Scrapy綜述
Scrapy總體架構?
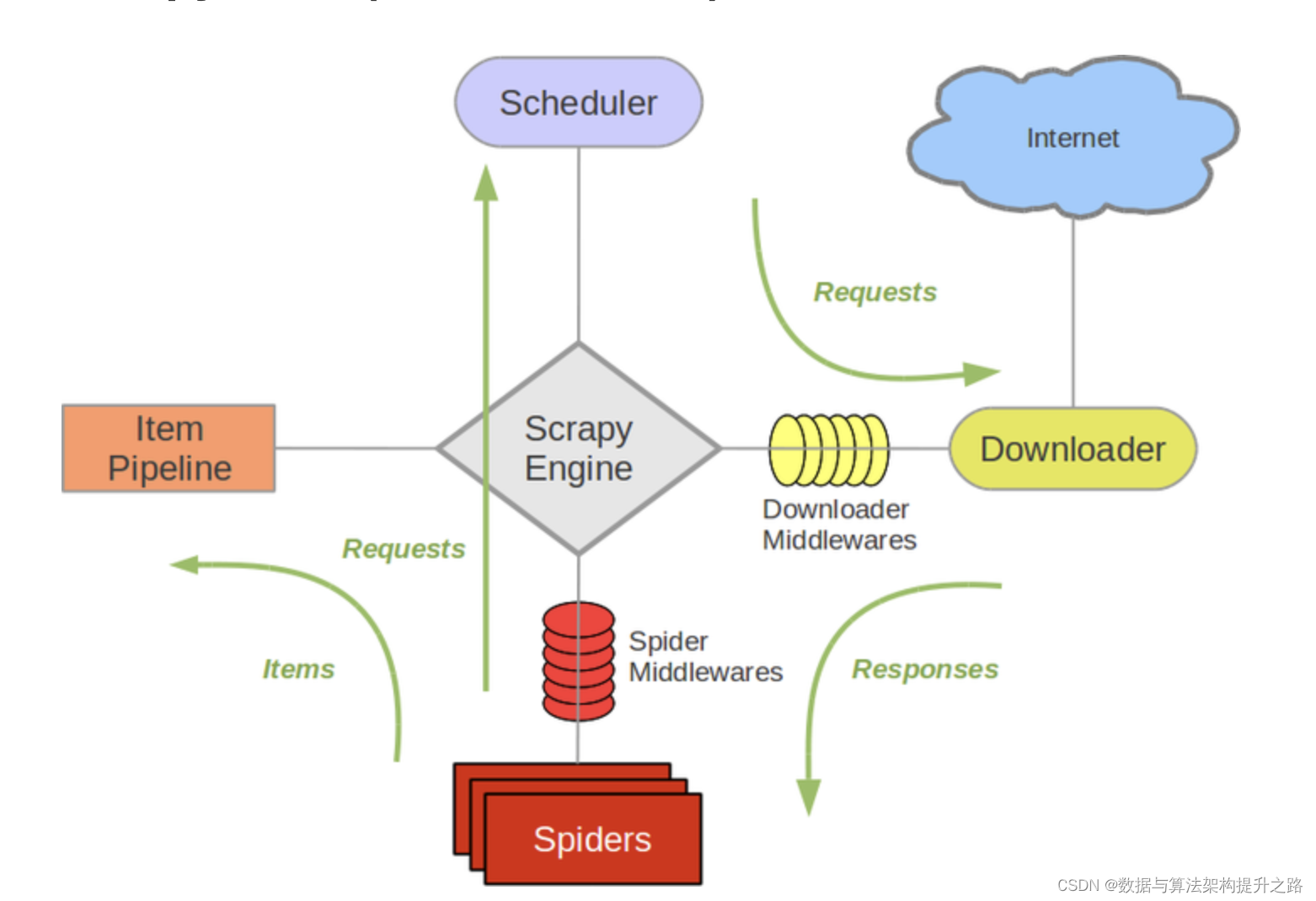
適用于海量靜態頁面的數據下載?
-
Scrapy Engine(引擎): 負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊,信號、數據傳遞等。 -
Scheduler(調度器): 它負責接受引擎發送過來的Request請求,并按照一定的方式進行整理排列,入隊,當引擎需要時,交還給引擎。 -
Downloader(下載器):負責下載Scrapy Engine(引擎)發送的所有Requests請求,并將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理, -
Spider(爬蟲):它負責處理所有Responses,從中分析提取數據,獲取Item字段需要的數據,并將需要跟進的URL提交給引擎,再次進入Scheduler(調度器), -
Item Pipeline(管道):它負責處理Spider中獲取到的Item,并進行進行后期處理(詳細分析、過濾、存儲等)的地方. -
Downloader Middlewares(下載中間件):你可以當作是一個可以自定義擴展下載功能的組件。 -
Spider Middlewares(Spider中間件):你可以理解為是一個可以自定擴展和操作引擎和Spider中間通信的功能組件(比如進入Spider的Responses;和從Spider出去的Requests)
Scrapy的運作流程
代碼寫好,程序開始運行...
-
引擎:Hi!Spider, 你要處理哪一個網站? -
Spider:老大要我處理xxxx.com。 -
引擎:你把第一個需要處理的URL給我吧。 -
Spider:給你,第一個URL是xxxxxxx.com。 -
引擎:Hi!調度器,我這有request請求你幫我排序入隊一下。 -
調度器:好的,正在處理你等一下。 -
引擎:Hi!調度器,把你處理好的request請求給我。 -
調度器:給你,這是我處理好的request -
引擎:Hi!下載器,你按照老大的下載中間件的設置幫我下載一下這個request請求 -
下載器:好的!給你,這是下載好的東西。(如果失敗:sorry,這個request下載失敗了。然后引擎告訴調度器,這個request下載失敗了,你記錄一下,我們待會兒再下載) -
引擎:Hi!Spider,這是下載好的東西,并且已經按照老大的下載中間件處理過了,你自己處理一下(注意!這兒responses默認是交給def parse()這個函數處理的) -
Spider:(處理完畢數據之后對于需要跟進的URL),Hi!引擎,我這里有兩個結果,這個是我需要跟進的URL,還有這個是我獲取到的Item數據。 -
引擎:Hi !管道?我這兒有個item你幫我處理一下!調度器!這是需要跟進URL你幫我處理下。然后從第四步開始循環,直到獲取完老大需要全部信息。 -
管道``調度器:好的,現在就做!
注意!只有當調度器中不存在任何request了,整個程序才會停止,(也就是說,對于下載失敗的URL,Scrapy也會重新下載。)
Scrapy項目結構
Scrapy ? ? ? ? ? 2.11.2
Python? ? ? ? ? ?3.10.x
scrapy startproject tencent_job
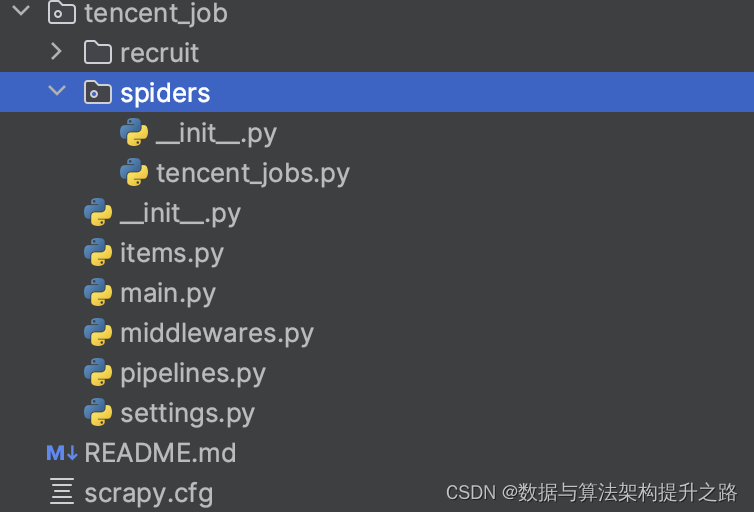
scrapy.cfg :項目的配置文件
tencent_job/ :項目的Python模塊,將會從這里引用代碼
tencent_job/items.py :項目的目標文件
tencent_job/pipelines.py :項目的管道文件
tencent_job/settings.py :項目的設置文件
tencent_job/spiders/ :存儲爬蟲代碼目錄
核心概念
Spider
Spider類定義了如何爬取某個(或某些)網站。包括了爬取的動作(例如:是否跟進鏈接)以及如何從網頁的內容中提取結構化數據(爬取item)。 換句話說,Spider就是您定義爬取的動作及分析某個網頁(或者是有些網頁)的地方。
class scrapy.Spider是最基本的類,所有編寫的爬蟲必須繼承這個類。
主要用到的函數及調用順序為:
__init__()?: 初始化爬蟲名字和start_urls列表
start_requests() 調用make_requests_from url():生成Requests對象交給Scrapy下載并返回response
parse()?: 解析response,并返回Item或Requests(需指定回調函數)。Item傳給Item pipline持久化 , 而Requests交由Scrapy下載,并由指定的回調函數處理(默認parse()),一直進行循環,直到處理完所有的數據為止。
CrawlSpiders
CrawlSpider類定義了一些規則(rule)來提供跟進link的方便的機制,從爬取的網頁中獲取link并繼續爬取的工作更適合。
通過下面的命令可以快速創建 CrawlSpider模板 的代碼:
scrapy genspider -t crawl tencent tencent.com
Item Pipeline
當Item在Spider中被收集之后,它將會被傳遞到Item Pipeline,這些Item Pipeline組件按定義的順序處理Item。
每個Item Pipeline都是實現了簡單方法的Python類,比如決定此Item是丟棄而存儲。以下是item pipeline的一些典型應用:
- 驗證爬取的數據(檢查item包含某些字段,比如說name字段)
- 查重(并丟棄)
- 將爬取結果保存到文件或者數據庫中
process_request(self, request, spider)
-
當每個request通過下載中間件時,該方法被調用。
-
process_request() 必須返回以下其中之一:一個 None 、一個 Response 對象、一個 Request 對象或 raise IgnoreRequest:
-
如果其返回 None ,Scrapy將繼續處理該request,執行其他的中間件的相應方法,直到合適的下載器處理函數(download handler)被調用, 該request被執行(其response被下載)。
-
如果其返回 Response 對象,Scrapy將不會調用 任何 其他的 process_request() 或 process_exception() 方法,或相應地下載函數; 其將返回該response。 已安裝的中間件的 process_response() 方法則會在每個response返回時被調用。
-
如果其返回 Request 對象,Scrapy則停止調用 process_request方法并重新調度返回的request。當新返回的request被執行后, 相應地中間件鏈將會根據下載的response被調用。
-
如果其raise一個 IgnoreRequest 異常,則安裝的下載中間件的 process_exception() 方法會被調用。如果沒有任何一個方法處理該異常, 則request的errback(Request.errback)方法會被調用。如果沒有代碼處理拋出的異常, 則該異常被忽略且不記錄(不同于其他異常那樣)。
-
-
參數:
request (Request 對象)?– 處理的requestspider (Spider 對象)?– 該request對應的spider
process_response(self, request, response, spider)
當下載器完成http請求,傳遞響應給引擎的時候調用
-
process_request() 必須返回以下其中之一: 返回一個 Response 對象、 返回一個 Request 對象或raise一個 IgnoreRequest 異常。
-
如果其返回一個 Response (可以與傳入的response相同,也可以是全新的對象), 該response會被在鏈中的其他中間件的 process_response() 方法處理。
-
如果其返回一個 Request 對象,則中間件鏈停止, 返回的request會被重新調度下載。處理類似于 process_request() 返回request所做的那樣。
-
如果其拋出一個 IgnoreRequest 異常,則調用request的errback(Request.errback)。 如果沒有代碼處理拋出的異常,則該異常被忽略且不記錄(不同于其他異常那樣)。
-
-
參數:
request (Request 對象)?– response所對應的requestresponse (Response 對象)?– 被處理的responsespider (Spider 對象)?– response所對應的spider
防止爬蟲被反主要策略
有些些網站使用特定的不同程度的復雜性規則防止爬蟲訪問,繞過這些規則是困難和復雜的,有時可能需要特殊的基礎設施
-
動態設置User-Agent(隨機切換User-Agent,模擬不同用戶的瀏覽器信息)
-
禁用Cookies(也就是不啟用cookies middleware,不向Server發送cookies,有些網站通過cookie的使用發現爬蟲行為)
- 可以通過
COOKIES_ENABLED?控制 CookiesMiddleware 開啟或關閉
- 可以通過
-
設置延遲下載(防止訪問過于頻繁,設置為 2秒 或更高)
-
Google Cache 和 Baidu Cache:如果可能的話,使用谷歌/百度等搜索引擎服務器頁面緩存獲取頁面數據。
-
使用IP地址池:VPN和代理IP,現在大部分網站都是根據IP來ban的。
-
使用?Crawlera(專用于爬蟲的代理組件),正確配置和設置下載中間件后,項目所有的request都是通過crawlera發出。
DOWNLOADER_MIDDLEWARES = {'scrapy_crawlera.CrawleraMiddleware': 600}CRAWLERA_ENABLED = TrueCRAWLERA_USER = '注冊/購買的UserKey'CRAWLERA_PASS = '注冊/購買的Password'
設置下載中間件
下載中間件(Downloader Middlewares)在Scrapy架構中扮演著至關重要的角色,主要功能是在Scrapy的請求(Request)和響應(Response)處理過程中提供一個可插拔的鉤子系統。這允許開發者在請求發送到服務器以及服務器返回響應的過程中插入自定義的處理邏輯。?
下載中間件是處于引擎(crawler.engine)和下載器(crawler.engine.download())之間的一層組件,可以有多個下載中間件被加載運行。
-
當引擎傳遞請求給下載器的過程中,下載中間件可以對請求進行處理 (例如增加http header信息,增加proxy信息等);
-
在下載器完成http請求,傳遞響應給引擎的過程中, 下載中間件可以對響應進行處理(例如進行gzip的解壓等)
下載中間件在Scrapy項目的settings.py文件中配置。您需要在DOWNLOADER_MIDDLEWARES設置中添加自定義中間件類,并分配一個整數值來確定它們的執行順序。數值越小,中間件越早執行
這里是一個例子:
DOWNLOADER_MIDDLEWARES = {'mySpider.middlewares.MyDownloaderMiddleware': 543,
}
編寫下載器中間件十分簡單。每個中間件組件是一個定義了以下一個或多個方法的Python類:
class scrapy.contrib.downloadermiddleware.DownloaderMiddleware爬取騰訊工作的項目實戰?
sevnce-crawler: 爬蟲相關技術 - Gitee.com
scrapy爬取招聘網站數據實戰
相關資料
聚焦Python分布式爬蟲必學框架Scrapy打造搜索引擎(二)-CSDN博客
Python的Requests來爬取今日頭條的圖片和文章_cookie池維護-CSDN博客
鏈接: 百度網盤 提取碼: qc48?

















)

