0 寫在前面
??程序員闖蕩江湖的一生都在與數據打交道,初入江湖時基于 MySQL 的 CRUD,漸入佳境后利用 Redis 實現查詢加速及分布式控制,本質上都是數據處理;無論主動/被動,都在利用數據來達成業務/技術目的。自然而然的,數據處理成為了計算機科學的重要研究方向。
??我們也充分享受了這門學科發展帶來的紅利,或許你很難想象,在20世紀50年代之前,人們保存與檢索數據的方式還是紙質文檔 + 字典目錄的人工排列;而現今我們能夠依據對性能、事務支持、擴展性、一致性、成本等不同層面的需求,在不同數據庫間自由選型。
??而在此基礎之上,人們又對數據處理能力提出了更高的要求,例如:PB級海量數據、秒級響應速度、Exactly-Once 語義、失敗容忍、動態擴縮容等等,此時傳統數據庫便顯得有些捉襟見肘。數據庫畢竟更專注于提供存儲服務而非計算服務,并且受制于不同的底層實現,其所能提供的計算規模、靈活程度、性能表現等也各不相同(例如 RDBMS 的表關聯、事務支持就是 KV 型數據庫所無法提供的,KV 型數據庫的高性能又是 RDBMS 無法企及的;不同索引數據結構的差異,導致對于點查、范圍查支持程度的不同)。當然,目前也存在 OceanBase、Hologres 這類原生高性能實時數據倉庫,不在本篇的討論范圍內。
??因此,存儲介質無關的大數據計算引擎應運而生,提供大量通用的函數算子、支持超大型數據計算規模、分布式調度能力、高性能底層計算處理引擎、高可用中間狀態存儲等等等等一系列牛逼的能力,能滿足一切你想要的。
??本文便以大數據實時計算領域的事實標準——Flink為例,帶你走進計算引擎的世界。
??
1 初入江湖:初識 Flink
??未見其人先聞其聲,來看看對于 Flink 相對官方的介紹:
Apache Flink 是一個用于流處理和批處理的開源分布式數據處理框架,它提供了高吞吐量、低延遲的數據處理能力,可以處理大規模數據并具有容錯性。Flink 最初是由德國柏林工業大學的研究人員開發的,現在是 Apache 軟件基金會的頂級項目之一。
??從這段介紹中可以提取出幾個關鍵詞:
- Apache(牛逼)
- 流(Streaming)處理/批(Batch)處理
- 分布式
- 高吞吐/低延遲/大規模數據集/容錯性···
1.1 Streaming/Batch
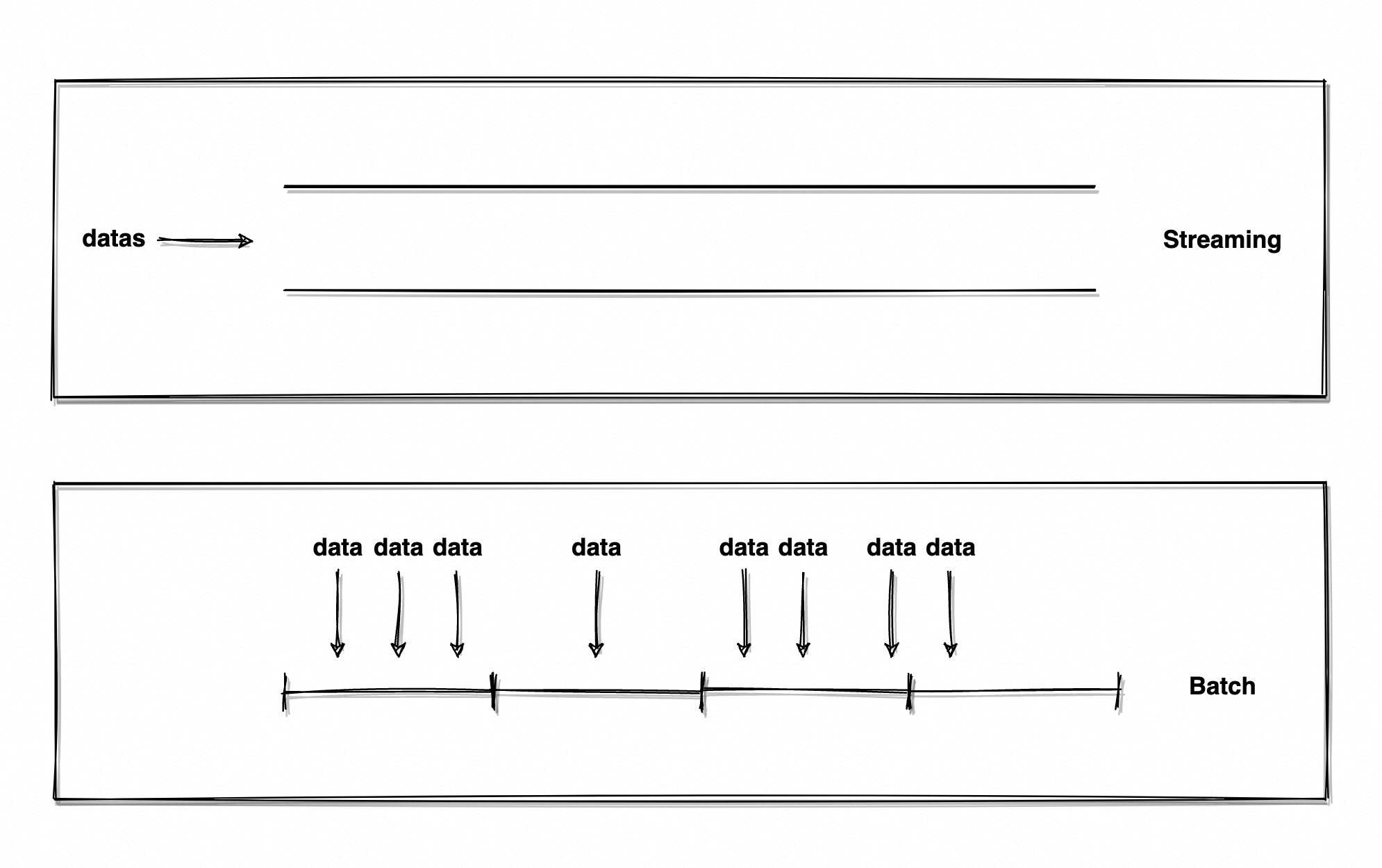
??什么是流處理/批處理?全程叫:流數據處理/批數據處理,大數據計算引擎的兩大核心分支。
??「批」并不難理解,一批人、一批貨、一批任務(你還認識「批」這個字不?),常見的用于描述數量的抽象單位,一切既定規模的實體都可以描述為「一批」。因此,批數據處理就是對于大小已知數據集的處理。
??再說「流」,人流量、車流量、金額流水,都是在描述無邊界、數量未知、源源不斷的數據流動趨勢。因此,流數據處理是對于實時生成、無邊界數據集的處理。
??簡單來說,流是源源不斷流動著數據的管道,批是既定規模的數據集。
??
??那「流」與「批」兩個概念是否相悖呢?
??為流加上“近1小時”、“近3天”的限定詞,流有了邊界、有了確定的范圍,流就成了批;將批無限縮小,將每批數據的取值界限設定為1ms,批的實時性又無限接近于流。顯然兩者并不相悖,只是出發的視角不同,批可以是有邊界的流、流也可以由無數個微型的批構成(Spark 便以此理念實現了流計算)。
??這時有同學就說了:“這不小流嗎?這我熟啊,我每天都 List.stream().map().collect()。”
??在了解流的概念后,顯然能夠知曉這并不是真正意義上的流,只是套用了流式計算的理念——流計算提供了大量函數算子(如 map/filter/flatMap/sum),融合了函數式編程風格,風格類似對管道中元素分步處理。但必須要分清,這并不是真正的流、也不是真正的流計算,因為數據集是既定規模的、有邊界的!一定要對流建立正確的認知!
??再說回 Flink,其設計理念就是進行流數據處理,流又有著天然實時性和規模未知的特性,所以 Flink 被稱為「大數據實時計算引擎」。現今 Flink 也支持了批計算,因為如上文所言“批就是有邊界的流”,做一些簡單的轉換便可以實現批計算語義,因此 Flink 實際上是「流批一體計算引擎」。
1.2 分布式
??分布式這個命題過于大,這里僅介紹分布式在 Flink 中的體現。實際這部分也是 Flink 運行時架構的核心內容,這里僅作枚舉和簡述,后續會進行詳細介紹。
??Flink 通常以分布式集群的形式運行,提到分布式集群就繞不開高并發/高可用/動態擴展等基本特性,Flink 也提供了這樣的基礎能力,內置 ZooKeeper 進行分布式環境協調及高可用保障。
??Flink 架構包含四大組件:**JobManager 作業管理器、ResourceManager 資源管理器、TaskManager 任務管理器、Dispatcher 分發器。**每個組件都是一個 JVM 進程(Flink 用 Java + Scala 語言開發,運行于 JVM 之上),組件間通訊、Master 節點選舉與高可用、動態擴縮容自然離不開分布式協調。
1.3 高級特性
??Flink 具備「高吞吐/低延遲/大規模數據集/容錯性」等高級特性,實際每個特性背后的實現都是門學問,這里只作簡單的介紹。
- 高吞吐:Flink 程序通常運行在大型集群之上,再加之能靈活調整 Task/算子并行度、最大化利用集群資源,能夠使數據處理能力達到極為夸張的水平。
- 低延遲:采用事件驅動模型,對輸入事件進行實時處理;使用本地狀態存儲,減少網絡通訊;異步化數據傳輸與網絡通訊,最小化延遲。
- 大規模數據集:放不下就加內存加內存加內存,加機器加機器加機器。
- 容錯性:Checkpoint 機制,定期保存作業執行狀態 State 快照,故障發生/任務重啟時可以利用 Checkpoint 快速恢復。
1.4 Why Flink?
??也許大家還是會對「為什么用 Flink?」有疑問,筆者其實也很難以孤例讓大家理解 Flink 的強大。以阿里巴巴 2018 年的公開數據為例:
- 運行總機器數 3000+
- 最大集群機器數 1500+
- 每秒支持實時計算次數 10 億+
??以筆者親身體驗來說,只要不是過于復雜的邏輯,基本單節點(單 TaskManager,類似 Worker 節點)就能支持千級別 RPS(Request Per Second,可以簡單理解為吞吐量)實時計算;通過不斷地調優與擴容(加機器加機器加機器),數十萬級別 RPS 并不是難事。
??所以,還就得是 Flink。
2 江湖新秀:初探 Flink
??相信諸位對 Flink 已建立了基本認知,下面筆者會帶領各位少俠,親身感受這門武林絕學的強悍。但在這之前,還需要清楚什么是「數據處理」,才能知道怎么用 Flink 完成數據處理。
??通用的數據處理可以抽象為 E-T-L三個環節:
- Extract 抽取:從不同數據源中獲取數據。
- Transform 轉換:按照使用方式或業務邏輯自定義數據轉換邏輯,編寫腳本/函數。
- Load 裝載:裝載到存儲介質中,如數據庫、消息隊列等。
??Flink 中的數據處理同樣可以抽象為三個環節:
- Source:數據源讀取。
- Transform:數據轉換。
- Sink:數據輸出。
??不難發現兩者概念上高度一致,因此 Flink 也不會跳出基本的數據處理流程與原則。
??
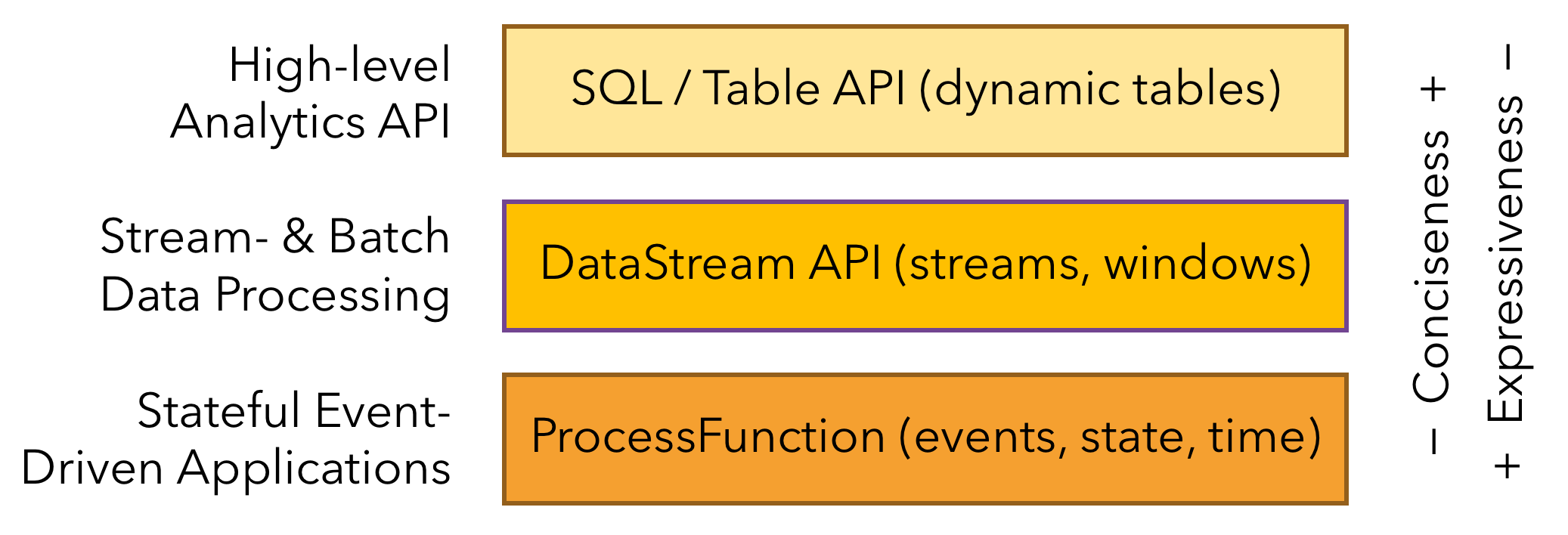
??在使用層面 Flink 提供了多層 API(如圖3),3 層 API 自上而下便利程度逐級降低、表達靈活程度逐級提高:
- SQL/Table API:最高層級,通用的結構化查詢語言/數據定義語言,類似 DML/DDL。
- DataStream/DataSet API:核心 API,分別對應流/批(無界/有界)數據集計算,包含大量函數式計算 API,如 map/flatMap/sum/max/min/keyBy/window 等。
- Stateful Stream Processing:有狀態流處理接口,由用戶自定義流中事件的處理邏輯,并自行管理狀態、時間屬性等。過于底層,一般用不到。
??得益于其提供的 SQL API,開發一個 Flink Job 實際就是寫一段 SQL,寫 SQL 也成了 Flink Job 開發最常用的方式。與 MySQL 語法基本完全一致,基本能想到的函數它都有,這使得 Flink 的入門門檻極低、使用極其方便,會寫 SQL 基本就可以說自己會 Flink 了(當然了不建議這么說,還是謙虛一點)。
??讓俺們來動手寫一寫。
2.1 Flink SQL
??本章節主要討論“如何寫出 Flink SQL”,再延伸到“怎么以流式思維寫好 SQL”。上文提到 Flink 數據處理可抽象為 Source -> Transform -> Sink 三個環節,后續便以該結構展開討論。
2.1.1 Source - 源表連接器
??處理數據第一步要先讀取數據,在Flink的世界里,構建與數據源鏈接的物質叫做「Connector 連接器」。
??以最常見的 MySQL CDC(簡稱 MySQL)源表連接器為例,使用該連接器可以監聽 MySQL 數據變動,類似于監聽 binlog。如下代碼塊是 MySQL Connector 示例:
CREATE TABLE mysqlcdc_source (order_id INT,order_date TIMESTAMP(0),customer_name STRING,price DECIMAL(10, 5),product_id INT,order_status BOOLEAN,PRIMARY KEY(order_id) NOT ENFORCED
) WITH (-- 連接器類型'connector' = 'mysql-cdc',-- 主機名'hostname' = '<yourHostname>',-- 端口號'port' = '3306',-- 賬號'username' = '<yourUsername>',-- 密碼'password' = '<yourPassword>',-- 數據庫名稱'database-name' = '<yourDatabaseName>',-- 表名'table-name' = '<yourTableName>'
);
??顯然這就是一段 DDL 語句,配置表字段以及元數據(WITH 參數,除連接地址/賬號/密碼等信息,還提供如批量讀取條數、指定 binlog 消費點位、連接超時時長之類的高級特性可選用),Flink 就能夠愉快讀取到 MySQL 表的數據變化。簡單到令人震驚,只需要一條簡單的 DDL 語句,便可以實現數據流的接入,但實現原理顯然沒有用起來這么簡單。
??為什么只配置一句 DDL,就可以將源數據結構無損轉換到流數據結構?為什么只靠一句 DDL,就能夠實現流式語義的數據讀取?
??這對應兩個極其重要的特性:流表對偶性(Duality)和持續查詢(Continuous Queries),這兩個特性賦予 Flink 將表轉為流的能力,后續會重點介紹。
??Flink 內置大量的 Connector,除了提到的 MySQL 還支持 Kafka、Socket、ElasticSearch、Hive 等等等等(見官方文檔:https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/connectors/table/overview/),基本常用的隊列/數據庫都能找到。實在有邪門的數據源或者定制化需求還可以自定義,自行實現 Flink 提供的連接器模板,但這個區域還是以后再來探索吧。
2.1.2 Sink - 結果表連接器
??讀取數據后自然要寫入數據,這種連接器被稱為結果表連接器。它也是連接器的一種,使用方式與源表連接器基本無異:
CREATE TABLE mysqlcdc_source (order_id INT,order_date TIMESTAMP(0),customer_name STRING,price DECIMAL(10, 5),product_id INT,order_status BOOLEAN,PRIMARY KEY(order_id) NOT ENFORCED
) WITH (-- 連接器類型'connector' = 'mysql',-- 主機名'hostname' = '<yourHostname>',-- 端口號'port' = '3306',-- 賬號'username' = '<yourUsername>',-- 密碼'password' = '<yourPassword>',-- 數據庫名稱'database-name' = '<yourDatabaseName>',-- 表名'table-name' = '<yourTableName>'
);
??可以說是毫無差別,事實上就是一模一樣的 DDL 語句,只不過 WITH 參數內聲明了不同的連接器類型、及部分結果表特有的元數據。實現原理也與上一章提到的流表對偶性和持續查詢息息相關,這里還是按下不表。
??有了結果表連接器,就可以將計算結果寫入特定的存儲介質中。具備讀/寫的能力,就只差計算了。
2.1.3 Transform - 算子
??Flink 精髓之處就在于大量的內置函數,而每個函數、每步轉換都可以稱為一個算子,對算子做組合就是 Transform。
??說半天其實就是在寫 SQL,老本行了,這也是為啥上文說會 SQL ≈ 會 Flink。
BEGIN STATEMENT SET
;INSERT INTO `sink`
SELECTid AS subscription_id,type AS subscription_type,age AS user_age,trim(sexual) AS user_sexual,CASEWHEN age < 18 THEN 1ELSE 0END AS is_minor
FROM `source`END;
??如上代碼塊,只比普通 SQL 多了寫入邏輯開始/結束的聲明(該聲明在只有一條 INSERT 語句時可以不加,多條 INSERT 時需要用該聲明括起來),具體寫法和內置函數算子(見官方文檔:https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/table/functions/systemfunctions/)這里不作贅述。
??「算子」篇主要聊聊 Flink 最強大的算子——時間窗口算子,這是使得實時計算引擎如此不同的根本所在。
??「時間」是 Streaming 的丈量尺度(Streaming 中每個元素,都對應絕對時間坐標軸上一個點),也是實時性的體現基準(實時性強弱計算公式: m = T c u r r ? T e v e n t m = T_{curr} - T_{event} m=Tcurr??Tevent?,m 越小實時性越強),是至高神一般的存在。
??在 Batch/離線計算中,時間就顯得沒那么重要——數據源天然被劃分好了時間屬性(有界數據源,「界」通常就是時間邊界,或是可以轉換成時間邊界),時效性通常不作強要求(通常采取 T 計算 T - 1 數據,有延誤可以通過重跑補償)。
??正是由于「時間」在 Flink 中的崇高地位、與人們對計算實時性的強要求不謀而合,致使大家選擇了 Flink。所以,是我們選擇了時間,而非時間選擇了我們。
??所以,Flink 到底為什么需要時間?
2.1.3.1 時間
??脫離時間談實時性沒有意義、甚至談流計算也沒有意義——沒有人需要從盤古開天辟地起的某個指標,通常需要的是“本月某品類產品的營業額”、“當日某景區的客流量”、“當前小時某工廠制造元件的壞品率”;也沒有人2024年看1995年的指標,人們更想感知一瞬間的實時變化趨勢。
??所以 Flink 通常將「時間」作為計算起止的界限,Streaming 沒有邊界,必須有人為限定的邊界作為計算觸發條件,例如上面提到的本月/當日/當前小時。
??時間的精準程度直接決定了計算結果的精準程度,試想元素亂序(某商品最近一次的成交價格,先產生的元素由于網絡異常后到達)、元素延遲到達(某商品近一小時內的總成交額,部分元素時間延遲導致被劃分到錯誤的時間窗口,甚至直接丟棄)會對計算會造成多大影響。
??因此 Flink 提供了「處理時間 Processing Time」和「事件時間 Event Time」。
??「處理時間」是 Flink 所能提供最簡單的時間屬性,可以簡單理解為機器的系統時鐘,使用上沒有任何心智負擔。但同時也帶來了最差的保障性——當元素流入的先后順序并非其原本的生產順序(如數據源網絡異常消息延遲下發,或不同機器節點由于負載情況不同、出現了消費吞吐量差異,發往下游順序錯亂),Flink 完全無法感知。
??因此更常用的是「事件時間」,通常由使用者自行將時間屬性寫入元素內,再于Flink中提取對應屬性作為元素的時間戳。如此一來,哪怕元素以混亂的時鐘順序進入 Flink,也能用事件時間重新扭轉。
??但這只解決了亂序,還有更致命的延遲。這里涉及一個更復雜的概念:Watermark 數據水位,專門用于解決延遲問題,后續會重點介紹。
??了解了時間在 Flink 中的重要性,Flink 對時間的使用更是得心應手。
2.1.3.2 滾動窗口
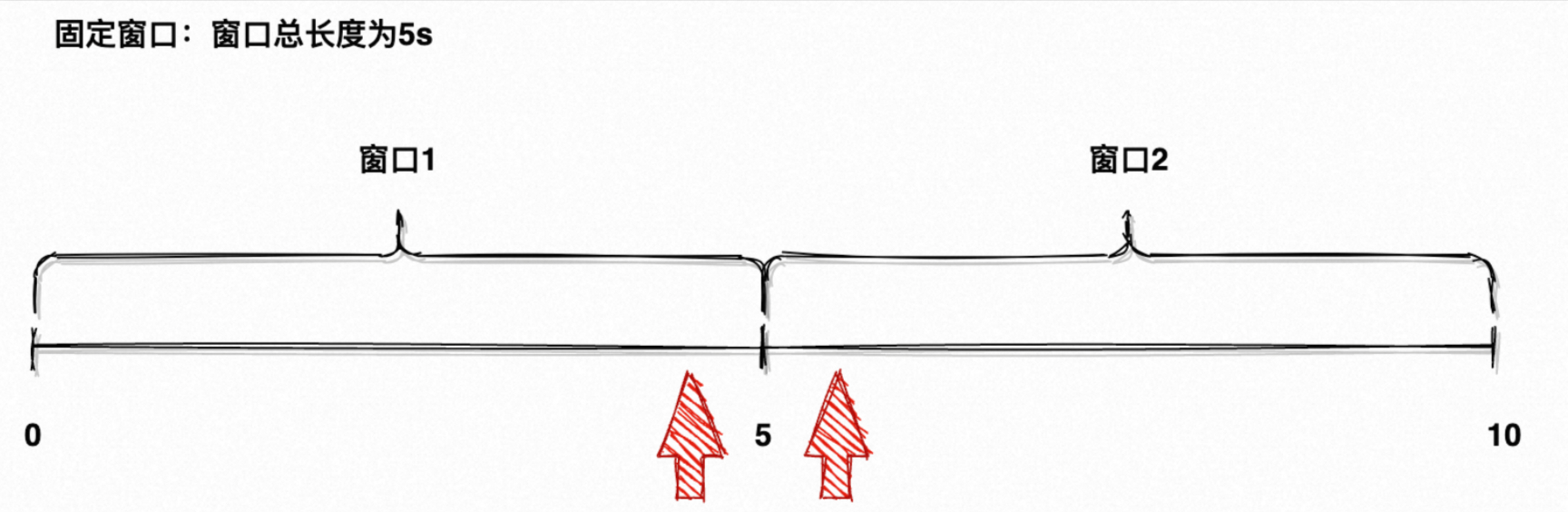
??上一章提到“沒有人需要從盤古開天辟地起的某個指標”,指標通常帶有確定的時間界限:天級、小時級、分鐘級、秒級,就是在為元素劃分好「時間窗口」,再計算每個窗口內的指標,而最簡單常用的時間窗口就是「滾動窗口 Tumble」。
??「滾動窗口」通常具有固定的大小,且每個窗口不重疊,如圖5所示的時間軸就由 [0, 5) 、 [5, 10) 兩個滾動窗口組成,它們沒有任何重疊部分。
??
??指定元素時間對應字段和時間窗口長度,元素就被分組到了所處時間窗口內,此時再計算對應窗口內的數據,如求聚合值、最大最小值等。
CREATE TEMPORARY TABLE user_clicks(username varchar,click_url varchar,eventtime varchar, ts AS TO_TIMESTAMP(eventtime),WATERMARK FOR ts AS ts - INTERVAL '2' SECOND --為Rowtime定義Watermark。
) WITH ('connector'='sls',...
);CREATE TEMPORARY TABLE tumble_output(window_start TIMESTAMP,window_end TIMESTAMP,username VARCHAR,clicks BIGINT
) WITH ('connector'='datahub' --目前SLS只支持輸出VARCHAR類型的DDL,所以使用DataHub存儲。...
);INSERT INTO tumble_output
SELECT
TUMBLE_START(ts, INTERVAL '1' MINUTE) as window_start,
TUMBLE_END(ts, INTERVAL '1' MINUTE) as window_end,
username,
COUNT(click_url)
FROM user_clicks
GROUP BY TUMBLE(ts, INTERVAL '1' MINUTE),username;
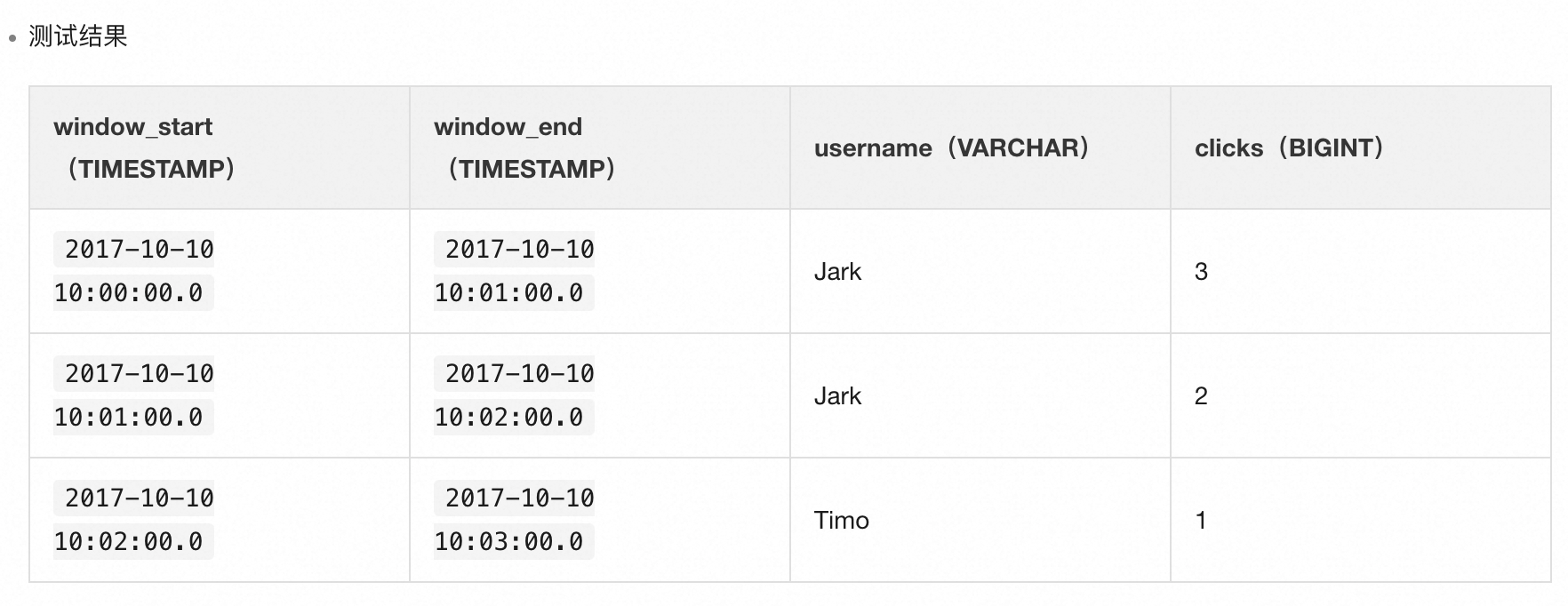
??如上代碼塊,TUMBLE 函數有兩個參數:
- 第一個參數“ts”代表元素時間戳字段(時間字段需要在連接器中指定,可用處理時間或事件時間);
- 第二個參數“INTERVAL ‘1’ MINUTE”意為窗口長度為1分鐘。
??再配合 TUMBLE_START/TUMBLE_END 函數獲取窗口起始/結束時間,便可以得到每個窗口內的計算結果(如圖5)。
??
2.1.3.3 滑動窗口
??「滑動窗口 Hop」比滾動窗口更絲滑,其由長度 + 步長兩個參數組成,長度代表計算窗口的總長度,步長代表每次滑動的步長。
??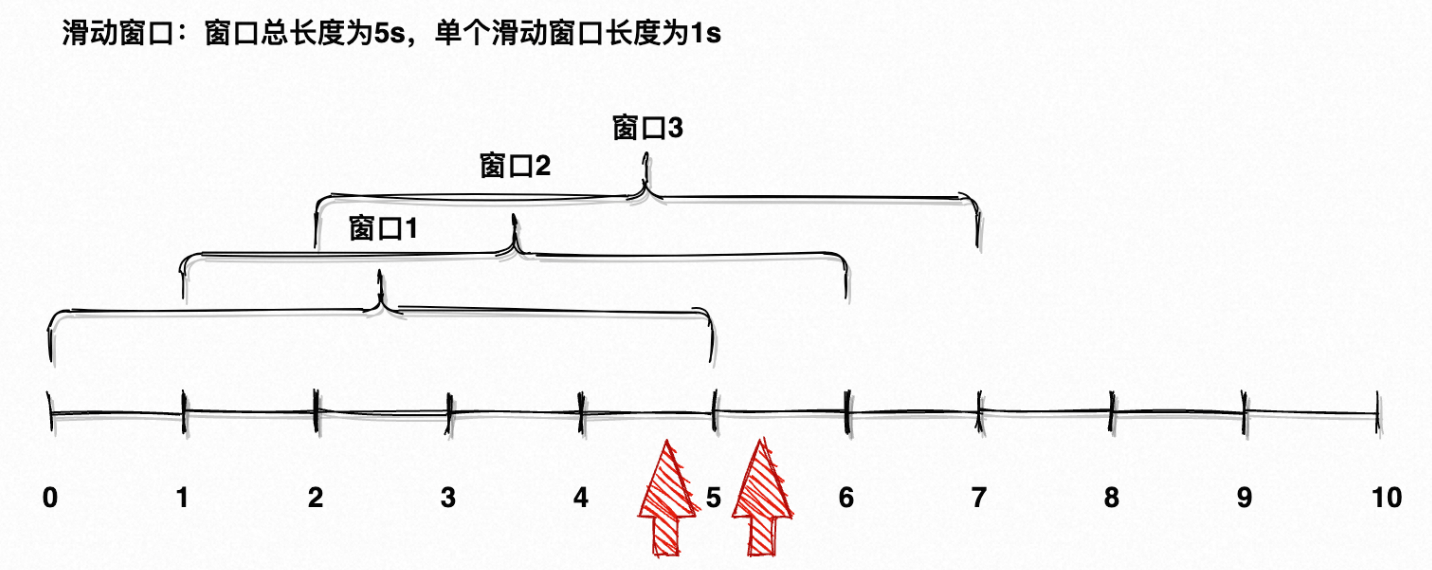
??如圖7所示是長度為 5s、步長為 1s 的滑動窗口,每次滑動步長1s;這意味著每個滑動窗口會與上個窗口有 4s 的重疊,數據的變化會更加平滑(具體原理可以自行搜索)。
CREATE TEMPORARY TABLE user_clicks (username VARCHAR,click_url VARCHAR,eventtime VARCHAR, ts AS TO_TIMESTAMP(eventtime),WATERMARK FOR ts AS ts - INTERVAL '2' SECOND --為Rowtime定義Watermark。
) WITH ('connector'='sls',...
);CREATE TEMPORARY TABLE hop_output (window_start TIMESTAMP,window_end TIMESTAMP,username VARCHAR,clicks BIGINT
) WITH ('connector'='datahub' --目前SLS只支持輸出VARCHAR類型的DDL,所以使用DataHub存儲。...
);INSERT INTOhop_output
SELECTHOP_START (ts, INTERVAL '30' SECOND, INTERVAL '1' MINUTE),HOP_END (ts, INTERVAL '30' SECOND, INTERVAL '1' MINUTE),username,COUNT (click_url)
FROMuser_clicks
GROUP BYHOP (ts, INTERVAL '30' SECOND, INTERVAL '1' MINUTE),username;
??HOP 函數使用方法與滾動窗口基本一致,只是多傳入了一個步長。如上代碼塊代表窗口長度與步長分別為1分鐘和30秒,意為每30秒計算一次過去1分鐘的數據,與滾動窗口最顯著的差異就是有30秒的窗口重合。
??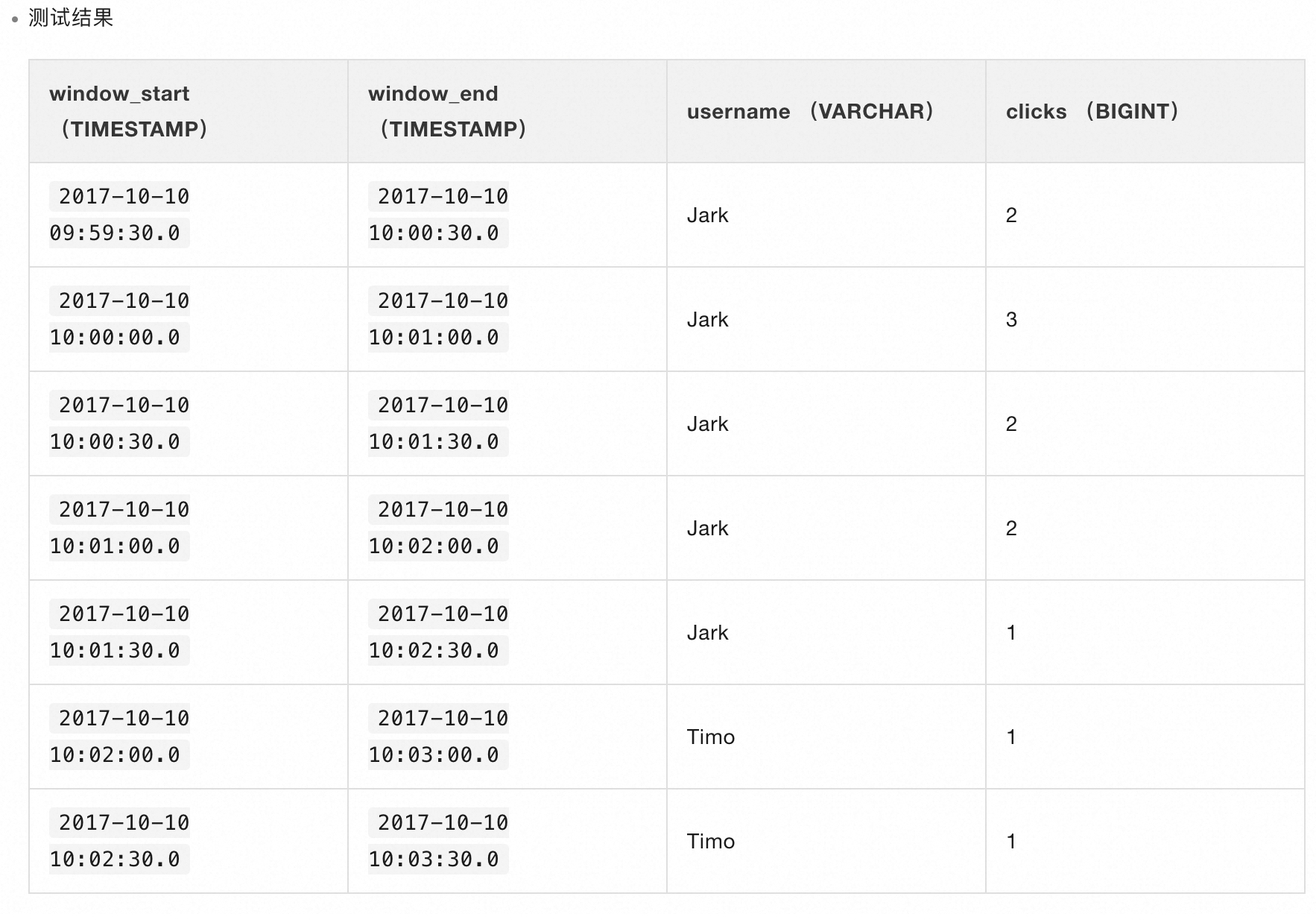
??從圖7的計算結果可以看出,每30秒觸發一次計算,計算過去1分鐘內窗口的數據。
2.1.3.4 會話窗口
??「會話窗口 Session」比較有意思,沒有窗口大小、也沒有窗口重疊,而是以會話開啟/斷開時機作為窗口。會話窗口會定義一個時間間隔(Gap),如果在該時間間隔內有元素產生,則會一直續期該窗口,反之則關閉窗口、輸出結果。
??以時間間隔30分鐘舉個例子:
- 00:00 元素進入,開啟會話窗口,此時會話窗口為 [00:00, 00:30] ;
- 00:15 元素進入,續期窗口,此時會話窗口為 [00:00, 00:45] ;
- 00:35 元素進入,續期窗口,此時會話窗口為 **[00:00, 01:15] **;
- 01:15 會話窗口關閉,輸出結果;
- 01:35 元素進入,開啟新會話窗口,此時會話窗口為 [01:35, 02:05] ;
- ······
CREATE TEMPORARY TABLE user_clicks(username varchar,click_url varchar,eventtime varchar, ts AS TO_TIMESTAMP(eventtime),WATERMARK FOR ts AS ts - INTERVAL '2' SECOND --為Rowtime定義Watermark。
) WITH ('connector'='sls',...
);CREATE TEMPORARY TABLE session_output(window_start TIMESTAMP,window_end TIMESTAMP,username VARCHAR,clicks BIGINT
) WITH ('connector'='datahub' --目前SLS只支持輸出VARCHAR類型的DDL,所以使用DataHub存儲。...
);INSERT INTO session_output
SELECT
SESSION_START(ts, INTERVAL '30' SECOND),
SESSION_END(ts, INTERVAL '30' SECOND),
username,
COUNT(click_url)
FROM user_clicks
GROUP BY SESSION(ts, INTERVAL '30' SECOND), username;
??會話窗口通常用于用戶短活躍時間內的數據統計,如用戶登錄以來所有的瀏覽記錄,超過10分鐘沒有操作視為會話斷開,停止統計。
2.1.3.5 OVER 窗口
??「OVER 窗口」比較特殊,它認為每個元素都是一個窗口,每個窗口都有自己的時間戳;實際分為兩種模式,合并過去 N 個窗口(實際就是 N 個元素)/合并過去N分鐘對應的窗口,再進行最終結果計算。并且,它是唯一可以實時觸發的窗口函數,前面3個窗口函數的觸發時機都是窗口結束,而 OVER 窗口可以來一個輸出一條、來一個輸出一條。
??有點抽象,直接通過例子來看吧。
-- 以Bounded ROWS OVER Window場景為例。
-- 假設,一張商品上架表,包含有商品ID、商品類型、商品上架時間、商品價格數據。
-- 要求輸出在當前商品上架之前同類的3個商品中的最高價格。SELECTitemID,itemType,onSellTime,price, MAX(price) OVER (PARTITION BY itemType ORDER BY onSellTime ROWS BETWEEN 2 preceding AND CURRENT ROW) AS maxPrice
FROM tmall_item;
??如上代碼塊使用了 Rows Over Window,以 itemType 為分區鍵、以 onSellTime 為時間字段倒序排序、向前追溯2個窗口,計算 Max(price)。簡單來說,就是以一個時間字段排序,往前追溯 N 行作為一個窗口計算。
-- Bounded RANGE OVER Window場景為例。
-- 假設一張商品上架表,包含有商品ID、商品類型、商品上架時間、商品價格數據。
-- 需要求比當前商品上架時間早2分鐘的同類商品中的最高價格。SELECT itemID,itemType, onSellTime, price, MAX(price) OVER (PARTITION BY itemType ORDER BY onSellTime RANGE BETWEEN INTERVAL '2' MINUTE preceding AND CURRENT ROW) AS maxPrice
FROM tmall_item;
??如上代碼塊使用了 Range Over Window,以 itemType 為分區鍵、以 onSellTime 為時間字段倒序排序、向前追溯2分鐘,計算 Max(price)。簡單來說,就是以一個時間字段排序,往前追溯N分鐘內元素作為一個窗口計算。
??數據計算通常由「時間量級」和「指標聚合」兩部分組成,Flink 窗口函數大大簡化了時間計算語義,再配合豐富的內置函數,使其變得極容易上手。
2.1.4 Join - 表連接
??「表連接 Join」大家都不陌生,通過特定條件構建表與表之間關聯關系,達成補充/拓寬數據維度的效果。作為數據庫廣為流傳的傳統藝能,Flink SQL 自然也是支持的。
??傳統的 Join(換句話說是批處理中的 Join)是兩張表通過某個鍵進行邏輯關聯,如下代碼塊是將訂單表 order_record 與用戶信息表 user_info_record 通過用戶id進行關聯,補充訂單表中不存在的用戶信息。
SELECT
A.id,
A.order_id,
A.price,
A.user_id,
B.user_name,
B.user_sexual,
B.user_age
FROM order_record A
LEFT JOIN user_info_record B
ON A.user_id = B.user_id
ORDER BY A.gmt_create desc
LIMIT 100;
??在關聯關系左側的表通常被稱為「事實表 Fact Table」,右側的表為「維表 Dimension Table」。依據數據庫第三范式:獨立性,事實表中通常只存儲與當前行為強相關的信息(當然這并不絕對,有時也會視情況冗余一些字段),因此需要維表進行事實表的維度補充。
??在流式計算中構建表連接顯然更具有挑戰性——事實表是一個流,隨時都會發生變化,表連接也要隨時觸發嗎?維表在流式計算中又該如何描述、也能夠被定義為流嗎?
2.1.4.1 維表 & 流表
??維表相較事實表有幾個顯著差異:
- 變化頻率更低:相較于事實表隨時可能插入/修改,維表的信息相對固化,如城市編碼信息、用戶地址信息。
- 維度更收斂:事實表通常含括一種行為對應的所有信息,如訂單包含商品、用戶、物流、評價、交易等信息,而一張維表通常只會包含一個維度的信息。
- 數量級更小:相較事實表來說,一個維度通常不會有過多的可選項(甚至是枚舉值),因此數據量會少很多。
??在傳統數據倉庫中,維表與事實表的差異只存在于邏輯層面;但在流式計算中,維表與流表基本是兩個獨立的概念,因為「時間」是流式計算的一等公民。Flink 為何要花這么大功夫區分這兩種語義,大家不妨先自己思考一下。
??從維表的定義其實就能看出一二,維度是對事實的補充,這意味著維表不會作為驅動計算的主體,自然也就沒必要像流一樣實時流入元素。
??其次,維表數據的變化頻率較低,通常在小時級或天級;實時性不高的數據可以采取一定的緩存措施,避免每次查詢都產生網絡 IO,這也與流的強時效性不同。
??最后最重要的一點,維度是事實的附庸,因此維度的時間來源于事實的時間;換言之,維度不具有獨立的時間屬性,或者說他自身具有的時間毫無意義,必須依附于事實才有意義。說得再通俗一點,今天發生的事實,只有今天的維度于其才有意義。
| Timestamp | Streaming emit | Dimension version | |
|---|---|---|---|
| 1 | 2024-06-01 00:00:00 | 2024-06-01 00:00:00 | 2024-06-01 00:00:00 |
| 2 | 2024-06-01 06:00:00 | 2024-06-01 06:00:00 | 2024-06-01 06:00:00 |
| 3 | 2024-06-01 12:00:00 | 2024-06-01 12:00:00 | 2024-06-01 12:00:00 |
| 4 | 2024-06-01 18:00:00 | 2024-06-01 18:00:00 | 2024-06-01 18:00:00 |
| 5 | 2024-06-02 00:00:00 | 2024-06-02 00:00:00 | 2024-06-02 00:00:00 |
| 6 | 2024-06-02 00:00:00 | 2024-06-01 00:00:00 (亂序) | 2024-06-02 00:00:00 |
??有點繞,舉個例子大家就懂了。流中元素因為一些原因出現了延遲,6月1日發生的事件延遲了整整一天、于6月2日才流入下游,維表數據此時已經更新到了最新版本6月2日;但對于延遲的事件來說,它需要的維度一定是6月1日,6月2日的維表數據確實是最新鮮的、最實時的,但沒有意義。
??對于這個例子而言,查詢條件是:關聯鍵 + 事件時間,也就是找到歷史版本的時間快照。因此維表在Flink當中其實是「歷史表 Temporal Table」,是種具有時間/版本屬性的表,這樣就滿足了找到任何時間線版本、而非最新版本數據的訴求,這是流無法實現的。
2.1.4.2 維表/歷史表連接器
??為了區分這類特殊的數據源,Flink 提供了「維表/歷史表連接器」。
create TEMPORARY table `dimension_table`
(`user_id` VARCHAR,`user_name` VARCHAR,`user_age` VARCHAR,`user_sexual` VARCHAR,`user_weight` VARCHAR,PRIMARY KEY (`user_id`) NOT ENFORCED
)
with ('connector' = 'mysql','endpoint' = '****','project' = '****','tablename' = '****','accessid' = '****','accesskey' = '****'-- 讀取最大記錄數,最好大于實際值,'maxRowCount' = '100000000'-- 動態最大分區,'partition' = 'max_pt()'-- 緩存策略,僅支持ALL,'cache' = 'ALL'-- 緩存超時時間,默認空,即永不過期 + 不reload緩存;需要設置該過期時間,才會刷新新分區!!!,'cacheTTLMs' = '3600000'
)
;
??維表連接器在元數據上多了數據緩存策略相關配置,維表數據通常固化,沒必要每次都去發起查詢(向外部存儲介質發起網絡 IO),因此可以采用一定的緩存策略:
- None(默認值):不使用緩存,每次都發起查詢,一般只有在實時性極強的維表場景才會使用。
- LRU:最近使用緩存策略,配合緩存大小、緩存超時時間使用。
- ALL:全量緩存策略,在作業啟動時一次性將所有維表數據讀取進內存,配合緩存超時時間使用。
??維表對作業的影響通常在于查詢效率以及內存占用,需要根據維表數據特性選取合適的維表存儲介質(更推薦 KV 型存儲,如 HBase/Redis)和緩存策略,筆者在這里就踩了許多坑,后續會專門介紹。
2.1.4.3 流表 Join
??流表 Join 是將流與維表進行關聯,需要構建與維表主鍵的關聯關系并指定時間屬性。
SELECT
A.id,
A.order_id,
A.price,
A.user_id,
B.user_name,
B.user_sexual,
B.user_age
FROM order_record A
LEFT JOIN user_info_record FOR SYSTEM_TIME AS OF PROCTIME() AS B
ON A.user_id = B.user_id??“FOR SYSTEM_TIME AS OF PROCTIME()”意為獲取處理時間時刻的表快照,Flink 目前只支持使用處理時間,后續會支持事件時間。
2.1.4.4 雙流 Join
??雙流 Join 就有點意思了,筆者第一次聽到這個玩意兒的時候腦子里完全沒概念,這兩邊都是無界數據流咋 join 啊?誰 join 誰啊?
??Join 說白了就是拿著一邊的數據去另一邊找,在流表 Join 場景下為拿著流里的元素去維表里找,因為只有流驅動計算;雙流 Join 本質就是相互的過程,左側流元素來了去右側流里找找、右側流元素來了去左側流里找找。前提是兩側流的元素都得先保存下來,才能實現一側來了去另一側找,這就引出了 Flink/流式計算狀態 State 這一概念。
??Flink 十分依賴狀態,比如現在討論的雙流 Join,就需要將左右側流的元素分別維護在自己的狀態中,待任意一側元素流入、去對側的 State 中進行 Join 計算,這被叫作「算子狀態 OperatorState」。大部分算子都會維護一份自身的 State(也叫作有狀態算子 Stateful Operator),例如上文提到的 Window 算子,也需要 State 存放時間窗口內的元素。一來是算子確實需要數據暫存的區域;二是算子需要保存中間結果,計算通常建立在中間結果基礎之上,例如求和算子不可能每次都對全量數據發起重新計算,這不現實。
??言歸正傳,畫個圖來理解一下雙流 Join 的流程,仍然以上面的訂單表 Join 用戶信息表為例。
??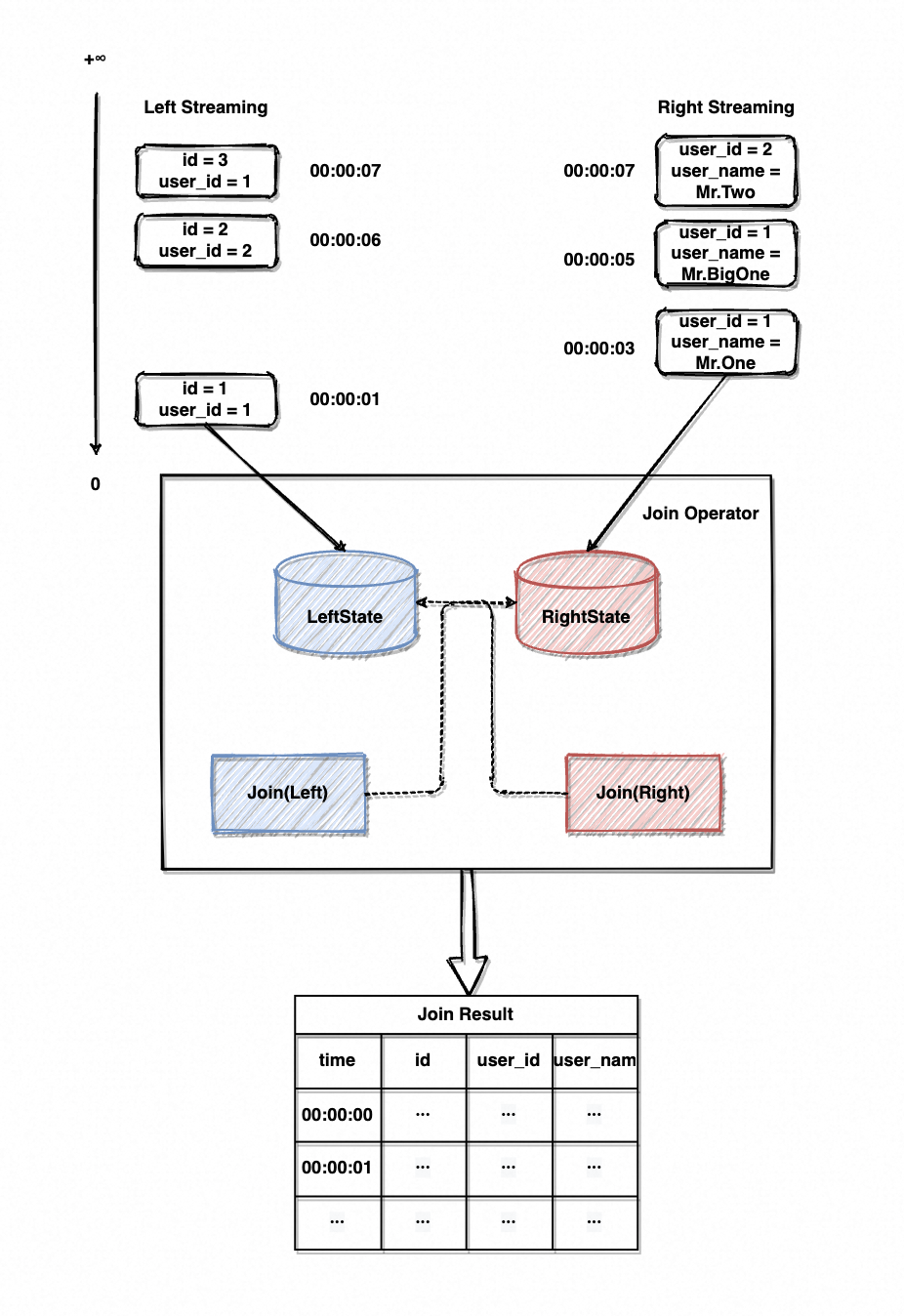
??在雙流 Join 場景下,Join 算子會維護兩側流的 State(如圖8中的 LeftState/RightState)。元素流入 Join 算子后會先暫存進 State 中,再觸發 Join 計算、去另一側的 State 中尋找可關聯的元素。
??如圖9的雙流 Join 示例,左側流會流入訂單id/用戶id、右側流會流入用戶id/用戶名,以用戶id作為關聯鍵進行 Join 計算。Join 過程示意大致如下:
?? | time | id | user_id | user_name | is_retract |
|---|---|---|---|---|---|
| 1 | 00:00:00 | null | null | null | null |
| 2 | 00:00:01 | 1 | 1 | null | false |
| 3 | 00:00:02 | null | null | null | null |
| 4 | 00:00:03 | 1 | 1 | null | true |
| 5 | 1 | 1 | Mr.One | false | |
| 6 | 00:00:04 | null | null | null | null |
| 7 | 00:00:05 | 1 | 1 | Mr.BigOne | false |
| 8 | 00:00:06 | 2 | 2 | null | false |
| 9 | 00:00:07 |
| 2 | 2 | null | true |
| 10 | | 2 | 2 | Mr.Two | false |
| 11 | | 3 | 1 | Mr.One | false |
| 12 | | 3 | 1 | Mr.BigOne | false |
??表頭從左至右分別代表行數、時間、訂單id、用戶id、用戶名、是否為回撤操作,再來逐行分析:
- 無事發生。
- 左流來了一個元素、放入 LeftState 中,去 RightState 尋找 user_id = 1 的記錄,未找到所以 user_name 補 null。最終向下游輸出 1/1/null 。
- 無事發生。
- 右流來了一個元素、放入 RightState 中,去 LeftState 尋找 user_id = 1 的記錄,找到1條記錄。首先可以輸出一條 1/1/Mr.One 的記錄,但 LeftState 中該元素已經被計算并產生了結果(對應第2行的 1/1/null ),且該結果是不完整的結果;在右流已經能夠補充左流時,之前輸出的結果顯然是不準確的,應當以當前結果為最終結果。
??因此,實際產生了2次結果輸出,一次正向的輸出(1/1/Mr.one)、一次逆向的撤回(1/1/null),這種撤回輸出也叫回撤 Retract,是一種特殊的輸出流,可以將之前輸出的不完整/錯誤結果撤回。 - 同4。
- 無事發生。
- 右流來了一個元素、放入 RightState 中,去 LeftState 尋找 user_id = 1 的記錄,找到1條記錄;最終向下游輸出 1/1/Mr.BigOne。
- 左流來了一個元素、放入 LeftState 中,去 RightState 尋找 user_id = 2 的記錄,未找到所以 user_name 補null。最終向下游輸出 2/2/null 。
- 右流來了一個元素、放入 RightState 中,去 LeftState 尋找 user_id = 2 的記錄,找到1條記錄。
??場景同4,最終向下游輸出正向的 2/2/Mr.Two、逆向的 2/2/null。 - 同9。
- 左流來了一個元素、放入 LeftState 中,去 RightState 尋找 user_id = 1 的記錄,找到2條記錄。最終向下游輸出 3/1/Mr.One 、 3/1/Mr.BigOne。
- 同11。
??Left Join/Right Join/Inner Join本質上都是一樣的過程,以 State 作為狀態存儲,由元素流入事件觸發計算,輸出正向(輸出)/逆向(撤回)事件。
??但這個過程顯然有脆弱的環節,比如可預見的 State 容量膨脹、大量輸出 null 事件產生的數據傾斜、多流 Join 是否會產生新的風暴?后續調優環節會探討這些問題。
2.2 流式計算 SQL
??看完 Flink SQL 章節,相信同學們對于「如何寫」已經有了底氣,但要「如何寫好」又是另一門學問。本文一直在強調“流式計算是一項技術、更是一種理念”,流式計算傾向于描述:對流這種特殊載體的處理流程以及對變化事件的響應模式。
??為何要這么說,還是可以拿更傳統的批處理作對比。
??批處理是完美的面向過程編程,對已知的數據分步驟處理、朝向最終期望的結果進發。可以發現當處理主體不可變時,唯一需要考慮的就是如何清晰地描述步驟,五步化作三步也無所謂,甚至一步到位也 OK。
??但這套理念套在 Streaming 上顯然不成立,流式計算的主體是事件,是隨時可產生、可變化、可伸縮的;不管你愿不愿意,事件/元素會不斷流入。這意味著必須明確每個處理環節該做什么,處理好所有異常、邊界、邏輯,否則流會因為某個環節的異常而整個 Crash。
??這種場景下其對于 SQL 的要求便更嚴格,SQL 的好壞直接影響到了執行計劃的生成,而執行計劃又對應了無數個執行節點,節點間的影響是相互的且無法估量的。如同一條由無數中轉站連接的航道,任一站點異常都會影響整條航道的正常運轉(例如產生反壓 BackPressure,后續章節會介紹)。并且這對后續排查問題是極為重要的,如果作業的執行計劃十分清晰,你就能快速定位到異常的執行節點,通過優化節點配置/算子來消除問題。
??因此,在編寫流式計算 SQL 時有幾個原則:
- 構思清晰的執行計劃
- 以事件為主體的響應式處理
- 盡可能編寫完美的函數
??也是老生常談的「低耦合,高內聚」,盡可能保證每步處理的原子性。
??在 Flink SQL 中,可以采用「視圖 View」來清晰地描述計算步驟、編寫流式 SQL。舉個簡單例子,現在要計算訂單中不同城市用戶、對于不同消費金額的偏向水平,俗稱城市級消費水平。
??這個過程可以描述為:
- 按業務對于金額的分階進行訂單金額劃分,這里以每百元作為分階模式。
- 按省份對訂單區域進行劃分,需要將省份編碼轉換為對應名稱。
- 統計不同城市、不同消費金額階級的總數。
//簡單的數據提取
CREATE TEMPORARY VIEW `original`
AS SELECTtotal_price AS price,province_code AS province
FROM `order_info`
;//數據轉換
CREATE TEMPORARY VIEW `price_rank_calculate`
AS SELECTFLOOR(price / 100) AS price_rank,code_to_name(province) AS province
FROM `original`
;//group by
CREATE TEMPORARY VIEW `price_rank_group_by`
AS SELECTprovince,price_rank,count(*) as total_count
FROM `price_rank_calculate`
GROUP BY province, price_rank
;//sink
BEGIN STATEMENT SET
;INSERT INTO `result`
SELECT*
FROM `price_rank_group_by`
;END
;
??一定要將過程描述清晰,千萬不要擔心步驟過多(或者是字數過多)對性能產生影響,Flink 會根據 SQL 生成最優執行計劃(例如進行算子合并等),因此描述得越清晰越細致、對于執行計劃的生成就越有利。
3 江湖少俠:Flink 核心概念
??本章會介紹是什么支撐了 Flink 以及流式計算、是什么使它變得如此美麗且不同,前面賣的所有關子,都會在這一章揭曉。筆者相信,這會成為你真正走進 Flink 以及 Streaming Compute 至關重要的一步。
3.1 流表對偶性 Duality
??章節「2.1.1 Source - 源表連接器」中提到,僅需一句 DDL,就可以完成流式數據讀取、數據結構映射。Flink 依靠 SQL 層面就了實現這樣的語義轉換,這實際是構建了一套流與表之間的映射協議,即本章的內容「流表對偶性 Duality」。
3.1.1 MySQL binlog
??binlog(Binary Log,二進制日志) MySQL 中極為重要的組件,是實現數據恢復、主從同步、增量監聽的核心。binlog 記錄了數據庫所有執行的 DDL 與 DML,簡言之為所有的變更操作。
??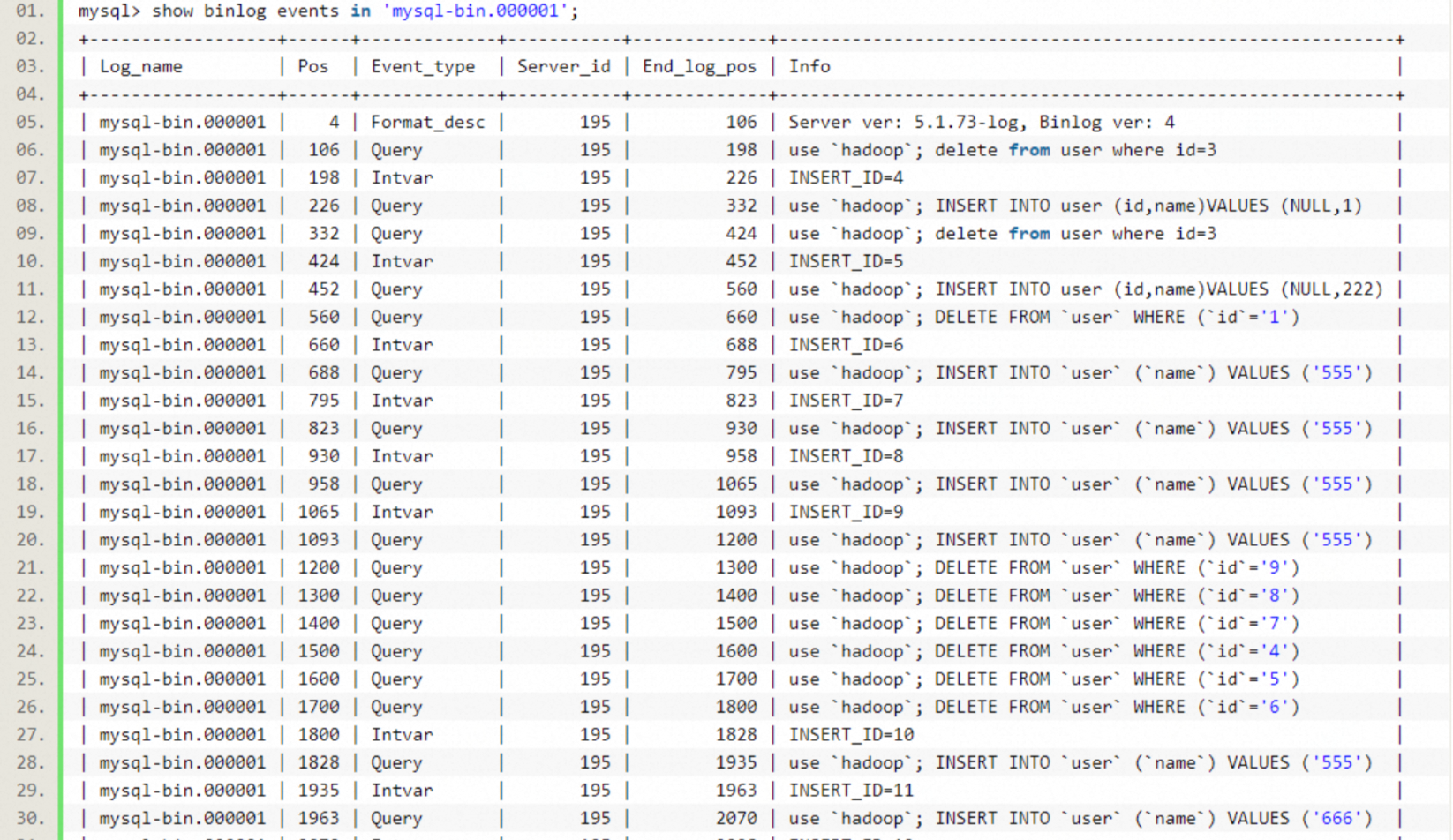
??如圖 9 所示,binlog 將所有數據庫操作視為事件并記錄操作內容(具體見 binlog 的3種格式,Statement/Row/Mixed)。
# at 447
#170330 14:19:25 server id 10 end_log_pos 607 CRC32 0x321d4518 Update_rows: table id 133 flags: STMT_END_F
### UPDATE `sbtest`.`sbtest`
### WHERE
### @1=1
### @2=0
### @3=''
### @4='qqqqqqqqqqwwwwwwwwwweeeeeeeeeerrrrrrrrrrtttttttttt'
### SET
### @1=1
### @2=1
### @3=''
### @4='qqqqqqqqqqwwwwwwwwwweeeeeeeeeerrrrrrrrrrtttttttttt'
??操作事件具體內容如上代碼塊,記錄了操作時間與操作內容,例如代碼塊內就記錄了今天 14:19:25 執行的一條 UPDATE 語句。這也是為何通過 binlog 可以實現數據同步等功能,擁有 binlog 即擁有數據庫進行的所有操作記錄,通過回放 binlog 就可以還原完整的數據庫數據。
3.1.2 流表對偶
??對傳統數據庫而言,DDL 只是用于描述表元數據的語句,描述的是一張表靜態的結構信息。而通過 binlog 回放可以發現,表的變更操作可以用帶時間的事件描述、表也可以通過回放操作事件得到最終的變更結果。
??動態表可由 DDL(靜態結構) + binlog(動態變更事件) 描述,動態表的變化趨勢可以視為流,而流的處理結果又構成了表。這就是流與動態表的對偶性:
Dynamic Table = DDL + binlog <=> Streaming
??因此在 Flink 中,DDL 并非簡單描述了表的結構,而是聲明了動態表的結構與變更事件;又由于動態表與流的對偶性,這就相當于描述了流。
3.2 持續查詢 Continuous Queries
??Flink 利用 DDL 描述了流,下面則要讀取流并進行處理,Flink 又是如何實現通過 DML 語句讀取并處理流的呢?
?? 在 MySQL 中執行“SELECT * FROM table_a”,會得到當前時間節點表的結果,且只會執行一次;在 Flink 中執行效果顯然不同,每當元素流入就會觸發計算,并且計算得是最新一條記錄。可以將這兩種效力不同的查詢稱為「靜態查詢/持續查詢」,前者僅在調用時觸發一次、得到的是快照結果,后者每次元素流入都會觸發、得到的是當前記錄。
??顯然,Flink 用 DML 語句描述了后者、也就是持續查詢的過程。再結合章節「3.1 流表對偶性 Duality」所講述,DML 的結果又可以被映射為流,這就組成了完整的計算流程:
- 聲明動態表(Source + DDL)
- 持續讀取動態表(DML)+ 處理最新記錄(Operator)
- 流向下游節點(DML)
- ······
- 輸出結果(Sink)
??利用「流表對偶性」與「持續查詢」,Flink 實現了真正意義上的無損轉換與流式讀取,通過 SQL API 大大降低了流式計算的難度。
3.3 數據水位 Watermark
??章節「2.1.3.1 時間」中提到,Flink 提供了處理時間/事件時間兩種時間語義,同時更加推薦使用事件時間來避免流亂序導致的時間戳混亂。也留下了另一個問題:元素延遲流入該如何處理?
??其實并非所有場景都需要處理元素延遲,例如基于特定 key group by 求和,只要元素最終總會流入、那么最終結果就一定是精準的。這種場景時間屬性不強,所以對延遲不敏感;但不劃分時間窗口進行計算,相當于在求從盤古開天辟地起的某個指標。
??你說時間窗口太復雜,就不用就不用。直接將時間字段也作為 group by 鍵,需要天級就將時間格式化為 yyyyMMdd、小時級就 yyyyMMdd HH,你就說能不能用吧?這種做法確實可以達到目的、也不用考慮亂序和延遲,但并不是優雅實現方式。按理來說,天級時間窗口聚合,一天就 1 條記錄;而照這種方式一天會有 N 條記錄,因為每個元素都會觸發一次計算、下發一次結果,對于作業吞吐以及存儲容量都是非常不利的。
??因此時間屬性相關的聚合計算都應該使用 Window 算子,以時間窗口而非元素作為計算的觸發條件,而使用窗口算子就必須考慮元素的延遲問題,因為達到了窗口邊界就會觸發計算。
??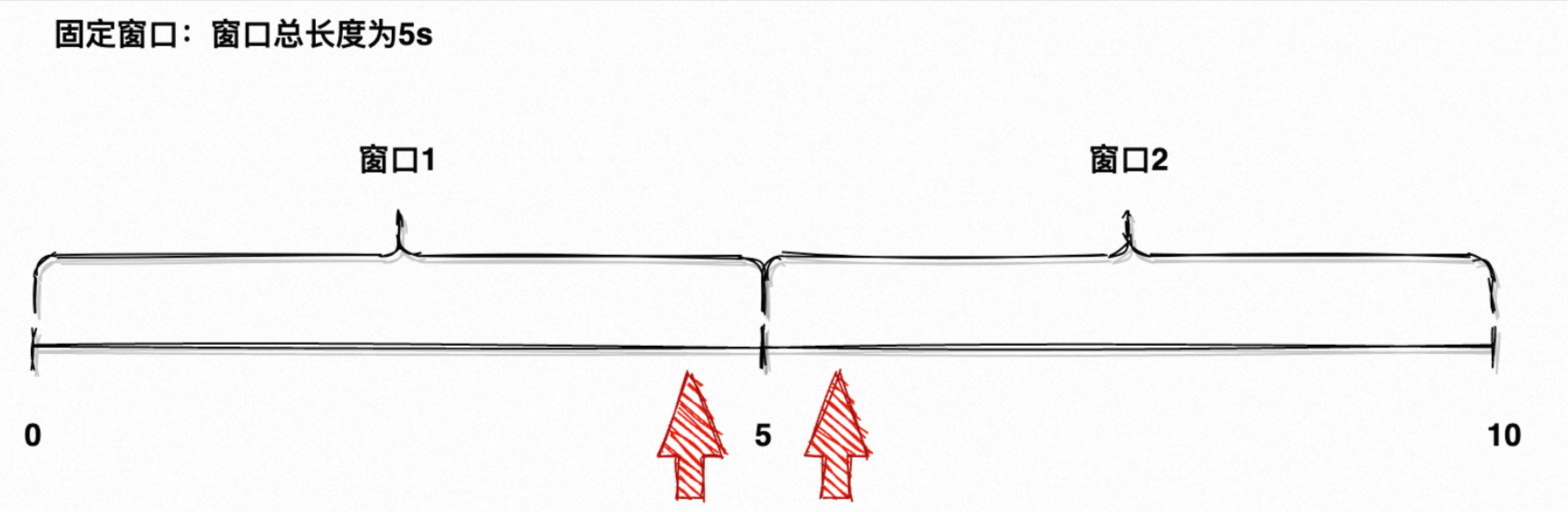
??以章節「2.1.3.2 滾動窗口」窗口長度為 5s 的滾動窗口為例,如圖 10 所示,5s 與 10s 會觸發計算,分別計算 [0, 5)、[5, 10) 窗口內的元素。
??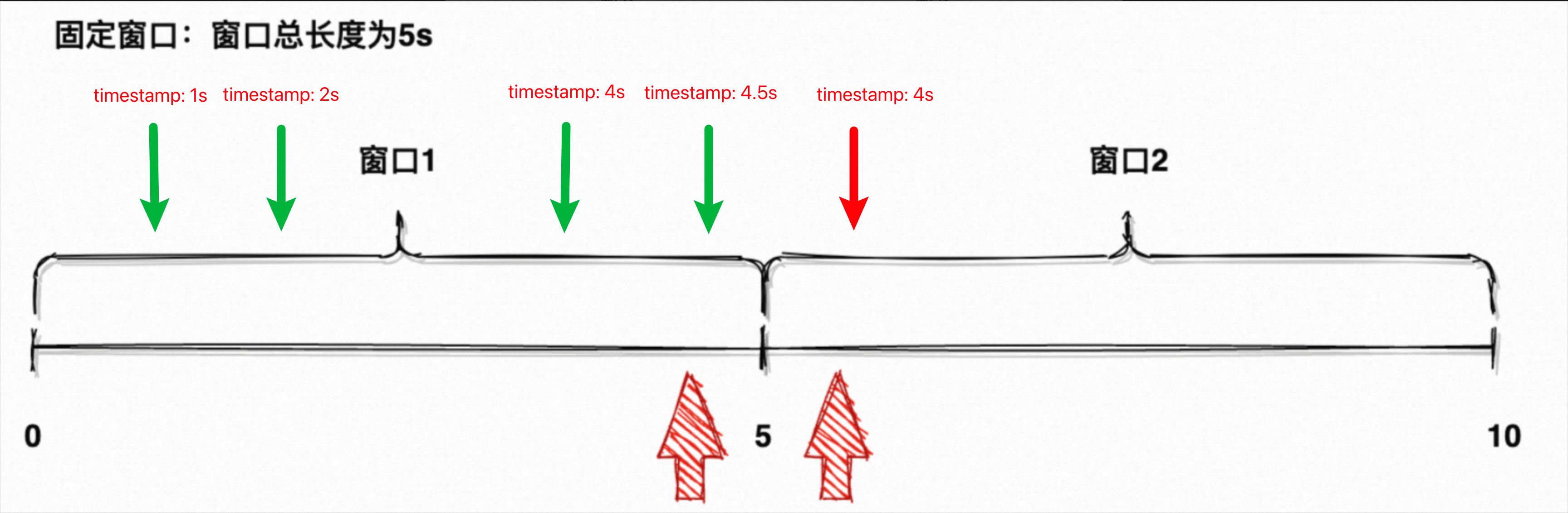
??如圖 11 所示,坐標軸代表機器時鐘、坐標軸上方箭頭代表元素流入。現在發生了可怕的事,這 5 個元素的事件時間都處于 [0, 5) 窗口,但第 4 秒產生的元素因為網絡延遲、5 秒多才流入算子。延遲元素屬于第一個窗口,但它流入時該窗口已經觸發過計算,也不能把它算在第二個窗口內,否則第二個窗口也不準了。這種延遲很常見,你沒法指望事件發生的瞬間就進入 Flink,也不可能指望作業永遠年輕永遠不背壓。如果沒有容錯機制,窗口末端的大部分元素計算都會不準確。
??解決思路其實并不復雜,Window 算子本身在窗口結束就會觸發計算、此時又無法確認窗口內的元素是否全部流入、但又不能一直死等,那索性就給點 buffer,稍微等等再觸發。回到圖 11 的例子,[0, 5) 窗口原本會于 5s 觸發計算,此時最后一個元素是一定會漏掉的;如果給 3 秒的 buffer,窗口于 8s 再觸發計算,就能將延遲 3 秒內的元素含括進去,元素延遲導致的漏算就被大大改善了。
??這種機制就是 Flink 的「數據水位」,在元素流入時基于其事件時間再生成一個水位時間,水位時間會比事件時間小一些(如例子中的 -3s)。
??使用 Watermark 后,Window 算子的觸發時機就不再是時間窗口結束,而是根據事件時間不斷推進系統 Watermark,并判斷 Watermark >= Window 邊界,如果滿足條件、則說明可容忍的最大延遲時間也超過了窗口結束時間,此時可視為窗口結束并觸發計算。后續仍有遲到元素流入,則可以丟棄/再忍一次/收集后統一分析。
??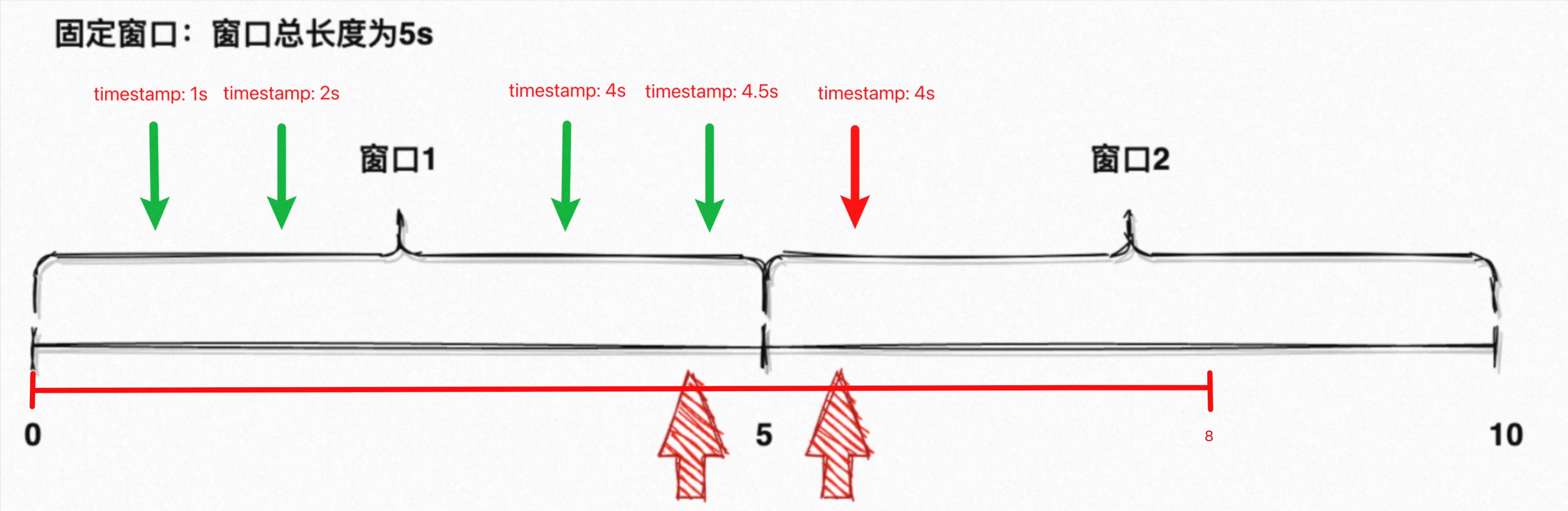
??如圖 12 所示,設置 Watermark = EventTime - 3s:
- 事件時間在 [0, 8) 內的元素都能被 [0, 5) 窗口捕獲,因為 [0, 8) 內生成的 Watermark 都會處于 [0, 5) 窗口;系統 Watermark < 5s,此時不會觸發窗口計算。
- 當 EventTime = 9s 的元素流入,其 Watermark = 6s;系統 Watermark 被推進到 6s,此時 10s > Watermark > 5s,觸發 [0, 5) 窗口計算、繼續收集 [5, 10) 窗口元素。
- 當 EventTime = 10s 的元素流入,其 Watermark = 7s;系統 Watermark 被推進到 7s,此時 Watermark < 10s,繼續收集 [5, 10) 窗口元素。
- 當 EventTime = 12s 的元素流入,其 Watermark = 9s;系統 Watermark 被推進到 9s,此時 Watermark < 10s,繼續收集 [5, 10) 窗口元素。
- 當 EventTime = 15s 的元素流入,其 Watermark = 12s;系統 Watermark 被推進到 12s,此時 15s > Watermark > 10s,觸發 [5, 10) 窗口計算、繼續收集 [10, 15) 窗口元素。
- ·······
??設置合理的 Watermark 確實可以解決大部分元素延遲,但也是把雙刃劍——降低了結果的實時性,窗口計算結果最少也會延遲所設定的時間之久;其次在筆者看來,如果 Watermark 一直不推進(即一直沒有元素流入)、已結束窗口的計算就一直不會被觸發(這里需要了解 Watermark 的兩種生成模式「Punctuated Watermark 標點水位線」與「Periodic Watermark 定期水位線」,標點水位線是以元素流入事件觸發 Watermark 生成、后者是周期性生成。使用標點水位線就可能會出現 Watermark 不推進的現象,但實時性更強)。
??因此不建議設置過長的水位延遲時間,根據業務可能存在的延遲時間及實時性要求合理配置即可。
3.4 狀態 State
??章節「2.1.4.4 雙流 Join」中提到,在進行雙流 Join 時會先元素保存在自身的 State 中、再去對側 State 發起 Join 計算。
??「狀態 State」是流式計算/實時計算極為核心的構成,與批計算不同的是,批計算不存在中間結果、也不存在計算進度,失敗了就重新發起全量計算;流計算失敗重啟一定依賴于已知的狀態節點,因為流計算本身是有狀態計算,具有計算位點、時間、元素暫存、中間結果等狀態。
??Flink 中存在兩類 State:
- Keyed State:具有分區鍵的算子會以鍵為單位維護自身的 State,例如 group by 算子在求和計算時,會為每個分區鍵維護其數量總和。結構大致為 Map<Keyed, Long>。
- Operator State:不具有分區鍵算子的 State 統稱為算子 State,例如 Source 連接消息隊列時需要維護已消費位點、雙流 Join 時需要維護左右側流中元素。結構大致為 Map<Operator, State>。
??通常情況下,State 會先維護在內存內,通俗地說就是一個 HashMap**;經過一段時間、或內存占用量達到閾值,會寫入本地的 RocksDBStateBackend,這是 Flink 提供的本地高性能 KV 數據庫**;為了避免作業異常重啟、確保 Checkpoint 構建,隔一段時間還要將 State 從 RocksDB、異步同步到外部分布式存儲(通常是 HDFS)。這樣的架構,既避免內存不斷膨脹、也保證數據的安全性,同時通過異步保障性能。
??還有 HashMapStateBackend 供選擇,即純內存 StateBackend,由于其不存在磁盤 IO 與序列化,因此性能比 RocksDBStateBackend 快一個數量級;但完全依賴分配內存,并且安全性較弱,因此這里不作探討。
??使用者還可以維護自身的 State,通過實現 ValueState、ListState、ReducingState、MapState<UK, UV>等接口,將信息緩存在本地狀態中。但需要時刻注意 State 對于內存的占用,設置合理的清除策略或 TTL。
3.5 檢查點 Checkpoint
??Checkpoint 意為檢查點,是 Flink Failover 最大的仰仗。其本質就是保存全局快照,快照內存儲了集群內所有算子的 State,在讀取時重放所有算子的狀態,并一比一恢復到 Checkpoint 存儲的狀態。
??這一章太過艱深,利用許多算法來解決諸如:分布式集群全局狀態一致性、Checkpoint 持久化模式、Exactly-Once/At-Least-Once 語義保證之類的問題。因此不作展開,有興趣的同學可以自行學習。
3.6 回撤流 Retract
??章節「2.1.4.4 雙流 Join」中提到,當右側流中出現能補齊左側流已輸出不完整結果的元素時,會產生兩次輸出:一次正向的、帶有完整結果的輸出,一次反向的、試圖撤回不完整結果的輸出。這種特殊的回撤行為稱為回撤算子,其產生的流被稱為「回撤流 Retract」。
??支持回撤的算子內部會記錄已輸出元素,每次輸出前會根據 key 進行匹配,如該元素已經輸出過、則發往下游一條回撤 + 一條輸出。回撤流與流并沒有本質區別,只不過將加運算變成了減運算。例如聚合算子中,流會對聚合結果產生正向影響(+),回撤流則會對結果產生逆向影響(-),回撤流使得計算的最終結果更加精準。
??
??如圖 13 所示,第一次輸出包含:一次正向輸出 1/1、一次回撤輸出 1/1、一次正向輸出 1/2,說明第一次計算的最終結果是 1/2。第二次輸出同理,兩次正向兩次逆向,最后啥也沒剩下。
??這種特性并非所有場景都支持,Sink 算子在不同插入模式下對回撤流的支持程度也不同。Sink 插入模式分為 3 種:
- Append Only:僅支持追加。
- Upsert:支持插入、更新、刪除,最完備的模式。
- Retract:支持插入、刪除。
??Append Only 模式不支持回撤,每次 Sink 都會插入一條記錄。而 Upsert 模式在處理回撤流時,可以根據主鍵直接更新已有的記錄,或者先刪除已有記錄、再插入新的記錄代替它,實現結果上的更新。Retract 模式使用先刪除、后插入,也可以實現更新效果。顯然 Append Only 模式的數據準確性不如其他兩者,只有最新輸出的一條記錄才是準確的。
??不同數據源支持不同的插入模式,例如 Kafka 只支持 Append Only ,但其是消息隊列所以可以接受這種順序讀寫;而 MySQL 如果只支持 Append Only 那就成災難了,基本沒法使用,因此其支持基于主鍵的 Upsert。因此在使用回撤流以及回撤算子時,需要結合數據源的插入模式分別考慮,合理利用回撤流來保證數據的準確性。
3.7 反壓/背壓 BackPressure
??章節「2.2 流式計算 SQL」中提到,SQL 的好壞直接影響執行計劃的生成,執行計劃中的執行節點又會互相影響,任一節點異常都會影響整個作業,這種現象就叫做「反壓 BackPressure」,也稱作背壓。
??反壓是流式系統中常見的概念,具體指下游節點的處理速率 < 上游節點的生產速率,此時下游節點所采取保護自身的策略,就被稱為反壓。其實這種場景極為常見,并非流式系統獨有;下游服務經常會面對上游流量激增、或自身服務出現異常,而不得不采取一些措施,例如熔斷/限流/降級。這些措施本質上也是反壓的一種,提供者通過一些手段來防止上游的無序調用,防止自身被壓垮導致服務不可用。
??舉個最簡單的例子, Java 有界阻塞隊列 LinkedBlockingQueue,當隊列容量達到上限,再次嘗試放入元素會直接阻塞。這就是最簡單且常見的反壓實現。
public void put(E e) throws InterruptedException {if (e == null) throw new NullPointerException();// Note: convention in all put/take/etc is to preset local var// holding count negative to indicate failure unless set.int c = -1;Node<E> node = new Node<E>(e);final ReentrantLock putLock = this.putLock;final AtomicInteger count = this.count;putLock.lockInterruptibly();try {/** Note that count is used in wait guard even though it is* not protected by lock. This works because count can* only decrease at this point (all other puts are shut* out by lock), and we (or some other waiting put) are* signalled if it ever changes from capacity. Similarly* for all other uses of count in other wait guards.*/while (count.get() == capacity) {notFull.await();}enqueue(node);c = count.getAndIncrement();if (c + 1 < capacity)notFull.signal();} finally {putLock.unlock();}if (c == 0)signalNotEmpty();
}
??在筆者之前的一篇文章《Reactor 響應式編程》中有介紹過,Reactor 采取了推拉結合的方式,下游向上游發出具體拉取元素數量的信號量,上游根據信號量向下游推送對應數量(具體見https://blog.csdn.net/m0_62375467/article/details/132404504 《響應式編程:面向數據/事件流的編程范式
》)。不同系統對反壓有不同的實現方式,本質都是對下發/消費速率的調控與平衡,并且反壓都是級聯,從反壓節點一路向上影響到初始節點。
??而 Flink 支持反壓的方式十分自然,可謂是天生反壓圣體。
??當節點的消費速率 < 生產速度,節點的 local buffer(本地緩沖區,可以理解為 JVM 內存)就會趨于膨脹;local buffer 塞不進去,Netty 的 buffer 就沒法騰地方出來,也會跟著膨脹;Netty buffer 在膨脹到一定程度后也塞不下了,就會停止讀取 Socket 中的數據(不發起調用recv()函數或調用被阻塞);而 Socket 不被讀取后,TCP 又具有端到端自動調速的能力(詳見 TCP 滑動窗口),TCP 的發送方就會自動停止。
??整個反壓的過程渾然天成,利用了所有可利用的網絡傳輸機制,牛逼。考慮到這個過程有些抽象,以下游節點的視角重新梳理一次反壓過程:
- 節點的消費速率 < 生產速度,local buffer 開始膨脹,直至打滿。
- local buffer 打滿,Netty 無法寫入,導致 Netty buffer 開始膨脹,直至打滿。
- Netty buffer 打滿,停止讀取 Socket,導致 **Socket read buffer **開始膨脹,直至打滿。
- Socket read buffer 打滿,TCP 寫入(write()函數)read buffer 操作阻塞。
- TCP 發起端到端自動調速,TCP 發送方自動停止。
- 分割線
- 上游節點作為 TCP 發送方,此時也受到了影響。
- TCP 無法繼續發送,Socket write buffer 打滿。
- Socket write buffer 打滿,Netty 不可寫,Netty buffer 打滿。
- Netty buffer 打滿,local buffer 無法回收,也打滿。
- ······
??如圖 14 是 Alibaba VVP 作業運維的執行計劃信息,該作業的 Vertex5 節點負載較高,該節點就會發起反壓;Vertex4 節點受到反壓影響,調整生產速率,但其本身的消費速率也會受到影響(他是下游的生產者、也是上游的消費者)。因此可以看出,每個節點都有不同程度的反壓。整個過程周而復始,最壞的情況下反壓會一路影響到 Source 節點,整個作業會 Crash 重啟;因此反壓現象是一定要處理的,后續的作業調優會介紹大致方法。
??
??反壓過程遠比描述復雜得多,筆者唯恐誤人子弟,建議有興趣的同學了解一下以下知識:Flink 網絡傳輸模型、Netty 實現及水位線、TCP 滑動窗口及擁塞控制。
4 江湖豪俠:Flink 作業調優
??看到這里的你,已經對如何開發一個 Flink Job 有了基本的認知,也對 Flink 最核心的概念、以及依托于其之上的設計有了大致的理解。
??本章將會更貼近工程層面,就 Flink Job 如何生成、如何調優、并結合場景具體分析。磨刀不誤砍柴工,在思考如何調優前,更需要先知曉一個 Flink Job 進入系統后都發生了什么,本章也會以該順序循序漸進展開討論。
4.1 Flink 運行時架構
??章節「1.2 分布式」初步介紹了 Flink 具備的分布式特性,并且提到 Flink 實際就是一個大型 JVM 進程集群,其由 4 大組件構成,本章將會具體介紹運行時架構以及構成組件。
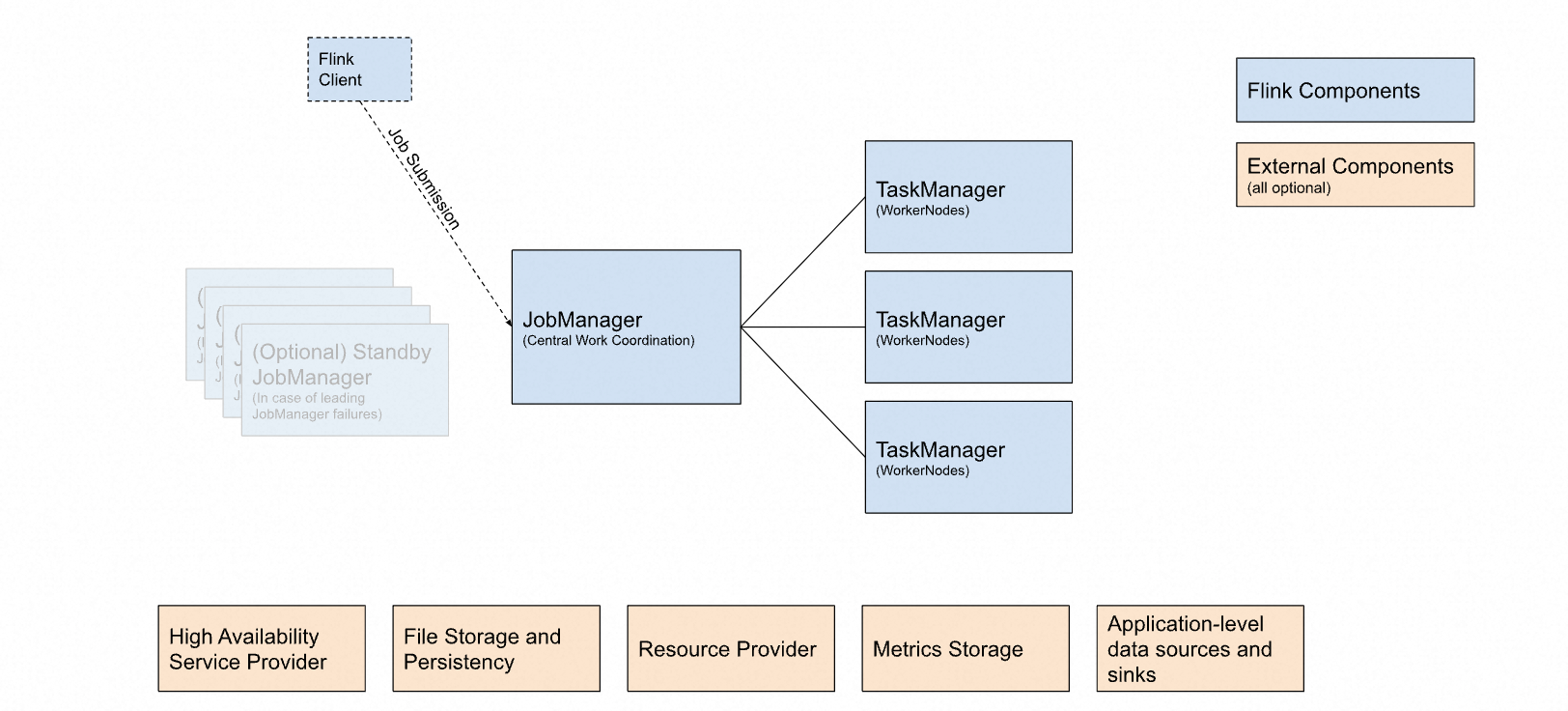
??如圖 15 為 Flink 官方給出的整體架構圖,邏輯上劃分為「內部組件 Flink Components」(必需)、「外部組件 External Components」(可選)。外部組件不多作介紹,主要包含高可用支持、文件/持久化存儲、指標存等。從圖中能明顯看出,JobManager 與 TaskManager 之間的交互才是核心——也是本章的核心內容,運行時架構。
??
??Flink 的運行時架構主要包含四大組件:
- JobManager 作業管理器:Flink 集群的 Master,每個集群有且只有一個主 JobManager(為保障高可用會有多個備 JobManager),負責 Flink 集群的作業管理、資源調度、任務分配、環境協調等等,是集群真正的心臟。
- ResourceManager 資源管理器:負責 Flink 集群的資源分配管理,JobManager 在進行任務分配時需要先獲取相應的運行資源(TaskSlot),此時就會與 ResourceManager 產生交互。每個集群有且只有一個 ResourceManager。
??比較有意思的點是,它可以與資源管理框架交互(如 YARN、K8S、Mesos 等),動態控制資源的擴縮容。 - TaskManager 任務管理器:Flink 集群的 Worker,任務真正執行的工作節點,通常一個集群有 N 個 TaskManager(非 standalone 模式)。最小工作單元是 TaskSlot(任務槽),一個 TaskManager 可以提供多個 TaskSlot,這些 Slot 會作為 ResourceManager 的分配單元。
??每個 Slot 擁有獨立的內存空間,但 CPU 資源會被共享,因此通常建議 Slot 數 = CPU 核數。 - Dispatcher 分發器:主要提供 REST 接口用于提交作業,以及 Web UI 用于展示作業執行監控,非必需。
??說直白點:
- JobManager 是大老板,集群的協調分配者;
- TaskManager 是工作人員,純干活兒的,負責執行計算任務;
- ResourceManager 是管賬的,JobManager 協調資源先找 ResourceManager,負責分配/回收 TaskManager;
- Dispatcher 是前臺,負責任務提交后報信給 JobManager,以及作業指標展示。
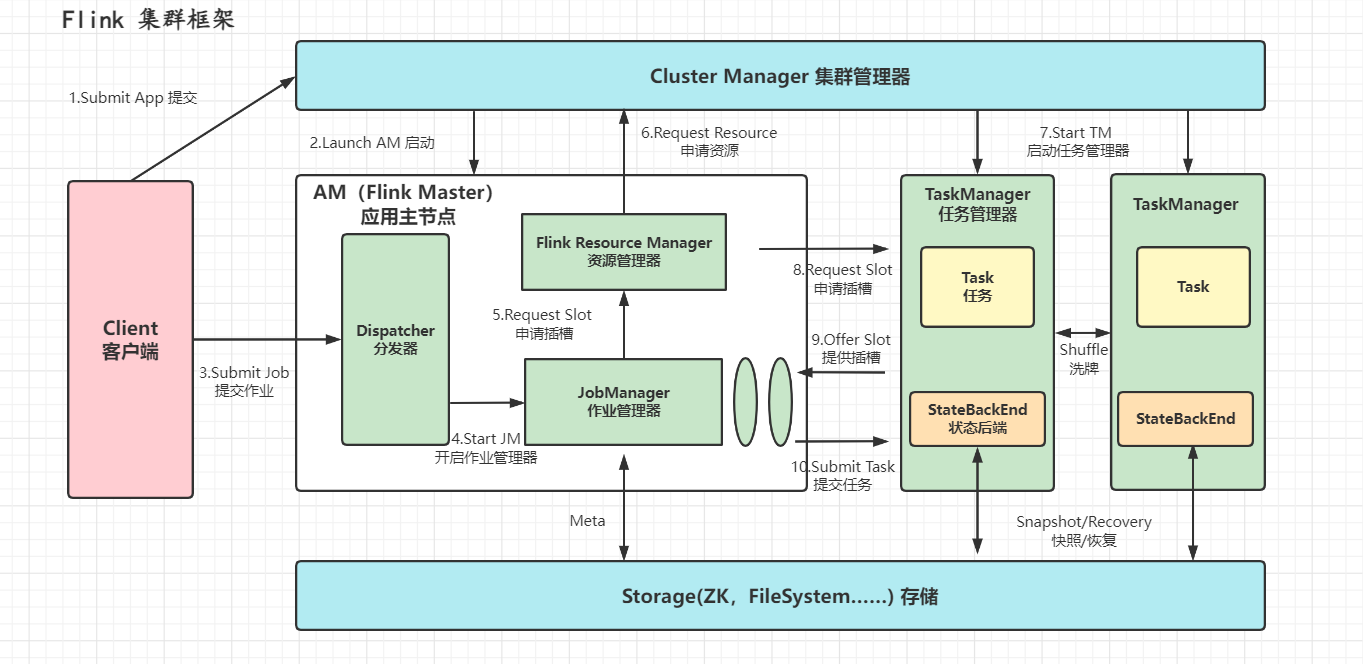
??那么在 Flink Job 提交進 Flink 集群后,運行時架構的運行交互關系(如圖 16)可以簡述為:
- **JobManager **將 Job 解析為 ExecutionGraph(執行圖),即一份具體的執行計劃(DAG);
- **JobManager **根據執行圖向 **ResourceManager **申請執行所需資源,**ResourceManager **與底層資源管理系統(如 YARN)交互,確保集群資源滿足執行要求(通常伴隨著動態擴縮容、啟停 TaskManager);
- **JobManager **獲取所需資源后,將任務分發給 TaskManager,由 **TaskManager **具體執行計算邏輯;
- **TaskManager **會持續上報執行狀態 State,并由 **JobManager **維護檢查點 Checkpoint,確保作業的故障恢復。
4.2 執行計劃
??Flink 運行時架構的全貌大致清晰,Flink 官方也通過整體架構圖(如圖 15)強調了 JobManager 與 TaskManager 、以及二者間關聯的重要性,這是作業調優不可缺少的前置知識。本章將會著重介紹 JobManager 如何解析并構建執行計劃。
??借用 Flink Forward Asia 2022《Adaptive and flexible execution management for batch jobs》中的一張圖,圖 17 描述了最終的執行計劃 ExecutionGraph 是如何生成的。
??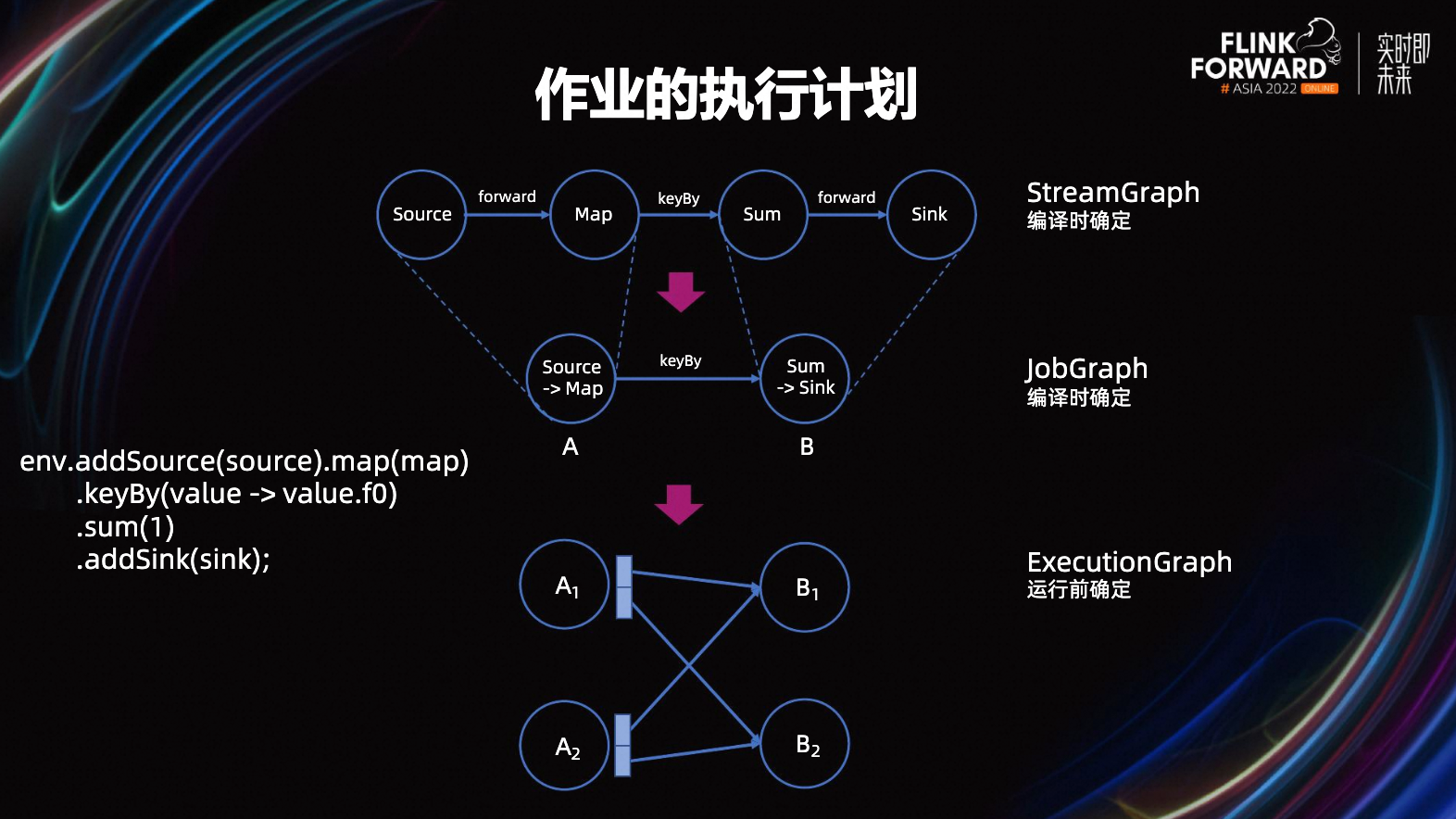
??以 DataStream 作業為例,作業代碼編譯完畢后會生成「流圖 StreamGraph」,流圖內描述了完整的 DataStream API 計算邏輯,如圖中例子為:Source -> 元素轉換 -> 按 key 分組并求和 -> Sink。
??在未禁用「算子鏈(Operator chain)合并」的情況下,編譯期間還會根據算子邏輯的復雜程度、并行度、分發方式(分組/forward)等因素,對相連算子進行合并、組成一個算子鏈。算子鏈合并是 Flink 最常用的優化手段之一,因為算子邏輯天然存在復雜度差異,如果每個算子都分配單獨的資源,會使得負載極其不均衡;合并也能夠減少服務間網絡通訊、線程切換、序列化帶來的損耗。因此,編譯的最終結果會生成「作業圖 JobGraph」,即算子合并后的圖。
??JobGraph 提交給 JobManager,JobManager 會根據每個任務節點的并行度進行展開,并確定節點間的連接關系,生成最終可執行的「執行圖 ExecutionGraph」,此時每個任務節點都對應一個具體執行的 TaskSlot。「并行度 Parallelism」代表每個算子需要幾個 Worker ,類似于多線程并行消費,只不過調度資源由 Thread 變成了 TaskSlot。
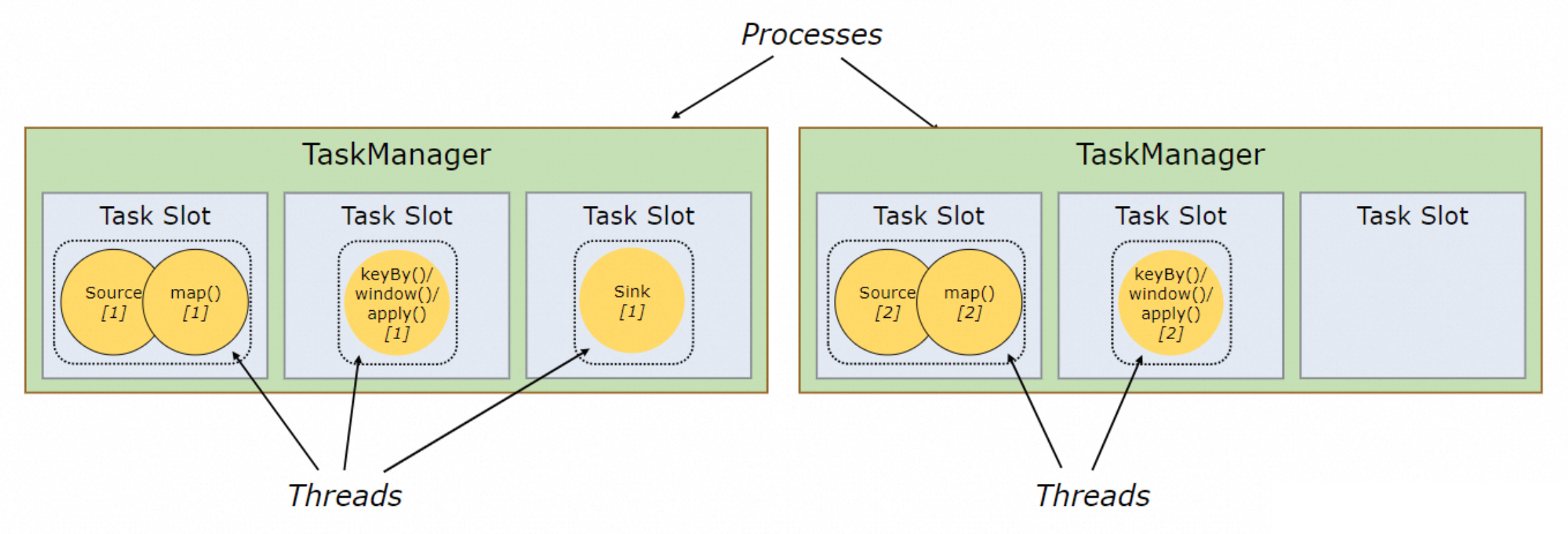
??例如圖 17 中的作業并行度為 2,A 節點的結果會發往 B,因此最終執行圖為 A1/A2 -> B1/B2,共對應 4 個 TaskSlot。而實際的執行計劃還存在進一步優化空間。如圖 18 所示,在經過算子合并后的每個算子鏈會分配一個 TaskSlot,部分節點計算邏輯仍然相對簡單,其分配到的 TaskSlot 大部分時間是空閑的,其他節點卻一秒沒閑著。
??
??因此 Flink 會在 Slot 維度采取進一步合并,將簡單算子的 Slot 共享給復雜算子(Slot Sharing),反正閑著也是閑著,不如給別人用;在算子并發度高的場景下,最終會得到如圖 19 的執行計劃。但是同一個 Slot 只能共享給同一 Job 內不同的算子,例如合并 Map + Sink,將兩個相同的算子放在一個 Slot 內無法實現并行。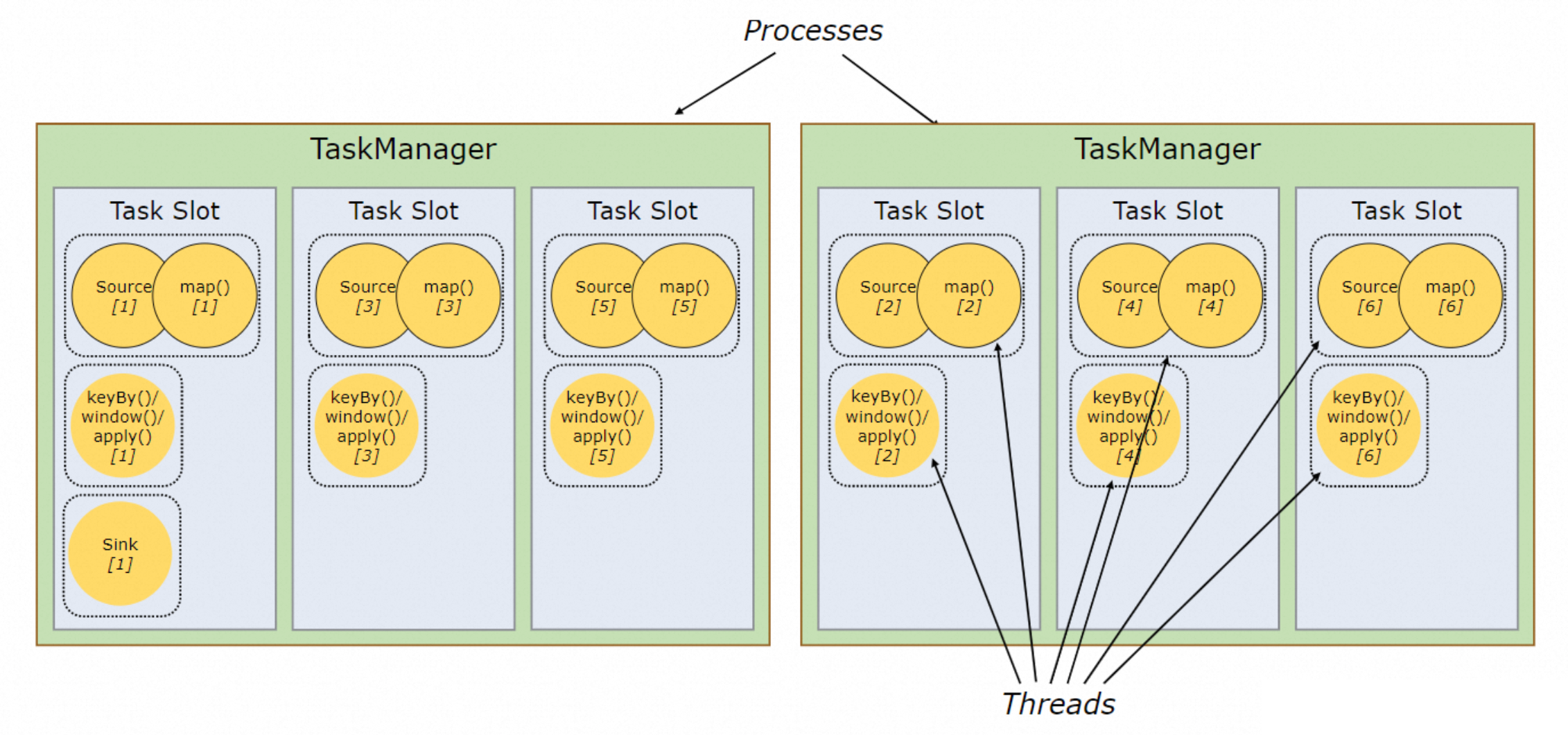
4.3 性能瓶頸
??討論到 Flink Job 的性能瓶頸,其表現形式在前文其實都有提及。
??首先是背壓,在消費速率 < 生產速率時該節點會向上游算子發起背壓,嚴重時會阻塞住整個作業的運行;表現出來就是數據延時越來越大,這種情況不手動調優是不可能主動恢復的。
??其次是所有運行于 JVM 之上程序的共性問題——內存。于 Flink 而言又分為兩類:
- 堆內占用過大,如圖 20 中的 Task Heap(圖 20 是 Flink TaskManager 的內存模型,分為堆內/堆外內存,有興趣的同學可以自行了解),算子邏輯與業務代碼產生的內存將會占用 Task Heap 空間;這個區域非常容易膨脹,處理復雜運算邏輯時更甚。
- 堆外內存占用過大,如圖 20 中的 Managed Memory,Flink Job State 會存儲在這個區域內;算子邏輯復雜(或者是雙流 Join 這種本身就強依賴 State 的算子)一定程度也會導致 State 變大,也是俗稱的「大狀態」。
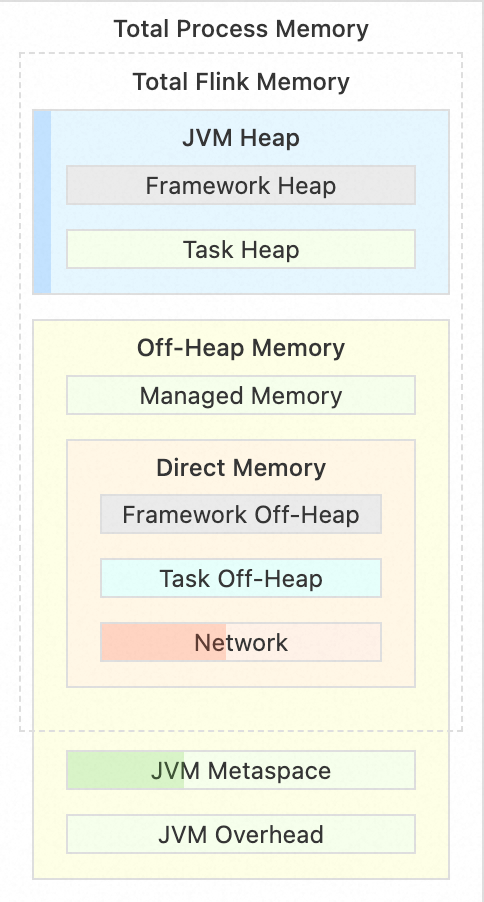
??內存瓶頸的表現形式通常為作業 OOM 后崩潰重啟,如果不進行調整作業會一直重啟。
4.4 配置調優
??首先記住大原則:寫出高性能 SQL 才是最有效的優化方案!!!
??不過要寫出美麗高性能 SQL 還是有難度的,例如謂詞下推、手動構建 PK、避免 NULL 熱點、Shuffle/Rebalance 等概念,每個拿出來都能說半天。因此本章還是僅針對上文場景、討論配置層面的調優方向,不涉及特定算子及計算模式層面的優化方式。
4.4.1 加機器
??直白地說,Flink 中的大部分性能問題都能夠通過加機器解決。算子消費速率過低?上 128C 的!數據延遲越來越大?再加二北臺機器!內存占用過大一直 OOM?上 128G 的!甚至連 Flink 官方也建議先通過加內存/加機器來嘗試解決問題(來自 Flink 官方文檔 -> Tunning Checkpoints and Large State -> Tuning RocksDB Memory 的原話),可謂是一力降十會。
??因此在作業性能出現問題時,建議先加機器恢復正常運行,后續再針對細節進行優化。當然也不能無腦加,需要結合實際的執行計劃和具體異常節點,合理且有針對性地調整。
4.4.2 算子并發度
??作業的瓶頸通常是由于單節點吞吐 < 整體吞吐導致的,常見的水桶效應。這種現象十分正常,章節「4.2 執行計劃」中提到,算子復雜度天然存在差別,Map 算子的吞吐自然大于 Join 算子(Map 為無狀態算子,只有 convert 邏輯,Join 要考慮得就多了),Join 算子的吞吐就可能成為整個作業的瓶頸。此時可以針對執行計劃中忙碌的節點調高并發度,直至作業吞吐恢復正常。
??而上游 Source 流量激增的場景,即使沒有單點瓶頸也無法滿足目前的需求,作業延時還是會越來越大。此時則需要調整整個作業的并發度,再尋找單點瓶頸逐個擊破。
4.4.3 關閉共享
??前文提到 Flink 在執行計劃層面會采取兩種優化:算子鏈合并和 Slot 共享,但好心也有可能辦壞事。
??算子鏈合并確實能一定程度減少網絡通訊帶來的損耗,并且實打實節省了資源。但同時也導致了資源分配不均且不透明,原本一人一個了變成一人一半(甚至可能因為爭搶導致不足一人一半)。并且為算子層面的調優造成了極大困難,在不開啟算子鏈合并的情況下,每個算子獨立存在,哪個算子異常一眼便知;合并后,5 個算子合成一個,只能看到這一坨,基本沒法定位某個算子來調整細節。Slot 共享同理,原本一個算子用 4C,現在變成一人 2C,對性能的影響是必然的。
??因此需要算子層面的細節調優時,可以關閉這兩類共享(或者調整為僅允許某些高吞吐算子共享,將這類算子設置相同的組別,詳見 SlotSharingGroup)。
4.4.4 內存分配
??前文提到與內存有關的性能瓶頸通常出現在兩塊區域,對應 TaskManager 的堆內/堆外內存的核心部分,即運行時內存 Task Heap、管理內存 Managed Memory。兩塊內存的具體大小會根據比例自行計算,默認情況下 Managed Memory 會占用總內存的 40%,而 Task Heap 會用所有內存區域分配完畢后剩余的。
??Managed Memory 通常用于存儲 State Backend,而 Flink 最常見使用場景是做數據 ETL,ETL 本質上就是 Mapping,而 Map 算子是無狀態算子。這意味著大部分作業的 State 容量并不會很大,Managed Memory 利用率也就低得可憐。如圖 21 是一個純 ETL 作業的內存占用情況,可以看到 Managed Memory 的占用量是 0%,卻和堆內內存大小持平(1.19GB/1.33GB)——這是由于 Flink 的默認配置中,Managed Memory 會分配到總內存的 40%。
??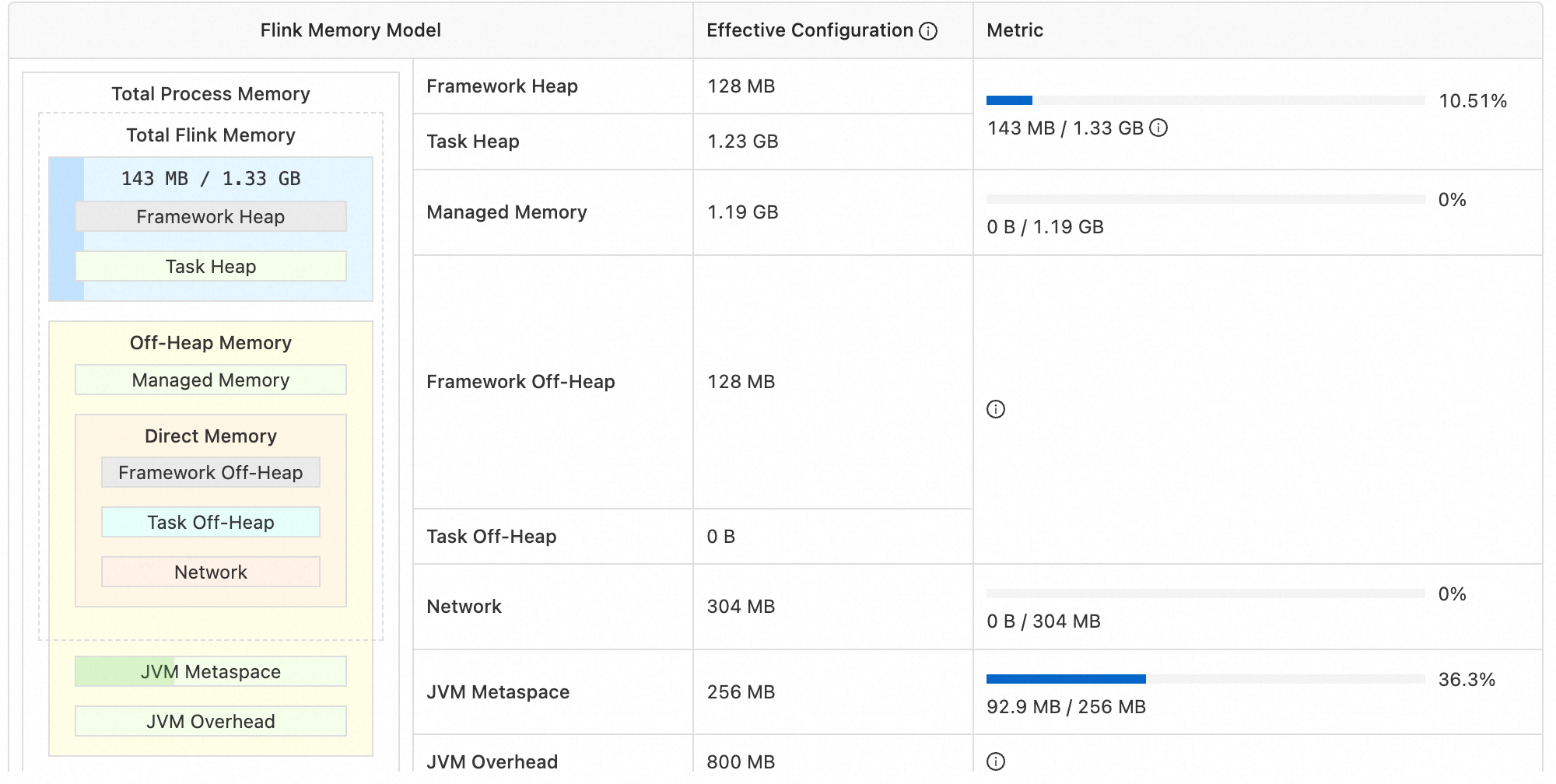
??但圖中的作業設置分配 5% 就已經足夠,甚至更低。因此,使用者應當根據運行時不同內存區域的占用情況,自行調整內存分配。
4.4.5 大狀態
??前文提到,內存瓶頸最大的罪魁禍首之一便是「大狀態」,大狀態對 Flink Job 穩定性的危害是不言而喻的:
- 大狀態會迅速填滿 Managed Memory,加劇節點 GC。
- 從 RocksDBStateBackend 中讀取大狀態效率很差,因為涉及大量數據的檢索、磁盤 IO、序列化/反序列化。
- Checkpoint 的構建依賴狀態,狀態越大構建效率越低。
??在雙流 Join、以及無邊界的聚合計算等場景,State 非常容易膨脹。但實際使用者能做得也不多,要減少對 State 的使用那是執行計劃層面的優化,不在本章探討范圍內。
??但絕大多數情況大狀態的出現,是因為沒有設置 State TTL,TTL 默認是永久,你敢信?所以,請務必根據業務對 State 中歷史數據的依賴程度(例如雙流 Join 中,業務方不會出現依賴 1 天前記錄場景下,就可以設置 TTL 為 24H 左右),設置合理的 State TTL!
4.4.6 Mini-Batch
??Mini-Batch 俗稱攢批,是 Flink 中最常用、好用的調優方式之一。
??在聚合計算場景下,每個元素的到來都會觸發一次計算,即 State 讀取 + State 累加 + State 回寫;當上游 RPS 極高時,State 的急劇膨脹及高頻率讀寫會成為極大的性能瓶頸。而使用方大部分時候并不需要感知每一秒的指標變化,此時便可以使用 Mini-Batch。
??Mini-Batch 的原理實際就是將元素攢在手里,周期性地觸發計算,而不是每次元素到來都觸發。這樣做能大幅度降低計算頻率,減少高頻率計算產生的性能負擔;最重要的是用批量操作 State 代替了單行操作,要知道每次 State 操作都意味著磁盤 IO + 序列化。Mini-Batch 會以使用者配置的允許延遲時長作為周期觸發計算,性能提升的同時意味著數據的實時性降低了,這一秒發生的事件需要 N 秒后才能看到結果。
??因此需要結合對數據時效性的要求合理設置是否開啟 Mini-Batch、合理配置允許延遲時長。
4.5 調優效果
??以上為筆者曾經使用過的部分調優策略,筆者的一個作業曾經由于 Source RPS 突然提高了 3000 左右,導致部分節點反壓,作業延遲一度增大到 3 小時。在嘗試過以上所有的調優策略后,吞吐量增長也是十分顯著:
??
??
??從 3000 輸出 RPS 最終達到穩定 16000+,非常好用。
5 一代宗師:后車之師
??到這里,對于 Flink 的整體介紹基本結束,相信你已經深切感受到 Flink/流式計算的魅力所在,也衷心祝愿你能在流式計算的世界里越走越遠。
??筆者在學習與使用 Flink 的過程中踩了不少坑,希望在最后能幫到你。
5.1 大型維表 Join 導致 OOM
??維表 Join 是很常見的計算場景,章節「2.1.4.2 維表/歷史表連接器」中提到,由于維表變動不頻繁的特性,其可以采取一定的緩存策略,避免每次查詢產生的網絡 IO。不同存儲介質對緩存策略的支持程度不同,KV/列式存儲對 LRU 策略支持較好,而筆者的使用場景 ODPS 僅支持全量緩存策略。
??這意味著作業啟動時,要將表中的所有數據一次性讀取進內存(Task Heap)。這就很令人犯難了,這張維表正好是張巨大的維表,筆者盡全力去縮減數據量仍然只能控制在一千萬上下。粗略估算僅這些數據,就能占據幾十 G 的內存空間。自從引入這張維表后,筆者的作業啟動就十分艱難。TaskManager 在讀取維表全量數據時會瘋狂的 OOM,然后不斷重啟重啟重啟。
??筆者當時采取了幾種思路:
- 加內存、加內存、加內存,但這樣肯定不是個事。
- 調整內存空間分配,由于維表數據存儲在 Task Heap 區域、且并不是大狀態作業,因此可以調小其他區域(如上文提到的 Managed Memory),優先確保 Task Heap 空間。
??在初期確實能夠很好的緩解問題,但維表的數據會一直膨脹,總不能沒事就來調調作業的內存吧?但既然一臺機器放不下所有記錄,能不能打散到所有機器內呢?
??答案是可以!Flink 的分區算子就是干這個的。
??通常情況下,上游算子流入哪個下游算子分區(可以理解為哪臺機器)是 shuffle 算子隨機選擇的(keyedBy 聚合場景除外),因為都大差不差;但如果在 Join 計算前先對 Join Key 作 hash 運算,將左側流元素根據 hash 結果分配到同一分區,確保相同 hash 的記錄落在同一分區內,那就可以確定每個分區需要加載哪些 key 對應的維表信息。
??相當于從每臺機器加載全量維表數據,變成了每臺機器只加載被分配到的 key 的維表數據,數據量縮減到了 1/Parallelism。但前提要先擴大算子并發數,否則就 1 個分區參與分配等于沒分。
??
5.2 并發度過高導致無法啟動
??調整并發度是提高作業吞吐非常有效的手段,但連接器的吞吐往往不是越大越好。因為提高并發度相當于增加同時計算的 Worker,而數據源的讀取通常具有事務性,不能誰來都能讀。例如 Kafka Connector,有多少個 shard 就支持多少個并發,調大了剩下幾個 Worker 就只能一直閑著。
??筆者有次遇到一個奇怪的問題,在數據源 Datahub(類似 Kafka 的消息隊列)shard 數為 1 的場景下設置了并發度為 4,此時作業出現一直重啟的現象;在調低并發度后(即調整并發度 = shard 數),作業又能夠正常啟動了。但是筆者后續再也沒有復現過該場景,哪怕并發度與 shard 不對等也沒有影響作業的啟動。
??這也成了筆者心中的一根刺,希望有人能解惑。T_T
5.3 窗口函數啟動異常
??使用窗口函數時需要指定時間字段,且該字段類型必須是 timestamp + rowtime,否則無法正常啟動窗口。
??筆者在 DDL 中指定了時間字段、將其轉換為 timestamp 類型、還設置了 Watermark,可以說是妥妥的優質可開窗字段。但在調用下方的 TUMBLE 算子后,還是報出了“當前字段不是時間格式”的錯誤。
CREATE TEMPORARY TABLE user_clicks(username varchar,click_url varchar,eventtime varchar, ts AS TO_TIMESTAMP(eventtime),WATERMARK FOR ts AS ts - INTERVAL '2' SECOND --為Rowtime定義Watermark。
) with ('connector'='sls',...
);CREATE TEMPORARY VIEW one_minute_window_output AS
SELECT TUMBLE_ROWTIME(ts, INTERVAL '1' MINUTE) as rowtime, --使用TUMBLE_ROWTIME作為二級Window的聚合時間。username, COUNT(click_url) as cnt
FROM user_clicks
GROUP BY TUMBLE(ts, INTERVAL '1' MINUTE),username;
??筆者簡直不敢相信自己的眼睛,并且其他的測試 demo 中,同樣的寫法也沒有任何問題。
??在不斷地排錯后,發現問題出在開窗的時機不對。筆者的 SQL 類似于一個子查詢查出表中所有的字段、再于子查詢外側調用窗口算子,查完表字段直接開窗就沒有出現問題。這說明:子查詢在查出時間字段時,沒有保留其附加的 rowtime 屬性,只剩了基本的數據類型 timestamp。這就有點坑了,原封不動地查出來還能把字段上的屬性丟掉?在筆者看來這應該屬于 bug。
??因此,子查詢可能會丟失字段原有的屬性,這點是可能存在的風險。
5.4 序列化
??由于 Flink 中存在大量的網絡/磁盤 IO,因此其要求所有傳輸的對象都必須是可序列化的。而在一次 Flink UDF 開發中,筆者在上傳 UDF 并嘗試啟動后,發現作業一直報序列化錯誤:
Exception in thread "main" org.apache.flink.api.common.InvalidProgramException: java.***.***$***@123 is not serializable.
??令人困惑的是,UDF 實現的 TableFunction 接口本身實現了 Serializable 序列化接口,那為啥又會出現序列化錯誤呢?在不斷地尋覓后,筆者發現 UDF 的一個局部變量沒有實現序列化,筆者將這個類刪掉以后就沒報錯了。但那又是個很重要的外部類,沒法刪掉、也不方便 copy 過來的那種,筆者當時心涼了半截。
??那這個問題該如何解決呢?
??首先想到 transient 修飾符,它用于標記一個局部變量不用被序列化。看起來沒什么實際意義,因為字段如果不被序列化,那在分布式環境肯定是沒法使用的;但如果這個字段在外部環境確實沒什么用,只在系統內部(內/外部指網絡通訊的發起/接收者)使用,外部不感知,那確實是不用被序列化。筆者試了試,倒是不報序列化錯誤了,但調用該類的時候直接開始報錯,因為變量根本沒被序列化(服了。。。)。
??可如果變量本身就無法被序列化,那就必須得用 transient 標記,不然對象都無法正常序列化并傳輸。那不成死結了?
??但是,Java 基礎知識中提到:類變量屬于類、不歸屬于對象。而序列化/反序列化都是在字節序列和對象之間轉換,如果一個變量不屬于對象,它也就不需要參與序列化。
??所以最終解決方案就是把它標記為成員變量(類變量),如果要網絡傳輸某個字段、而這個字段又沒有實現序列化,就把它標記成類變量吧,準好使。
6 特別鳴謝
??感謝你看到這里,也感謝領筆者進門的兩位幫派師兄,最后感謝所有 Committer、編寫官方文檔、分享技術知識、極具開源精神的程序員們。
??再推薦幾篇筆者覺得非常有意思的文章(也同時作為本文的參考文獻),鏈接一同貼在下面,再次感謝各位的無私奉獻。
- 阿里云 Flink 產品文檔:https://help.aliyun.com/zh/flink/?spm=a2c4g.11186623.0.0.15584a58S2EZt8
- Apache Flink 漫談系列(必看!必看!必看!):https://developer.aliyun.com/article/666043
- Apache Flink 官方文檔:https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/try-flink/local_installation/
- Flink Forward Asia 2022:https://2022.flink-forward.org.cn/
??如果你對本文的內容仍有疑惑、指正、補充、更優解,歡迎隨時找筆者討論,不允許自帶酒水。
、MySQL數據庫)
)








 D. Constellation 題解 枚舉)





)


