
在大模型中,文本解碼通常是指在自然語言處理(NLP)任務中使用的大型神經網絡模型(如Transformer架構的模型)將編碼后的文本數據轉換回可讀的原始文本的過程。這些模型在處理自然語言時,首先將輸入文本(如一段話或一個句子)編碼成高維空間中的向量表示,這些向量能夠捕捉到文本的語義和上下文信息。
在編碼過程中,模型通過多層神經網絡將文本的每個字符、單詞或標記(token)轉換成對應的向量。這些向量隨后在模型的解碼階段被處理,以生成或選擇最合適的序列來表示原始文本的含義。例如,在機器翻譯任務中,解碼階段會生成目標語言的文本;在文本摘要任務中,解碼階段會生成原文的摘要;在問答系統中,解碼階段會生成問題的答案。
?一、自回歸語言模型:
1、根據前文預測下一個單詞:

2、一個文本序列的概率分布可以分解為每個詞基于其上文的條件概率的乘積?:
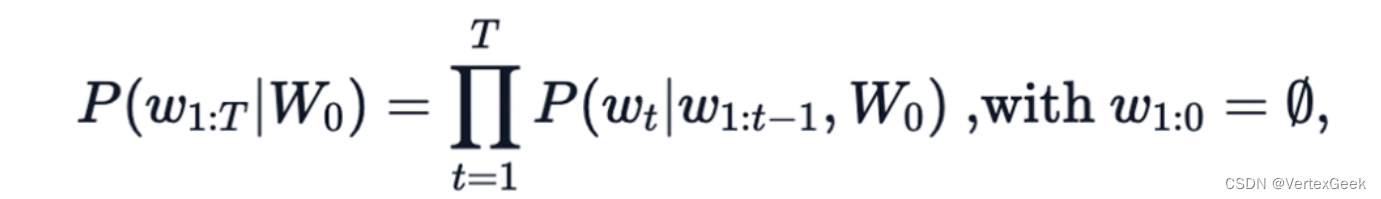
- w_0:初始上下文單詞序列
- T:時間步
- 當生存ESO標簽時停止生成?
3、MindNLP/huggingface Transformers提供的文本生成方法:
?二、環境準備:
首先還是需要下載MindSpore,相關教程可以參考我昇思25天學習打卡營第1天|快速入門這篇博客,之后就需要使用pip命令在終端卸載mindvision和mindinsight包之后,下載mindnlp:
pip uninstall mindvision -y
pip uninstall mindinsight -ypip install mindnlp相關依賴下載完成之后,就可以開始我們下面的實驗了!
三、Greedy Search:
在每個時間步𝑡都簡單地選擇概率最高的詞作為當前輸出詞:
wt = argmax_w P(w|w(1:t-1))
按照貪心搜索輸出序列("The","nice","woman")?的條件概率為:0.5 x 0.4 = 0.2
缺點: 錯過了隱藏在低概率詞后面的高概率詞,如:dog=0.5, has=0.9 
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModeltokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')# generate text until the output length (which includes the context length) reaches 50
greedy_output = model.generate(input_ids, max_length=50)print("Output:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))
四、Beam Search:
Beam search通過在每個時間步保留最可能的?num_beams?個詞,并從中最終選擇出概率最高的序列來降低丟失潛在的高概率序列的風險。如圖以?num_beams=2?為例:
("The","dog","has") : 0.4 * 0.9 = 0.36
("The","nice","woman") : 0.5 * 0.4 = 0.20
優點:一定程度保留最優路徑
缺點:1. 無法解決重復問題;2. 開放域生成效果差

from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModeltokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')# activate beam search and early_stopping
beam_output = model.generate(input_ids, max_length=50, num_beams=5, early_stopping=True
)print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
print(100 * '-')# set no_repeat_ngram_size to 2
beam_output = model.generate(input_ids, max_length=50, num_beams=5, no_repeat_ngram_size=2, early_stopping=True
)print("Beam search with ngram, Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
print(100 * '-')# set return_num_sequences > 1
beam_outputs = model.generate(input_ids, max_length=50, num_beams=5, no_repeat_ngram_size=2, num_return_sequences=5, early_stopping=True
)# now we have 3 output sequences
print("return_num_sequences, Output:\n" + 100 * '-')
for i, beam_output in enumerate(beam_outputs):print("{}: {}".format(i, tokenizer.decode(beam_output, skip_special_tokens=True)))
print(100 * '-')?
缺點的具體表現:
重復性高,這個看我生成的例子就可以很清楚的看到,著幾句話幾乎一模一樣,還有就是開放域的問題,可以看下圖:
 ?
?
五、超參數:
由于普通的默認索引均存在著難以克服的問題,人們通常會使用各種超參數來減小索引缺陷的影響。
1、n_gram懲罰:
將出現過的候選詞的概率設置為 0
設置no_repeat_ngram_size=2?,任意?2-gram?不會出現兩次
Notice: 實際文本生成需要重復出現

?2、Sample:
根據當前條件概率分布隨機選擇輸出詞w_t

優點:文本生成多樣性高
缺點:生成文本不連續
import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModeltokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')mindspore.set_seed(0)
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(input_ids, do_sample=True, max_length=50, top_k=0
)print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))?
3、Temperature:
降低softmax?的temperature使 P(w∣w1:t?1?)分布更陡峭,以增加高概率單詞的似然并降低低概率單詞的似然。

?
import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModeltokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')mindspore.set_seed(1234)
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(input_ids, do_sample=True, max_length=50, top_k=0,temperature=0.7
)print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True)) ?
?
4、Topk Sample:
選出概率最大的?K?個詞,重新歸一化,最后在歸一化后的?K?個詞中采樣,確定就是:將采樣池限制為固定大小?K 導致在分布比較尖銳的時候產生胡言亂語和在分布比較平坦的時候限制模型的創造力。
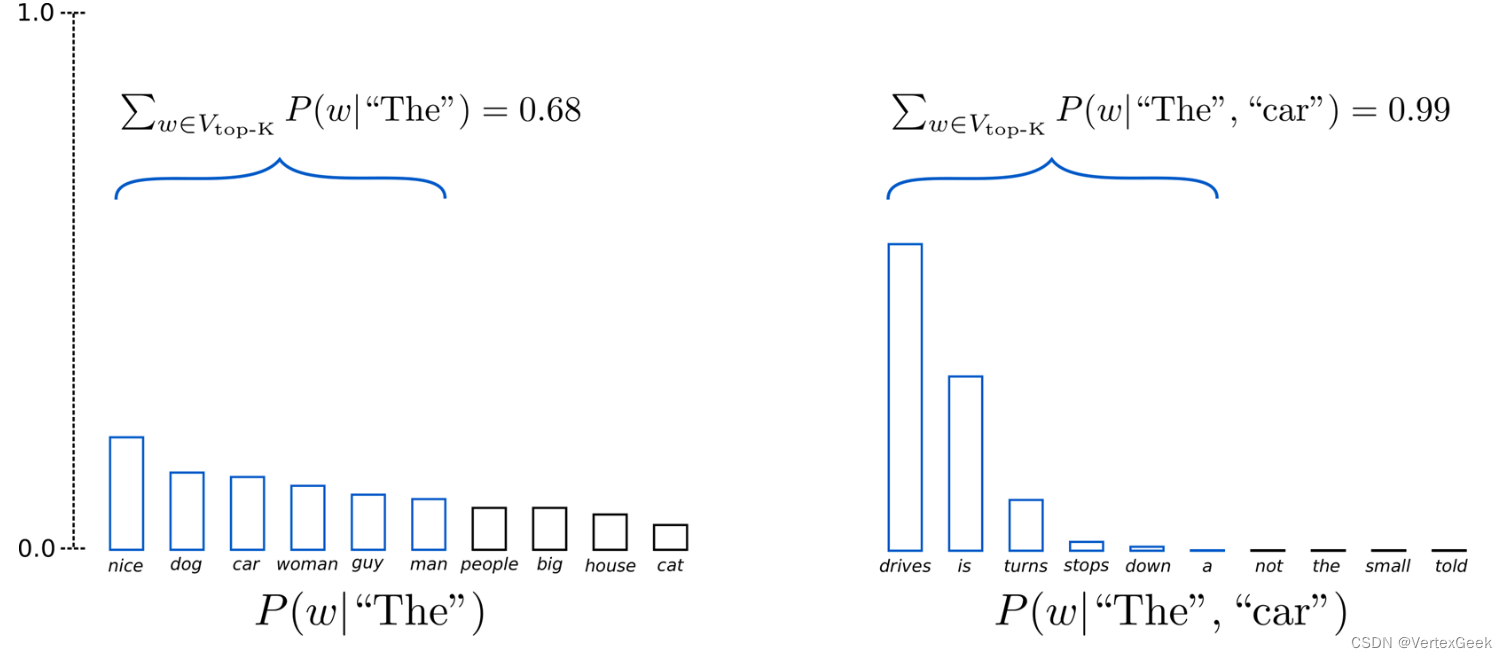
?
import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModeltokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')mindspore.set_seed(0)
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(input_ids, do_sample=True, max_length=50, top_k=50
)print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))

5、Top_P Sample:
在累積概率超過概率?p?的最小單詞集中進行采樣,重新歸一化,缺點就是:采樣池可以根據下一個詞的概率分布動態增加和減少。

import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModeltokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')mindspore.set_seed(0)# deactivate top_k sampling and sample only from 92% most likely words
sample_output = model.generate(input_ids, do_sample=True, max_length=50, top_p=0.92, top_k=0
)print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
?6、Top_k_Top_p:
import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModeltokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')mindspore.set_seed(0)
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(input_ids,do_sample=True,max_length=50,top_k=5,top_p=0.95,num_return_sequences=3
)print("Output:\n" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))


遠程連接失敗)




)











