提前注意:請注意路徑是否和我的相同,放置的位置不同,請修改標紅處?
HDFS部署
HDFS介紹及部署![]() http://t.csdnimg.cn/Q3H3Y
http://t.csdnimg.cn/Q3H3Y
部署說明
Hadoop HDFS分布式文件系統,我們會啟動:
NameNode進程作為管理節點
DataNode進程作為工作節點
SecondaryNamenode作為輔助
同理,Hadoop YARN分布式資源調度,會啟動:
ResourceManager進程作為管理節點
NodeManager進程作為工作節點
ProxyServer、JobHistoryServer這兩個輔助節點
那么,MapReduce呢?
?MapReduce運行在YARN容器內,無需啟動獨立進程
?所以關于MapReduce和YARN的部署,其實就是2件事情:
關于MapReduce: 修改相關配置文件,但是沒有進程可以啟動
關于YARN: 修改相關配置文件, 并啟動ResourceManager、NodeManager進程以及輔助進程(代理服務器、歷史服務器)。
通過表格進行匯總

集群規劃

?MapReduce配置文件
在 $HADOOP_HOME/etc/hadoop 文件夾內,修改:
mapred-env.sh文件,
添加如下
export JAVA_HOME=/export/server/jdk
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
mapred-site.xml文件
<configuration>
? <property>
? ? <name>mapreduce.framework.name</name>
? ? <value>yarn</value>
? ? <description></description>
? </property>? <property>
? ? <name>mapreduce.jobhistory.address</name>
? ? <value>node1:10020</value>
? ? <description></description>
? </property>
? <property>
? ? <name>mapreduce.jobhistory.webapp.address</name>
? ? <value>node1:19888</value>
? ? <description></description>
? </property>
? <property>
? ? <name>mapreduce.jobhistory.intermediate-done-dir</name>
? ? <value>/data/mr-history/tmp</value>
? ? <description></description>
? </property>
? <property>
? ? <name>mapreduce.jobhistory.done-dir</name>
? ? <value>/data/mr-history/done</value>
? ? <description></description>
? </property>
<property>
? <name>yarn.app.mapreduce.am.env</name>
? <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
? <name>mapreduce.map.env</name>
? <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
? <name>mapreduce.reduce.env</name>
? <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>
?YARN配置文件
?在 $HADOOP_HOME/etc/hadoop 文件夾內,修改:
?yarn-env.sh文件
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
?
?yarn-site.xml文件
?
<configuration>
<property>
? ? <name>yarn.resourcemanager.hostname</name>
? ? <value>node1</value>
? ? <description></description>
? </property><property>
? ? <name>yarn.nodemanager.local-dirs</name>
? ? <value>/data/nm-local</value>
? ? <description>Comma-separated list of paths on the local filesystem where intermediate data is written.</description>
? </property>? <property>
? ? <name>yarn.nodemanager.log-dirs</name>
? ? <value>/data/nm-log</value>
? ? <description>Comma-separated list of paths on the local filesystem where logs are written.</description>
? </property><property>
? ? <name>yarn.nodemanager.aux-services</name>
? ? <value>mapreduce_shuffle</value>
? ? <description>Shuffle service that needs to be set for Map Reduce applications.</description>
? </property><property>
? ? <name>yarn.log.server.url</name>
? ? <value>http://node1:19888/jobhistory/logs</value>
? ? <description></description>
</property>? <property>
? ? <name>yarn.web-proxy.address</name>
? ? <value>node1:8089</value>
? ? <description>proxy server hostname and port</description>
? </property>
? <property>
? ? <name>yarn.log-aggregation-enable</name>
? ? <value>true</value>
? ? <description>Configuration to enable or disable log aggregation</description>
? </property>? <property>
? ? <name>yarn.nodemanager.remote-app-log-dir</name>
? ? <value>/tmp/logs</value>
? ? <description>Configuration to enable or disable log aggregation</description>
? </property>
? <property>
? ? <name>yarn.resourcemanager.scheduler.class</name>
??<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
? ? <description></description>
? </property>??<property>
? ? <name>yarn.nodemanager.log.retain-seconds</name>
? ? <value>10800</value>
? ? <description>Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.</description>
? </property>
</configuration>
?解釋:

?MapReduce和YARN的配置文件修改好后,需要分發到其它的服務器節點中。
分發
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node2:`pwd`/
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node3:`pwd`/
分發完成配置文件,就可以啟動YARN的相關進程啦。
?集群啟動命令介紹
?常用的進程啟動命令如下:
一鍵啟動YARN集群:
$HADOOP_HOME/sbin/start-yarn.sh
會基于yarn-site.xml中配置的yarn.resourcemanager.hostname來決定在哪臺機器上啟動resourcemanager
會基于workers文件配置的主機啟動NodeManager
一鍵停止YARN集群:
$HADOOP_HOME/sbin/stop-yarn.sh
在當前機器,單獨啟動或停止進程
$HADOOP_HOME/bin/yarn --daemon start|stop resourcemanager|nodemanager|proxyserver
start和stop決定啟動和停止
可控制resourcemanager、nodemanager、proxyserver三種進程
歷史服務器啟動和停止
$HADOOP_HOME/bin/mapred --daemon start|stop historyserver
獨立進程啟停可用
$HADOOP_HOME/bin/yarn --daemon
控制resourcemanager、nodemanager、proxyserver
$HADOOP_HOME/bin/mapred --daemon
控制historyserver?
?開始啟動YARN集群
?在node1服務器,以hadoop用戶執行
?首先執行:
$HADOOP_HOME/sbin/start-yarn.sh
 ?
?
一鍵啟動所需的: ResourceManager NodeManager ProxyServer(代理服務器)
?其次執行:?
$HADOOP_HOME/bin/mapred --daemon start historyserver
?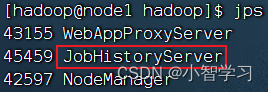
啟動: HistoryServer(歷史服務器)
?jps
查看java進程

查看YARN的WEB UI頁面
打開 http://node1:8088 即可看到YARN集群的監控頁面(ResourceManager的WEB UI)
 在最后,可以給虛擬機打上快照,保存安裝狀態
在最后,可以給虛擬機打上快照,保存安裝狀態
提交MapReduce程序至YARN運行?
?在部署并成功啟動YARN集群后,我們就可以在YARN上運行各類應用程序了。
們目前先來體驗一下在YARN上執行MapReduce程序的過程。?
?Hadoop官方內置了一些預置的MapReduce程序代碼,我們無需編程,只需要通過命令即可使用。
常用的有2個MapReduce內置程序:
wordcount:單詞計數程序。 統計指定文件內各個單詞出現的次數
pi:求圓周率 通過蒙特卡羅算法(統計模擬法)求圓周率
?這些內置的示例MapReduce程序代碼,都在: ?$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar 這個文件內。
可以通過 hadoop jar 命令來運行它,提交MapReduce程序到YARN中。
語法:
hadoop jar 程序文件 java類名 [程序參數] ... [程序參數]
?提交wordcount示例程序
?單詞計數示例程序的功能很簡單:
給定數據輸入的路徑(HDFS)、給定結果輸出的路徑(HDFS)
將輸入路徑內的數據中的單詞進行計數,將結果寫到輸出路徑
我們可以準備一份數據文件,并上傳到HDFS中。
?請隨意填寫內容,假設文件為words.txt,上傳到HDFS
hadoop fs -mkdir -p /input/wordcount
hadoop fs -mkdir /output
hadoop fs -put words.txt /input/wordcount/
執行如下命令,提交示例MapReduce程序WordCount到YARN中執行
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount hdfs://node1:8020/input/wordcount/ hdfs://node1:8020/output/wc1
?注意: 參數wordcount,表示運行jar包中的單詞計數程序(Java Class)
參數1是數據輸入路徑(hdfs://node1:8020/input/wordcount/)
參數2是結果輸出路徑(hdfs://node1:8020/output/wc1), 需要確保輸出的文件夾不存在
?提交程序后,可以在YARN的WEB UI頁面看到運行中的程序(http://node1:8088/cluster/apps)
? 執行完成后,可以查看HDFS上的輸出結果
執行完成后,可以查看HDFS上的輸出結果
?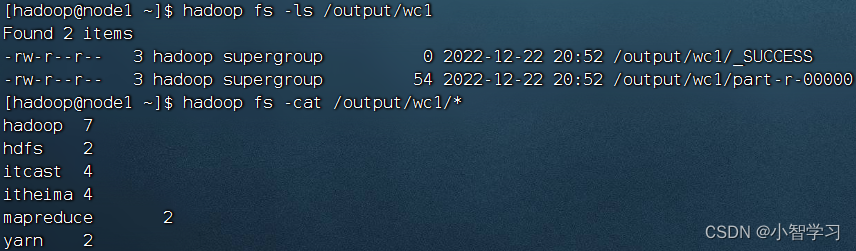
_SUCCESS文件是標記文件,表示運行成功,本身是空文件
part-r-00000,是結果文件,結果存儲在以part開頭的文件中?
?執行完成后,可以借助歷史服務器查看到程序的歷史運行信息 ps:如果沒有啟動歷史服務器和代理服務器,此操作無法完成(頁面信息由歷史服務器提供,鼠標點擊跳轉到新網頁功能由代理服務器提供)
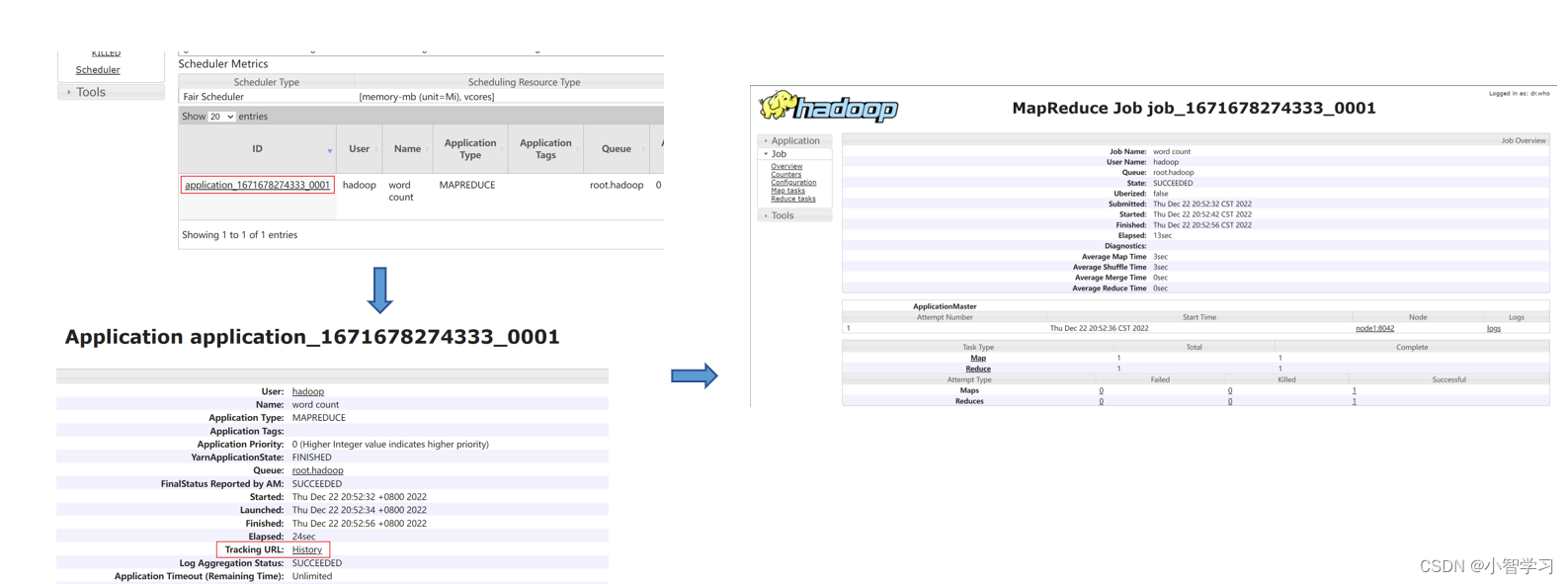
?查看運行日志
?點擊logs鏈接,可以查看到詳細的運行日志信息。 此功能基于:
1. 配置文件中配置了日志聚合功能,并設置了歷史服務器
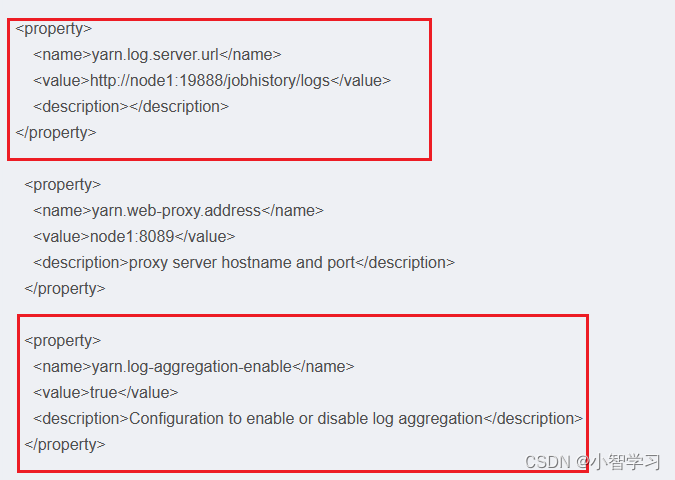
2. 啟動了代理服務器和歷史服務器
3. 歷史服務器進程會將日志收集整理,形成可以查看的網頁內容供我們查看。
所以,如果發現無法查看程序運行歷史以及無法查看程序運行日志信息,請檢查上述1、2、3是否都正確設置。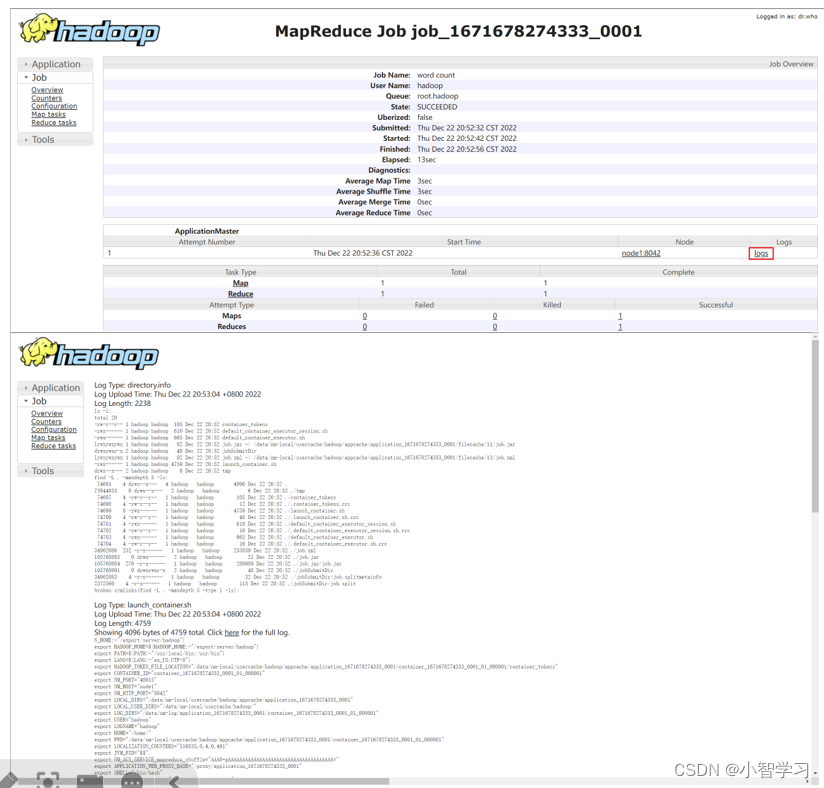


)
)


)

)










)