目錄
- 處理不平衡數據集
- 1.分類需求描述
- 2.計算精確率和召回率
- 權衡精確率和召喚率
- 1.手動調整閾值
- 2.F1分數
- 總結
處理不平衡數據集
1.分類需求描述
如果你在處理一個機器學習應用,其中正例和負例的比例(用于解決分類問題)非常不平衡,遠遠不是50-50,常規的錯誤指標如準確率不適用。通過一個檢測罕見疾病的例子,指出即使算法有99%的準確率,可能仍然沒有實際意義,因為簡單的總是預測為0的算法也能達到類似的準確率。因此,在這種情況下,應該使用其他錯誤指標來評估算法的表現。
2.計算精確率和召回率
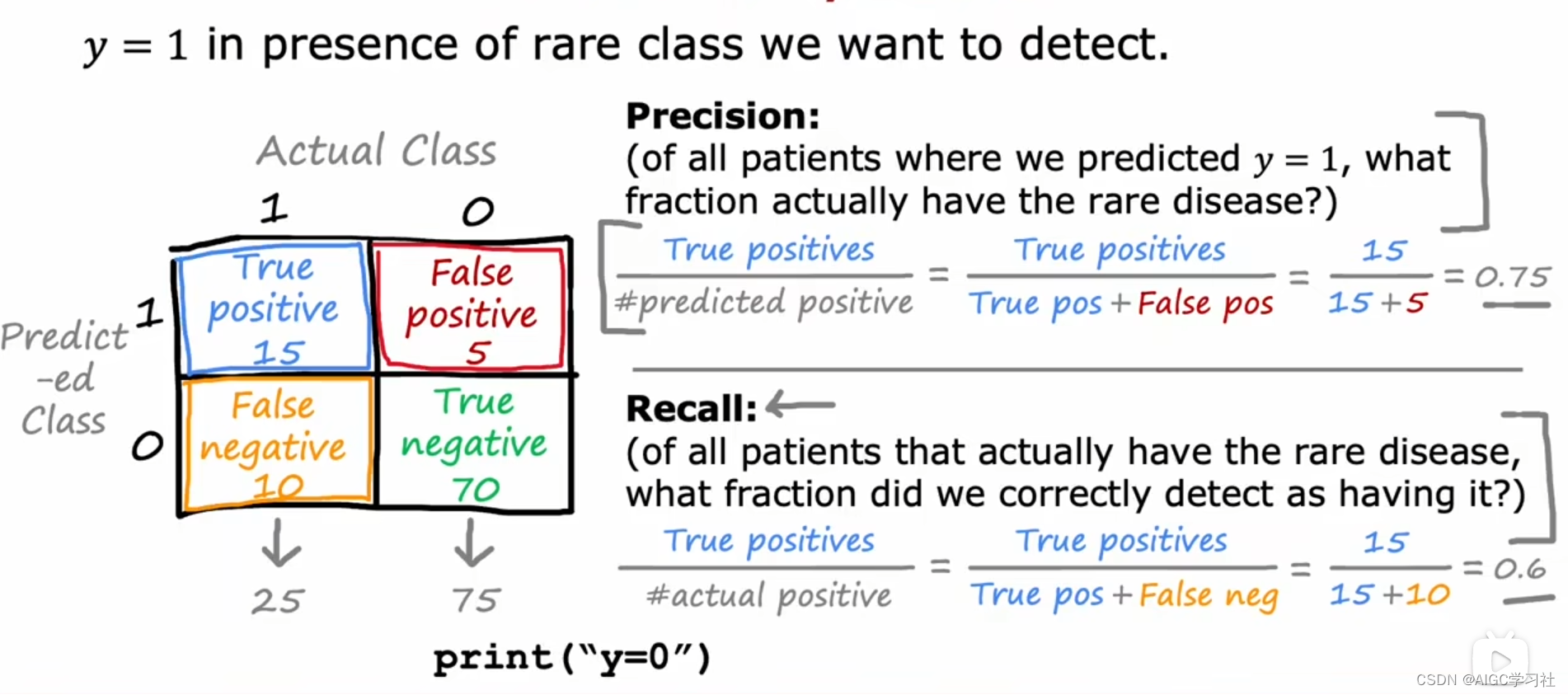
通過構建混淆矩陣,可以計算出真陽性(實際預測都為1)、假陽性(實際為0預測為1)、真陰性(實際預測都為0)和假陰性(實際為1預測為0),從而求得準確率和召回率。
準確率:有多少人真正患有罕見病?真陽性數量/被預測分類為真陽性的數量。
召回率:所有患有罕見病的人中,我們正確檢測到多少人有這種病?真陽性數量/實際真陽性的數量。
在罕見類別中,這兩個指標可以幫助更好地評估算法的有效性。
權衡精確率和召喚率
1.手動調整閾值
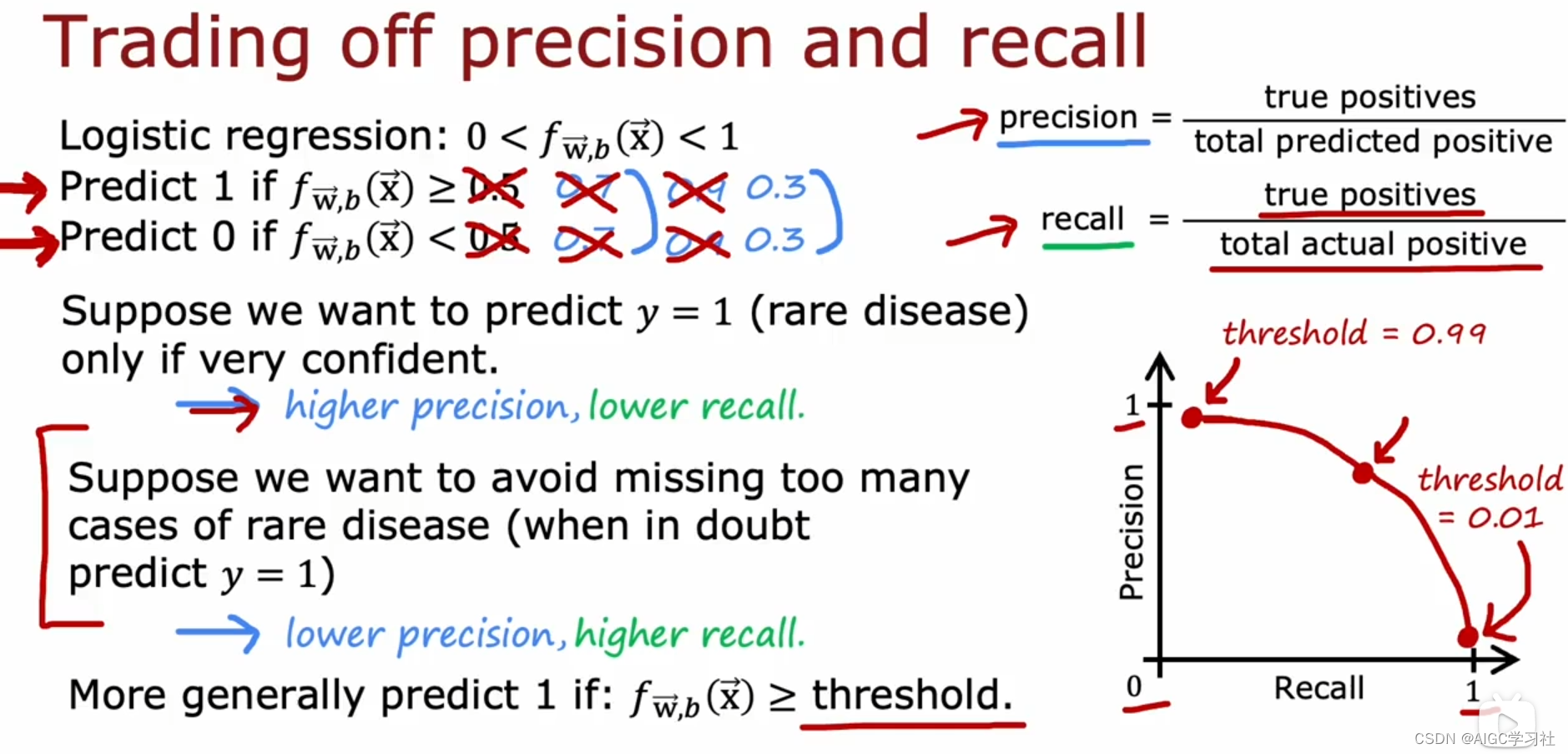
在理想狀況下,我們追求高精確度和高召回率的機器學習算法,但現實中這兩者往往不可兼得。通過調整預測模型(如邏輯回歸)的閾值,可以在精確度和召回率之間進行權衡
-
提高閾值(如從0.5提高到0.7或0.9)會增加模型的精確度,因為它僅在高度確信時預測為正例,減少了假陽性,但這也降低了召回率,因為一些實際的正例可能因標準過高而被遺漏。
-
降低閾值(如降至0.3)會提升召回率,因為模型在較低的確信度下也會預測為正例,減少了假陰性,但同時引入了更多的假陽性,降低了精確度。
選擇合適的閾值需依據具體應用場景:
- 如果錯誤預測的代價很高(如誤診導致不必要的治療),可能傾向于提高閾值保證精確度。
- 若漏診的后果更嚴重(如錯過治療時機),則可能降低閾值以提高召回率。
通過繪制精確度-召回率曲線并選擇曲線上的特定點,可以幫助平衡精確度和召回率,以適應不同的成本效益分析或應用需求。手動調整閾值是一種策略,它依賴于對應用場景特性的深入理解,無法簡單地通過自動化過程如交叉驗證來完成。
2.F1分數
為了自動平衡精度和召回率,可以使用 F1 分數。精度和召回率作為兩個不同的指標,可能會使選擇最佳算法變得困難。F1 分數結合了精度和召回率,更強調較低的一個值,提供了一個綜合指標來選擇最佳算法。
計算 F1 分數的方法是平均 1/精度 和 1/召回率 的值,然后取其倒數。這種方法比簡單平均更有效,因為它避免了精度或召回率特別低的情況。

總結
在處理正負樣本比例嚴重不平衡的問題時,傳統的錯誤指標如準確率并不適用。一個算法可能在測試集上達到1%的錯誤率,看起來效果很好,但如果疾病非常罕見,簡單地預測所有患者沒有疾病的非學習算法也能達到99.5%的準確率。這表明準確率不足以評估算法的有效性。在這種情況下,使用精度和召回率更為合適。精度衡量預測為陽性的樣本中有多少是正確的,而召回率衡量實際為陽性的樣本中有多少被正確識別。通過混淆矩陣,可以計算出這些指標,并更好地評估算法的性能。這對于檢測罕見類別特別有用。
)


















