

🌈個人主頁: 鑫寶Code
🔥熱門專欄: 閑話雜談| 炫酷HTML | JavaScript基礎
?💫個人格言: "如無必要,勿增實體"

文章目錄
- K-means++: 一種改進的聚類算法詳解
- 引言
- 1. K-means算法回顧
- 1.1 基本概念
- 1.2 局限性
- 2. K-means++算法介紹
- 2.1 初始質心選擇策略
- 2.2 算法優勢
- 3. K-means++算法實現步驟
- 3.1 準備工作
- 3.2 初始化質心
- 3.3 迭代優化
- 3.4 結果評估
- 4. 實際應用案例
- 4.1 數據降維
- 4.2 客戶細分
- 4.3 文檔分類
- 5. 總結
K-means++: 一種改進的聚類算法詳解
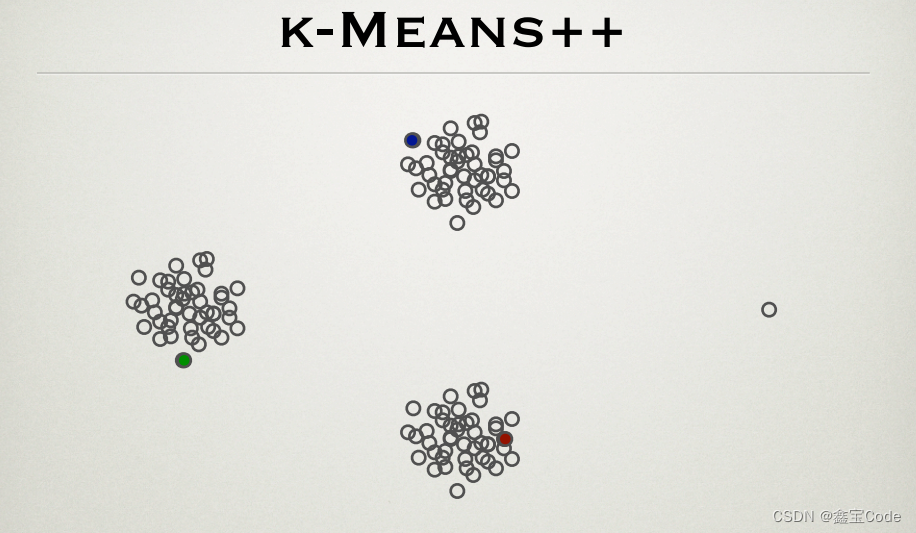
引言
在數據分析與機器學習領域,聚類算法作為無監督學習的重要組成部分,被廣泛應用于數據分組、模式識別和數據挖掘等場景。其中,K-means算法以其簡單直觀和高效的特點,成為最常用的聚類方法之一。然而,經典K-means算法在初始聚類中心的選擇上存在隨機性,可能導致算法陷入局部最優解。為解決這一問題,2007年,David Arthur 和 Sergei Vassilvitskii 提出了K-means++算法,它通過一種智能化的初始化策略顯著提高了聚類質量。本文將深入探討K-means++算法的原理、優勢、實現步驟以及實際應用案例,旨在為讀者提供一個全面且易于理解的K-means++算法指南。
1. K-means算法回顧

1.1 基本概念
K-means算法的目標是將數據集劃分為K個簇(clusters),每個簇由距離其質心(centroid)最近的數據點組成。算法迭代執行以下兩個步驟直至收斂:
- 分配步驟:將每個數據點分配給最近的質心。
- 更新步驟:重新計算每個簇的質心,即該簇所有點的均值。
1.2 局限性
- 對初始質心敏感:隨機選擇的初始質心可能導致算法陷入局部最優解。
- 不適合處理不規則形狀的簇:傾向于形成球形或凸形簇。
- 難以處理大小和密度變化較大的簇。
2. K-means++算法介紹
2.1 初始質心選擇策略
K-means++算法的核心改進在于其初始化過程,具體步驟如下:
- 從數據集中隨機選擇第一個質心。
- 對于每個數據點
x,計算其到已選擇的所有質心的最短距離D(x)。 - 選擇一個新的數據點作為下一個質心,選擇的概率與
D(x)成正比,即概率P(x)=D(x)/ ΣD(x)。 - 重復步驟2和3,直到選擇了K個質心。
這種選擇策略確保了質心之間的分散性,從而提高了聚類效果。
2.2 算法優勢
- 減少局部最優解的風險:更大概率選擇相距較遠的初始質心,提高聚類質量。
- 理論保證:K-means++能夠給出接近最優解的界,即與最優聚類方案的距離平方誤差最多是理論最小值的8倍。
- 效率:雖然初始化復雜度有所增加,但整體算法依然保持高效,尤其是對于大規模數據集。
3. K-means++算法實現步驟
3.1 準備工作
- 確定K值:根據實際需求預先設定簇的數量。
- 數據預處理:標準化或歸一化數據,以消除量綱影響。
3.2 初始化質心
- 按照K-means++策略選取K個初始質心。
3.3 迭代優化
- 分配數據點:將每個數據點分配給最近的質心。
- 更新質心:根據新分配結果,重新計算每個簇的質心。
- 檢查收斂:如果質心位置變化不大于預定閾值或達到最大迭代次數,則停止迭代。
3.4 結果評估
- 使用如輪廓系數、Calinski-Harabasz指數等評價指標評估聚類質量
下面是一個使用Python和scikit-learn庫實現K-means++算法的示例代碼。首先,確保你已經安裝了scikit-learn庫,如果沒有安裝,可以通過運行pip install scikit-learn來安裝。代碼僅供參考
# 導入所需庫
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs# 生成模擬數據
# 這里我們創建一個包含3個類別的數據集,每個類別有不同數量的點和方差
X, _ = make_blobs(n_samples=300, centers=3, cluster_std=[1.0, 1.5, 0.5], random_state=42)# 使用KMeans++算法進行聚類
kmeans_plus = KMeans(n_clusters=3, init='k-means++', random_state=42) # 'k-means++' 是關鍵參數
kmeans_plus.fit(X)# 可視化結果
plt.figure(figsize=(10, 5))# 繪制原始數據點
plt.subplot(1, 2, 1)
plt.scatter(X[:, 0], X[:, 1], c='grey')
plt.title('Original Data')# 繪制K-means++聚類結果
plt.subplot(1, 2, 2)
plt.scatter(X[:, 0], X[:, 1], c=kmeans_plus.labels_, cmap='viridis')
plt.scatter(kmeans_plus.cluster_centers_[:, 0], kmeans_plus.cluster_centers_[:, 1], s=300, c='red', label='Centroids')
plt.title('K-means++ Clustering Result')
plt.legend()plt.show()
這段代碼首先生成了一個具有三個聚類中心的二維模擬數據集,然后使用scikit-learn的KMeans類,并設置init='k-means++'來應用K-means++初始化策略進行聚類。最后,通過matplotlib庫可視化了原始數據點和聚類后的結果,其中紅色點表示各個簇的質心。這個例子簡潔地展示了如何在Python中實施K-means++算法并評估其效果。
4. 實際應用案例
4.1 數據降維
- 在PCA(主成分分析)之前,使用K-means++進行初步聚類,可以有效降低數據維度,提高后續分析效率。
4.2 客戶細分
- 在市場營銷中,通過對客戶消費行為數據進行K-means++聚類,企業可以識別不同的客戶群體,定制個性化營銷策略。
4.3 文檔分類
- 在文本挖掘領域,利用K-means++對文檔向量化后的特征進行聚類,有助于自動分類和主題發現。
5. 總結
K-means++算法通過一種更加智能的初始化策略,顯著改善了經典K-means算法的性能,尤其在解決初始質心選擇的隨機性和局部最優問題上表現出色。它不僅在理論上提供了性能保證,而且在實踐中廣泛應用于多個領域,展現了強大的實用價值。隨著大數據和機器學習技術的發展,K-means++及其變種將繼續在數據科學中扮演重要角色。






)
)


ISERDESE2原語仿真)



 - 圖像畸變校正)






