1. P-Tuning v1
1.背景
????????大模型的Prompt構造方式嚴重影響下游任務的效果。比如:GPT-3采用人工構造的模版來做上下文學習(in context learning),但人工設計的模版的變化特別敏感,加一個詞或者少一個詞,或者變動位置都會造成比較大的變化。
????????P-Tuning,在《GPT Understands, Too》中被提出,該方法將離散的Prompt轉換為可以學習的Embedding層,并用MLP+LSTM的方式來對Prompt Embedding進行一層處理,成功地實現了模版的自動構建。
2.技術原理
????????P-Tuning 提出將 Prompt 轉換為可以學習的 Embedding 層,并考慮到直接對 Embedding 參數進行優化會存在這樣兩個挑戰:
? ? ? ? 1.Discretenes: 對輸入正常語料的 Embedding 層已經經過預訓練,而如果直接對輸入的 ????????????????prompt embedding進行隨機初始化訓練,容易陷入局部最優。
? ? ? ? 2.Association:沒法捕捉到 prompt embedding 之間的相關關系。
????????基于此,作者提出了P-Tuning,設計了一種連續可微的virtual token(同Prefix-Tuning類似)。該方法將Prompt轉換為可以學習的Embedding層,并用MLP+LSTM的方式來對Prompt Embedding進行一層處理。
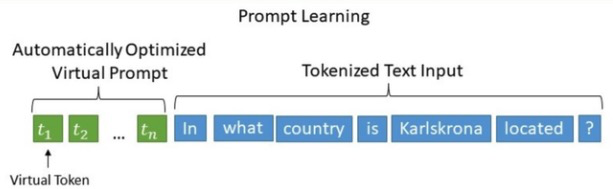
????????相比Prefix Tuning,P-Tuning加入的可微的virtual token僅限于輸入層,沒有在每一層都加;另外,virtual token的位置也不一定是前綴,插入的位置是可選的。這里的出發點實際是把傳統人工設計模版中的真實token替換成可微的virtual token。
????????優化virtual token:經過預訓練的LM的詞嵌入已經變得高度離散,如果隨機初始化virtual token,容易優化到局部最優值;這些virtual token理論是應該有相關關聯的,要對這種關聯進行建模。作者發現的是用一個prompt encoder來編碼收斂更快,效果更好。也就是說,用一個LSTM+MLP去編碼這些virtual token以后,再輸入到模型。換言之,P-tuning并不是隨機初始化幾個新token然后直接訓練的,而是通過一個小型的LSTM模型把這幾個Embedding算出來,并且將這個LSTM模型設為可學習的。
????????選擇雙向長短期記憶網絡 (LSTM),使用 ReLU 激活的兩層多層感知器 (MLP) 來對prompt embedding 進行一層處理來鼓勵離散性。
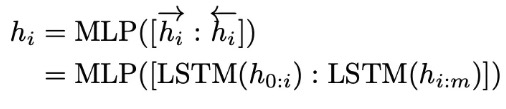
????????將LSTM作為prompt-encoder,并進行隨機初始化。GPT模型仍然會被全部凍結,只更新LSTM的參數。LSTM的參數是所有任務同時共享的,但是LSTM為不同的task輸出unique virtual token embeddings。virtual token embedding和Prompt Tuning以一樣的方式插入input token中。
class PromptEncoder(torch.nn.Module):......def forward(self, indices):input_embeds = self.embedding(indices)if self.encoder_type == PromptEncoderReparameterizationType.LSTM:output_embeds = self.mlp_head(self.lstm_head(input_embeds)[0])elif self.encoder_type == PromptEncoderReparameterizationType.MLP:output_embeds = self.mlp_head(input_embeds)else:raise ValueError("Prompt encoder type not recognized. Please use one of MLP (recommended) or LSTM.")return output_embeds2.?P-Tuning v2
1.背景
????????之前的Prompt Tuning和P-Tuning等方法存在兩個主要的問題:
? ? ? ?1.缺乏模型參數規模和任務通用性。
????????缺乏規模通用性:Prompt Tuning論文中表明當模型規模超過100億個參數時,提示優化可以與全量微調相媲美。但是對于那些較小的模型(從100M到1B),提示優化和全量微調的表現有很大差異,這大大限制了提示優化的適用性。
????????缺乏任務普遍性:盡管Prompt Tuning和P-tuning在一些 NLU 基準測試中表現出優勢,但提示調優對硬序列標記任務(即序列標注)的有效性尚未得到驗證。
????????2.缺少深度提示優化,在Prompt Tuning和P-tuning中,連續提示只被插入transformer第一層的輸入embedding序列中,在接下來的transformer層中,插入連續提示的位置的embedding是由之前的transformer層計算出來的,這可能導致兩個可能的優化挑戰。
????????由于序列長度的限制,可調參數的數量是有限的。
????????輸入embedding對模型預測只有相對間接的影響。
????????考慮到這些問題,作者提出了Ptuning v2,它利用深度提示優化(如:Prefix Tuning),對Prompt Tuning和P-Tuning進行改進,作為一個跨規模和NLU任務的通用解決方案。
2.技術原理???????
?????????針對?P-Tuning v1存在的局限論文《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》P-Tuning v2 的目標就是要讓 Prompt Tuning 能夠在不同參數規模的預訓練模型、針對不同下游任務的結果上都達到匹敵 Fine-tuning 的結果。也就是說當前 Prompt Tuning 方法在這兩個方面都存在局限性。基于此,P-Tuning V2進行了下述改進:
????????1.在每一層都加入了Prompts tokens作為輸入,而不是僅僅加在輸入層,這與Prefix Tuning的做法相同。這樣得到了更多可學習的參數,且更深層結構中的Prompt能給模型預測帶來更直接的影響。
????????2.去掉了重參數化的編碼器。以前的方法利用重參數化功能來提高訓練速度和魯棒性(例如,用于prefix-tunning的 MLP 和用于 P-tuning的 LSTM)。在 P-tuning v2 中,作者發現重參數化的改進很小,尤其是對于較小的模型,同時還會影響模型的表現。
????????3.針對不同任務采用不同的提示長度。提示長度在提示優化方法的超參數搜索中起著核心作用。在實驗中,我們發現不同的理解任務通常用不同的提示長度來實現其最佳性能,這與Prefix-Tuning中的發現一致,不同的文本生成任務可能有不同的最佳提示長度。比如簡單分類任務下 length=20 最好,而復雜的任務需要更長的 Prompt Length。
????????4.可選的多任務學習。先在多任務的Prompt上進行預訓練,然后再適配下游任務。一方面,連續提示的隨機慣性給優化帶來了困難,這可以通過更多的訓練數據或與任務相關的無監督預訓練來緩解;另一方面,連續提示是跨任務和數據集的特定任務知識的完美載體。比如說,在NER中,可以同時訓練多個數據集,不同數據集使用不同的頂層classifer,但是prefix continuous prompt是共享的。
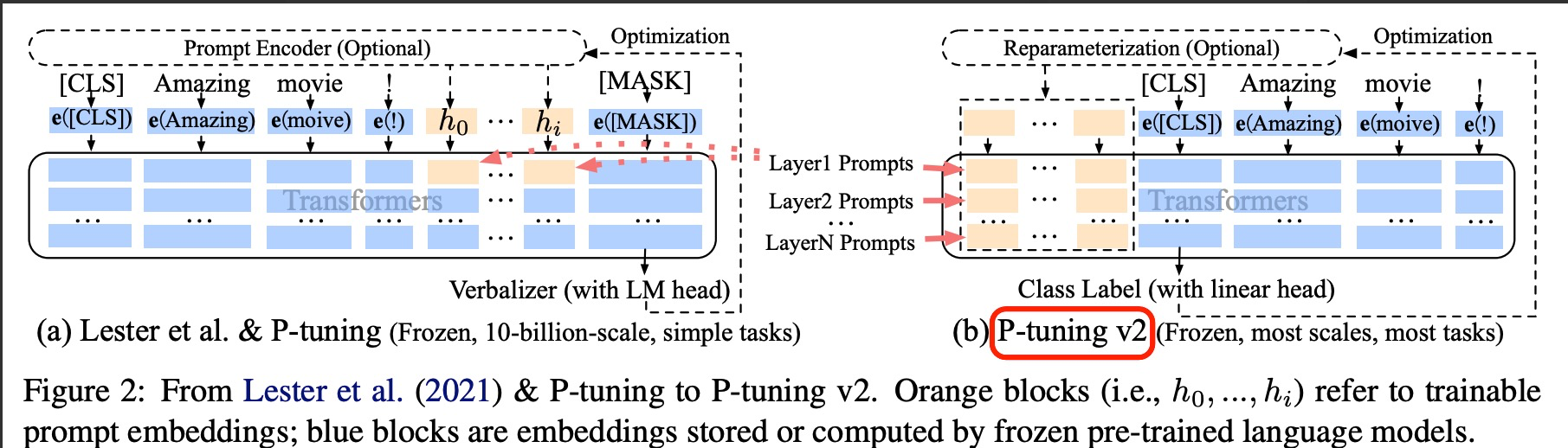
????????可以看到右側的p-tuning v2中,將continuous prompt加在序列前端,并且每一層都加入可訓練的prompts。在左圖v1模型中,只將prompt插入input embedding中,會導致可訓練的參數被句子的長度所限制。
? ? ? ? 另外在V2中,移除了Reparameterization,舍棄了詞匯Mapping的Verbalizer的使用,重新利用CLS和字符標簽,來增強通用性,這樣可以適配到序列標注任務。此外,作者還引入了兩項技術:
? ? ? ? 1.Deep Prompt Encoding:采用 Prefix-tuning 的做法,在輸入前面的每層加入可微調的參數。使用無重參數化編碼器對pseudo token,不再使用重參數化進行表征(如用于 prefix-tunning 的 MLP 和用于 P-tuning 的 LSTM),且不再替換pre-trained word embedding,取而代之的是直接對pseudo token對應的深層模型的參數進行微調。
? ? ? ? 2.Muliti-task learning:基于多任務數據集的Prompt進行預訓練,然后再適配到下游任務。對于pseudo token的continous prompt,隨機初始化比較難以優化,因此采用multi-task方法同時訓練多個數據集,共享continuous prompts去進行多任務預訓練,可以讓prompt有比較好的初始化。
peft_config = PrefixTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=20)
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)Reference:
1.大模型煉丹術:大模型微調的常見方法 - 知乎?
2.大模型微調之P-tuning方法解析 | 美熙智能
3.Prompt Tuning和P-Tuning的區別在哪里? - 知乎
4.大模型微調總結
5.詳解大模型微調方法Prompt Tuning(內附實現代碼)


)





)
)






)


