基本原理:
Transformer 的核心概念是 自注意力機制(Self-Attention Mechanism),它允許模型在處理每個輸入時“關注”輸入序列的不同部分。這種機制讓模型能夠理解每個單詞或符號與其他單詞或符號之間的關系,而不是逐個地線性處理輸入。
Transformer 主要由兩個部分組成:
編碼器(Encoder):將輸入序列轉換為一個隱表示(向量表示)。
解碼器(Decoder):從隱表示生成輸出序列。
編碼器 和 解碼器 都由多個 層(layers) 組成,每層都包括一個 自注意力機制 和一個 前饋神經網絡(Feed-Forward Neural Network, FFN)。
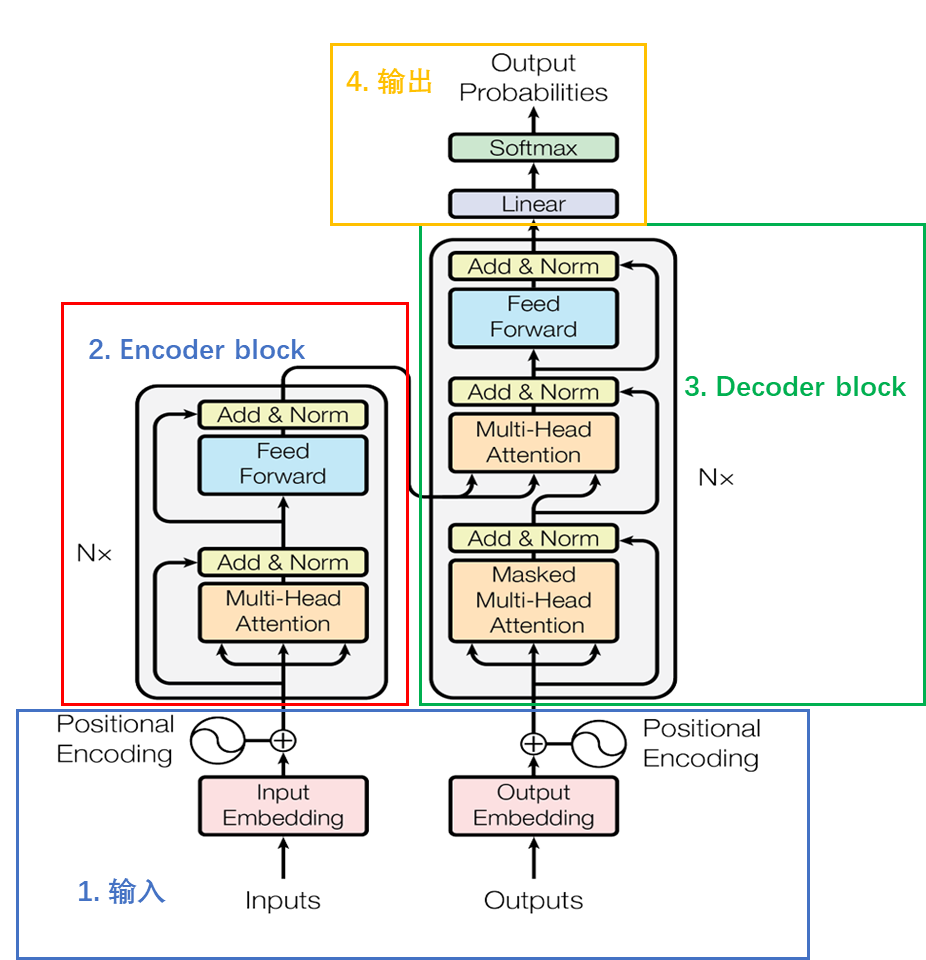
整體組成:
Encoder block由6個encoder堆疊而成,一個Encoder由兩個子層組成,即Multi-Head Attention和全連接神經網絡Feed Forward Network,每個子層都采用了殘差連接的結構,后面接一個layer_norm層。
Decoder block由6個decoder堆疊而成,一個Decoder包含兩個 Multi-Head Attention 層。第一個 Multi-Head Attention 層采用了 Masked 操作。第二個 Multi-Head Attention 層的K, V















類加載器)

9)

)