聚合查詢的概念
- 聚合查詢(Aggregation Queries)是Elasticsearch中用于數據匯總和分析的查詢類型。
- 它不同于普通的查詢,而是用于執行各種聚合操作,如計數、求和、平均值、最小值、最大值、分組等。
聚合查詢的分類
分桶聚合(Bucket Aggregations)
-
類似于SQL中的GROUP BY操作,根據指定的條件對數據進行分組統計。
-
可以進行嵌套分桶,即在一個分桶的基礎上再進行細分。
-
示例:按照手機的品牌進行分桶統計數量,再在小米手機的分桶基礎上按照檔次進行二次分桶。
-
語法格式
GET /index/_search
{"size": 0,"aggs": {"aggregation_name": {"bucket_type": {"bucket_options": {"bucket_option_name": "bucket_option_value",...},"aggs": {"sub_aggregation_name": {"sub_aggregation_type": {"sub_aggregation_options": {"sub_aggregation_option_name": "sub_aggregation_option_value",...}}}}}}}
}
#解析
# index: 替換為要執行聚合查詢的索引名稱。
# aggregation_name: 替換為自定義的聚合名稱。
# bucket_type: 替換為特定的桶聚合類型(如 terms、date_histogram、range 等)。
# bucket_option_name 和 bucket_option_value: 替換為特定桶聚合選項的名稱和值。
?
# sub_aggregation_name: 替換為子聚合的名稱。
# sub_aggregation_type: 替換為特定的子聚合類型(如 sum、avg、max、min 等)。
# sub_aggregation_option_name 和 sub_aggregation_option_value: 替換為特定子聚合選項的名稱和值
指標聚合(Metrics Aggregations)
-
主要用于計算數值字段的統計信息,如平均值、最大值、最小值、求和、去重計數等。
-
示例:計算某個班級、某個學科的最高分、最低分等。
-
語法格式
GET /index/_search
{"size": 0,"aggs": {"aggregation_name": {"aggregation_type": {"aggregation_field": "field_name"// 可選參數}}// 可以添加更多的聚合}
}
?
# 解析
#index:要執行聚合查詢的索引名稱。
#size: 設置為 0 來僅返回聚合結果,而不返回實際的搜索結果,這里將hits改為0表示返回的原始數據變為0
#aggs:指定聚合操作的容器。
?
#aggregation_name:聚合名稱,可以自定義。
#aggregation_type:聚合操作的類型,例如 terms、avg、sum 等。
#aggregation_field:聚合操作的目標字段,對哪些字段進行聚合
聚合查詢的特點
-
嵌套性:聚合查詢支持嵌套,即一個聚合內部可以包含別的子聚合,實現復雜的數據挖掘和統計需求。
-
靈活性:可以用于多種場景的數據分析,滿足各種業務需求。
-
高效性:Elasticsearch的聚合查詢基于倒排索引和優化的數據結構,使得聚合操作能夠高效地執行。
常見聚合用途及應用場景
聚合指標(Aggregation Metrics):
- Avg Aggregation:計算文檔字段的平均值。- Sum Aggregation:計算文檔字段的總和。- Min Aggregation:找到文檔字段的最小值。- Max Aggregation:找到文檔字段的最大值。
聚合桶(Aggregation Buckets):
- Terms Aggregation:基于字段值將文檔分組到不同的桶中。
- 語法格式
GET /index/_search
{"size": 0,"aggs": {"aggregation_name": {"bucket_type": {"bucket_options": {"bucket_option_name": "bucket_option_value",...},"aggs": {"sub_aggregation_name": {"sub_aggregation_type": {"sub_aggregation_options": {"sub_aggregation_option_name": "sub_aggregation_option_value",...}}}}}}}
}
#解析
#index: 替換為要執行聚合查詢的索引名稱。
#aggregation_name: 替換為自定義的聚合名稱。
#bucket_type: 替換為特定的桶聚合類型(如 terms、date_histogram、range 等)。
#bucket_option_name 和 bucket_option_value: 替換為特定桶聚合選項的名稱和值。
?
#sub_aggregation_name: 替換為子聚合的名稱。
#sub_aggregation_type: 替換為特定的子聚合類型(如 sum、avg、max、min 等)。
#sub_aggregation_option_name 和 sub_aggregation_option_value: 替換為特定子聚合選項的名稱和值- Date Histogram Aggregation:按日期/時間字段創建時間間隔的桶。
- 語法格式
GET /index/_search
{"size": 0,"aggs": {"date_histogram_name": {"date_histogram": {"field": "date_field_name","interval": "interval_expression"},"aggs": {"sub_aggregation": {"sub_aggregation_type": {}}}}}
}
?
#解析
#index:替換為要執行聚合查詢的索引名稱。
#date_histogram_name:替換為自定義的 date_histogram 聚合名稱。
#date_field_name:替換為要聚合的日期類型字段名。
#interval_expression:指定用于分桶的時間間隔。時間間隔可以是一個有效的日期格式(如 1d、1w、1M),也可以是一個數字加上一個時間單位的組合(如 7d 表示 7 天,1h 表示 1 小時)。
#sub_aggregation:指定在每個日期桶內進行的子聚合操作。
#sub_aggregation_type:替換單獨子聚合操作的類型,可以是任何有效的子聚合類型。- Range Aggregation:根據字段值的范圍創建桶。
- 語法格式
GET /index/_search
{"size": 0,"aggs": {"range_name": {"range": {"field": "field_name","ranges": [{ "key": "range_key_1", "from": from_value_1, "to": to_value_1 },{ "key": "range_key_2", "from": from_value_2, "to": to_value_2 },...]},"aggs": {"sub_aggregation": {"sub_aggregation_type": {}}}}}
}
?
#解析
# index:替換為要執行聚合查詢的索引名稱。
# range_name:替換為自定義的 range 聚合名稱。
# field_name:替換為要聚合的字段名。
# ranges:指定范圍數組,每個范圍使用 key、from 和 to 參數進行定義。
# key:范圍的唯一標識符。
# from:范圍的起始值(包含)。
# to:范圍的結束值(不包含)。
# sub_aggregation:指定在每個范圍內進行的子聚合操作。
# sub_aggregation_type:替換單獨子聚合操作的類型,可以是任何有效的子聚合類型。
Query DSL指標聚合多案例介紹實戰
創建索引
PUT /sales
{"mappings": {"properties": {"id":{"type":"keyword"},"product": {"type": "keyword"},"sales": {"type": "integer"}}}
}
批量插入數據
POST /sales/_bulk
{"index": {}}
{"product": "iPhone", "sales": 4}
{"index": {}}
{"product": "Samsung", "sales": 60}
{"index": {}}
{"product": "iPhone", "sales": 100}
{"index": {}}
{"product": "Samsung", "sales": 80}
{"index": {}}
{"product": "小米手機", "sales": 50}
{"index": {}}
{"product": "小米手機", "sales": 5000}
{"index": {}}
{"product": "小米手機", "sales": 200}
指標聚合實戰
根據商品名稱分組
GET /sales/_search
{"aggs": {"phone_group": {"terms": {"field": "product"}}}
}
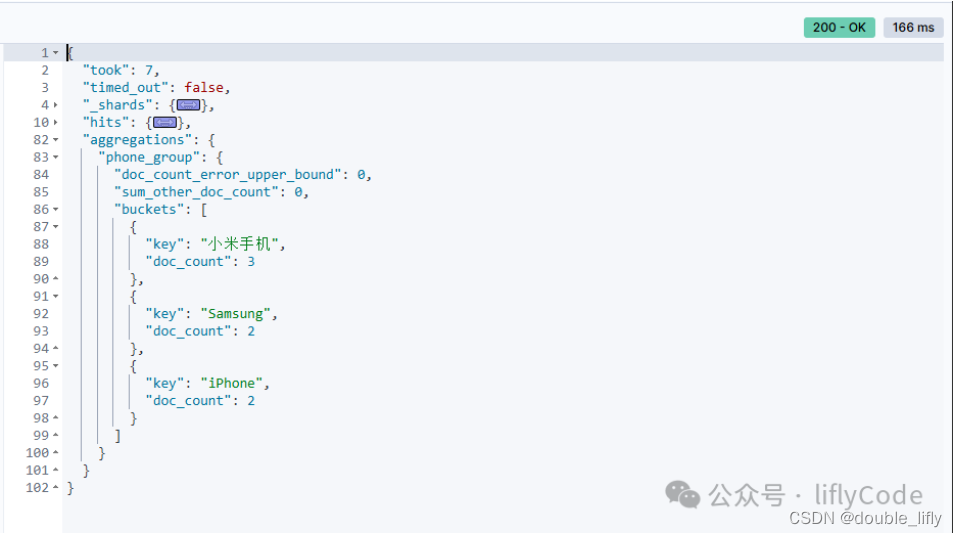
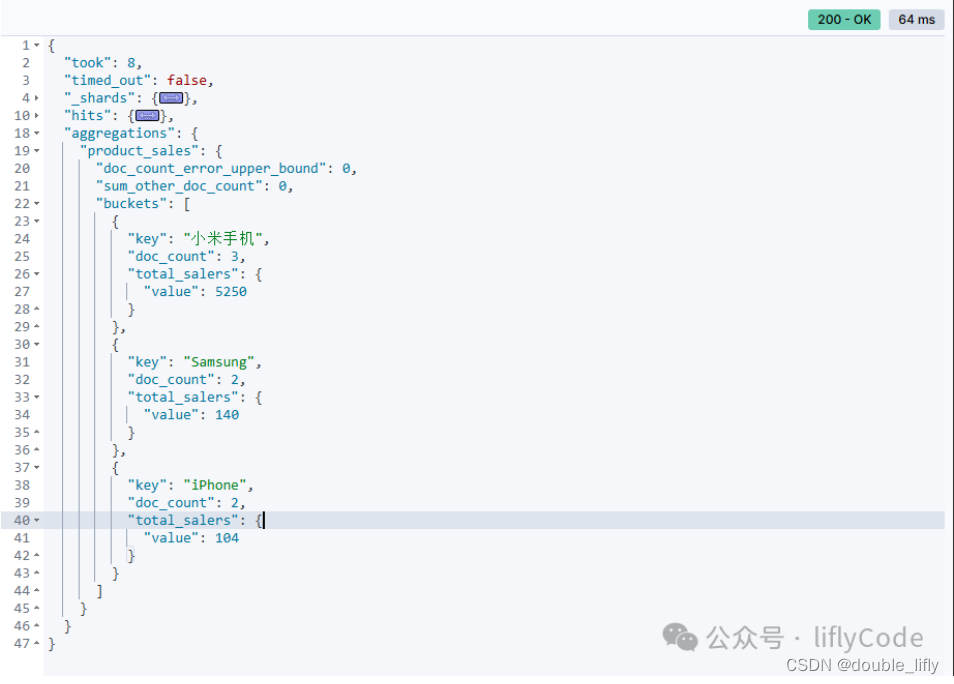
計算每組的銷售總量,使用terms聚合和sum聚合來
GET /sales/_search
{"size": 0,"aggs": {"product_sales": {"terms": {"field": "product" },"aggs": {"total_salers": {"sum": {"field": "sales"}}}}}
}
計算總和
GET /sales/_search
{"aggs": {"sum_sales": {"sum": {"field": "sales"}}}
}
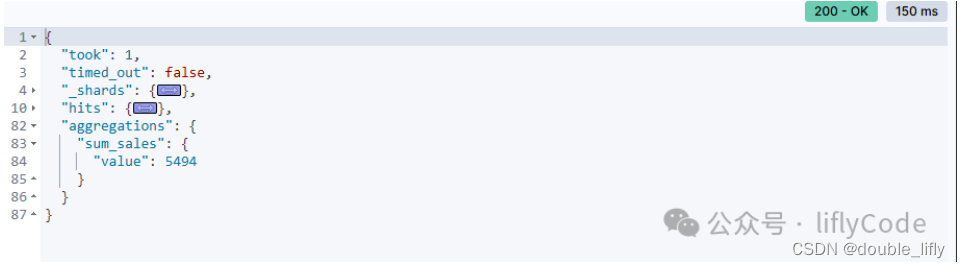
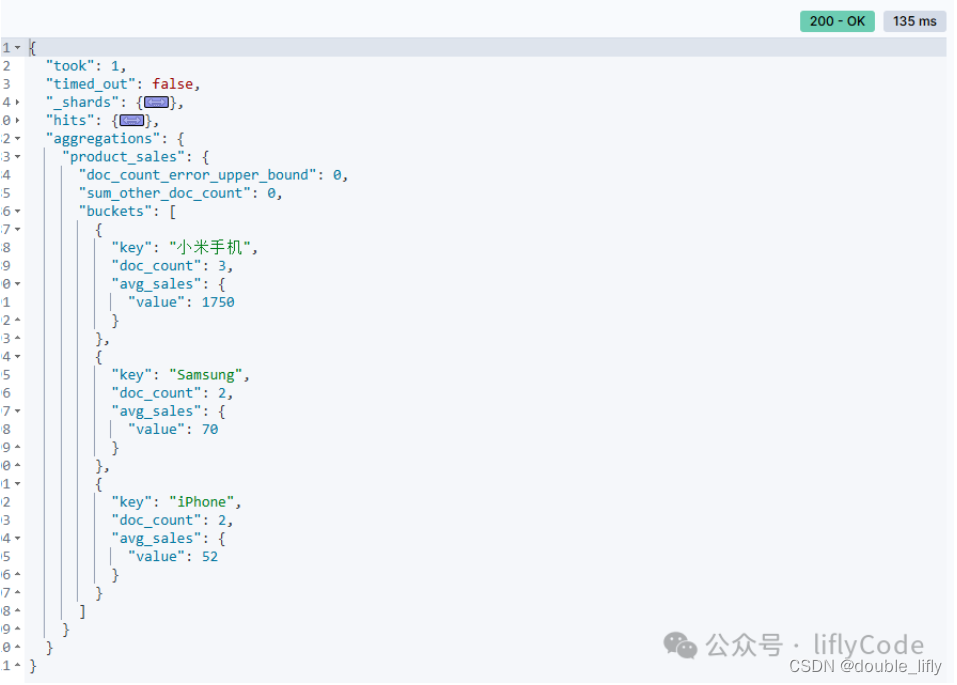
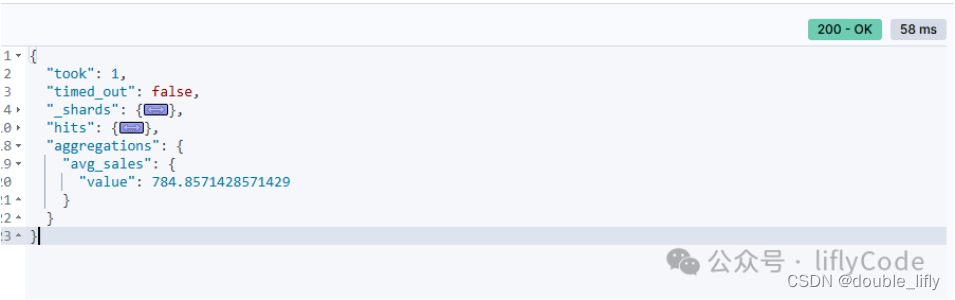
計算不同品牌的平均值
GET /sales/_search
{"aggs": {"product_sales": {"terms": {"field": "product"},"aggs": {"avg_sales": {"avg": {"field": "sales"}}}}}
}
計算總商品的平均值
GET /sales/_search
{"size": 0,"aggs": {"avg_sales": {"avg": {"field": "sales"}}}
}
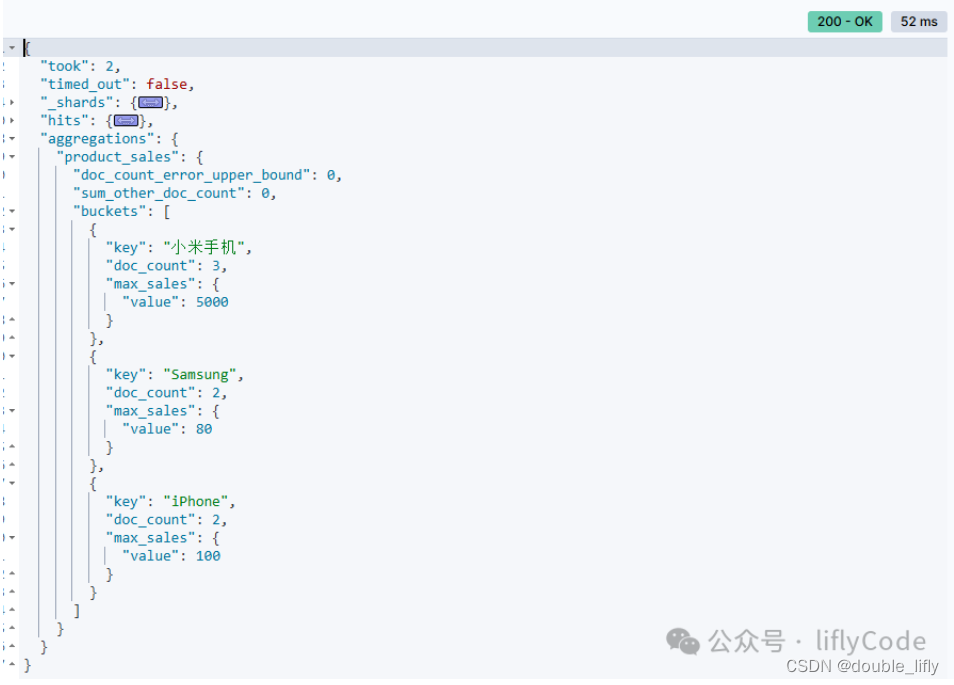
計算不同品牌的手機的最高低價
GET /sales/_search
{"size": 0,"aggs": {"product_sales": {"terms": {"field": "product"},"aggs": {"max_sales": {"max": {"field": "sales"}}}}}
}
?
?
GET /sales/_search
{"size": 0,"aggs": {"product_sales": {"terms": {"field": "product"},"aggs": {"max_sales": {"min": {"field": "sales"}}}}}
}
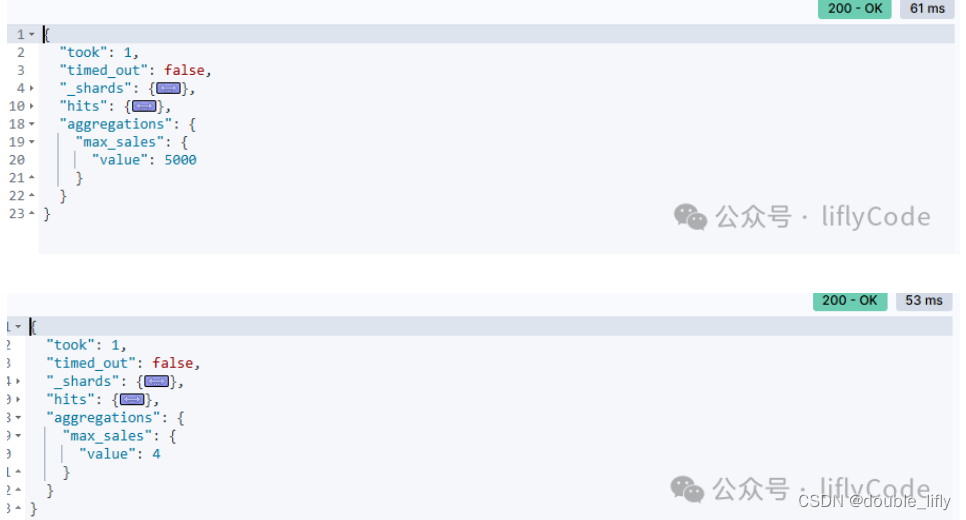
查找最大最小值
GET /sales/_search
{"size": 0,"aggs": {"max_sales": {"max": {"field": "sales"}}}
}
?
GET /sales/_search
{"size": 0,"aggs": {"max_sales": {"min": {"field": "sales"}}}
}
Query DSL 桶聚合Terms案例實戰
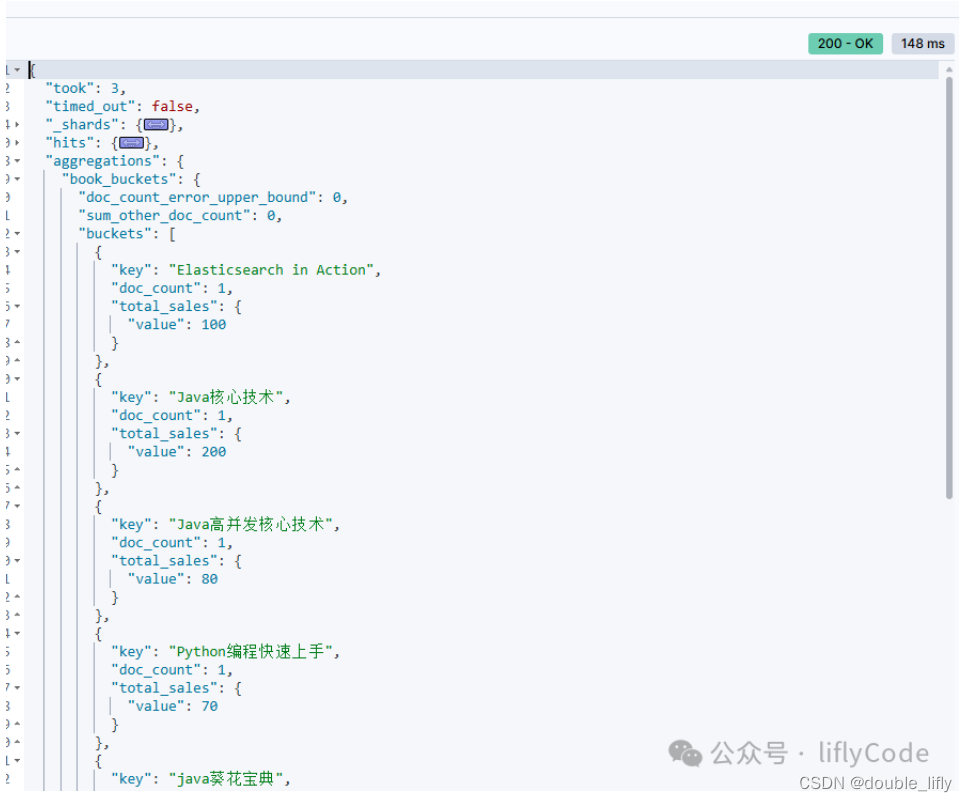
使用 terms 聚合查詢將圖書按銷售數量進行分桶,并獲取每個分桶內的銷售數量總和。
GET /book_sales/_search
{"size": 0,"aggs": {"book_buckets": {"terms": {"field": "book_title"},"aggs": {"total_sales": {"sum": {"field": "sales_count"}}}}}
}
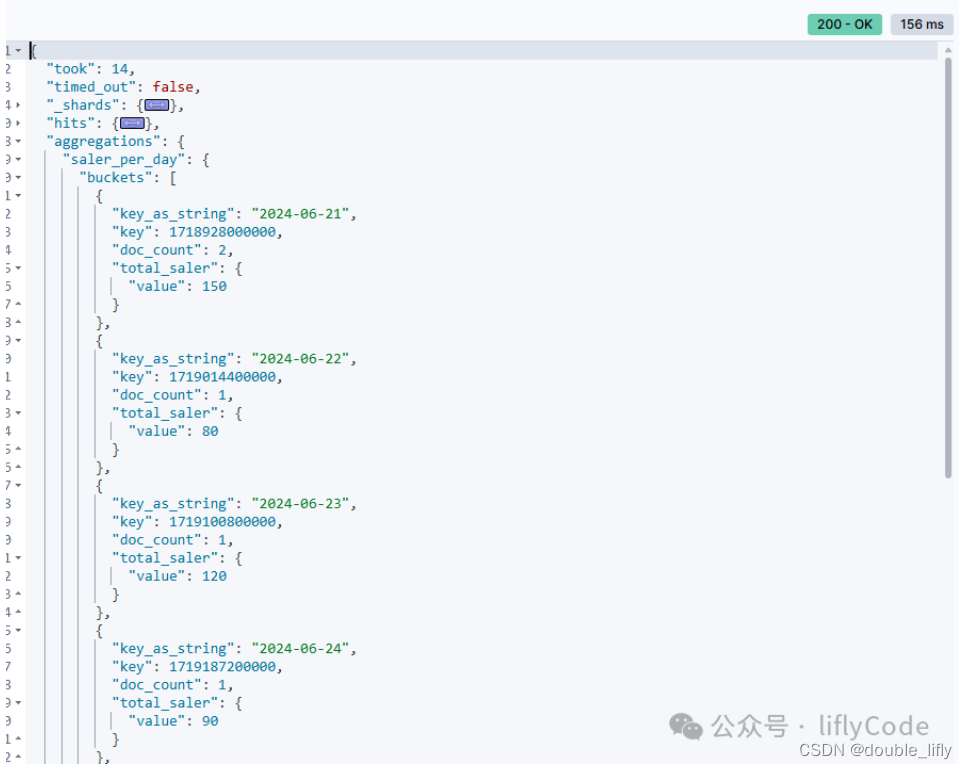
Query DSL 桶聚合Date Histogram介紹和案例實戰
使用 date_histogram 聚合查詢將訂單按日期進行分桶,并計算每個分桶內的訂單金額總和
GET /book_sales/_search
{"size": 0,"aggs": {"saler_per_day": {"date_histogram": {"field": "date","calendar_interval": "day","format": "yyyy-MM-dd"},"aggs": {"total_saler": {"sum": {"field": "sales_count"}}}}}
}
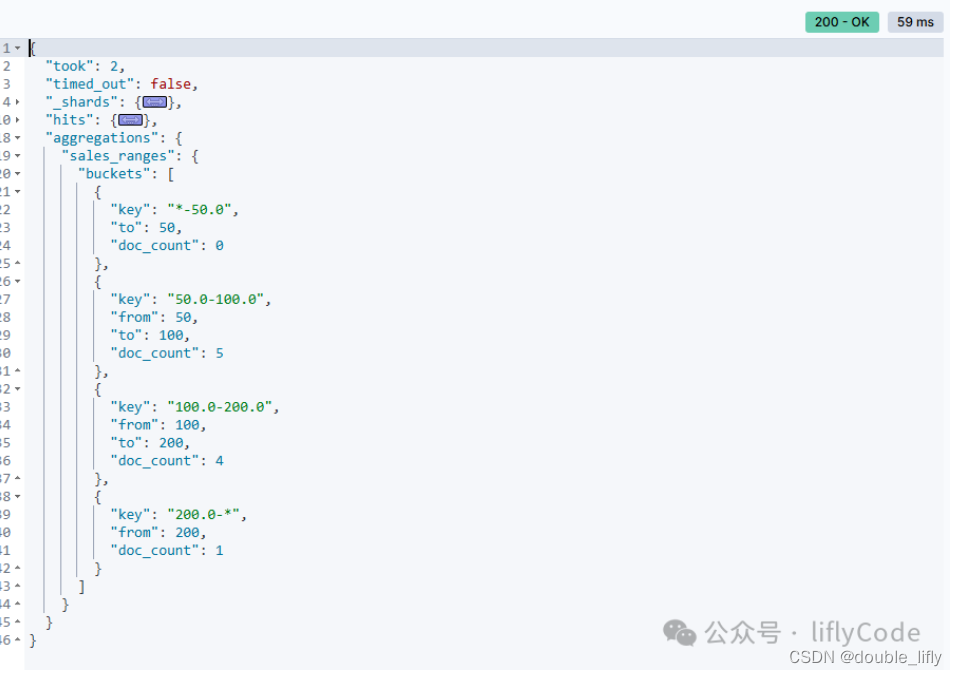
Query DSL 桶聚合Range介紹和案例實戰
使用 range 聚合查詢將商品按價格范圍進行分桶,并計算每個分桶內的商品數量
GET /book_sales/_search
{"size": 0,"aggs": {"sales_ranges": {"range": {"field": "sales_count","ranges": [{"to": 50},{"from": 50,"to": 100},{"from": 100,"to": 200},{"from": 200}]}}}
}
通過本篇文章的深入解析,我們不僅掌握了Elasticsearch聚合查詢的基本概念與分類,還通過一系列實戰案例學習了如何有效地運用分桶聚合與指標聚合進行數據挖掘與統計分析。從簡單的平均值、求和計算到復雜的多層級分桶與時間序列分析,Elasticsearch的聚合功能展現了其在大規模數據處理與復雜業務分析場景中的強大能力。
記住,無論是進行市場趨勢分析、用戶行為洞察還是日志數據的深入挖掘,合理設計聚合查詢都是解鎖數據價值的關鍵。隨著實踐的深入,不斷探索高級特性與優化策略,你將能更加靈活高效地應對各種數據分析挑戰。
總之,Elasticsearch聚合查詢是通往數據智能分析的重要橋梁,它不僅能夠幫助我們快速洞察數據分布特征,還能驅動業務決策更加精準高效。希望本指南能成為你掌握Elasticsearch聚合查詢技能的堅實基石,開啟數據驅動決策的新篇章。
更多精彩內容,請關注以下公眾號








)











