應用層優化
Web服務器問題
尋找最優并發度
每個Web服務器都有一個最佳并發度——就是說,讓進程處理請求盡可能快,并且不超過系統負載的最優的并發連接數。這就是前面說的最大系統容量。進行一個簡單的測量和建模,或者只是反復試驗,就可以找到這個"神奇的數",為此花一些時間是值得的。
對于大流量的網站,Web服務器同一時刻處理上千個連接是很常見的。然而,只有一小部分連接需要進程實時處理。其他的可能是讀請求,處理文件上傳,填鴨式服務內容,或者只是等待客戶端的下一步請求。隨者并發的增加,服務器會逐漸到達它的最大吞吐量。在這之后,吞吐量通常開始降低,更重要的是,響應時間(延遲)也會i那位排隊而開始增加。為什么會這樣呢?試想,如果服務器只有一個CPU,同時接受到100個請求,,會發生什么事情呢?j假設CPU每秒能夠處理一個請求。即便理想情況下操作系統沒有調度的開銷,也沒有上下文切換的成本,那100個請求也需要CPU花費整整100s才能完成。
處理請求i的最好辦法是什么?可以將其一個個地排到隊列中,也可以并行地執行在不同請求之間切換,每次切換都給每個請求相同的服務時間。在這兩種情況下,吞吐量都是每秒處理一個請求。然而,如果使用隊列(并發=1),平均延時是50s,如果是并發執行(并發=100)則是100s。在實踐中,并發執行會使平均延時更高,主要是因為上下文切換的代價。
對于CPU密集型工作負載,最佳并發度等于CPU數量(或者CPU核數)。然而,進程并不總是處于可運行狀態的,因為會有一些阻塞式請求,例如IO、數據庫查詢,以及網絡請求。因此,最佳并發度通常會比CPU數量高一些。
可以預測最優并發度,但是這需要精確的分析。嘗試不同的并發值,看看在不增加響應時間的情況下的最大吞吐量是多少,或者測量真正的工作負載進行分析,這通常更容易。Percona Toolkit的pt-tcp-model工具可以幫助從TCP轉儲中測量和建模分析系統的可擴展性和性能特性。
緩存
緩存對高負載應用來說至關重要。一個典型的Web應用程序會提高大量的內容,直接生成這些內容的成本比采用緩存要高得多(包括檢查和緩存超時的開銷),所以采用緩存通常可以獲得數量級的性能提升。訣竅是找到正確的粒度和緩存過期策略組合。另外也需要決定哪些內容適合緩存,緩存在哪里。
典型的高負載應用會有很多層緩存。緩存并不僅僅發生在服務器上,而是在每一個環節,甚至包括用戶的Web瀏覽器(這就是內容過期頭的用處)。通常,緩存越接近客戶端,就越節省資源并且效率更高。從瀏覽器緩存提供一張圖片比從Web服務器的內容獲取快得多,而從服務器的內存讀取又比從服務器的磁盤上讀取好得多。每種類型的緩存有其不一樣的特點,例如容量和延時。
可以把緩存分成兩大類:被動緩存和主動緩存。被動緩存除了存儲和返回數據外不做任何事情。當從被動緩存請求一些內容時,要么可以得到結果,要么得到"結果不存在"。被動緩存的一個典型例子時memcached.相比之下,主動緩存會在訪問未命中時做一些額外的工作。通常會將請求轉發給應用的其他部分來生成請求結果,然后存儲該結果并返回給應用。Squid緩存代理服務器就是一個主動緩存。設計應用程序時,通常希望緩存是主動的(也可以叫做透明的),因為它們對應用隱藏了檢查——生成——存儲這個邏輯過程。也可以在被動緩存的前面構建一個主動緩存。
應用層以下的緩存
MySQL服務器有自己的內部緩存,但也可以構建你自己的緩存和匯總表。可以對緩存表量身定制,使他們最有效地過濾、排序、與其它表關聯、計數,或者用于其他用途。緩存表也比許多應用層緩存更持久,因為在服務器重啟后它們還存在。
緩存并不總是有用。
必需確認緩存真的可以提升性能,因為有時候緩存可能沒有任何幫助。例如,在實踐中發現從Nginx的內存中獲取內容比從緩存中代理中獲取要快,如果代理的緩存在磁盤上則尤其如此.
原因很簡單:緩存自身也有一些開銷。比如檢查緩存是否存在,如果命中則直接從緩存中返回數據。另外將緩存對象失效或者寫入新的緩存對象都會有開銷。緩存只在這些開銷比沒有緩存的情況下生成和提供數據的開銷少時才有用。如果直到所有這些操作的開銷,就可以計算出緩存能提供多少幫助。沒有緩存時的開銷就是每個請求生成數據的開銷。有緩存的開銷是檢查緩存的開銷加上緩存不命中的概率乘以生成數據的開銷,再加上緩存命中的概率乘以緩存提供數據的開銷。如果有緩存時的開銷比沒有時要低,則說明緩存可能有用,但依然不能保證。還要記住,就像從Nginx的內存中獲取數據比從代理在磁盤中的緩存獲取要好一樣,有些緩存的開銷比另外一些要低
應用層緩存
應用層緩存通常在同一臺機器的內存中存儲數據,或者通過網絡存在另一臺機器的內存中。因為應用可以緩存部分計算結果,所以應用緩存可能比更低層次的緩存更有效。因此應用層緩存可以節省兩方面的工作:獲取數據以及基于這些數據進行計算。一個很好的例子是HTML文本塊。應用程序可以生成例如頭條新聞的標題這樣的HTML片段,并且做好緩存。后續的頁面試圖就可以簡單地插入這個緩存過的文本。一般來說,在緩存數據前對數據做的處理越多,緩存命中節省的工作越多。
但應用層緩存也有缺點,那就是緩存命中率可能更低,并且可能使用較多的內存。假設需要50個不同版本的頭條新聞標題,以使不同地區生活的用戶看到不同的內容,那就需要足夠的內存去存儲全部50個版本,任何給定版本的標題命中次數都會更少,并且失效策略也會更加復雜。
應用緩存有許多種,下面是其中的一小部分:
1.本地緩存
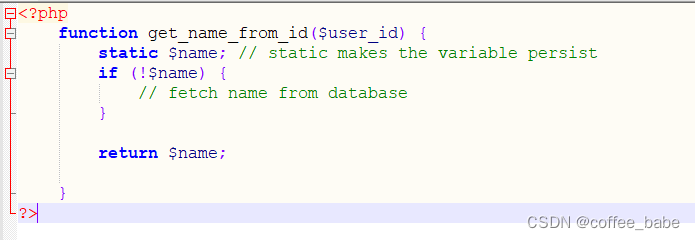
這種緩存通常很小,只在進程處理請求期間存在于進程內存中。本地緩存可以有效地避免對某些資源的重復請求。這種類型的緩存技術并不復雜:通常只是應用代碼中的一個變量或者哈希表。這種類型的緩存技術并不復雜:通常只是應用代碼中的一個變量或者哈希表。例如,假設需要顯式一個用戶名,而且已經直到其ID,就可以創建一個get_name_from_id()函數并且在其中增加緩存。像下面這樣:
<?php
function get_name_from_id($user_id) {
static $name; // static makes the variable persist
if (!$name) {
// fetch name from database
}return $name;}
?>
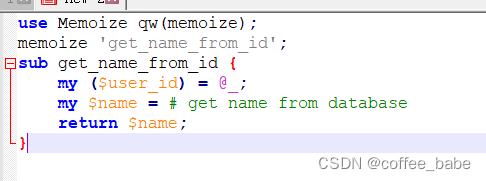
如果使用的是Perl,那么Memoize模塊是函數調用結果標準的緩存方式:
use Memoize qw(memoize);
memoize 'get_name_from_id';
sub get_name_from_id {
my ($user_id) = @_;
my $name = # get name from database
return $name;
}
新政)
服務端包含 合并拼裝靜態內容)





歐幾里得、DES、RSA、SHA-1算法)











