假如你正在使用關系型數據庫開發一款健康類系統。業務發展很好,系統有很多活躍的新老用戶,這些用戶會和平臺的醫生團隊進行交互,每天可能會生成數萬甚至數十萬級別的業務數據。這樣的話,隨著數據量越來越大,系統中的某些數據表的訪問就會出現瓶頸,最典型的就是用于保存用戶和醫生日常交流數據的健康咨詢表:

雖然從理論上講,像健康咨詢表這樣位于關系型數據庫中的單個表可以存儲的數據能夠達到億條級別,但這時候訪問性能就會變得很差。業界普遍認為,諸如MySQL這樣的主流數據庫,單表容量在千萬以下是一項最佳實踐,一旦超過這個量級,就需要考慮采用其他方案。那么問題就來了,我們如何應對日益增長的數據量呢?有沒有成熟的解決方案呢?
答案是肯定的,這就是我們接下來要引入的分庫分表技術。所謂分庫分表,你可以簡單理解為:將原來獨立的數據庫拆分成若干數據庫,將原來數據量大的單個表拆分成若干個數據表,使得單一數據庫、單一數據表的數據量變得足夠小,從而達到提升數據庫性能的效果。有時候,我們也把分庫分表統稱為是一種數據分片技術,因為從概念上講,無論是分庫還是分表,都是把一定數據劃分成不同的數據片,并存儲在不同的目標對象中。
講到這里,你實際上已經明確了一點,無論是分庫還是分表,本質上體現的都是一種對現有數據進行拆分的思想,而這種拆分思想又有兩種不同的實現策略,即垂直拆分和水平拆分:

相比水平拆分,垂直拆分相對比較容易理解和實現,所以我們先來討論這種拆分策略。在健康類系統中,用戶在查看健康咨詢表數據時,位于健康咨詢首頁的諸如咨詢編號、醫生編號等基礎數據的訪問頻率顯然要比咨詢詳情等明細數據更高,因為用戶總是先定位到基礎數據,然后再選擇某一個咨詢記錄并查看明細。基于這兩種數據的不同訪問特性,我們可以把健康咨詢這種單表進行拆分,根據訪問頻次來把咨詢數據分別放在兩張表中,如下所示:

由此可以,垂直分表的處理方式就是將一個表按照字段分成多張表,每個表存儲其中一部分字段。在實現上,我們通常會把諸如詳情類的低熱度數據放在一張獨立的表中。
通過垂直分表能得到來一定程度的性能提升,但畢竟拆分后的數據仍然都是位于同一個數據庫實例中,每個表還是會競爭同一臺數據庫服務器中的CPU、內存、網絡IO等資源,性能的提升限制很多。基于這一考慮,在有了垂直分表之后,我們就可以進一步引入垂直分庫。
讓我們回到案例,針對前面介紹的場景,分表之后的健康咨詢表同樣還是跟健康用戶表等其他數據表存放在同一臺服務器中。基于垂直分庫思想,這時候,我們就可以把健康咨詢相關的數據表單獨拆分出來,放在一個獨立的數據庫中,如下圖所示:

上圖的效果就是垂直分庫。從定義上講,垂直分庫是指將表進行分類,然后分布到不同的數據庫實例上。顯然,在高并發場景下,垂直分庫能夠一定程度的提升IO訪問效率和數據庫連接數,并降低單機硬件資源的瓶頸。
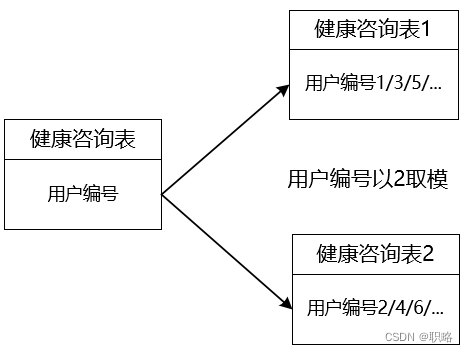
從前面的分析中我們不難明白,垂直拆分盡管實現起來比較簡單,但并不能解決單表數據量過大這一核心問題。所以,現實中我們往往需要在垂直拆分的基礎上再添加水平拆分機制。例如,我們可以對健康咨詢庫中的健康咨詢表數據按照用戶編號進行取模,然后分別存儲在不同的數據庫中,這就是水平分庫的常見做法,如下所示:

可以看到,水平分庫是把同一個表的數據按一定規則拆分到不同的數據庫實例中。如果采用了上圖中的水平分庫方案,系統復雜度就會比垂直分庫要高很多,因為我們就不得不面臨一個問題,即如何知道目標數據位于哪一個數據庫中呢?這就需要引入路由規則的概念。像上圖中根據“用戶編號以3取模”就是一條路由規則。
那么,我們如何來設計并實現這些路由規則呢?業界也存在一系列路由算法,常見的包括范圍限定算法、預定義算法以及前面介紹的取模算法:

參照水平分庫的思路,我們也可以對用戶庫中的用戶表進行水平拆分,效果如下所示。也就是說,水平分表是在同一個數據庫內,把同一個表的數據按一定規則拆到多個表中。
到現在為止,我們已經把分庫分表的基本概念梳理了一遍。你會發現這些概念理解起來并不是很復雜,但如何實現這些概念呢?你可以自己從零開始打造一套分庫分表的實現工具,但顯然并沒有看上去那么簡單,而我也不推薦你重復造輪子。幸好,目前業界已經存在一批分庫分表的實現方案,主要分成客戶端類分庫分表和代理服務類分庫分表兩大類,接下去我也來介紹一下。

所謂客戶端類分庫分表,相當于在使用數據庫的客戶端應用程序中就完成了數據分片的實現。針對這種方案,因為沒有獨立的服務器組件,所以結構上比較簡單。在Java世界中,通常做法會把客戶端分片相關的處理邏輯單獨抽離出來封裝成一個獨立的工具包,從而避免業務代碼和分庫分表邏輯過于耦合。而這個獨立工具包的構建方法通常就是覆寫現有的JDBC規范,這樣,業務開發人員還是使用與JDBC規范完全兼容的一套API來操作數據庫,但這套API的背后卻自動完成了分庫分表操作,效果如下:
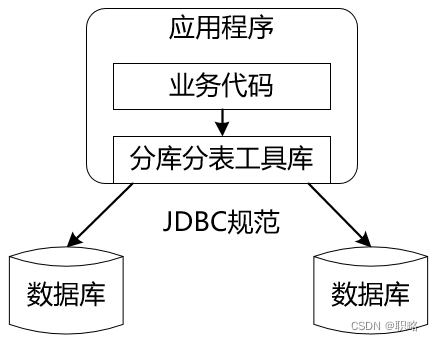
這種解決方案的優勢在于分庫分表操作對于業務而言是完全透明的。這樣,普通業務開發人員只需要理解JDBC規范就可以自行實現分庫分表,開發難度以及代碼維護成本得到降低。
另一方面,代理服務類分庫分表的解決方案也比較明確,顧名思義,就是采用了代理機制,也就是說在應用層和數據庫層之間添加一個代理層。有了代理層之后,對內我們就可以把分片規則集中維護在這個代理層中,對外則同樣提供與JDBC兼容的API給到應用層,其效果如下所示:
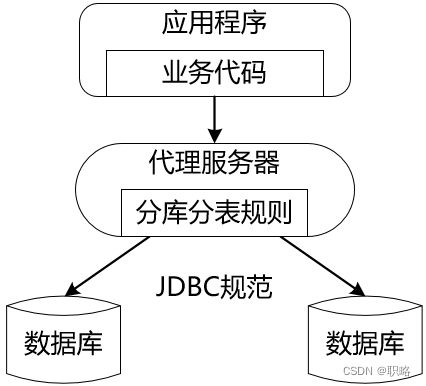
顯然,代理服務器分庫分表方案的優點在于解放了業務開發人員對分庫分表規則的管理工作,而缺點就是添加了一層代理層,一方面會因為新增了一層網絡傳輸而對性能產生一定的影響;另一方面,通常也需要專門的運維人員來確保代理服務器本身的穩定性。










)








