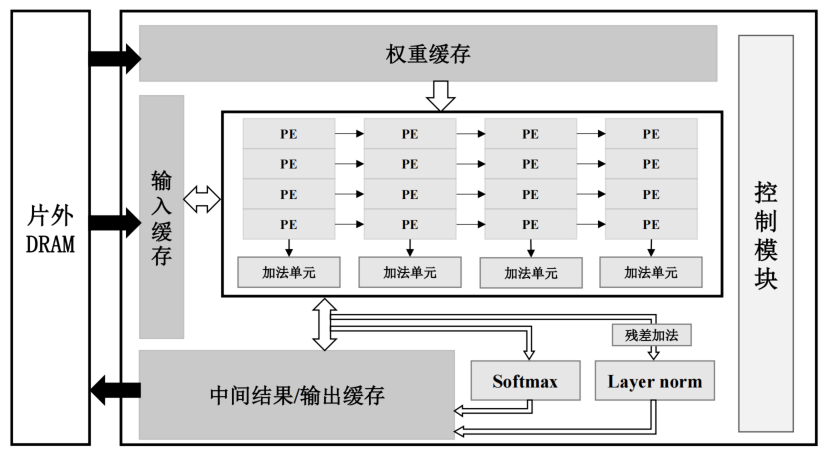
運算單元陣列的設計
多個計算單元(Processing Element, PE)和加法單元組成,每個PE對輸入和權重塊進行計算
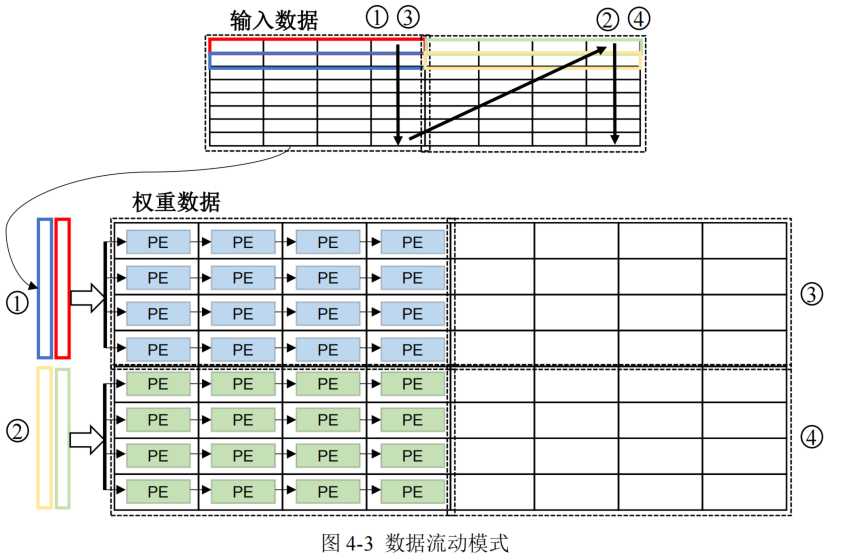
- 輸入數據以行數據形式流入運算單元陣列
- 為了減少數據移動成本,本文采取權重復用最大化的策略,并且權重以稀疏塊形式送入運算單元,對于輸入到運算單元陣列每一塊權重,將與之對應的所有輸入數據進行遍歷
- 輸入數據在 PE 陣列間傳遞可以對其進行復用,輸入數據的復用次數取決于 PE 陣列的列大小
PE的設計
每個 PE 中包括 16個乘法器和 1 個數據分配器,可以完成向量乘矩陣操作,輸出結果送入加法單元進行加法操作。
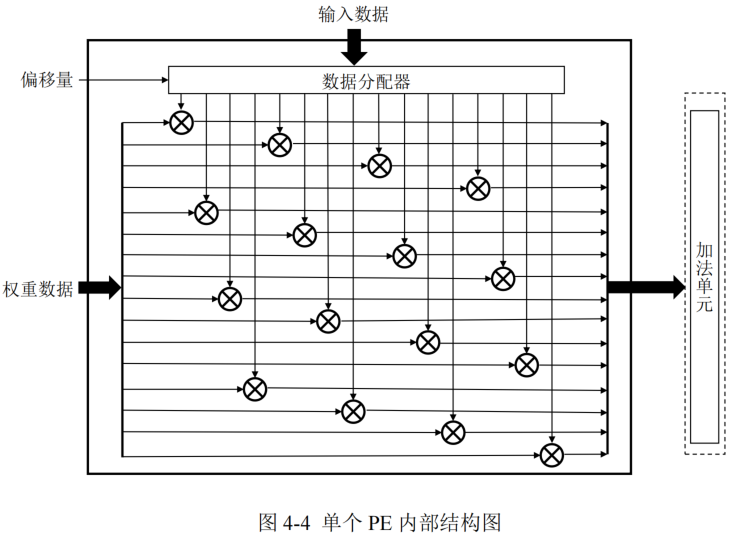
- 數據分配器的作用是根據偏移量對輸入數據進行重新排列,從而完成索引匹配,保證分配后的輸入數據和所對應的非零值權重數據相乘,同時也統一了密集矩陣運算和稀疏矩陣運算在 PE 內的數據流
這樣無需在 PE 外對剪枝后的權重數據進行稀疏解碼復原,同時不用對部分和輸出或計算結果進行地址索引,乘法器的部分和輸出排列順序與最終輸出數據的排列順序一致

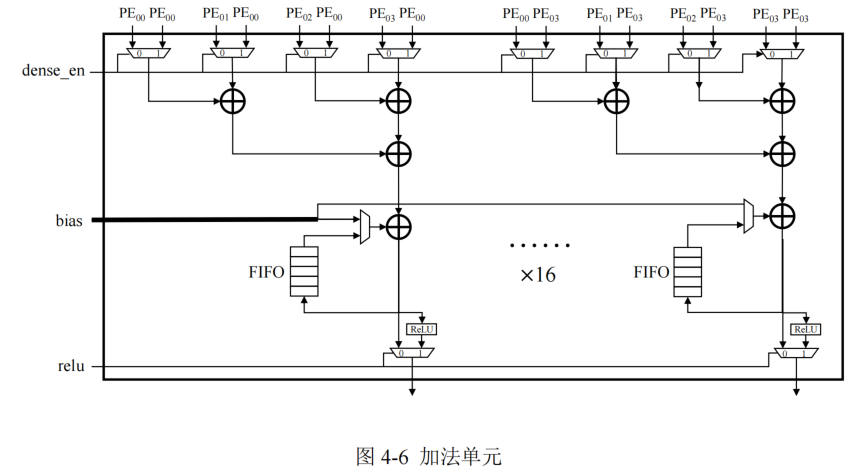
加法器的設計
加法單元負責將所在列的 4 個 PE 產生的部分和結果或者偏置數據進行加法運算,每個加法器單元內部配備用于緩存部分和結果的 FIFO,與加法單元內部的累加器進行數據交互產生最終計算結果,這樣可以縮短部分和的數據移動距離。
softmax函數計算單元的設計
包括:數據預處理模塊、指數計算模塊、累加模塊和對數計算模塊等模塊
softmax的計算:
對于一個K維向量 x = [ x 1 , x 2 , . . . , x K ] x=[x_1,x_2,...,x_K] x=[x1?,x2?,...,xK?],則softmax的輸出向量s為:
s j = e x j ∑ k = 1 K e x k s_j=\frac{e^{x_j}}{\sum_{k=1}^{K} e^{x_k}} sj?=∑k=1K?exk?exj??
- softmax的計算存在除法運算和指數計算的數據溢出兩個問題
- 除法溢出問題:通過計算域變換,即將除法運算轉換為減法和對數運算
- 指數計算溢出問題:將指數函數的輸入進行等比例縮小,即將所有輸入數據減去數據中的最大值 x m x_m xm?,將指數函數的輸入范圍限定為 ( ? ∞ , 0 ] ,從而避免了數據溢出 (-\infty,0],從而避免了數據溢出 (?∞,0],從而避免了數據溢出
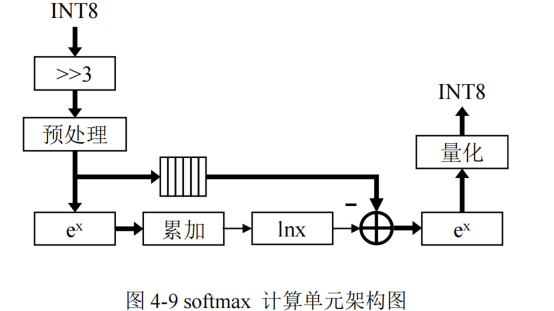
- 數據預處理模塊除了要減去最大值 x m x_m xm?,還需要對數據進行去量化操作
- softmax 計算單元的輸入數據的格式為 INT8,而且 Transformer 中的 softmax 的輸入值需要根據KaTeX parse error: Expected '}', got 'EOF' at end of input: \sqrt{d_{k}進行縮小,對應圖中的右移 3bit
- 對數計算模塊外的其他計算單元的計算并行度為 16
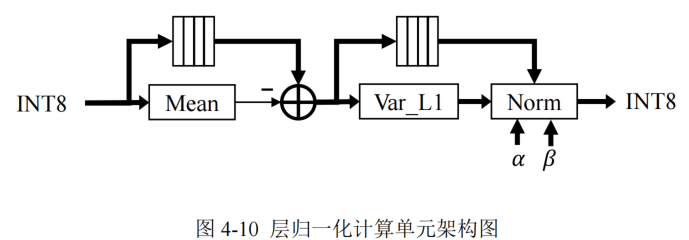
層歸一化函數計算單元設計
包括計算模塊有:均值計算模塊、Var_L1 計算模塊和 Norm 計算模塊
層歸一化計算存在于解碼器和編碼器的各子層間,為了避免復雜的標準差計算和簡化量化推理過程,本文使用 L1 范數的層歸一化代替了原始 Transformer 模型中的 L2 范數,通過實驗證實了 L1 范數的層歸一化不會影響數據分布以及模型性能。
- 計算輸入矩陣每行的均值,并將輸入數據進行緩存用于均值差計算
- 計算每行輸入的均值差,并將均值差緩存,避免重復計算
- 將均值差結果送入 Var_L1 模塊計算 L1 范數的標準差
- 在 Norm 模塊中將緩存的均值差進行除法運算,并且與對應的可訓練參數進行乘加計算。
權重數據存儲方案
為了減少非零數據的偏移量索引成本,本設計對硬件加速器的權重數據存儲進行了優化排列。
- 加速器運算單元陣列采取權重復用的數據復用模式,在整個計算過程中不重復讀取片上權重緩存中的權重數據,所以將偏移量索引與權重數據存儲在一起進行同步讀取,可以減少偏移量索引的讀取次數
- 在運算單元可以根據權重數據中的偏移量索引對輸入數據的順序進行重新排列,實現高效的索引匹配。
數據流
- 加速器的輸入數據和各層權重數據從片外 DRAM 中加載,并且在所有計算完成后將最終結果寫入到片外存儲
- 片內全局緩存負責所有片上數據的緩存,減少片外訪存的次數
- 運算單元陣列負責矩陣運算,可以兼容偏移對角稀疏權重矩陣以及密集矩陣計算,并且針對偏移對角稀疏矩陣進行了設計優化。
- softmax 單元負責模型中多頭注意力層中的注意力分數計算
- 層歸一化計算單元負責對編碼器和解碼器的子層運算結果進行歸一化運算
- 控制模塊負責控制整個計算過程中的數據讀寫和計算使能,根據計算矩陣類型、網絡層類型和輸入數據長度等信息實現加速器的靈活控制。














)
ubuntu18.04上安裝opencv環境)


方法)
)