【省流:打算直接測試效果的可以訪問這個網址】
http://decaptcha.ai?project_name=netease_zh_overlap
【實現方案】
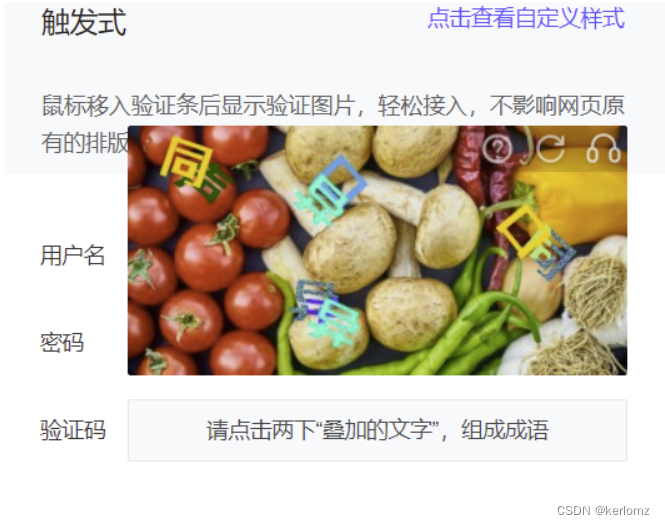
如圖所示,我們能看到,比起以往的“單個字”語序點選,這個驗證碼的難點在于“重疊漢字“,我們知道,一般的深度學習訓練單個漢字的圖像分類,我們假設一般的漢字常用字有3500個漢字。我們的輸出層維度一般是(1, 3500)
而對于重疊漢字的問題,我們有兩種建模形態,一種是兩個重疊的字作為一個整體,另一種是把兩個重疊的漢字分開,作為兩個獨立的分類任務。
我當前選擇的方案是前者,作為一個整體,為什么我不選擇后者呢?因為后者的重疊目標雖然區分開來,但是遮擋部分的特征太過隨機了,對于下層漢字被遮擋缺失的特征,很難識別出來具體的內容,而如果我們把它作為一個整體看待,我們特征既提取了上層漢字的特征,也能利用上層的特征推測下層漢字被遮擋部分的特征的可能性,能夠幫助網絡更加精準的推測出來具體的內容。
那么我們把大致的方向確立好了之后,就可以開始進一步的方案設計了,我們已經確立了把兩個重疊的漢字作為一個整體之后,我們就需要開始考慮如何對兩個漢字的識別建模了,首先我們有以下幾種方案的選擇:
- 作為多標簽分類,建模就是(1, 3500)一樣的輸出,只不過值是0-1范圍,作為概率,那么兩個重疊的漢字概率可以設置為0.5,0.5,或者1, 1。其余的分類都是0,如果我們使用這種方式建模,那么我們會遇到一個問題,因為絕大多數分類都是0,模型很容易收斂,即使忽略我們1的部分,損失一樣可以很小,在數學層面上,使用BCE損失很難達到預測出來我們需要的兩個重疊漢字的目的,所以我們需要對損失函數進行改進,設計一種能夠針對極端的正負樣本不平衡情況的損失函數。需要標注每張圖中的兩個漢字的內容,標注成本一般。
- 第二種就是我們把它作為兩個獨立的分類情況,區分上下層,建模就是(1, 2, 3500)這樣的話,我們可以把它作為兩個獨立的多分類任務,只不過這種方案對于標注的要求很高,需要區分上下層,人工外包單獨標注單個樣本的時候如果沒有其他組圖進行范圍參照的話,錯誤率挺高。
- 我們可以端到端的把四組圖作為一個批次的輸入(batch_size, 4, 224, 224, 3),這樣能夠加強每一組圖彼此之間的約束,我們的輸出可以有多個,結合上面兩種方案,順序輸出:(batch_size, 4,2,4),分類輸出(batch_size, 4,2, 3500)/(batch_size, 4,3500)。對于端到端的順序輸出,如果我們加入一個小型語言模型的多模態,或者直接單獨訓練這個語言模型再嵌入端到端模型中,都可以達到比較好的端到端效果,因為現實中我們挺難直接從樣本中獲取到盡可能多的成語的可能,我們單獨訓練語料庫的難度更低一些。網上有很多開源的語料庫可以下載作為訓練樣本。如果我們只保留順序輸出的話,樣本的成本最低,只需要對接人工標注平臺打碼的同時,采集驗證通過的圖,我們就能通過得到的順序坐標,結合一點點(500-1000張左右)目標檢測的成本,推理出四組圖的順序,自動化產生樣本標注。
有了以上的思路,我們嘗試實現它:
def forward(self, inputs):batch_size, num_images, height, width, channel = inputs.size()predictions = self.core_net(inputs.view(batch_size, num_images, height, width, channel))predictions = predictions.view(batch_size, num_images, self.core_num_classes)embedded = self.embedding(predictions)batch_size, num_groups, embedding_dim = embedded.size()suit_gru, _ = self.pair_gru(embedded)global_gru, hidden_gru = self.global_gru(suit_gru)hidden_gru = hidden_gru.permute(1, 0, 2).contiguous()hidden_gru = hidden_gru.view(batch_size, self.hidden_dim)ranks = self.rank_dense(hidden_gru)ranks = ranks.view(batch_size, 2, num_groups).sigmoid()return ranks
再根據我們選擇的建模方案,來設計它對應的損失函數,可以根據我們已知的信息增加多維度的約束,比如我們得到的排序結果的因果關系,結果本身的取值范圍的數學規律,場景中存在的某些隱性規則,我們都可以把它作為損失中的加權的影響因子。如果是使用多標簽分類我們甚至可以設計一個專用的topk2損失。
除此之外,我們可以使用增強手段,比如把標注的樣本相同標注的可以隨機配對組合成語,作為一組新的樣本等等,損失計算也可以設計階梯式,引導網絡先學習某個容易學習的特征,學習好了再學習另一個特征,加速模型收斂。







類加載器)

9)

)



Vue Router之路由守衛)



專業版怎么樣,值得購買嗎?)