文末有福利!
1. 集群高能效計算技術
隨著大模型從千億參數的自然語言模型向萬億參數的多模態模型升級演進,超萬卡集群吸需全面提升底層計算能力。
具體而言,包括增強單芯片能力、提升超節點計算能力、基于 DPU (Data Processing Unit) 實現多計算能力融合以及追求極致算力能效比。
這些系統性的提升將共同支持更大規模的模型訓練和推理任務,滿足迅速增長的業務需求。
1.1 單芯片能力
超萬卡集群中,單芯片能力包括單個 GPU 的計算性能和 GPU 顯存的訪問性能。
-
在單個 GPU 計算性能方面,首先需要設計先進的 GPU 處理器,在功耗允許條件下,研發單 GPU 更多并行處理核心,努力提高運行頻率。
-
其次,通過優化高速緩存設計,減少 GPU 訪問內存延遲,進一步提升單 GPU 芯片運行效率。
-
第三,優化浮點數表示格式,探索從 FP16 到 FP8 浮點數的表示格式,通過在芯片中引入新的存儲方式和精度,在保持一定精度條件下,大幅提升計算性能。
-
最后,針對特定計算任務,可在 GPU 芯片上集成定制化的硬件加速邏輯單元,這種基于 DSA (DomainSpecific Architecture) 的并行計算設計,可提升某些特定業務領域的計算速度。
?在 GPU 顯存訪問性能方面,為了將萬億模型的數據布放在數萬張 GPU 顯存上,要求顯存支持高帶寬、大容量的能力,確保計算單元能夠高效完成訪存任務,維持系統的低能耗運行。為便捷訪問顯存數據,建議 GPU 顯存采用基于 2.5D/3D 堆疊的HBM 技術,減少數據傳輸距離,降低訪存延遲,提升 GPU 計算單元與顯存之間的互聯效率。
通過這些技術的實施,超萬卡集群不僅能夠為智算中心提供強大的單卡算力處理能力,還能為未來更大規模的模型訓練和推理任務奠定堅實的硬件基礎。
2.2 超節點計算能力
針對萬億模型的訓練與推理任務,特別是在超長序列輸入和 MoE 架構的應用背景下,應重點優化巨量參數和龐大數據樣本的計算效率,滿足由此引發的 All2All 通信模式下的 GPU 卡間通信需求。
為此,建議超萬卡集群的改進策略集中在以下幾個關鍵領域:
-
加速推進超越單機8 卡的超節點形態服務器
為滿足萬億或更大參數量模型的部署需求,建議產業界致力于研制突破單機8 卡限制的超節點形態服務器,通過利用提高 GPU 南向的 Scale up 互聯能力,提升張量并行或 MoE 并行對大模型訓練任務的收益,實現性能躍升,縮短訓練總時長,實現大模型訓練整體性能的優化。
-
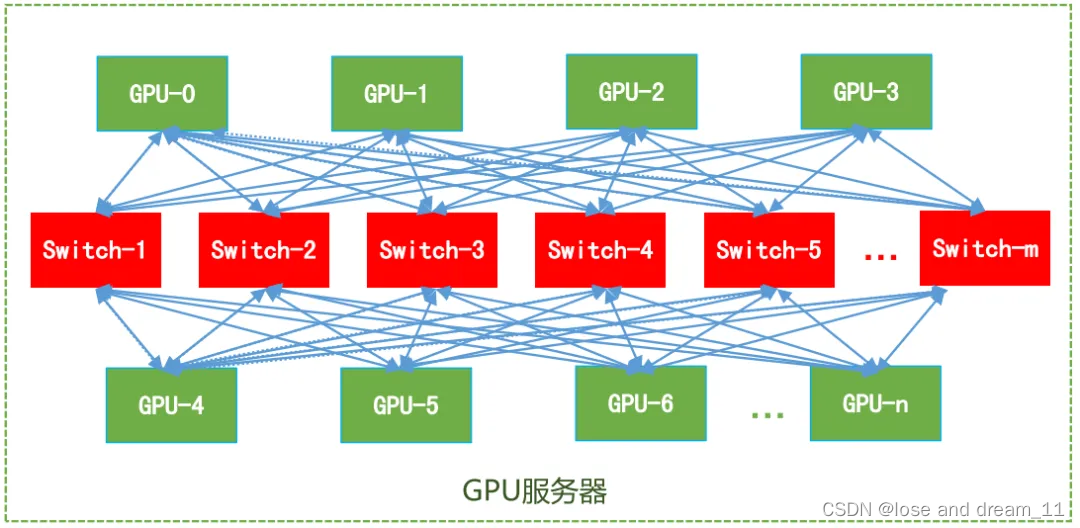
加快引入面向 Scale up 的 Switch 芯片
建議在節點內集成支持 Scale up 能力的 Switch 芯片,以優化 GPU 南向的互聯效率和規模,增強張量并行或 MoE 并行的數據傳輸能力。
如圖2 所示,通過引入節點內的 Switch 芯片,以增強 GPU 卡間的點對點 (Point to Point,P2P) 帶寬,有效提升節點內的網絡傳輸效率,滿足大模型日益增長的 GPU 互聯和帶寬需求,為大規模并行計算任務提供強有力的硬件支持。
home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fmmbiz.qpic.cn%2Fsz_mmbiz_png%2FZaRZRhbV4ribN4oTGasKsic8xsK9O5PGhtgZuX6ntlrc1mVknmhs2gKOicFxYBMIzgcCQGsmV5ZO4LO4MOTqjtmJA%2F640%3Fwx_fmt%3Dpng%26from%3Dappmsg&pos_id=img-JhsPSQKp-1719542155600)
圖2 在服務器內部引入 Switch 芯片示例
-
優化 GPU 卡間互聯協議以實現通信效率躍升
建議對 GPU 卡間互聯協議進行系統性優化和重構,以提升 AIl2All 模式下的通信效率。通過重新設計卡間通信過程中的數據報文格式、引入 CPO (Co-PackagedOptics) /NPO (Near Packaged Optics) 、提高和優化 SerDes 傳輸速率、優化擁塞控制和重傳機制以及多異構芯片 C2c(Chip-to-Chip)封裝等多種途徑,提高超萬卡集群的 GPU 卡間互聯的網絡利用率,減少通信時延,實現帶寬能力躍升,從而支持所需的更高頻次、更大帶寬和更低延遲通信特性。
2.3 多計算能力融合
面向超萬卡集群,考慮到智算中心內部成倍增長的數據交換需求,通過堆疊 CPU資源來處理網絡數據的做法無疑是低效且昂貴的,對此,智算中心的計算架構需要轉變方向,將原本運行在 CPU、GPU 中的數據處理任務卸載至具有層級化可編程、低時延網絡、統一管控等特性的 DPU 上執行,在大幅擴展節點間算力連接能力的同時,釋放 CPU、GPU 的算力,降低節點間的 CPU、GPU 協作成本,支撐集群發揮更大的效能。
具體地,可以對智算中心進行軟硬一體重構,打造計算、存儲、網絡、安全、管控五大引擎,定義標準化的 DPU 片上驅動內核:
-
計算引擎卸載加速 1/0 設備的數據路徑與控制路徑,面向節點提供標準化的virtio-net(Virtual1/0 Network)、virtio-blk(Virtiual 1/0 block)后端接口,屏蔽廠商專用驅動。
-
存儲引擎在 DPU 上實現存儲后端接口,可基于傳統 TCP/IP 網絡協議棧或RDMA(Remote Direct Memory Access)網絡功能連接塊存儲集群、對象存儲集群、文件存儲集群及文件存儲集群,將節點的全類型存儲任務卸載至 DPU 中完成。
-
網絡引擎將虛擬交換機卸載至 DPU 上,采用標準的流表和卸載接口實現網絡流量的卸載,全線速釋放硬件性能;同時集成 RDMA 網絡功能,降低多機多卡間端到端通信時延,提升多機間端到端通信帶寬至 400G 級別,構建節點間數據交換的高速通道”.
-
安全引擎通過信任根機制以及標準的IPsec等加密通訊協議對系統和多租戶網絡進行安全防護,并基于DPU提供有效的卸載方案。
-
管控引擎屏蔽裸金屬、虛擬機和容器等算力單元的形態差異,實現 DPU 資源統一管理和全鏈路管控運維。
-
以上述五大引擎為藍圖,中國移動于 2020 開始打造具有自主知識產權的磐石DPU,并于 2021 年正式推出磐石 DPU 版本。經過移動云現網的打磨,中國移動持續升級磐石 DPU 產品能力,并于 2024 年將磐石 DPU 的 FPGA 架構全面升級為ASIC 架構,旨在圍繞磐石 DPU 軟硬融合重構算力基礎設施,重新定義算力時代云計算技術新標準,構建算力時代新技術曲線。
將以磐石 DPU 為代表的 DPU 芯片融入現有智算中心技術體系,將算力集群由CPU+GPU 雙平臺支撐擴展至由 CPU+GPU+DPU 三平臺支撐,可以有效聯合集群節點間因數據 |/0 瓶頸而產生的算力孤島,突破現有技術架構下的集群規模極限,使超萬卡集群成為可能。
2.4 極致算力能效比
在制程工藝相對固定的條件下,芯片的高性能無疑會增加芯片的功耗,從而影響整機的散熱。面對高性能計算芯片功率密度急劇上升的現狀,需要通過制冷系統和GPU 芯片兩方面進行優化。
在制冷系統方面,當前單機8卡 GPU 服務器功耗已經數倍于通用服務器,由于GPU 的散熱量大幅增加,為了增加計算密度,節省空間,超萬卡集群建議采用當前較成熟的高密度冷板式液冷機柜,一個液冷機柜可容納多臺液冷 GPU 訓練服務器,相比傳統風冷機柜大幅提升空間利用率。
在 GPU 芯片方面,為了提升 GPU 單芯片的能效比,應采取多領域的優化策略實現高性能與低能耗之間的平衡。在芯片工藝領域,建議采用更加先進的半導體制造工藝,如 7nm 或更小的特征尺寸,以此降低晶體管的功耗,同時提升單芯片集成度。
此外,應加強超萬卡集群內 GPU 架構的創新設計,包括優化片上總線設計、改進流水線結構、優化電壓和頻率策略以及精確的時鐘門控技術,從而在不同工作狀態下實現最優的能耗效率。
在軟件層面,超萬卡集群應采用更加精細的監控和分析,實時跟蹤 GPU 的運行數據,并不斷優化算法和工作負載分配,以實現更加均衡和高效的算力利用。通過上述設計和優化,不僅能提高用戶的計算體驗,降低成本,也為智算中心可持續發展和綠色環保提出了可行方案。
2. 高性能融合存儲技術
為了實現存儲空間高效利用、數據高效流動,并支持智算集群大規模擴展,超萬卡集群應采用多協議融合和自動分級存儲技術,提升智算數據處理效率,助力超萬卡集群支撐千億乃至萬億大模型訓練。

2.1 多協議融合
超萬卡集群融合存儲底座承載Al全流程業務數據處理,兼容Al 全流程工具鏈所需的 NFS (Network File System)、S3 (Sample Storage Service) 和并行客戶端POSIX (Portable Operating System Interface) 等協議,支持各協議語義無損,達到與原生協議一樣的生態兼容性要求,在不同階段實現數據零拷貝和格式零轉換,確保前一階段的輸出可以作為后一階段的輸入,實現A各階段協同業務的無縫對接,達到“零等待”效果,顯著提升大模型訓練效率。
2.2 集群高吞葉性能
為滿足超萬卡集群大模型對干存儲高吞葉性能需求,基干全局文件系統技術,可支持超 3000 節點擴展規模,為大模型訓練提供百 PB 級全閃存儲大集群能力,從閃存密度、數據面網絡、并行客戶端和對等通信機制等多個維度全面提升存儲系統性能實現存儲集群 10TB/S 級聚合吞吐帶寬、億級 PS,智能算力利用率提升 20%以上.大模型 checkpoint 恢復時長從分鐘級提升至秒級,同時對高價值智算存儲數據提供強一致性訪問和 99.9999%可靠性能力。
2.3 高效分級管理
超萬卡集群數據量巨大,其中大部分是溫冷數據,統籌考慮性能和成本因素,規劃普通性能、高性能兩類存儲集群。普通性能存儲集群使用混閃存儲介質,具備低成本和大容量優勢,提供溫冷數據存儲;高性能存儲集群使用全閃存儲介質,為大模型訓練提供數據高吞吐能力,主要用于存放熱數據。為智算應用高效管理和訪問數據,兩類存儲集群應該對外呈現統一命名空間,提供基于策略的數據自動分級流動能力實現冷熱數據按照策略白動流動,避免人工頻繁介入,提升存儲系統整體運行效率。
3 大規模機間高可靠網絡技術
超萬卡集群網絡包括參數面網絡、數據面網絡、業務面網絡、管理面網絡。業務面網絡、管理面網絡一般采用傳統的 TCP 方式部署,參數面網絡用于計算節點之間參數交換,要求具備高帶寬無損能力。
數據面網絡用于計算節點訪問存儲節點,也有高帶寬無損網絡的訴求。超萬卡集群對參數面網絡要求最高,主要體現在四個方面:大規模,零丟包,高吞吐,高可靠。
**目前業界成熟的參數面主要包括B(InfiniBand) 和RoCE 兩種技術。**面向未來Al大模型演進對網絡提出的大規模組網和高性能節點通信需求,業界也在探索基于以太網新一代智算中心網絡技術,包括由中國移動主導的全調度以太網 (GlobaScheduled Ethernet,GSE)方案和 Linux Foundation 成立的超以太網聯盟(UltraEthernet Consortium,UEC),兩者通過革新以太網現有通信棧,突破傳統以太網性能瓶頸,為后續人工智能和高性能計算提供高性能網絡。中國移動也將加速推動 GSE技術方案和產業成熟,提升AI 網絡性能,充分釋放 GPU 算力,助力 AI 產業發展。
3.1 大規模組網
根據不同的 Al服務器規模,參數面網絡推薦采用 Spine-Leaf 兩層組網或胖樹(Fat-Tree)組網。
Spine-Leaf 兩層組網如圖3 所示。每8 臺 Leaf 交換機和下掛的 Al 服務器做為一個 group,以 group 為單位進行擴展。在 group 內部,推薦采用多軌方案將Al服務器連接至Leaf 交換機,即所有Al服務器的1 號網口都上連至Leaf1,所有2 號網口上連至 Leaf2,依此類推,所有8 號網口上連至 Leaf8。Spine 交換機和Leaf 交換機之間采用 Fullmesh 全連接。Leaf 交換機上下行收斂比為 1:1。

圖3 Spine-Leaf 兩層組網
胖樹 (Fat-Tree)組網由 Leaf 交換機、Spine 交換機和 Core 交換機組成,如圖4 所示。每8臺Leaf 交換機和下掛的AI 服務器做為一個 group,8臺 Leaf 交換機又和上面N 臺 Spine 交換機組成一個 pod,胖樹組網以 pod 為單位進行擴展。在胖樹組網中,Spine 交換機和 Leaf 交換機之間采用 Fullmesh 全連接,所有Spine1 都 Full-Mesh 連接至第一組 Core,所有 Spine2 都 Full-Mesh 連接至第二組 Core,依次類推。Spine 交換機和 Leaf 交換機上下行收斂比都為 1:1。

圖4 胖樹組網
3.2 零丟包無損網絡
分布式高性能應用的特點是“多打一”的 Incast 流量模型。對于以太交換機,Incast 流量易造成交換機內部隊列緩存的瞬時突發擁塞甚至丟包,帶來應用時延的增加和吞吐的下降,從而損害分布式應用的性能。Al 人工智能計算場景通常采用RoCEv2 協議與 DCOCN (Data Center Quantized Congestion Notification) 擁塞控制機制相互配合實現零丟包無損網絡。
DCOCN 要求交換機對遇到擁塞的報文進行 ECN (Explicit CongestionNotification) 標記,傳統方式的 ECN 門限值是通過手工配置的,這種靜態的 ECN水線無法適配所有的業務流量模型:水線配置低了,頻繁進行 ECN 通告,網絡吞葉上不來;水線配置高了,可能導致頻繁觸發 PFC(Priority-based Flow Control) ,影響整網的其他業務流量。因此建議在參數面網絡和數據面網絡里部署動態 ECN 技術.通過 AI算法,根據網絡業務流量模型,計算出對應的 ECN 水線配置,達到在保證吞吐的同時,盡量維持較低的隊列時延,讓網絡的吞吐和時延達到最佳平衡。
無論是靜態 ECN 還是動態 ECN,本質上都是被動擁塞控制機制,通過反壓源端降低報文發送速度來保證網絡無損,實際上并沒有達到提升吞吐率效果,反而降低了GPU 利用率。因此,中國移動提出 GSE 技術,通過全局動態的主動授權機制,從根本上最大限度消除網絡擁塞,減少網絡設備隊列資源的開銷,降低模型訓練任務的長尾時延,突破RoCEv2 性能瓶頸。
3.3 高吞吐網絡
AI 人工智能計算場景的流量特征是流數少、單流帶寬大。傳統的 ECMP (EqualCost Multi Path) 是基于5 元組的逐流 HASH,在流數少的時候極易出現 HASH 不均的情況,建議使用端口級負載均衡技術或算網協同負載均衡技術代替傳統的 ECMP。
端口級負載均衡部署在 Leaf 交換機上,以源端口或目的端口作為數據流均衡的影響因子,在一個端口組內將歸屬于不同端口的數據流均衡到本地出端口集合上,消除傳統基于五元組哈希的不確定性。
除此之外,還可以在參數網絡里部署算網協同負載均衡技術,Al調度平臺把任務信息通知給網絡控制器,網絡控制器結合已經建立的整網拓撲信息,進行整網最優轉發路徑計算,計算完成后自動生成路徑并動態下發到網絡設備,實現多任務全網負載均衡。使網絡吞吐可以達到 95%以上,接近滿吞葉。
3.4 高可靠網絡
超萬卡集群中網絡作為業務流量的調度中樞,其穩定性決定著整個集群的運行效率。在典型的 CLOS 組網中,交換機之間都有多條路徑,當一條鏈路出現故障的時候通過感知端口狀態、路由收斂、轉發路徑切換等操作,完成流量從故障鏈路到備用鏈路的收斂。但是這個時間一般在秒級。然而在Al場景里面,每次通信時間在毫秒級別,秒級時間內正常情況下已完成了多輪通信。如果依靠傳統的路由收斂方式,將極大的影響 Al計算效率。
DPFR (Data Plane Fast Recovery) 技術在此場景下,可以做到毫秒級收斂,提供基于數據面的本地快收斂或遠程快收斂。特性包含故障快速感知,故障本地快速收斂,故障通告生成、接收和中繼處理,故障遠程快速收斂和表項老化處理。針對關鍵應用,盡量做到應用無感知的故障快速收斂效果,即在鏈路故障發生時業務性能無明顯下降。
4 高容錯高效能平臺技術
智算平臺是智算中心承載模型訓練、推理和部署的綜合性平臺系統,在智算中心技術體系架構中承擔著重要的角色,對算力基礎設施進行統一納管、調度、分配和全生命周期管理,主要包含對計算、存儲、網絡等laas 資源的云化管控,在此基礎上通過云原生的容器底座能力,實現智算資源納管分配、AI任務作業調度、拓撲感知調度、訓練全鏈路監控等滿足智算業務的核心需求。
隨著模型參數量和數據量的激增,訓練所需的單集群規模來到萬級,但是智算平臺的性能通常不能隨著算力線性增長,而是會出現耗損,因此大模型訓練還需要高效的算力調度來發揮算力平臺的效能。而這不僅需要依賴算法、框架的優化,還需要借助高效的算力調度平臺,根據算力集群的硬件特點和計算負載特性實現最優化的算力調度,來保障集群可靠性和計算效率。針對以上問題,業界多以斷點續訓、并行計算優化、智能運維等作為切入點,構建高容錯高效能智算平臺。
4.1 斷點續訓高容錯能力
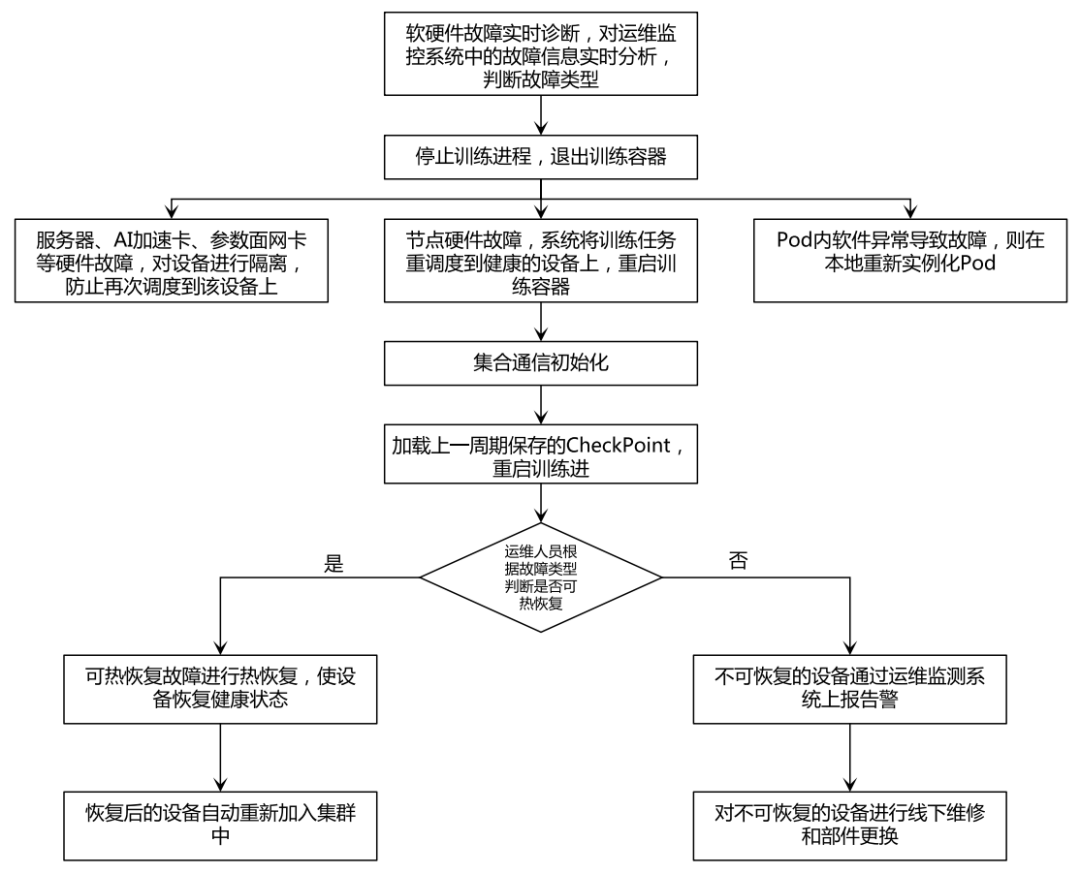
大模型訓練面臨的困難在于確保訓練任務能夠持續進行而不中斷。在訓練過程中,可能會遇到硬件故障、軟件故障、網絡故障以及其他故障。這種頻繁中斷導致的訓練進度的損失對于耗時又耗資源的大模型訓練來說是難以承受的,需要具備自動故障檢測和訓練重啟。當前業界大模型訓練主要容錯方案依賴于訓練過程中周期性保存checkpoint,故障發生后從上一個周期性 checkpoint 重新啟動訓練。
基于平臺的運維監控能力,可以實現對超萬卡集群的軟硬件故障檢測和預警,但是當故障發生且導致模型訓練中斷或停止時,通常需要人工介入排查故障信息,隔離故障并重新觸發容器 pod 資源調度,重新完成并行訓練中集合通信的初始化,重新加載基于中斷前最近一次保存的 checkpoint 信息,最后經歷算子庫的重新編譯,完成訓練任務的繼續。
圖5 為典型的斷點續訓流程:
智算業務需求短時爆發,敏捷部署的智算中心成為剛需。新型智算中心規劃建設時,可采用一體化電源系統、預制集成泵站模式、集裝箱式智算中心、模塊化智算中心等預制模塊化建造技術,縮短工程交付周期,實現快速部署。
5.4 綠色能源應用
新型智算中心應積極應用綠色能源技術,實現低碳零碳算力和可持續發展。新型智算中心應結合園區選址特點與周邊環境條件,因地制宜部署分布式光伏、風力發電等系統,實現清潔能源的就地生產與消納;通過電力交易、綠色證書交易等模式采購可再生能源電力,提升綠色能源使用比例。隨著氫能應用技術的發展,智算中心可內逐步規模化應用氫燃料電池。
5.5 智能化運維管理
借助大數據、Al 技術、數字李生等技術,構建新型智算中心的智能運維管理體系。運用 AI算法預測設備故障、優化能源使用、智能調度資源,實現主動運維、精準運維。通過機器學習、大數據分析等技術,對智算中心的運行數據進行深度挖掘,提升故障診斷、性能調優、容量規劃等方面的決策準確性與效率。
6 未來展望
隨著數據規模的持續擴大、集群能力的不斷增強以及大模型應用的日益豐富,對新型智算底座的升級提出了更高的要求。
面對未來,我們呼吁在超節點、跨集群訓練、軟件框架等領域實現技術突破,以強化智算基礎設施能力。
與此同時持續探索存算一體、光子芯片等先進技術領域與智算中心的結合,為下一次信息變革奠定基礎。
1) 引入超節點,拓展 Scale up 能力:
隨著大模型的進一步發展,單純通過Scale out 擴展更多張 Al 卡已經無法滿足萬億、數十萬億大模型的訓練需要,算力形態將通過 Scale up 發展到超節點架構,突破傳統單機8 卡,通過內部高速總線將A 芯片互聯,一臺超節點即可實現萬億參數訓練和實時推理,未來超節點將成為智算基礎設施的重要組成部分。
面向未來數萬乃至數十萬卡超大規模組網、高速總線無收斂互連、統一內存語義互訪、數十乃至數百 MW 級供電散熱等等,仍需重點攻克。
為了支持 scale up 卡間互聯能力,中國移動提出一種創新的互聯架構一-全向智感互聯系統 (0mnidirectionalIntelligentSensing Express InterconnectArchitecture,簡稱OISA,音譯“歐薩”),旨在為 GPU 間南向通信提供優化的連接方案。
OISA 將基于對等通信架構、極簡報文格式、高效物理傳輸和靈活擴展能力等設計理念,構建一套可以支持百卡級別的 GPU 高速互聯系統,在支持卡間交換拓撲的同時,通過對電接口、聚合技術、報文格式進行優化,提高 GPU 之間的數據傳輸效率。
0ISA 將在物理層、鏈路層、事務層等方面進行系統性重構,為大規模并行計算和 Al應用構建個高效、可靠的互聯能力,以支持非平面布局的多維互聯,打破傳統服務器內連接限制,實現高效數據協同。
2) 大規模邏輯集群,突破傳輸距離限制,探索跨節點互聯網絡技術:
隨著模型參數量、算力資源需求十倍速增長,驅動智算中心組網規模向萬卡級,甚至是十萬卡級演進。智算中心因機房空間、供電等基礎設施限制,不可避免出現同園區跨樓宇部署及小局點短距互聯實現邏輯大集群的需求。網絡傳輸距離拉遠會增加傳輸時延以及對傳輸設備的無損緩沖提出了更高的要求,相應也會影響集群有效算力,需要從工程上和科學上進一步研究和驗證影響性和優化方案。
3) 軟件框架技術方面,提升自動化能力和訓練效率:
超萬卡集群下模型規模和數據集復雜度提升,需要在軟硬件、算法、網絡等方面持續創新,聚焦于自動化、跨平臺支持、大規模模型訓練、跨集群訓練、邊緣訓推等方面不斷優化完善,實現高效可靠和快速的深度學習模型訓練,提高模型的準確性和訓練效率,降低用戶開發大模型的使用門檻和資源開銷,提供更加高效、易用的模型訓練工具。
4)潛在換道超車技術方面,突破摩爾極限,探索下一代芯片設計和應用范式:
大模型的發展給傳統馮諾伊曼計算體系結構帶來了功耗墻、內存墻和通訊墻等多重挑戰。
未來需探索從存算一體、光子芯片等領域突破現有 Al芯片設計和應用范式。
一方面大力推動存算一體在大模型推理場景應用,推進先進制程支持,加速存算一體技術在大模型芯片和大規模應用。
另一方面是利用好光子芯片在傳輸速度、低功耗等方面的技術優勢,探索未來與智算產業和 A生態的結合方式。
我意識到有很多經驗和知識值得分享給大家,也可以通過我們的能力和經驗解答大家在人工智能學習中的很多困惑,所以在工作繁忙的情況下還是堅持各種整理和分享。但苦于知識傳播途徑有限,很多互聯網行業朋友無法獲得正確的資料得到學習提升,故此將并將重要的AI大模型資料包括AI大模型入門學習思維導圖、精品AI大模型學習書籍手冊、視頻教程、實戰學習等錄播視頻免費分享出來。

 **_
**_

? 能夠利用大模型解決相關實際項目需求: 大數據時代,越來越多的企業和機構需要處理海量數據,利用大模型技術可以更好地處理這些數據,提高數據分析和決策的準確性。因此,掌握大模型應用開發技能,可以讓程序員更好地應對實際項目需求;
? 基于大模型和企業數據AI應用開發,實現大模型理論、掌握GPU算力、硬件、LangChain開發框架和項目實戰技能, 學會Fine-tuning垂直訓練大模型(數據準備、數據蒸餾、大模型部署)一站式掌握;
? 能夠完成時下熱門大模型垂直領域模型訓練能力,提高程序員的編碼能力: 大模型應用開發需要掌握機器學習算法、深度學習框架等技術,這些技術的掌握可以提高程序員的編碼能力和分析能力,讓程序員更加熟練地編寫高質量的代碼。

1.AI大模型學習路線圖
2.100套AI大模型商業化落地方案
3.100集大模型視頻教程
4.200本大模型PDF書籍
5.LLM面試題合集
6.AI產品經理資源合集
👉獲取方式:
😝有需要的小伙伴,可以保存圖片到wx掃描二v碼免費領取【保證100%免費】🆓

 _
_



)
)














