資源1:晏明 - RISC-V向量擴展指令架構及LLVM自動向量化支持 - 202112118 - 第13屆開源開發工具大會(OSDTConf2021)_嗶哩嗶哩_bilibili資源2:張先軼 - 基于RISC-V向量指令集優化基礎計算軟件生態【第12屆開源開發工具大會(OSDT2020)】_嗶哩嗶哩_bilibili
資源3:Release Vector Extension 1.0, frozen for public review · riscv/riscv-v-spec · GitHub
1. SIMD簡介
1.1 SIMD(單指令多數據)與 SISD
????????在計算機架構中,SIMD(Single Instruction, Multiple Data)和SISD(Single Instruction, Single Data)是兩種不同的處理數據的方法。
????????SIMD指令允許您執行的操作是將相同的操作應用于多個元素。我們可以將它與SISD(單指令單數據進行對比)
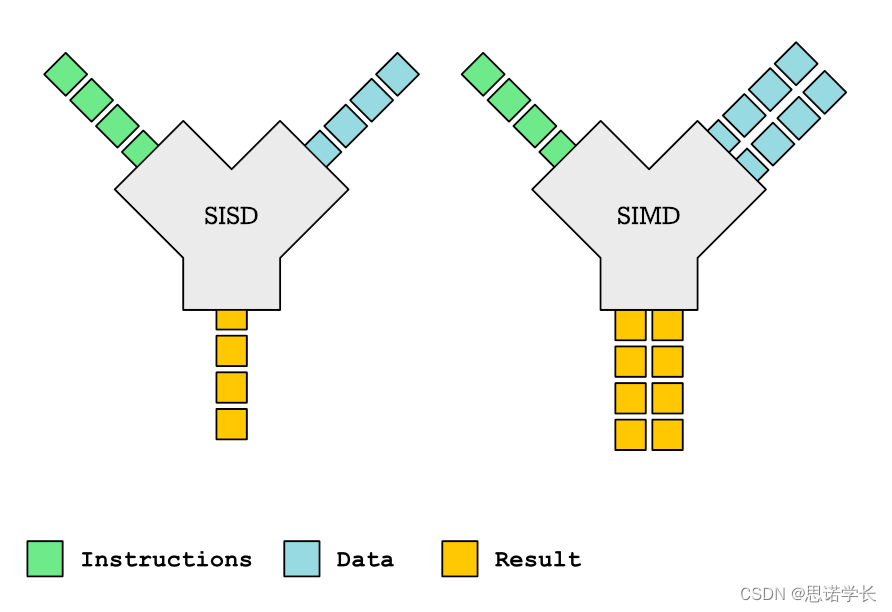
1.1.1 SISD (Single Instruction, Single Data)
? ? ? ? 標量指令,每次處理一個數據。
????????這是最傳統的計算機架構類型,它在任何時刻只能執行一條指令操作一個數據。這意味著處理器每次只能處理一個數據點。大多數順序計算機都是基于SISD架構的,它們按順序執行指令,每個指令操作單個數據項。SISD架構適用于大多數通用計算需求,但在處理大量數據或進行高性能計算任務時,可能不如其他架構高效。
? ? ? ? 每條指令僅指定處理單個數據。處理多個數據項需要多條指令,如下
? ? ? ? add x10,x11,x12
? ? ? ? 這種方法速度慢,很難看出不同寄存器之間的關系。在32位處理器上,執行大量單獨的8位或者16位操作也不能有效地使用機器資源。
1.1.2 SIMD (Single Instruction, Multiple Data)
????????這種架構允許一條指令同時對多個數據進行操作。這是通過在處理器中使用向量處理單元或SIMD寄存器來實現的,這些單元可以存儲多個數據點,并允許一條指令同時對這些數據執行相同的操作。SIMD架構在處理圖像處理、科學計算、機器學習等需要對大量數據執行相同操作的應用程序時特別有效。它能夠顯著提高這些任務的處理速度。
? ? ? ? 一個操作可以指定對儲存在一個寄存器中的多個數據進行相同的處理。
VADD. I16 Q10,Q8,Q9
????????SIMD(Single Instruction, Multiple Data)架構在特定的應用領域內提供了顯著的性能優勢,但也存在一些局限性。以下是SIMD的優勢與缺點的概述:
1.1.2.1 SIMD的優勢
1.1.2.1.1 提高數據處理效率
????????SIMD可以同時對多個數據執行相同的操作,顯著提高了數據處理的速度,尤其是在處理大規模數據集時,如圖像處理、視頻編解碼、科學計算和機器學習等應用。通過同時對多個數據點執行相同的操作,SIMD可以大幅提高數據處理速度,尤其是在涉及大量數據運算的應用中。
1.1.2.1.2 能效比提升
????????由于可以在單個操作中處理多個數據點,SIMD架構可以更有效地利用處理器資源,減少了必要的指令數量和處理器周期,從而在執行大規模并行數據處理任務時提高能效比。相較于分別對每個數據點執行操作,SIMD通過減少指令的數量來降低能源消耗,從而提高能效。
1.1.2.1.3 簡化編程模型
????????對于能夠利用數據并行性的應用,SIMD提供了一種相對簡單的方式來加速計算,程序員可以不必管理復雜的多線程或多進程并發模型,而是通過向量化操作來實現性能提升。
1.1.2.1.4 并行處理能力
????????SIMD架構能夠利用數據并行性,有效加速并行處理任務,這對于實時處理和高性能計算來說至關重要。
1.1.2.2?缺點
1.1.2.2.1 編程復雜性
????????雖然SIMD可以簡化某些并行編程任務,但編寫有效利用SIMD指令的代碼通常需要對目標應用和硬件架構有深入的理解。此外,需要手動優化代碼以適應特定的SIMD架構,這可能會增加開發復雜性。利用SIMD的高性能可能需要開發者對算法進行特殊優化,這可能增加編程的復雜性。
1.1.2.2.2 應用局限性
????????SIMD最適合于那些可以進行大量相同操作的數據并行任務。對于需要不同數據執行不同操作的任務,或者數據依賴性導致無法并行的情況,SIMD的優勢可能會大幅減少。
1.1.2.2.3 硬件資源限制
????????實現SIMD需要額外的硬件資源,如向量寄存器和專門的執行單元。這意味著,與傳統的標量處理相比,SIMD架構的處理器可能會更復雜和成本更高。在一些場景中,使用SIMD指令可能會占用大量的處理器資源,如寄存器,這可能限制其他類型操作的性能。
1.1.2.2.4 可移植性問題,向量長度固定,處理器和應用程序的依賴性
????????不同的處理器可能支持不同的SIMD指令集和向量大小,這可能導致針對特定硬件優化的代碼在其他硬件上運行效率不高,甚至無法運行。因此,實現跨平臺高性能應用可能需要針對每種目標硬件編寫和優化不同的代碼版本。
????????SIMD指令通常對特定長度的數據向量進行操作。如果處理的數據量不匹配處理器支持的向量長度,這可能導致效率低下。
????????不同的處理器可能支持不同長度的SIMD指令,這意味著軟件可能需要針對特定硬件進行優化才能實現最佳性能。
????????綜上所述,SIMD架構能夠為適合的應用場景提供顯著的性能提升和能效優勢,但同時也帶來了編程復雜性、應用局限性、硬件資源和可移植性方面的挑戰。
1.1.2.2.5 向量長度的限制
????????可擴展性問題:固定的向量長度可能不適合所有應用場景,特別是當數據集的大小變化較大時,處理器可能無法充分利用其并行處理能力。
????????效率問題:當數據集大小不能整除向量長度時,可能會出現尾部處理問題,導致處理效率降低。
????????兼容性問題:軟件需要考慮不同硬件平臺上SIMD向量長度的差異,以確保最佳性能和兼容性。
????????盡管存在這些缺點,SIMD架構在許多領域仍然是加速數據處理的有效手段。開發者和架構師需要根據具體的應用需求和硬件能力,權衡SIMD的優勢和限制,以實現最佳的性能和效率。
1.1.3?RISC-V架構中的應用
????????在RISC-V架構中,也支持這兩種處理模式。RISC-V是一種開源指令集架構(ISA),它的設計旨在支持從最小的嵌入式處理器到高性能計算(HPC)系統的廣泛設備。RISC-V定義了多個擴展,其中一些支持SIMD操作,例如“V”擴展,它為向量處理提供支持。這意味著RISC-V處理器可以配置為支持SIMD操作,以提高處理大規模數據集時的性能。
????????RISC-V向量擴展(RVV)是RISC-V指令集架構的一部分,專門用于支持向量計算。RVV的設計目標是提供一種高效、可擴展的向量處理能力,以支持從小型嵌入式系統到大型高性能計算環境的廣泛應用。以下是RVV的一些關鍵特點:
1.1.3.1?可擴展的向量長度
????????RVV允許實現可變的向量長度,這意味著硬件可以根據需要處理不同長度的向量。這種靈活性使得RVV能夠高效地適應各種處理需求,從而提高了處理器的通用性和性能。
1.1.3.2 類型和操作的豐富性
????????RVV支持多種數據類型,包括不同長度的整數和浮點數。它還定義了一系列的向量操作,如算術運算、比較、邏輯運算等,這使得RVV能夠支持廣泛的數值和非數值計算任務。
1.1.3.3 向量長度不固定
????????與其他一些固定向量長度的SIMD架構不同,RVV允許在運行時確定向量長度,這提供了更好的資源利用率和靈活性。這意味著軟件可以根據當前的硬件配置和數據集大小來優化性能,而無需為特定硬件配置重新編譯。
1.1.3.4 掩碼操作
????????RVV支持使用掩碼進行向量操作,這允許對向量中的單獨元素進行有條件的處理。這種功能對于實現復雜的數據依賴性操作非常重要,如稀疏數據處理或條件分支。
1.1.3.5 分組加載和存儲
????????RVV提供了分組加載和存儲指令,允許數據以分組的形式從內存中加載到向量寄存器,或從向量寄存器存儲回內存。這有助于更有效地管理內存帶寬,提高數據訪問效率。
1.1.3.6 向量配置指令
????????RVV引入了向量配置指令,允許動態調整向量操作的參數,如向量長度和數據類型。這增加了編程的靈活性,允許軟件更好地利用硬件資源。
1.1.3.7 兼容性和可擴展性
????????RVV設計時考慮了與RISC-V其他指令集擴展的兼容性,確保了向量擴展能夠無縫集成到現有的RISC-V生態中。此外,它的設計支持未來的擴展和優化,以適應新的計算需求。
????????總的來說,RISC-V向量擴展通過提供一種靈活、高效的方式來處理向量計算,旨在滿足從嵌入式到高性能計算的廣泛應用需求。
????????簡而言之,SISD和SIMD代表了處理數據的兩種不同方法,SISD適用于處理單個數據點的任務,而SIMD適用于同時處理多個數據點的任務。RISC-V通過支持包括SIMD在內的不同架構擴展,提供了靈活的處理能力,以適應各種應用需求。
2. RISC-V向量擴展
2.1 靈活的訪存指令
????????RISC-V向量擴展(RVV)為了提高數據處理效率和靈活性,設計了一系列靈活的訪存指令。這些指令允許高效地從內存加載數據到向量寄存器,以及將數據從向量寄存器存儲回內存。以下是一些關鍵點,描述了RVV中靈活訪存指令的特性:
2.1.1 分段加載和存儲(Strided Loads and Stores)
????????這類指令允許從內存中以固定的間隔(步長)加載數據,或者將數據存儲到內存中的固定間隔位置。這對于處理間隔排列的數據集(如矩陣的某一列)特別有用。
2.1.2 索引加載和存儲(Indexed Loads and Stores)
????????索引訪存指令允許使用另一個向量中的索引值來指定每個元素的加載或存儲位置。這為處理非規則數據結構提供了極大的靈活性,例如,當數據分布在內存中的不連續位置時。
2.1.3 單元素加載和存儲(Unit-stride Loads and Stores)
????????這類指令用于連續地加載或存儲數據,沒有間隔地從一個地址到下一個地址。這是最直接的訪存形式,適用于連續數據結構的高效處理。
2.1.4 掩碼加載和存儲(Masked Loads and Stores)
????????RVV支持使用掩碼來進行條件加載和存儲。這意味著可以根據掩碼向量中的位來選擇性地加載或存儲向量中的元素。這對于處理條件操作或稀疏數據集非常有用。
2.1.5 向量-標量操作(Vector-Scalar Operations)
????????雖然不是直接的訪存指令,但RVV允許在向量操作中使用標量值,這包括從標量寄存器加載數據到向量寄存器的能力。這增加了編程模型的靈活性,允許更高效的數據處理。
2.1.6 向量配置指令(Vector Configuration Instructions)
????????這些指令允許動態配置向量操作的參數,如向量長度和數據類型,進一步提高了對訪存操作的控制和靈活性。
????????通過這些靈活的訪存指令,RVV能夠有效支持各種數據訪問模式,從而優化性能并簡化編程模型。這些指令使得RVV非常適合處理廣泛的應用場景,包括高性能計算、數據分析、機器學習等,其中數據訪問模式可能非常多樣。
2.2?配置和設置指令
????????在RISC-V向量擴展(RVV)中,配置和設置指令是用于定義和控制向量操作的行為的一組指令。這些指令允許程序員在執行向量操作之前對向量處理單元(VPU)進行精確的配置,包括設置向量長度、數據類型和執行掩碼等。這種靈活性是RVV設計中的一個關鍵特點,它允許軟件根據運行時的需求和硬件的能力來動態調整參數,從而實現高效的向量處理。以下是一些關鍵的配置設置指令:
2.2.1 向量長度配置指令(VSETVLI)
????????這是RVV中最核心的配置指令之一,用于設置向量長度(VL)和向量數據類型。`VSETVLI`指令允許基于硬件的最大向量長度(VLMAX)來動態選擇當前操作的向量長度,同時指定操作的數據類型(如整數、浮點數等)。這使得代碼能夠在不同的硬件上以最優的向量長度運行,而無需重新編譯。
2.2.2 向量長度配置指令(VSETVL)
????????這個指令與`VSETVLI`類似,但它允許程序使用一個寄存器中的值來設置向量長度,提供了更大的靈活性。


2.2.3 掩碼配置指令
????????RVV提供了操作掩碼的能力,使得向量操作可以選擇性地對向量中的元素進行操作。掩碼操作對于執行條件處理和管理稀疏數據集非常有用。
2.2.4 向量數據類型配置
????????通過`VSETVLI`和`VSETVL`指令中的類型字段,程序可以指定向量操作的具體數據類型,如8位、16位、32位或64位的整數,以及單精度或雙精度浮點數等。這允許同一套向量指令在不同數據類型上重用,提高了代碼的可移植性和靈活性。
????????這些配置設置指令為RVV提供了極高的靈活性和可擴展性,允許軟件開發者根據具體的應用場景和硬件特性來優化他們的程序。通過動態地調整向量長度和數據類型,RVV能夠有效地支持各種向量處理需求,從嵌入式系統到高性能計算應用,同時保持代碼的簡潔和可維護性。
2.2?vtype
????????在RISC-V向量擴展(RVV)中,vtype寄存器是一個關鍵的系統寄存器,用于控制和指示當前向量操作的類型和模式。這個寄存器包含了多個字段,每個字段都有特定的作用,它們共同定義了向量指令的執行特性,包括向量長度(VL),數據類型,以及其他可能的配置選項如分段加載/存儲操作的步長等。
2.2.1?vtype寄存器的主要字段
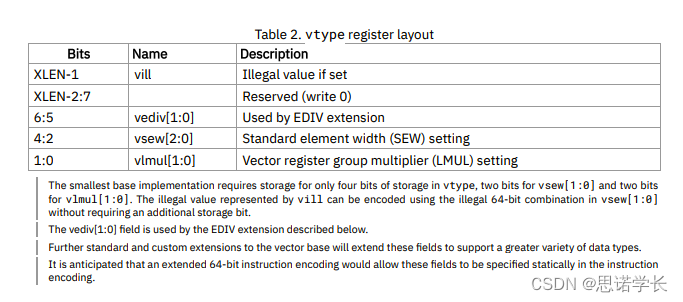
2.2.1.1 向量數據類型(`vsew`)
????????這個字段指定了向量中元素的數據寬度,例如8位、16位、32位或64位等。它決定了向量操作處理的數據類型大小。
2.2.1.2 向量長度乘數(`vlmul`)
????????這個字段允許向量寄存器組以不同的組合方式使用,從而支持更寬的向量操作或更多的并行度。它影響了向量寄存器組的配置和使用方式。
2.2.1.3 掩碼寄存器(`vta`和`vma`)
????????這些字段控制向量操作中的掩碼類型,包括對齊訪問(`vta`)和掩碼訪問(`vma`),允許細粒度控制向量操作的執行。
2.2.1.4 向量長度(VL)
????????雖然VL通常是通過`vsetvli`或`vsetvl`指令動態設置的,但`vtype`寄存器的配置直接影響可以實現的VL的最大值和行為。
2.2.1.5?vtype寄存器的作用
????????配置向量操作:通過設置`vtype`寄存器,軟件可以詳細配置向量指令的執行方式,包括操作的數據類型和向量長度,這為高效的向量計算提供了基礎。
????????適應不同的硬件:由于`vtype`的配置可以動態變化,軟件可以根據運行時檢測到的硬件能力(如支持的最大向量長度和數據寬度)來調整向量操作的配置,實現跨不同硬件的可移植性和優化。
????????優化性能:通過靈活地使用`vtype`寄存器配置,程序可以針對具體的算法和數據特征來優化向量操作,比如選擇最適合處理特定數據大小和形狀的向量長度和數據類型,從而提高計算效率和性能。
????????vtype寄存器的設計反映了RISC-V向量擴展的核心設計哲學——靈活性和可擴展性,使得RISC-V向量指令集能夠適應廣泛的應用需求,從而在不同的計算環境中實現高效的向量計算。
2.3?寄存器組
????????在RISC-V向量擴展(RVV)中,向量寄存器組是一組專門設計用于存儲和操作向量數據的寄存器。這些寄存器與傳統的標量寄存器不同,它們能夠存儲多個數據元素,并支持對這些元素進行并行操作。向量寄存器組的設計旨在提高數據處理的效率,特別是對于那些可以利用數據并行性的應用場景,如數字信號處理、圖像處理、科學計算等。
2.3.1 向量寄存器組的特點
2.3.1.1 寄存器數量和大小
????????RVV規范定義了一組向量寄存器,數量通常為32個(從v0到v31),但這可以根據具體的實現而變化。每個向量寄存器的大小不是固定的,而是可以配置的,允許存儲多個數據元素。向量寄存器的大小通常以位(bit)為單位描述,其最大長度由硬件支持的最大向量長度決定。
2.3.1.2 動態配置
????????通過vsetvli(設置向量長度和類型的指令)等指令,軟件可以動態地配置向量寄存器組的行為,包括向量長度(即寄存器中可以存儲的元素數量)和元素的數據類型(如8位整數、32位浮點數等)。這種動態配置能力提供了極大的靈活性,允許軟件根據不同的應用需求和硬件能力來優化性能。
2.3.1.3 并行操作
????????向量寄存器組設計用于支持單指令多數據(SIMD)操作,這意味著一條向量指令可以同時對寄存器中的多個數據元素執行相同的操作。這種并行處理能力可以顯著提高數據處理任務的效率。
2.3.1.4 掩碼操作
????????RVV允許通過掩碼操作來條件地執行向量指令,即只對那些被掩碼選中的元素執行操作。這為處理復雜的數據依賴和條件邏輯提供了強大的工具。
2.3.1.5 支持多種數據類型
????????向量寄存器組支持多種數據類型,包括不同長度的整數和浮點數,這使得它們可以適用于廣泛的應用場景。
2.3.1.6 適用于多種計算模型
????????由于其高度的配置能力和強大的并行處理能力,向量寄存器組適用于多種計算模型,從傳統的數據并行處理到更復雜的模型,如圖形處理和機器學習等。
????????向量寄存器組是RISC-V向量擴展的核心組成部分,它們的設計目的是為了提供高效的并行數據處理能力,以適應當前和未來計算密集型應用的需求。通過靈活的配置和強大的處理能力,向量寄存器組使得RISC-V架構能夠有效地支持寬廣的應用領域。
-狀態機模式)

)

:模板的實例化問題)











)


