? ? ? ?語音的產生涉及器官的復雜協調,因此,語音包含了有關身體各個方面的信息,從認知狀態和心理狀態到呼吸條件。近十年來,研究者致力于發現和利用語音生物標志物——即與特定疾病相關的語音特征,用于診斷。隨著人工智能(AI)的進步,這些生物標志物的學習關聯和臨床預測變得更加可行。自動語音評估利用語音生物標志物、AI和移動技術進行遠程患者健康評估,預期將為早期識別和遠程監測帶來許多好處。
? ? 研究人員對將深度學習應用于自動語音評估,主要有兩種方法:
- 端到端訓練: 模型直接從音頻中做出臨床預測,但需要大量手動標注數據。
- 預訓練模型微調: 使用在大型語音語料庫上預訓練的深度學習模型作為特征提取器,并用少量標注數據進行微調。這種模型學習了一組特征,即表示,以捕獲語音的屬性,并可用于各種語音識別任務。
? ? ?語音表示捕獲了人類感知理解,并在語音中保持了一致的屬性,如說話者、語言、情感和年齡。由于語音包含了有關幾個重要器官狀況的豐富信息,隨著這些模型的興起,已有幾項工作探索并評估了它們在識別疾病方面的潛力。然而,深度學習模型缺乏可解釋性,這限制了它們在醫療領域的應用。為了解決這個問題,研究人員開發了工具來理解模型的工作原理,這些工具通常分為兩大類:白盒方法和黑盒方法。
- 白盒方法:這類方法通過分析數學關系來提供模型如何在特定情況下從輸入推斷輸出的局部解釋。通常需要特定的模型架構和屬性,例如激活函數的存在。在神經網絡中,有基于梯度的方法,如Grad-CAM和Integrated Gradient以及基于注意力的方法,如注意力流和注意力展開。
- 黑盒方法:這些方法系統地使用各種任務和數據探測模型,以估計其在一般情況中的行為,這被稱為全局解釋。雖然黑盒方法與模型無關,但也有一些方法如LIME和SHAP允許提供局部解釋。
1 方法論
1.1 數據選擇
? ? ? 本研究使用Saarbrücken語音數據庫,該數據庫包含來自1002名說話者的錄音,其中454名男性,548名女性,以及851名對照組(423名男性,428名女性)。
- 說話者的年齡從6歲到94歲不等(病理組),以及9歲到84歲(對照組)。
- 每個錄音會話包含/i/、/a/和/u/元音的中性、高、低、上升和下降音調的錄音,以及簡短短語“Guten Morgen, wie geht es Ihnen?”的錄音。
- 音頻以16位50kHz的采樣率使用專業錄音設備錄制。
- 將參與者按性別和病理狀態分組,病理狀態分為三類:有機、無機和健康。
- 僅選擇簡短短語的錄音,并將所有樣本下采樣到16kHz供模型使用。
1.2 模型訓練
? ? ? 使用Audio Spectrogram Transformer (AST),一種無卷積、純基于注意力機制的音頻分類模型。它通過將音頻轉換為頻譜圖來處理音頻數據,并使用視覺變換器(Vision Transformer,ViT)的架構來進行音頻分類任務。
- 模型輸入是t秒的音頻波形,將其填充到模型的最大尺寸T秒,并轉換為128維的log Mel濾波器組(fbank)特征序列,然后將其分割成16x16的塊,并使用線性投影層將其展平,生成768維的嵌入序列。
- 每個嵌入都添加了可訓練的位置嵌入(大小為768),以提供語譜圖的空間結構,并在序列的開頭添加了類別標記[CLS]嵌入(大小為768),并將其輸入到Transformer編碼器中。
- 編碼器在類別標記[CLS]處的輸出被提取為語音表示。
- 使用的模型在AudioSet上進行預訓練,并在HuggingFace Transformers中實現和提供。
- 訓練模型進行二元分類:病理(有機和無機)或健康受試者。
- 數據集按分層方式劃分為訓練集、開發集和測試集,比例為80%、10%和10%。
- 本研究比較了兩種模型配置:
ast_freeze: AST模型設置為不可訓練,并在模型頂部添加一個線性層,將嵌入投影到分類輸出。
ast_finetuned: 與ast_freeze的構建相同,但AST模型設置為可訓練,并對整個模型進行微調。
1.3 模型決策解釋
? ? ?本研究使用注意力回放方法可視化模型的決策過程。
- 該方法使用模型的注意力層生成相關圖,以可視化語譜圖區域的相關性分數。
- 通過將相關圖與語譜圖拼接成一個圖像,并用色調表示相關性分數,用亮度表示頻譜功率,從而可視化模型的注意力分布。
- 為了更好地理解語譜圖區域,本研究使用Montreal Force Aligner生成與音頻對應的語音音素標注,并將其添加到圖像中。
- 根據兩個模型的預測結果手動選擇樣本,分為四種情況:
O:ast_freeze和ast_finetuned都預測正確。
X:ast_freeze和ast_finetuned都預測錯誤。
A:ast_finetuned預測錯誤,ast_freeze預測正確。
B:ast_finetuned預測正確,ast_freeze預測錯誤。
2 結果
2.1 模型性能
下表顯示了模型的性能指標,包括:

- 加權平均召回率 (UAR):不考慮類別樣本大小的情況下,所有類別的平均召回率。
- ROC曲線下面積 (AUC):曲線衡量模型在不同分類閾值下的真正例率和假正例率。
與基礎AST模型相比,ast_finetuned模型具有更好的性能,表明微調對模型預測的改善作用。
2.2 分析
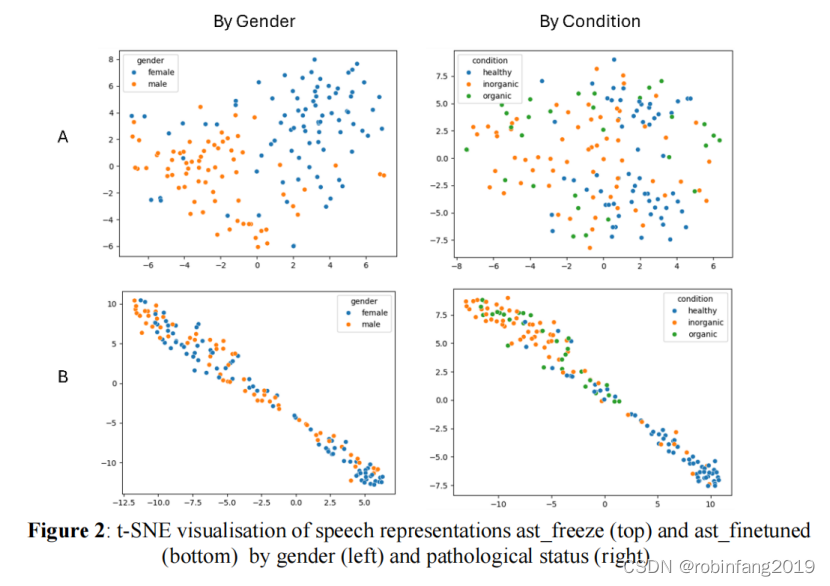
當基礎AST模型未完全訓練(A, ast_freeze)時,表示顯示出性別之間的分離而不是病理狀態(病理性與健康),換句話說,語音表示包含更多關于說話者性別而不是潛在聲音病理狀態的信息。另一方面,當基礎AST模型完全訓練(B, ast_finetuned)時,顯示出相反的趨勢。兩個模型都無法清晰地分離有機和無機病理。
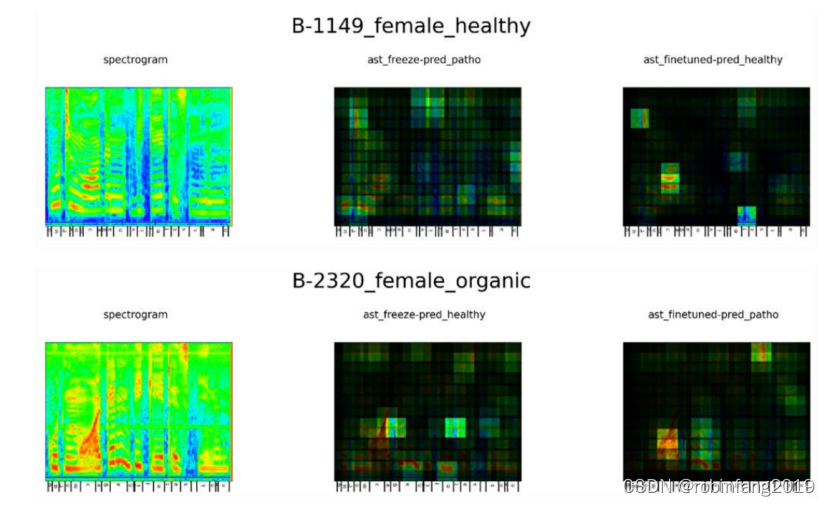
上圖展示了兩個女性語音樣本的頻譜圖(左)和ast_freeze(中)與ast_finetuned(右)的相關性圖(頂部:健康,底部:病理性):這兩個樣本的預測結果被標記為B,即ast_finetuned預測正確,而ast_freeze預測錯誤。
從可用的可視化中,我們可以看到最高相關性分數并不一定分配給最高強度區域,如基頻和諧波。在兩種模型中都出現的更常見模式是,它們給音素“/?/”和音段“/e/ /s/ /i/ /n/”更高的分數。當模型微調后,我們發現更多的集中度,位置經常改變/移動,然而,沒有得出明顯一致的模式。
? ? 本研究訓練和比較了兩種Audio Spectrogram Transformer (AST) 配置,用于語音障礙檢測,并使用注意力回放方法生成了模型的相關圖。
? ? 通過分析相關圖,發現模型無法完全識別有機和無機語音障礙之間的差異,并且模型對音素“/?/”和片段“/e/ /s/ /i/ /n/”給予更高的分數。
? ? 當模型進行微調時,發現注意力范圍往往會減少,這表明模型更加關注特定的音素區域。
3 模型配置
3.1 ast_freeze
- 模型類: ASTForAudioClassification
- 模型路徑: MIT/ast-finetuned-audioset-10-10-0.4593
- 類別數量: 2
- 凍結: TRUE
- 評估策略: epoch
- 保存策略: epoch
- 學習率: 0.001
- 每個設備訓練批次大小: 8
- 梯度累積步驟: 4
- 每個設備評估批次大小: 8
- 訓練周期數量: 10
- 預熱比率: 0.1
- 日志記錄步驟: 50
- 評估步驟: 50
- 推送到Hub: FALSE
- 移除未使用的列: FALSE
- 早停耐心: 5
- 早停閾值: 0
3.2 ast_finetuned
- 模型類: ASTForAudioClassification
- 模型路徑: MIT/ast-finetuned-audioset-10-10-0.4593
- 類別數量: 2
- 凍結: FALSE
- 評估策略: epoch
- 保存策略: epoch
- 學習率: 0.00025
- 每個設備訓練批次大小: 8
- 梯度累積步驟: 4
- 每個設備評估批次大小: 8
- 訓練周期數量: 40
- 預熱比率: 0.1
- 日志記錄步驟: 50
- 評估步驟: 50
- 推送到Hub: FALSE
- 移除未使用的列: FALSE
- 早停耐心: 8
- 早停閾值: 0


(圖形化界面手把手教學))
)


?詳細解讀文本分類、情感分析和機器翻譯的核心技術)



)


)





