0 引言
隨著水質自動站的普及,監測頻次越來越高,自動監測越來越準確。
水質站點增多,連續的水質監測數據,給水質預測提供更多的訓練基礎。
長短時記憶網絡(LSTM)適用于多變量、連續、自相關的數據預測。
人工神經網絡模型特點為的非線性映射,是廣泛應用的水質預測方法。
1.長短時記憶網絡(LSTM)介紹
1.1起源
1997年,Hochreiter等提出了長短時記憶網絡(LSTM),作為深度學習的一種,LSTM既考慮了多元變量間的非線性映射關系,又可以解決傳統人工神經網絡不能解決的時間序列長期依賴問題,應用場景包括:金融交易、交通預測、機器翻譯、水質預測等。
1.2原理
長短時記憶網絡(LSTM)是在循環神經網絡(RNN)的基礎上改進而來。
循環神經網絡(RNN)作為深度學習方法的一種,其主要用途是對序列數據處理。RNN具有自連接隱層,其t時刻隱層狀態依靠t-1時刻隱層狀態進行更新,因此能夠解決時間序列長期依賴的問題。RNN理論上可以進行非線性時間序列的有效處理,但實際對較長時間序列進行建模應用中,存在梯度消失及梯度爆炸的問題。
LSTM是RNN的一種變體,與RNN一樣,LSTM隱藏層具有隨時間序列的重復節點。LSTM節點相較RNN更為復雜,它將RNN中隱含層中的神經元替換為記憶體,以此實現序列信息的保留與長期記憶。
一個標準的LSTM記憶體見圖1。
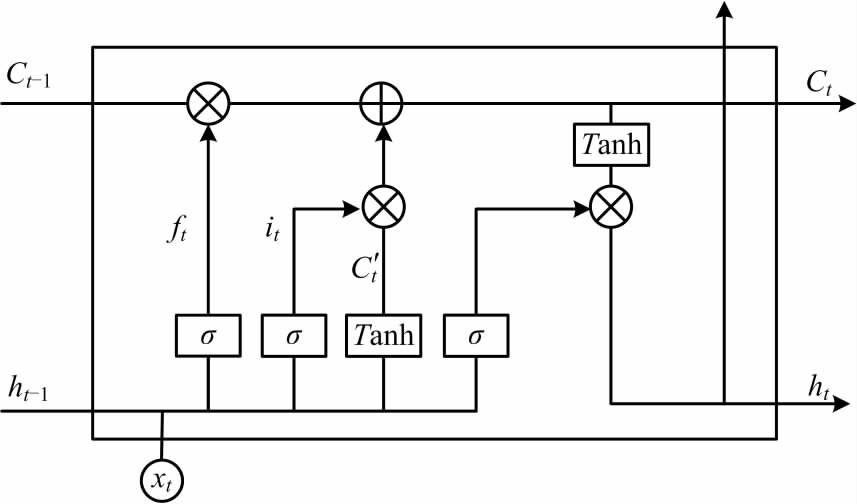
圖 1 中,C 為 LSTM 記憶體的細胞狀態,h 為節點的隱藏層狀態。每個記憶體包含一到多個記憶細胞和 3 種“門”,LSTM 通過記憶細胞進行細胞狀態信息存儲,門結構負責細胞狀態的更新與保持,3 種 “門”包括“遺忘門”“輸入門”和“輸出門”。“遺忘門”控制歷史信息對當前細胞狀態的影響。 f t f_t ft? 決定了上一時刻細胞狀態 C t ? 1 C_{t -1} Ct?1? 的通過程度。
f t = σ ( w f [ h t ? 1 , x i ] + b i ) (01) f_t=σ(w_f[h_{t-1},x_i]+bi)\tag{01} ft?=σ(wf?[ht?1?,xi?]+bi)(01)
C t ? 1 C_{t -1} Ct?1?為t - 1 時刻細胞狀態;ht - 1為t - 1 時刻隱藏層狀態; σ 為sigmoid 激活函數; wf 為輸入循環權重; Xt 為當前時刻節點的輸入值;bf 為偏置項。“輸入門”決定了進入記憶細胞的是哪些信息,“遺忘門”與“輸入門”結合可以實現細胞狀態Ct 的更新。
i t = σ ( w i [ h t ? 1 , x i ] + b i ) (02) i_t=σ(w_i[h_{t-1},x_i]+b_i)\tag{02} it?=σ(wi?[ht?1?,xi?]+bi?)(02)
C t ‘ = T a n h ( w C [ h t ? 1 , x i ] + b C ) (03) C_t^‘=Tanh(w_C[h_{t-1},x_i]+b_C)\tag{03} Ct‘?=Tanh(wC?[ht?1?,xi?]+bC?)(03)
C t = f i C t ? 1 + i t C t ‘ (04) C_t=f_iC_{t-1}+i_tC_t^‘\tag{04} Ct?=fi?Ct?1?+it?Ct‘?(04)
式中it 為輸入門向量值; C’t為新信息; Ct 為t 時刻,細胞狀態; bi、bC 為偏置項; wC 為輸入權重。
“輸出門”控制細胞狀態值的輸出,用Tanh 激活函數處理細胞狀態后,與記憶單元狀態值相乘得到輸出信息。
σ t = σ ( w o [ h t ? 1 , x t ] + b o ) (05) σ_t=σ(w_o[h_{t-1},x_t]+b_o)\tag{05} σt?=σ(wo?[ht?1?,xt?]+bo?)(05)
h t = o t × T a n h ( C t ) (06) h_t=o_t×Tanh(C_t)\tag{06} ht?=ot?×Tanh(Ct?)(06)
式中 h t h_t ht?為t 時刻隱藏層狀態; w o w_o wo?為輸入權重; o t o_t ot?為輸出值; b o b_o bo?為偏置項。
由上式可以看出,LSTM 節點通過門結構對細胞狀態上的信息進行線性修改,從而保證在時間序列變長的情況下,依然能夠保持時間相關性不會衰減。
2.算法流程及評價指標
2.1 算法流程
模型包括2個部分,分別為模型預處理與模型訓練與評價。
2.1.1 數據預處理
數據預處理分為引入前處理及引入后處理。
引入前處理
引入前使用sql語句進行預處理,主要是去除0值、空值、異常值。這里異常值判斷依據基于設備上下限、及經驗。
select * FROM
(SELECTCASE device_idWHEN '87d39a3c' THEN '站點D'WHEN '2ab9a08e' THEN '站點C'WHEN '17b96c2b' THEN '站點B'WHEN 'e83005a1' THEN '站點A'END AS 'device_name' ,data_time AS 'data_time',CASE factor_codeWHEN 'w01003-Avg' THEN '濁度'WHEN 'w21003-Avg' THEN '氨氮'WHEN 'w01010-Avg' THEN '水溫'WHEN 'w01014-Avg' THEN '電導率'WHEN 'w01019-Avg' THEN '高指'WHEN 'w01001-Avg' THEN 'PH'WHEN 'w21011-Avg' THEN '總磷'WHEN 'w01009-Avg' THEN '溶解氧'WHEN 'w21001-Avg' THEN '總氮'END AS 'fator_code',value as 'value'FROM iot_devices_detailwhere device_id in ('87d39a3c','2ab9a08e','17b96c2b','e83005a1')and data_time > '2021-01-01 00:00:00'and factor_code in ('w21003-Avg','w21011-Avg','w01019-Avg')and frequency='h4'and value>0AND value is not nulland flag='1'group by data_time,factor_code,device_idorder by device_id,factor_code) dWHEREd.fator_code='高指' and d.value between 2 and 20or d.fator_code='總磷' and d.value between 0 and 1.5or d.fator_code='氨氮' and d.value between 0 and 150or d.fator_code='濁度' and d.value between 0 and 4000or d.fator_code='水溫' and d.value between 0 and 60or d.fator_code='電導率' and d.value between 0 and 2000or d.fator_code='PH' and d.value between 0 and 14or d.fator_code='溶解氧' and d.value between 0 and 20or d.fator_code='總氮' and d.value between 0 and 100
py引入可使用MySQL語句
其中sql為上面的代碼,注意去掉換行符
def conn_sql(sql):conn = pymysql.connect(host="",port=3306,user="",password="",db="",charset="utf8")sql = sqlread_sql = pd.read_sql(sql, conn)return read_sql
# read_sql=conn_sql()
# 定義鏈接數據庫
df = conn_sql(sql)
引入后處理
py數據處理內容為空值補全,補全方法為生成連續一小時時間序列index,數據拼接,數據線性插值。
def dataprocess_en(df, s, y):"""df:DataFrame時間序列數據;s:device_namey:fator_code"""aidunqiao = df.loc[df["device_name"] == s, :]ai_cod = aidunqiao.loc[df["fator_code"] == y, :]ai_cod_mn = ai_cod.loc[:, ["data_time", "value"]]baseline = ai_cod.loc[:, ["data_time", "value"]]ai_cod_mn.set_index("data_time", inplace=True)interp_cod_mn = ai_cod_mn["value"].interpolate()ai_cod_mn["value_2"] = interp_cod_mnstarttime = baseline.iloc[0, 0]rows = baseline.shape[0]endtime = baseline.iloc[rows - 1, 0]year_month_day = pd.date_range(starttime, endtime, freq="h").strftime("%Y%m%d%h%m%s")a_ser = pd.DataFrame({"data_time": year_month_day})a_ser.set_index("data_time", inplace=True)df = pd.concat([a_ser, ai_cod_mn], axis=0, join="outer")df = df.reset_index(drop=False)df["data_time"] = pd.to_datetime(df["data_time"])df1 = df.drop_duplicates(subset="data_time", keep="last", ignore_index=True)df2 = df1.sort_values(by="data_time", ignore_index=True)df2["value_2"] = df2["value"].interpolate()df2.drop(columns="value", inplace=True)df2.set_index("data_time", inplace=True)df2.columns = [s]return df2
數據輸出結果為,指定站點,制定因子的連續一小時監測結果。
引入數據后根據dataprocess_en,計算并拼接為最終預測基礎數據。
station = df["device_name"].unique()
factors = df["fator_code"].unique()
dfn= pd.DataFrame()
for j in range(len(factors)):dfn= pd.DataFrame()for i in range(len(station)):globals()['df_{}_{}'.format(i,j)] = data_process.dataprocess_en(df,station[i],factors[j])globals()['dm{}'.format(j)] = pd.concat([dfn, globals()['df_{}_{}'.format(i,j)]],axis=1)dfn=globals()['dm{}'.format(j)]
以上代碼將輸出dm0,dm1,dm2,不同因子的預測數據集
# 將需要預測的數據放在首列
pred_col= ['站點A']
all_cols = dm0.columns.values.tolist()
new_cols = pred_col + all_cols
new_cols = pd.Series(pred_col + all_cols).drop_duplicates()
當然也可以用比較直接的方式拼接數據集。
yx ="站點B"
fh ="站點C"
bl ="站點D"
cb = "站點A"
cod ="高指"
tp ="總磷"
nh3 ="氨氮"
df_cb_tp =data_process.dataprocess_en(df,cb,tp)
df_yx_tp =data_process.dataprocess_en(df,yx,tp)
df_fh_tp =data_process.dataprocess_en(df,fh,tp)
df_bl_tp =data_process.dataprocess_en(df,bl,tp)
df2 = pd.concat([df_cb_tp ,df_yx_tp,df_fh_tp,df_bl_tp],axis=1)
df2=df2[-3000:] # 取近3000個數據,保證運算速度和數據的更新程度
# df2=df2[::4] 可以取逐4小時值
以上數據準備結束,總磷預測數據集示例如下,第一列站點A為預測因變量。data_time為index
| data_time(index) | 站點A | 站點B | 站點C | 站點D |
|---|---|---|---|---|
| 2022-05-17 05:00:00 | 0.1955 | 0.250125 | 0.24355 | 0.247800 |
| 2022-05-17 06:00:00 | 0.1950 | 0.247950 | 0.24340 | 0.243100 |
| 2022-05-17 07:00:00 | 0.1945 | 0.245775 | 0.24325 | 0.238400 |
| 2022-05-17 08:00:00 | 0.1940 | 0.243600 | 0.24310 | 0.233700 |
| 2022-05-17 09:00:00 | 0.1885 | 0.240850 | 0.24290 | 0.230225 |
2.1.2 模型搭建與訓練
模型框架為
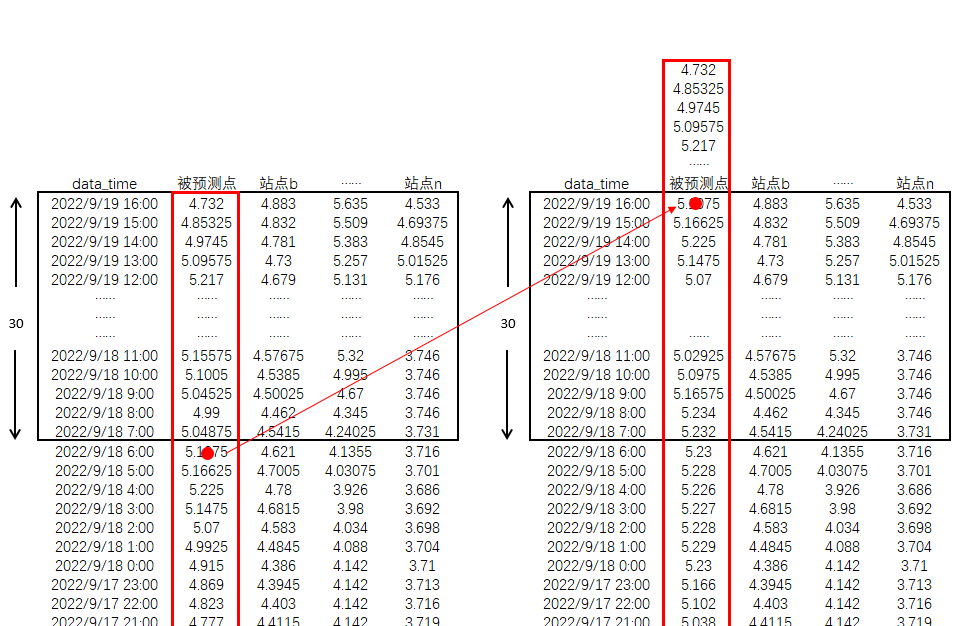
訓練階段 預測站點窗口滑動,
從結構示例圖看,若樣本窗口數量為30,樣本列數(含預測站點)為n,則框中紅點數據為預測數據,其余數據為訓練因變量,通過模型建立非線性關系。
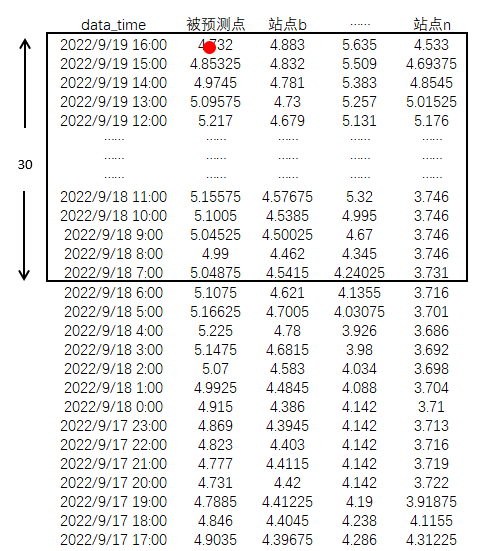
為了實現預測效果,采用滑動時間滑動技術,生成訓練基礎數據。
本次模型搭建采用tensorflower框架,面向對象編程。
# 導入相關包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.wrappers.scikit_learn import KerasRegressor
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_scoreplt.rcParams["font.sans-serif"] = ["Simhei"] # 解決坐標軸刻度負號亂碼
plt.rcParams["axes.unicode_minus"] = False
from datetime import date, datetime, timedelta
from sklearn.model_selection import GridSearchCV# 訓練模型,使用 girdsearchCV 進行參數調整以找到基礎模型。
定義本體,主要參數包括,預測數據集,預測時長,預測窗口數,預測步長
預測時間和預測窗口數最好一致,
預測數據集可為多參數,第一列為預測參數,
預測步長可以理解為逐小時,還是逐4小時,默認逐小時。
class LSTMTimePredictor:def __init__(self, df, shift_n=30, test_ratio=0.2, n_past=30,p_step=1 ,optimizer="adam"):"""df:DataFrame時間序列數據;test_ratio:測試比率n_past:預測的窗口數;optimizer:優化器;n_features:特征數;feature_names:特征名稱;shirt_n:預測時長"""self.df = dfself.test_ratio = test_ratioself.n_past = n_pastself.shift_n = shift_nself.optimizer = optimizerself.n_features = self.df.shape[1]self.feature_names = self.df.columnsself.p_step = p_step
時間滑動生成新的數據集。
def shift_date_new(self):"""時間滑動下一段滑動函數 n 為移動參數,即為預測長度df4都有的數據集用于訓練和測試df9向后預測的數據需要的未知數據集;"""df1 = self.dfn = self.shift_nbl_fh = df1.iloc[:, 1: self.n_features]cb = df1.iloc[:, 0]cb.to_framedf2 = cb.shift(periods=-n, axis=0)df3 = pd.concat([df2, bl_fh], join="outer", axis=1)df9 = df3[-n:]df4 = df3[:-n]return df4, df9
數據集劃分,歸一化
def _train_test_split(self):"""訓練測試劃分;"""df = self.shift_date_new()[0]test_split = round(len(self.df) * self.test_ratio) # 計算測試集中的樣本數量df_training = df[:-test_split]df_testing = df[-test_split:]# 進行最小最大歸一化scaler = MinMaxScaler(feature_range=(0, 1))df_training_scaled = scaler.fit_transform(df_training)df_testing_scaled = scaler.transform(df_testing)# 獲取訓練集和測試集的樣本數量self.train_length = len(df_training_scaled)self.test_length = len(df_testing_scaled)# 獲取歸一化后的訓練樣本和測試樣本self.scaler = scalerreturn df_training_scaled, df_testing_scaled區分自變量,因變量
def createXY(self, datasets):"""生成用于LSTM輸入的多元數據,例如時間窗口n_past=30,則一個樣本的維度為(30,5)30代表時間窗口,5代表特征數量將數據分為x yn_past 我們在預測下一個目標值時將在過去查看的步驟數 粒度n_past使用30,意味著將使用過去的30個值dataX 代表目標預測值dataY前所有因子,包括預測因子30個數據若n_past越小,則預測的平滑度越低,越注重于短期預測,若n_past越大則越注重長期預測"""dataX = []dataY = []for i in range(self.n_past, len(datasets)):dataX.append(datasets[i - self.n_past : i, 0 : datasets.shape[1]])dataY.append(datasets[i, 0])return np.array(dataX), np.array(dataY)
建立模型,并查找最優參數
def grid_search(self,):"""根據數據訓練模型,并查找最優的參數"""df_training_scaled = self._train_test_split()[0]df_testing_scaled = self._train_test_split()[1]X_train, y_train = self.createXY(df_training_scaled)X_test, y_test = self.createXY(df_testing_scaled)grid_model = KerasRegressor(build_fn=self._build_model, verbose=1, validation_data=(X_test, y_test))parameters = {"batch_size": [16, 20],"epochs": [8, 10],# , "Adadelta" "optimizer": ["adam"],}# 這里前文設置了optimizer為adam grid_search = GridSearchCV(estimator=grid_model, param_grid=parameters, cv=2)grid_search = grid_search.fit(X_train, y_train, validation_data=(X_test, y_test))self.model = grid_search.best_estimator_.model至此模型建立。
2.1.3 模型評價與模型預測
本次采用4種方法評價模型精度,分別是MSE、MAE、R2、準確率。
測試集模型預測精度評價及繪圖代碼如下:
def evaluate(self, plot=True):"""制圖及模型評價"""df_testing_scaled = self._train_test_split()[1]X_test, y_test = self.createXY(df_testing_scaled)# 預測值prediction = self.model.predict(X_test)prediction_copy_array = np.repeat(prediction, self.n_features, axis=-1)pred = self.scaler.inverse_transform(np.reshape(prediction_copy_array, (len(prediction), self.n_features)))[:, 0]# 實際值original_copies_array = np.repeat(y_test, self.n_features, axis=-1)original = self.scaler.inverse_transform(np.reshape(original_copies_array, (len(y_test), self.n_features)))[:, 0]# 序號還原df = self.shift_date_new()[0]test_split = round(len(self.df) * self.test_ratio) # 計算測試集中的樣本數量df_training = df[:-test_split]df_testing = df[-test_split:]index1 = df_testing.indexstarttime = index1[30]delta = timedelta(hours=30) # 時間序號還原starttime = starttime + deltastarttime = starttime.strftime("%Y-%m-%d %H:%M:%S")endtime = index1[-1]endtime = endtime + deltaendtime = endtime.strftime("%Y-%m-%d %H:%M:%S")time_nu = pd.date_range(starttime, endtime, freq="h").strftime("%Y-%m-%d %H:%M:%S")time_nu = time_nu[::self.p_step]original_2 = pd.DataFrame(original)col_2 = ["真實值"]original_2.columns = col_2original_3 = original_2.set_index(time_nu)pred_2 = pd.DataFrame(pred)col_1 = ["預測值"]pred_2.columns = col_1pred_3 = pred_2.set_index(time_nu)if plot:plt.figure(figsize=(14, 6))plt.plot(original_3, color="red", label="真實值")plt.plot(pred_3, color="blue", label="預測值")# plt.title(" 站點A氨氮預測")plt.xlabel("Time")plt.ylabel(" 預測值")plt.locator_params(axis="x", nbins=10)plt.xticks(range(1, len(time_nu), 48), rotation=45) # 刻度線顯示優化plt.legend()plt.show()mae = mean_absolute_error(original, pred)mse = mean_squared_error(original, pred)mape = np.mean(np.abs(original - pred) / original)r2 = r2_score(original, pred)acc = 1 - abs((pred - original) / original)acc = np.mean(acc)print("MSE : {},MAE : {}, MAPE : {}, r2 : {}, 準確率:{}".format(mse, mae, mape, r2, acc))return pred
數據集采用臨江河站點A、站點B、站點C、站點D等4個站點,預測站點A高指、氨氮、總磷3個因子。數據范圍為2022/5/19 5:00:00 至 2022/9/21 4:00:00。共3000個數據。測試集占比0.2。
測試集預測評價結果如下:MSE、MAE、R2均表現較好,總磷準確率、MAPE較差,與水質濃度波動大,關系密切,可以通過進一步優化數據清理減少數據波動。
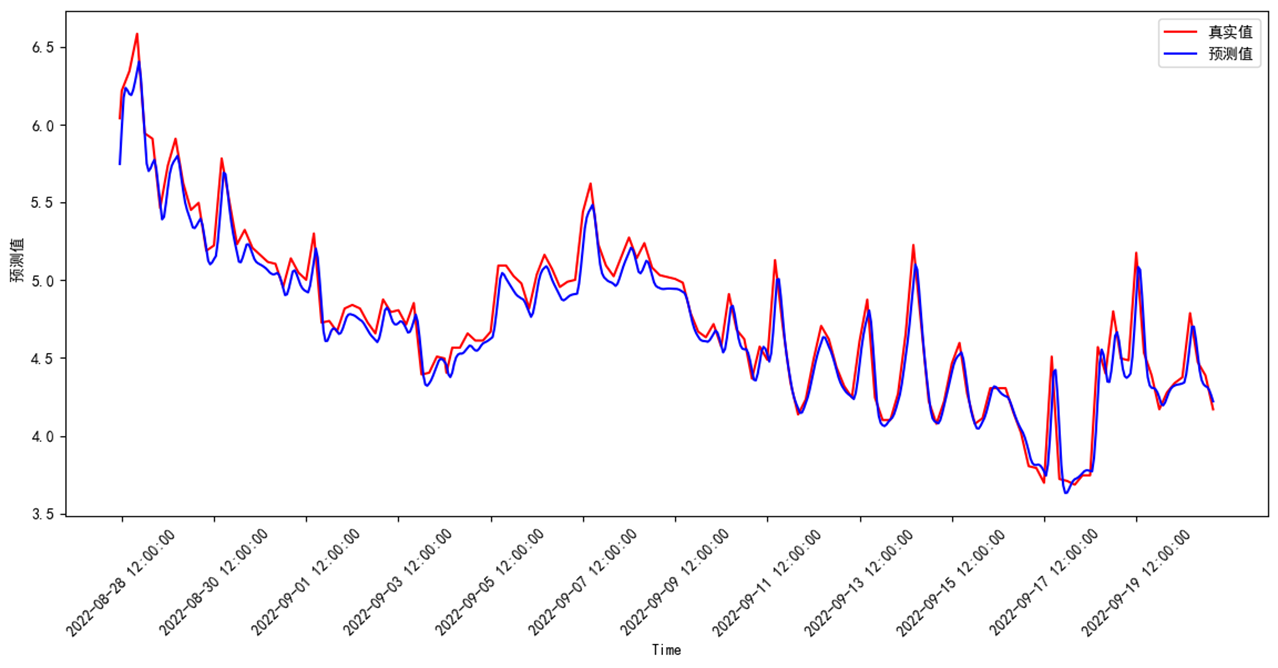
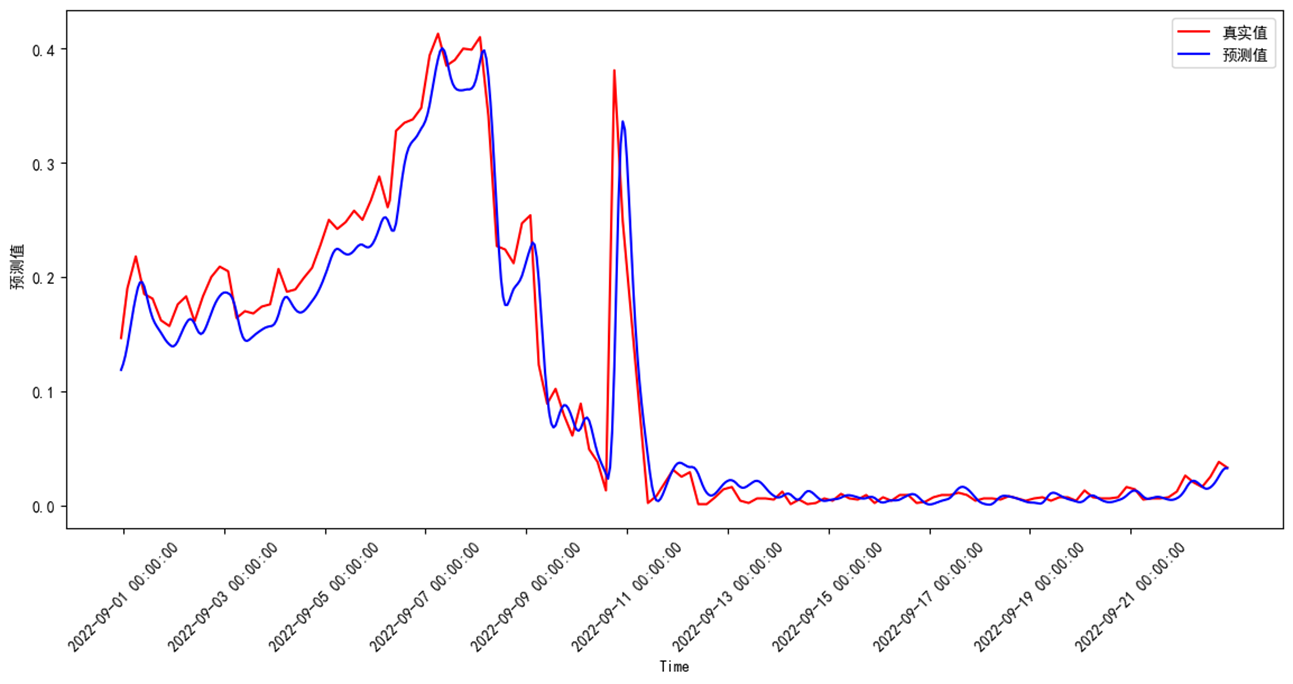
| 因子 | MSE | MAE | MAPE | r2 | 準確率 |
|---|---|---|---|---|---|
| 高指 | 0.00004273 | 0.00521874 | 0.037992 | 0.968379 | 0.962008 |
| 氨氮 | 0.01103716 | 0.07946250 | 0.016475 | 0.959818 | 0.983525 |
| 總磷 | 0.00081064 | 0.01672249 | 0.698055 | 0.947509 | 0.301945 |
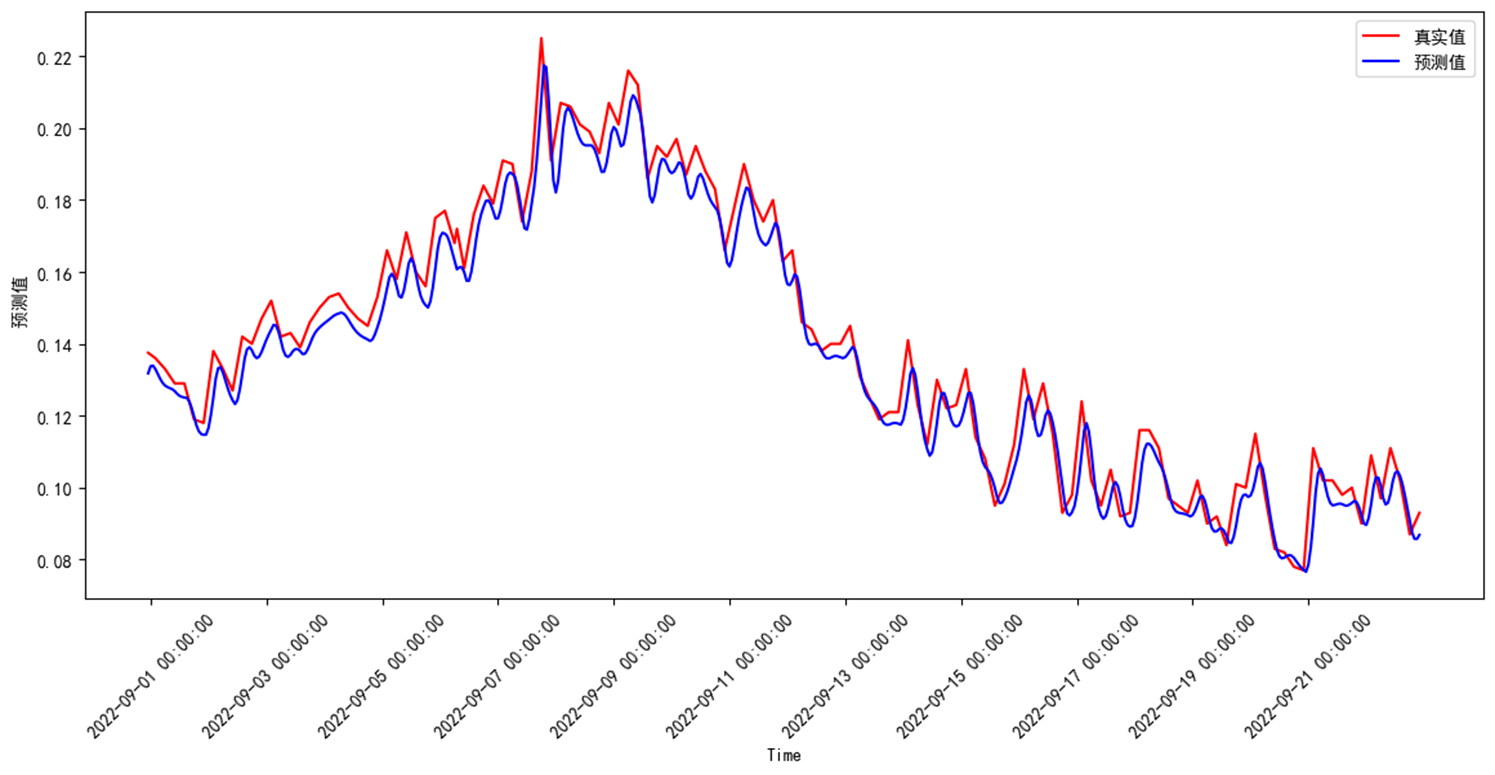
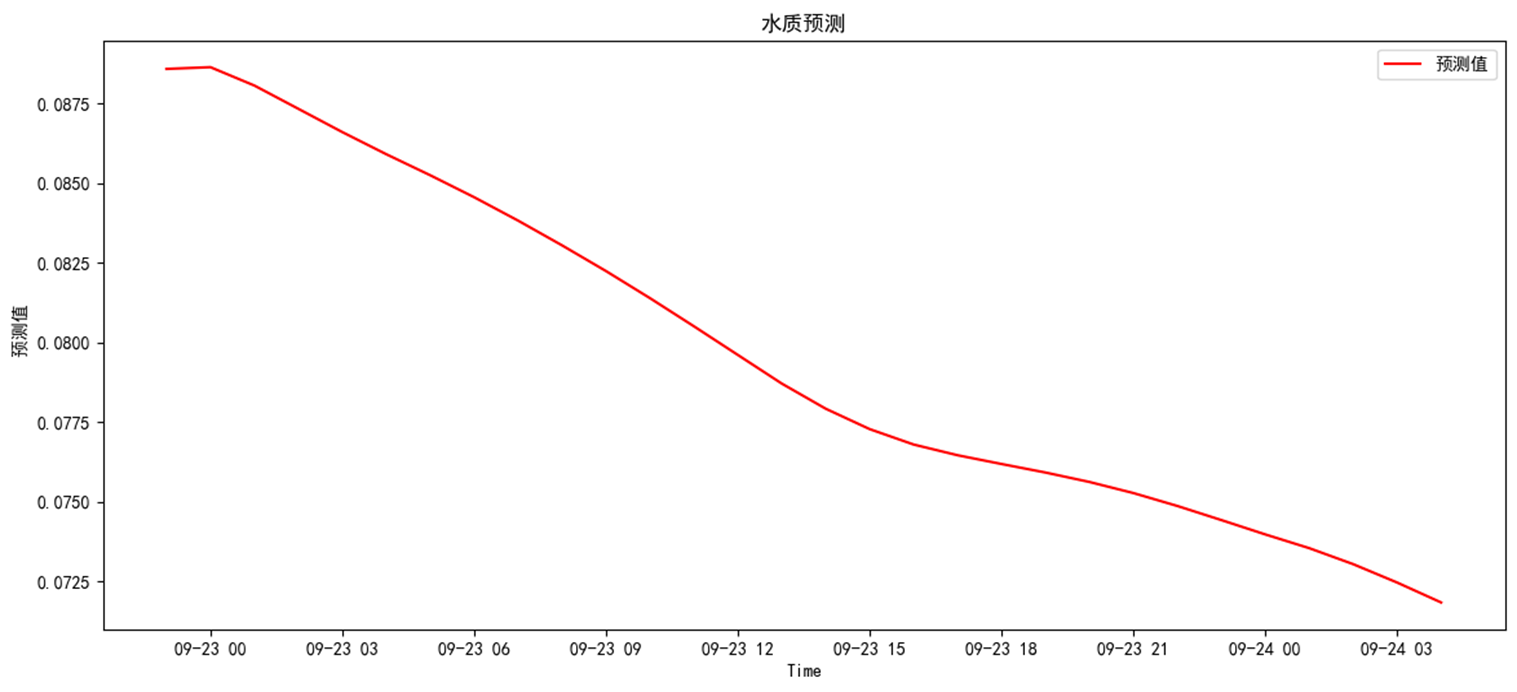
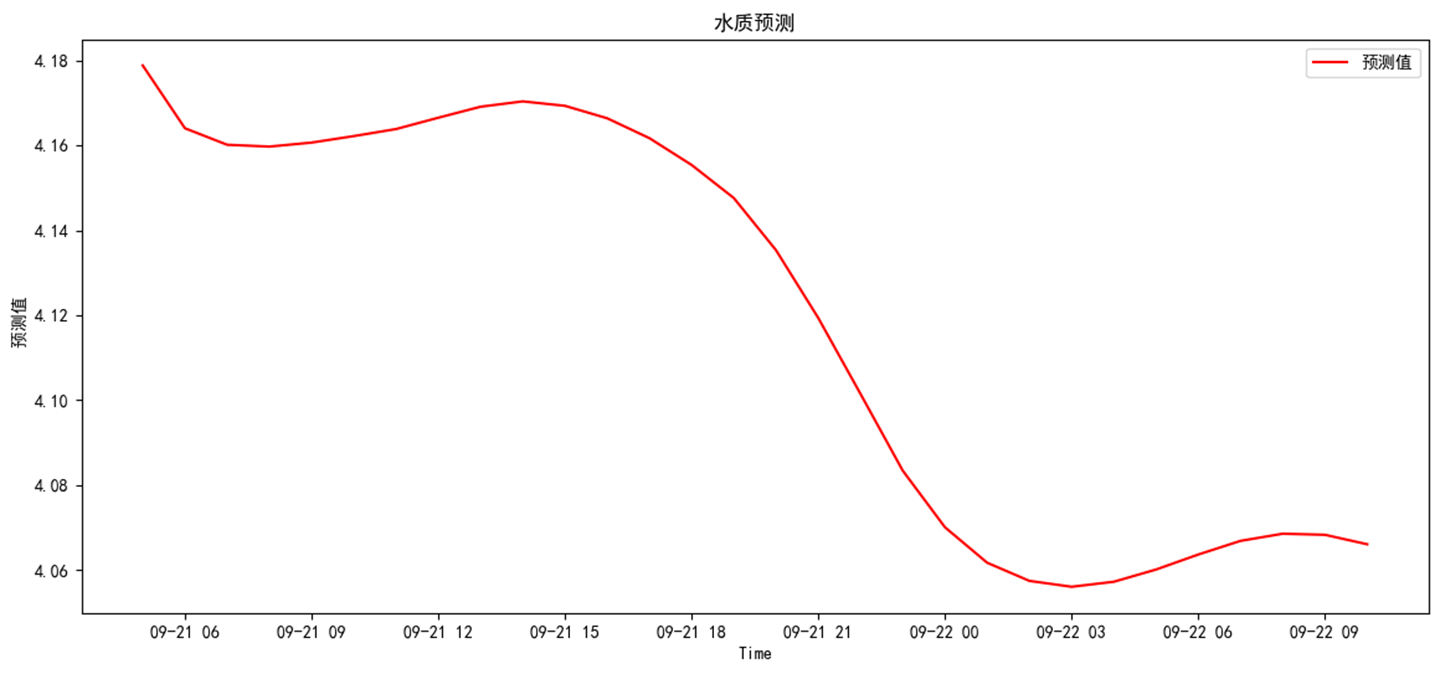
對未來的預測
模型可以自定義模型預測時長,本次以72小時為例。運行預測評價模塊
lstm2 = LSTMTimePredictor(dm2,test_ratio=0.2,n_past=72,p_step=1 )
lstm2.grid_search()
lstm2.evaluate()
lstm2.fig_predict()
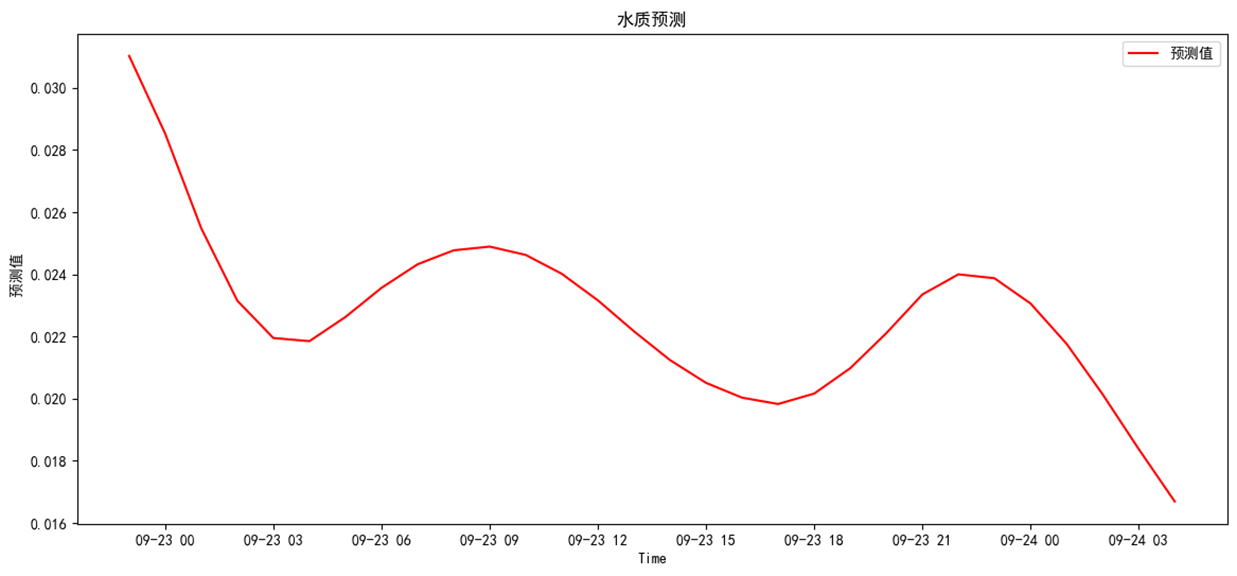
def fig_predict(self):"""查看數據概覽圖;"""df = self.predict()plt.figure(figsize=(14, 6))plt.plot(df, color="red", label="預測值")plt.xlabel("Time")plt.ylabel(" 預測值")plt.title("水質預測")plt.locator_params(axis="x", nbins=10)# plt.xticks(range(1,len(time_nu),48),rotation=45) # 刻度線顯示優化plt.legend()plt.show()
預測結果分別為,整體呈下降趨勢
3 應用場景及展望
LSTM作為成熟的神經網絡模型,可以實現多因子,連續時間序列預測,可以應用在有一定連續水質檢測數據的平臺上,預測結果較準確。因子關聯可根據實際情況選擇,例如上下游關系,機理關系等。
shuju ,與RNN一樣,LSTM隱藏層具有隨時間序列的重復節點。LSTM節點相較RNN更
為復雜,它將RNN中隱含層中的神經元替換為記憶體,以此實現序列信息的保留與長期記憶。TM是RNN的一種變體,與RNN一樣,LSTM隱藏層具有隨時間序列的重復節點。LSTM節點相較RNN更為復雜,它將RNN中隱含層中的神經元替換為記憶體,以此實現序列信息的保留與長期記憶。
短的的多連續適用于時記憶網絡(LSTM)應用
BY
如有幫助,請收藏點贊,如需引用轉載請注明出處。
微信公眾號:環境貓 er
CSDN:細節處有神明
個人博客:wallflowers (maoyu92.github.io)





函數詳解:能給萬物排序的神奇函數)




- 一元線性回歸模型)


)




FTP、NFS以及SAMBA服務)
創建項目)