目錄
Spark的任務執行流程
Spark的運行流程
Spark的作業運行流程是怎么樣的?
Spark的特點
Spark源碼中的任務調度
Spark作業調度
Spark的架構
Spark的使用場景
Spark on standalone模型、YARN架構模型(畫架構圖)
Spark的yarn-cluster涉及的參數有哪些?
Spark提交job的流程
Spark的階段劃分
Spark處理數據的具體流程說下
Sparkjoin的分類
Spark map join的實現原理
Spark的任務執行流程
Apache Spark 的任務執行流程主要分為以下幾個階段:
1. 初始化與作業提交
創建SparkContext:Spark應用程序啟動時,首先創建一個SparkContext,這是Spark與集群資源管理器(如YARN或Mesos)交互的入口點。
作業提交:用戶編寫好Spark應用后,通過SparkContext提交到Spark集群。提交過程包括解析作業、依賴分析等。
2. DAG構建與優化
RDD(彈性分布式數據集)鏈:Spark應用的核心是通過一系列轉換(Transformation)操作構建出RDD鏈。
DAG(有向無環圖)生成:Spark將這些轉換操作轉化為DAG,每個節點代表一個操作,邊表示數據依賴關系。
DAG優化:Spark會對DAG進行優化,比如消除無效操作、重排操作以減少shuffle等,生成優化后的執行計劃。
3. 任務調度
Stage劃分:根據RDD之間的依賴關系,Spark將DAG劃分為多個Stage。寬依賴(如shuffle)處切分,窄依賴則在同一Stage內。
Task生成:每個Stage被進一步劃分為多個Task,Task是最小的計算單元,運行在Executor上。
Task調度:Spark的調度器(默認采用FIFO策略,也可以配置為Fair策略)負責將Task分配給各個Worker節點上的Executor執行。
4. 任務執行
Executor執行Task:Executor接收來自Driver的Task,讀取或計算所需的數據,執行計算任務。
數據 Shuffle:在有寬依賴的Stage間,數據需要重新分布(Shuffle),這一步通常涉及磁盤I/O和網絡傳輸,是性能瓶頸之一。
結果聚合:每個Stage的輸出可能需要進一步聚合,直到最終結果被計算出來。
5. 結果返回與清理
結果收集:最后的Stage計算出的結果會通過網絡返回給Driver程序。
SparkContext關閉:當應用程序執行完畢,SparkContext會被關閉,釋放所有資源。
日志與監控:Spark提供豐富的日志和Web UI供開發者監控任務執行狀態和性能指標。
整個流程體現了Spark的高效執行模型,尤其是其基于內存計算的能力和對迭代式計算的優化,使得Spark在大數據處理場景下表現出色。
Spark的運行流程
Spark的運行流程大致可以概括為以下幾個步驟:
啟動與初始化:
用戶提交Spark應用時,首先會啟動一個Driver進程。Driver是Spark應用的主程序,負責管理和協調整個應用的執行。
Driver啟動后,會創建一個SparkContext實例,它是Spark與底層集群資源管理器(如YARN、Mesos或Standalone)進行交互的主要接口。SparkContext負責向資源管理器注冊應用并請求執行資源。
資源分配與Executor啟動:
資源管理器接收到請求后,會為該應用分配必要的資源,如CPU核心和內存。
根據分配的資源,在各個Worker節點上啟動Executor進程。Executor是真正執行任務的工作者進程,它們負責運行任務并存儲數據。
構建DAG與Stage劃分:
Spark會根據用戶的代碼邏輯構建一個DAG(有向無環圖),表示RDD之間的依賴關系。
根據DAG中的寬依賴,DAG會被切分成多個Stage。每個Stage包含一組需要并行執行的Task。
任務調度與執行:
SparkContext中的DAGScheduler將DAG分解成TaskSets(任務集),每個TaskSet對應一個Stage中的所有任務。
TaskScheduler負責將這些TaskSets分配給各個Executor執行。它可以根據不同的調度策略來優化任務的分配。
Executor接收任務后,會執行具體的計算邏輯,包括從內存或磁盤讀取數據、執行變換操作、將結果寫回存儲等。
數據處理與Shuffle:
在處理過程中,如果遇到寬依賴,數據需要進行Shuffle操作,即重新分布數據,以便后續Stage可以并行處理。
Shuffle過程中可能會涉及到數據的序列化、網絡傳輸、磁盤寫入和讀取等操作,這是Spark計算中的一個潛在瓶頸。
結果收集與應用結束:
最終Stage的計算結果會被收集回Driver節點。
應用程序執行完畢后,SparkContext會向資源管理器注銷并釋放所有資源,包括Executor和分配的內存、CPU等。
監控與日志:
Spark提供了Web UI,可以實時監控應用的執行狀態、資源使用情況、任務進度等信息,便于調試和性能優化。
整個流程展示了Spark如何從應用提交開始,經過資源申請、任務調度與執行,直至最終結果產出并釋放資源的全過程,體現了其高度的并行計算能力和資源管理效率。
Spark的作業運行流程是怎么樣的?
Spark的作業運行流程可以概括為以下幾個關鍵步驟:
1、啟動與初始化:
用戶通過編寫Spark應用程序并提交至Spark集群。
提交后,首先啟動一個Driver進程,該進程負責解析用戶代碼,創建SparkContext(Spark應用的入口點),并與集群資源管理器(如YARN、Mesos或Standalone)進行通信,申請執行資源。
2、構建執行計劃:
SparkContext將用戶編寫的RDD(彈性分布式數據集)操作轉換成DAG(有向無環圖),表示RDD間的依賴關系。
DAGScheduler分析DAG,根據RDD之間的依賴關系將DAG切分成多個Stage,每個Stage包含一組可以并行執行的Task。這些Stage按照依賴順序排列,形成了執行計劃。
3、資源分配與Executor準備:
SparkContext根據執行計劃的需求向資源管理器請求Executor資源。
Executor在各個Worker節點上啟動,準備好執行Task所需的計算資源和環境。
4、任務調度與執行:
TaskScheduler將Stage進一步分解為具體Task,并將這些Task分配給各個Executor執行。
Executor執行Task,處理數據,執行轉換操作(如map、reduce等),并在必要時進行數據Shuffle。
Executor之間通過網絡交換數據,實現數據的重新分配。
5、結果匯總與輸出:
最終Stage的Task執行完成后,它們的結果被收集并匯聚到Driver進程中。
如果是行動(Action)操作,如collect或saveAsTextFile,Driver會處理這些結果,如打印輸出或保存到外部存儲。
6、資源釋放與應用結束:
應用程序執行完畢后,SparkContext會通知資源管理器釋放所有資源,包括關閉Executor。
最后,SparkContext自身也會關閉,標志著整個Spark作業的生命周期結束。
在整個過程中,Spark利用內存計算、懶惰求值、DAG執行模型和高效的調度機制,旨在最小化數據讀寫磁盤的次數,從而提高數據處理的效率和速度。同時,Spark提供了豐富的監控工具,如Web UI,便于跟蹤作業的執行狀態和性能指標。
Spark的特點
Apache Spark 是一個廣泛使用的開源大數據處理框架,它以其高效、易用和靈活的特性,在數據處理領域占據重要地位。以下是Spark的主要特點:
-
高性能:Spark 最顯著的特點是它的高性能。它利用內存計算技術,能夠在內存中進行數據處理,相比于傳統的Hadoop MapReduce,官方數據顯示Spark在內存中的運算速度能快100倍以上,即使在需要磁盤IO時也能達到10倍以上的速度提升。這得益于其高效的DAG(有向無環圖)執行引擎,能夠優化數據處理流程,減少不必要的讀寫操作。
-
易用性:Spark 提供了高度抽象的API,支持Scala、Java、Python、R等多種編程語言,使得數據處理任務的編寫變得更加簡單直觀。它包括Spark SQL(用于結構化數據處理)、Spark Streaming(處理實時數據流)、MLlib(機器學習)、GraphX(圖形處理)等多個庫,方便開發者構建復雜的數據處理管道。
-
通用性:Spark 是一個統一的數據處理平臺,能夠支持批處理、交互式查詢(通過Spark SQL)、實時流處理(Spark Streaming)、機器學習和圖計算等多種工作負載。這意味著開發者可以使用單一框架解決多樣化的數據處理需求,降低了技術棧的復雜度。
-
可擴展性與容錯性:Spark 設計為可以輕松部署在從單個計算機到數千臺機器的集群上,具備良好的水平擴展能力。它利用Hadoop HDFS或其他分布式文件系統來存儲數據,確保數據的高可用性。同時,Spark內部的RDD(彈性分布式數據集)模型支持數據的容錯處理,能夠在節點故障時自動恢復計算任務。
-
交互式分析:Spark支持交互式查詢,允許用戶以快速反饋的方式探索數據,這對于數據分析和數據科學應用尤為重要。
-
集成與生態系統:Spark與Hadoop生態系統深度集成,可以無縫讀取HDFS、Hive等Hadoop相關組件的數據,并且可以通過Spark SQL與傳統關系型數據庫和數據倉庫進行交互。此外,Spark擁有活躍的社區支持和豐富的第三方工具與庫,生態完善。
綜上所述,Spark憑借其高性能、易用性、通用性、可擴展性以及強大的生態系統支持,成為大數據處理領域的首選工具之一。
Spark源碼中的任務調度
Spark的任務調度主要由兩大部分組成:DAGScheduler和TaskScheduler。這兩個組件協同工作,負責將用戶提交的Spark作業轉化為可執行的任務,并在集群中高效地調度執行。
DAGScheduler
DAGScheduler位于Spark的Driver端,主要職責如下:
1、構建DAG(有向無環圖):根據RDD的依賴關系,構建一個表示整個作業計算流程的DAG。
2、Stage劃分:通過對DAG進行分析,識別出那些會產生shuffle的操作(即寬依賴),并據此將DAG切分成多個Stage。Stage之間的邊界通常是在shuffle操作的地方,這樣可以優化資源的使用和任務的執行。
3、任務集(TaskSet)生成:為每個Stage生成一組Task,這些Task將在Executor上并行執行。每個Task對應RDD的一個分區上的計算操作。
4、任務調度策略:雖然DAGScheduler負責Stage的劃分和TaskSet的產生,但它并不直接與Executor交互來分配任務。它會將這些任務集提交給TaskScheduler,由后者負責實際的資源請求和任務調度。
TaskScheduler
TaskScheduler同樣位于Driver端,但更側重于資源管理和任務的實際分配:
1、資源請求與分配:與底層資源管理器(如YARN、Mesos或Kubernetes)交互,請求Executor資源,并接收資源分配的響應。
2、任務分配:根據Executor的資源狀況和數據的本地性原則,將DAGScheduler產生的TaskSet中的Task分配給合適的Executor執行。TaskScheduler會嘗試將任務分配到數據所在的節點,以減少網絡傳輸,提高執行效率。
3、任務狀態跟蹤:監控Task的執行狀態,包括任務的開始、完成、失敗和重試。在Task失敗時,TaskScheduler會根據配置的重試策略來決定是否重新調度該任務。
4、Executor管理:管理Executor的生命周期,包括Executor的添加與移除,以及與Executor的通信,以獲取任務執行的狀態信息。
調度流程總結
1、用戶提交作業后,SparkContext創建DAGScheduler和TaskScheduler。
2、DAGScheduler分析作業的RDD依賴,劃分Stage并生成TaskSet。
3、TaskScheduler根據資源情況和任務需求,向資源管理器請求Executor資源。
4、TaskScheduler將TaskSet中的Task分配給Executor,并管理任務的執行與失敗重試。
5、Executor執行Task,處理數據,并將結果返回給Driver。
這一系列過程確保了Spark能夠高效、靈活地在分布式環境中執行復雜的計算任務。
Spark作業調度
Apache Spark作業調度是Spark集群管理中的一個關鍵部分,它決定了如何在集群的節點上分配和執行任務。Spark提供了幾種調度策略和資源管理機制,以確保任務能夠有效地被調度和執行。
以下是關于Spark作業調度的一些關鍵概念和機制:
1、調度器(Scheduler):
Spark提供了幾種調度器,如FIFO(先進先出)、Fair(公平)和Capacity(容量)調度器。這些調度器決定了如何為提交的作業分配資源。
FIFO調度器按照作業提交的順序來調度它們。
Fair調度器嘗試在所有作業之間公平地分配資源,允許配置作業池和權重。
Capacity調度器允許用戶配置多個隊列,并為每個隊列分配一定數量的資源。
2、作業(Job):
在Spark中,一個作業通常是由一個行動(Action)觸發的,如collect(), count(), saveAsTextFile()等。作業被拆分成多個任務(Tasks)來在集群上并行執行。
3、任務(Task):
每個任務都是作業中的一部分,并在集群的一個節點上執行。任務可以是map任務、reduce任務或shuffle任務等。
4、資源管理器(Resource Manager):
在Spark on YARN這樣的環境中,YARN的資源管理器(ResourceManager)負責集群資源的分配。
在Spark Standalone模式下,Spark Master節點負責資源的分配。
5、動態資源分配(Dynamic Resource Allocation):
Spark支持動態資源分配,這意味著它可以根據工作負載自動地增加或減少executor的數量。這有助于更有效地利用集群資源。
6、配置參數:
Spark提供了許多配置參數來控制作業調度和資源管理,如spark.scheduler.mode(設置調度器模式)、spark.dynamicAllocation.enabled(啟用動態資源分配)等。
7、任務本地化(Task Locality):
Spark嘗試將任務調度到存儲了所需數據的節點上,以減少數據傳輸的開銷。這被稱為任務本地化。Spark會根據數據的存儲位置來決定任務應該在哪里執行。
8、作業調度日志和監控:
Spark提供了Web UI來監控作業的進度、執行時間和資源使用情況。此外,還可以使用Spark的日志和事件日志來分析作業的性能和調度行為。
9、優化調度:
為了優化作業調度,可以采取一些策略,如合并小任務以減少調度開銷、優化數據布局以減少數據傳輸、調整配置參數以適應不同的工作負載等。
10、Spark SQL和DataFrame的調度:
對于使用Spark SQL和DataFrame API編寫的作業,Spark會生成一個邏輯執行計劃,并將其轉換為物理執行計劃來執行。這些計劃中的操作也會被拆分成任務并在集群上執行。
Spark的架構
Spark的架構是一個基于內存計算的分布式處理框架,其設計旨在高效地處理大規模數據集。以下是Spark架構的主要組件和關鍵概念的清晰概述:
1、核心組件:
Application:建立在Spark上的用戶程序,包括Driver代碼和運行在集群各節點的Executor中的代碼。
Driver Program:驅動程序,是Application中的main函數,負責創建SparkContext,并作為Spark作業的調度中心。
SparkContext:Spark的上下文對象,是應用與Spark集群的交互接口,用于初始化Spark應用環境,創建RDD、廣播變量等。
Executor:Spark應用運行在Worker節點上的一個進程,負責執行Driver分配的任務,并將結果返回給Driver。
Cluster Manager:在集群上獲取資源的外部服務,可以是Standalone、YARN、Mesos等。
Worker Node:集群中任何可以運行Application代碼的節點,負責啟動Executor進程。
2、運行架構:
Spark采用Master-Slave架構模式,其中Driver作為Master節點,負責控制整個集群的運行;Executor作為Slave節點,負責實際執行任務。
Driver負責將用戶程序轉化為作業(Job),并在Executor之間調度任務(Task)。Executor則負責運行組成Spark應用的任務,并將結果返回給Driver。
3、任務調度與執行:
Spark作業被拆分成多個Task,每個Task處理一個RDD分區。
DAG Scheduler負責根據應用構建基于Stage的DAG(有向無環圖),并將Stage提交給Task Scheduler。
Task Scheduler負責將Task分發給Executor執行。
4、資源管理器:
Spark支持多種資源管理器,如YARN、Mesos和Standalone模式。
在YARN模式中,ResourceManager分配資源,NodeManager負責管理Executor進程。
在Standalone模式中,Master節點負責資源的調度和分配,Worker節點負責執行具體的任務。
5、數據核心 - RDD:
RDD(彈性分布式數據集)是Spark的基本計算單元,表示不可變、可分區、里面的元素可并行計算的集合。
RDD支持多種轉換操作(如map、filter)和行動操作(如reduce、collect),并且具有容錯性,可以在部分數據丟失時重新計算。
6、其他特性:
Spark支持動態資源分配,可以根據工作負載自動增加或減少Executor的數量。
Spark提供了豐富的API,如Spark SQL、MLlib、GraphX等,用于數據查詢、機器學習和圖計算等任務。
Spark的使用場景
Apache Spark 是一個開源的大數據處理框架,以其高性能的內存計算和易用的API而廣受歡迎。以下是Spark的一些典型使用場景:
-
大規模數據處理與分析:Spark非常適合處理PB級別的數據集,常用于數據挖掘、日志分析、用戶行為分析等場景。例如,互聯網公司可以利用Spark分析用戶點擊流數據,優化網站布局和推薦算法。
-
實時數據處理:通過Spark Streaming模塊,Spark能夠實時處理數據流,適用于需要實時數據分析的場景,比如社交媒體趨勢分析、實時交通監控、在線廣告投放系統等。
-
機器學習與數據科學:Spark包含MLlib機器學習庫,支持分類、回歸、聚類、推薦等多種算法,適合構建和訓練大規模機器學習模型,以及進行特征工程、模型評估等數據科學任務。
-
交互式查詢:借助Spark SQL模塊,用戶可以使用SQL或者DataFrame API對數據進行交互式查詢,適用于需要快速響應的BI分析、即席查詢等場景。
-
圖計算:使用GraphX庫,Spark能處理大規模圖數據,適合社交網絡分析、推薦系統中的關系挖掘、知識圖譜構建等應用。
-
批處理:Spark擅長處理批處理任務,包括數據清洗、ETL(提取、轉換、加載)、大規模數據聚合等。
-
推薦系統:特別是實時推薦,Spark可以快速處理用戶行為數據,即時更新推薦模型,提升用戶體驗。
-
金融行業應用:在金融領域,Spark被用來處理海量交易數據,進行風險分析、欺詐檢測、信用評分等。
-
物聯網(IoT)數據處理:隨著IoT設備產生的數據量劇增,Spark可用于實時處理和分析這些數據,支持決策制定和預測維護。
-
醫療健康數據分析:在醫療領域,Spark可以用來處理電子病歷、基因組學數據,支持疾病預測、患者分群和個性化治療方案的制定。
綜上所述,Spark由于其靈活性和高效性,幾乎涵蓋了大數據處理的所有關鍵領域,特別是在需要快速迭代計算、實時處理和復雜數據分析的場景下,Spark展現了其獨特的優勢。
Spark on standalone模型、YARN架構模型(畫架構圖)
Spark on Standalone模型
在Spark on Standalone模型中,Spark集群由以下幾個主要組件組成:
Driver Program:這是Spark應用程序的入口點,負責創建SparkContext對象,并與集群管理器(在Standalone模式下為Master節點)進行交互。
SparkContext:Spark應用程序的上下文,用于初始化Spark環境,創建RDDs、廣播變量等。
Worker Nodes:集群中的工作節點,負責執行Spark任務。每個Worker節點上運行一個Worker進程,負責啟動Executor進程。
Executors:運行在Worker節點上的進程,負責執行具體的Spark任務。Executor進程負責讀取輸入數據、執行計算并將結果返回給Driver。
在Standalone模式下,Master節點負責集群的資源管理和任務調度。當Driver提交作業時,Master節點會分配資源給Executor進程,并監控它們的執行狀態。
Standalone模式架構圖
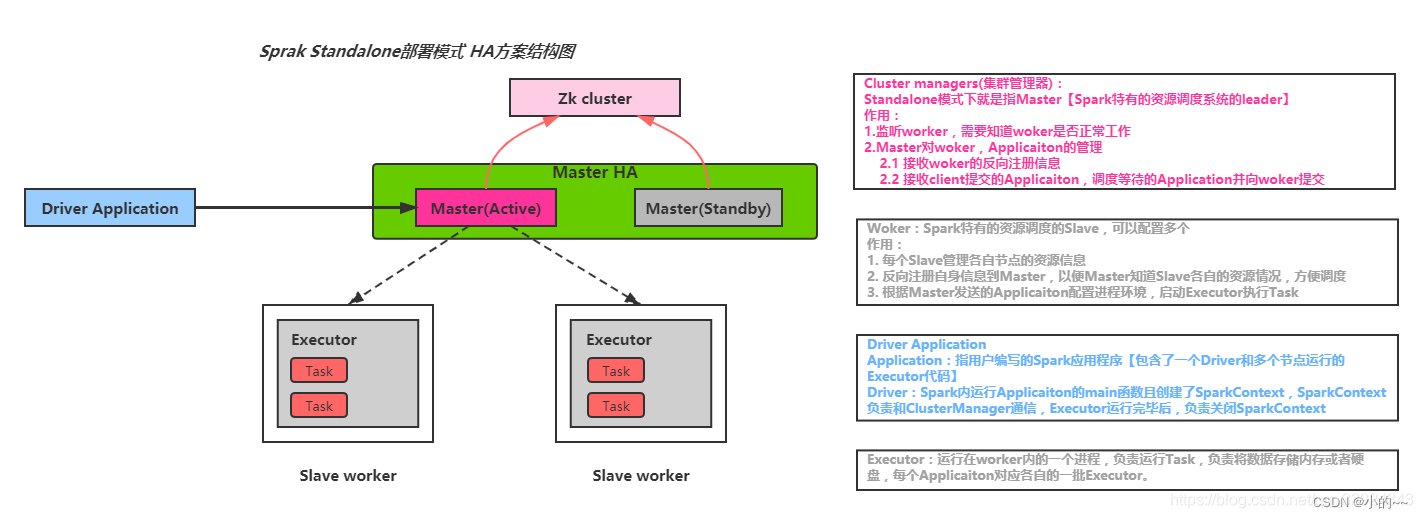
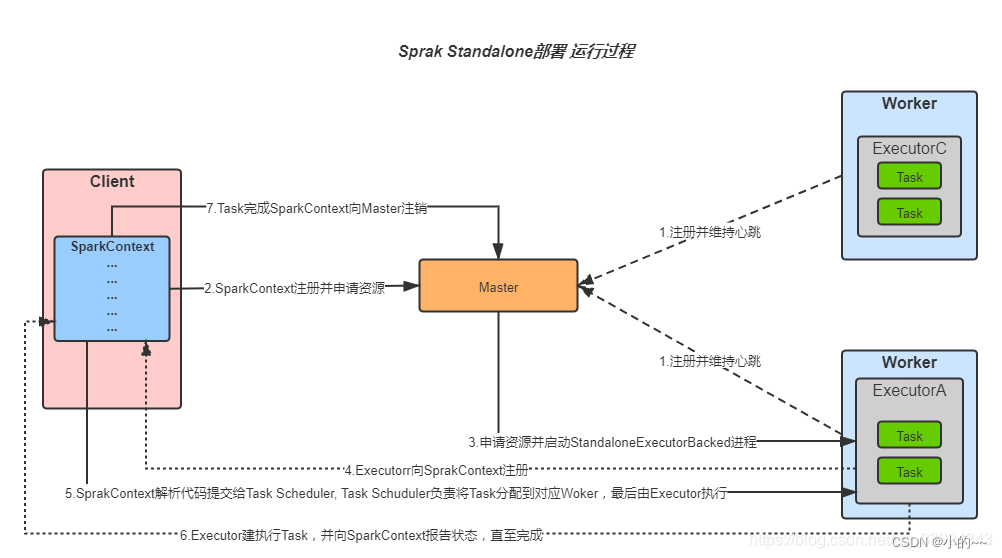
Standalone模式運行流程圖
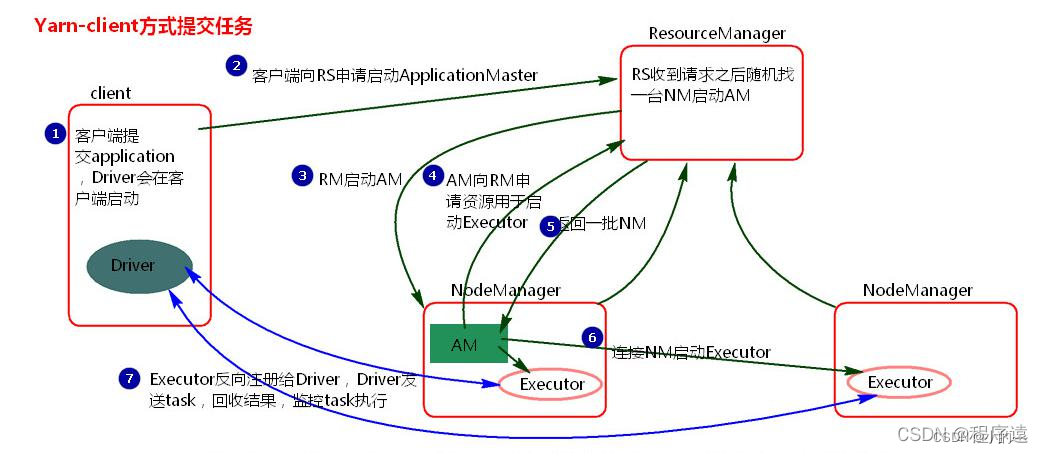
YARN架構模型
在Spark on YARN架構模型中,YARN作為集群的資源管理器,與Spark集群協同工作。主要組件包括:
ResourceManager (RM):YARN集群的資源管理器,負責整個集群的資源管理和調度。RM與NodeManager通信,以分配和管理資源。
NodeManager (NM):YARN集群中的每個節點都運行一個NodeManager進程,負責啟動和管理Container。Container是YARN中資源分配的基本單位。
ApplicationMaster (AM):對于每個Spark應用程序,YARN都會在集群中選擇一個NodeManager進程啟動一個AM。AM負責向RM申請資源,進一步啟動Executor進程以運行Task。
Executors:與Standalone模式類似,Executors運行在YARN的Container中,負責執行具體的Spark任務。
在Spark on YARN模式下,有兩種提交方式:
Client模式:Driver進程在客戶端啟動,與AM建立通信。AM負責申請資源并啟動Executors。
Cluster模式:Driver進程在YARN集群中啟動,作為AM的一部分。AM同時負責申請資源和啟動Executors。
在YARN架構中,RM負責資源的全局管理和調度,而AM則負責具體應用程序的資源請求和任務調度。這種架構使得Spark能夠充分利用YARN的資源管理和調度功能,實現更高效的資源利用和任務執行。
Spark的yarn-cluster涉及的參數有哪些?
Spark在YARN集群模式(yarn-cluster)下涉及的參數主要包括以下幾個方面,這些參數有助于控制應用的資源分配、行為表現及與YARN的集成方式:
1、資源相關參數
spark.executor.memory:每個Executor的內存大小。
spark.executor.cores:每個Executor可以使用的CPU核心數。
spark.executor.instances:Executor實例的數量。
spark.driver.memory:Driver進程的內存大小。
spark.driver.cores:Driver進程可以使用的CPU核心數。
2、網絡和序列化參數
spark.serializer:用于RDD序列化的類,默認為org.apache.spark.serializer.JavaSerializer,但推薦使用org.apache.spark.serializer.KryoSerializer以提高性能。
spark.network.timeout:網絡超時設置。
spark.rpc.askTimeout 或 spark.rpc.lookupTimeout:RPC通信超時時間。
3、應用名稱和隊列
spark.app.name:Spark應用的名稱。
spark.yarn.queue:YARN隊列的名稱,用于提交作業。
4、其他重要參數
spark.yarn.maxAppAttempts:應用程序最大重試次數。
spark.yarn.am.attemptFailuresValidityInterval:AM失敗有效間隔時間,決定多久內的失敗會被計數。
spark.yarn.historyServer.address:Spark歷史服務器地址,用于記錄和展示應用的歷史信息。
spark.yarn.applicationMaster.waitTries:嘗試等待Spark Master啟動和初始化完成的次數。
spark.yarn.submit.file.replication:Spark應用程序依賴文件上傳到HDFS時的備份副本數量。
5、日志和監控
spark.eventLog.enabled:是否啟用事件日志記錄。
spark.eventLog.dir:事件日志的目錄,通常在HDFS上。
6、動態資源分配(可選)
spark.dynamicAllocation.enabled:是否開啟動態資源分配。
spark.dynamicAllocation.minExecutors:動態分配時的最小Executor數量。
spark.dynamicAllocation.maxExecutors:動態分配時的最大Executor數量。
這些參數可以通過在提交Spark應用時使用spark-submit命令的--conf選項來設置,或者在Spark應用的配置文件中預先定義。正確配置這些參數對優化Spark作業的性能、資源管理和故障恢復至關重要。
Spark提交job的流程
1、準備階段:
用戶通過spark-submit命令或API提交Spark作業。
如果是基于YARN的集群模式(如YARN-Cluster),ResourceManager(RM)會收到任務提交請求,并進行任務記錄,為作業分配一個application_id,并在HDFS上分配一個目錄用于存儲作業所需的資源(如jar包、配置文件等)。
2、資源分配與初始化:
Spark Client根據application_id上傳任務運行所需的依賴到為其分配的HDFS目錄,并上傳應用代碼和其他必要的資源。
ResourceManager(RM)檢查資源隊列,如果存在可分配的資源(Node Manager, NM),則向這些NM發送請求以創建Container。
NM創建Container成功后,向RM發送響應,RM隨后通知Spark Client可以開始運行任務。
3、啟動Application Master和Driver進程:
Spark Client發送命令到NM所在的Container中,啟動Application Master(AM)。
AM從HDFS中獲取上傳的jar包、配置文件和依賴包,并創建Spark Driver進程。
4、Executor啟動與注冊:
Driver根據Spark集群的配置參數,通過RM申請NM容器以啟動Executor。
RM調度空閑的NM創建Container,AM獲取到NM的Container后,發送啟動Executor進程的命令。
Executor啟動后,會向Driver進行反向注冊,以便進行心跳檢測和計算結果返回。
5、任務劃分與提交:
Driver進程解析Spark作業并執行main函數,DAGScheduler會進行一系列DAG構建,根據RDD的依賴關系將作業拆分成多個Stage。
每個Stage會被轉化為一個或多個TaskSet,由TaskScheduler提交到Cluster Manager(如YARN的ResourceManager)。
6、任務調度與執行:
由于Executor已在Driver注冊,Driver會將Task分配到Executor中執行。
Executor執行Task,并將結果返回給Driver。
7、結果聚合與作業結束:
Driver根據Executor返回的結果進行聚合。
如果需要,Driver會決定是否進行推測執行(Speculative Execution),即對于運行較慢的Executor,開啟新的Executor執行該任務。
所有任務執行完畢后,Executor和Driver進程結束,Application結束,并向RM注銷。
8、資源釋放:
RM和NM繼續接受下一個任務的資源請求,之前為作業分配的資源被釋放并回收。
Spark的階段劃分
1. Spark作業的基本組成
Job:一個Spark作業通常是由一個行動(Action)操作觸發的,例如collect(), count(), saveAsTextFile()等。每個行動操作都會觸發一個或多個Stage的執行。
Stage:Stage是Job的組成單位,一個Job會切分成多個Stage。Stage之間通過依賴關系進行順序執行,而每個Stage是多個Task的集合。
2. 階段劃分的依據
Shuffle操作:Spark的階段劃分主要基于數據的Shuffle操作。當RDD之間的轉換連接線呈現多對多交叉連接時(即涉及Shuffle過程),會產生新的Stage。Shuffle操作是重新組合數據的過程,如將數據按照某個key進行聚合或關聯。
窄依賴與寬依賴:Spark中的依賴關系分為窄依賴和寬依賴。窄依賴(如map、filter等)不會導致新的Stage的產生,而寬依賴(如groupBy、join等涉及Shuffle的操作)則會導致新的Stage的產生。
3. 階段劃分的流程
DAG構建:Driver Program根據用戶程序構建有向無環圖(DAG, Directed Acyclic Graph),表示作業的計算流程。
劃分Stage:DAGScheduler遍歷DAG,根據寬依賴關系將DAG劃分為多個Stage。每個Stage內部是窄依賴的,而Stage之間通過寬依賴連接。
Task生成:在每個Stage中,根據RDD的分區數量生成相應數量的Task。每個Task處理一個RDD分區的數據。
4. 階段與Task的關系
一個Job至少包含一個Stage,但通常會包含多個Stage。
一個Stage包含多個Task,這些Task在集群的不同節點上并行執行。
5. 優化階段劃分
通過優化Spark代碼,減少不必要的Shuffle操作,可以減少Stage的數量,從而提高作業的執行效率。
合理設置RDD的分區數量,確保每個Task能夠處理合適大小的數據量,避免資源浪費或任務過載。
Spark處理數據的具體流程說下
1、作業初始化:
驅動程序啟動:Spark應用從一個稱為驅動程序(Driver Program)的進程中開始執行。驅動程序負責創建SparkContext,這是Spark與集群管理器(如YARN或Mesos)交互的主要接口。
構建邏輯計劃:用戶通過Spark的API(如RDD、DataFrame或Dataset)定義數據處理任務。驅動程序根據這些操作構建一個執行計劃,這個計劃是惰性求值的,即直到有動作(action)觸發時才會真正執行。
2、任務劃分:
DAG構建:Spark會根據用戶的轉換(transformation)操作構建一個有向無環圖(DAG),表示數據處理的各個階段。
Stage劃分:DAG被劃分為多個Stage,通常在寬依賴(例如shuffle)的地方切分。每個Stage包含一組任務(Task),這些任務可以在Executor上并行執行。
3、資源申請與任務調度:
向資源管理器申請資源:SparkContext與資源管理器(如YARN或Mesos)溝通,請求Executor資源。
任務分配:一旦資源獲得,Spark根據Stage和數據的位置來分配任務給Executor執行。任務調度器確保數據本地性原則,盡可能讓任務在數據所在的節點上執行,以減少網絡傳輸。
4、數據處理與計算:
Executor執行任務:每個Executor上的任務負責加載、處理其分配的數據塊。數據優先嘗試加載到內存中(RDD緩存),以便快速訪問和迭代計算。
Shuffle操作:在需要重新分布數據的Stage(如reduceByKey),Spark執行shuffle操作,重新組織數據,確保后續Stage的任務能正確處理分區后的數據。
5、結果匯聚與返回:
任務結果收集:任務完成后,計算結果返回到驅動程序。對于行動(Action)操作,如collect,所有Executor的結果會被匯聚到驅動程序。
結果處理:驅動程序可能對結果進行進一步處理,比如排序、過濾或保存到外部存儲系統(如HDFS、數據庫)。
6、清理與結束:
資源釋放:當應用完成或遇到錯誤時,Spark會釋放所有申請的資源,包括Executor和相關資源。
結果輸出:最終結果按照用戶需求輸出或保存。
Sparkjoin的分類
1、Shuffle Hash Join:
這是最基本的join類型,適用于兩個大表的關聯。它首先會對參與join的兩個數據集使用指定的鍵進行分區(shuffle過程),然后在每個分區內部使用哈希表來加速匹配過程。Shuffle Hash Join要求數據能夠跨節點重新分布,因此可能會產生較大的網絡開銷。
2、Broadcast Hash Join:
當一個數據集相對較小,可以輕松地復制到所有參與計算的節點上時,Broadcast Hash Join就會非常高效。較小的表會被廣播到所有Executor的內存中,形成一個哈希表,然后較大的表的每個分區會在本地與這個哈希表進行匹配。這種方式避免了shuffle過程,減少了網絡傳輸和磁盤I/O,提高了處理速度,但要求“小表”能夠適應Executor的內存限制。
3、Sort Merge Join:
如果兩個數據集都已經按照join鍵排序,或者可以接受進行排序的話,Sort Merge Join是一個好的選擇。每個數據集先進行局部排序,然后通過合并已排序的部分來進行join操作。這種方法在數據集已經有序或可以經濟地排序時,尤其是處理兩個大表的情況,能夠提供較好的性能。但它涉及到額外的排序步驟,可能增加計算成本。
4、Cartesian Join (Cross Join):
這是一種特殊的join,它返回兩個數據集的所有可能組合。在Spark中,通過不指定任何join鍵直接調用join方法即可實現Cartesian Product。由于其產生的結果集可能非常龐大,因此在實際應用中較少使用。
5、Outer Joins:
Spark還支持各種外連接,包括leftOuterJoin, rightOuterJoin, 和 fullOuterJoin。這些操作在匹配鍵的同時,還會保留沒有匹配項的一方或雙方的數據,并用null填充缺失的值。它們可以在上述任何一種join策略的基礎上實現。
Spark map join的實現原理
Spark的Map Join實現原理主要依賴于廣播小表(Broadcast Join)的策略,這種策略特別適用于一個表(我們稱之為“小表”)相對于另一個表(我們稱之為“大表”)來說非常小的情況。以下是Map Join實現原理的詳細解釋:
1、廣播小表:
當Spark執行Join操作時,如果它檢測到其中一個表(即小表)的大小小于某個閾值(這個閾值在Spark中可以通過spark.sql.autoBroadcastJoinThreshold進行配置,默認上限是10MB,但注意在較新版本的Spark中,這個限制可能已經提高到8GB),它會選擇將該小表廣播到所有節點上。
廣播是指將小表的數據分發到集群中的所有節點,每個節點都會緩存一份小表的完整數據。
2、Map端Join:
在數據已經被廣播到所有節點之后,Map Join操作在數據所在的節點上直接進行,而無需通過網絡傳輸大表的數據。
每個節點上的Executor都會使用本地緩存的小表數據和大表數據進行Join操作,這大大減少了網絡傳輸的開銷,并提高了Join操作的效率。
3、特點與限制:
只支持等值連接:Map Join主要適用于等值連接的情況,即連接條件是兩個表的列之間的等值關系。
內存占用:由于需要將小表廣播到所有節點,因此如果小表過大,可能會占用大量的內存,甚至導致內存溢出(OOM)。
廣播閾值:如前所述,廣播的閾值可以通過配置進行調整。選擇合適的閾值對于Map Join的性能至關重要。
4、執行過程:
識別小表:Spark首先會根據表的大小和配置識別出哪個表是小表。
廣播小表:將小表的數據廣播到集群中的所有節點。
執行Map Join:在每個節點上,使用本地緩存的小表數據和大表數據進行Join操作。
5、優化:
在使用Map Join時,可以考慮對經常用于Join的小表進行緩存,以減少廣播的開銷。
根據實際的數據分布和大小,合理調整廣播的閾值。
總的來說,Spark的Map Join通過廣播小表并在Map端直接進行Join操作,減少了網絡傳輸的開銷,提高了Join操作的效率。然而,它也有一些限制,如只支持等值連接和可能的內存占用問題。因此,在使用時需要根據實際情況進行合理的配置和優化。
引用:https://www.nowcoder.com/discuss/353159520220291072
通義千問、文心一言










JSON數據綁定)

什么是數字簽名和數字證書)


)



