第1關:基于支持向量機模型的應用案例
任務描述
本關任務:編寫一個基于支持向量機模型的應用案例。
相關知識
在本應用案例中,我們借助一個具體的實際問題,來完整地實現基于支持向量機模型的開發應用。在此訓練中,我們會介紹如何加載數據集、訓練集與測試集的劃分,以及如何利用sklearn構建支持向量機模型。
SVM應用案例之數據加載
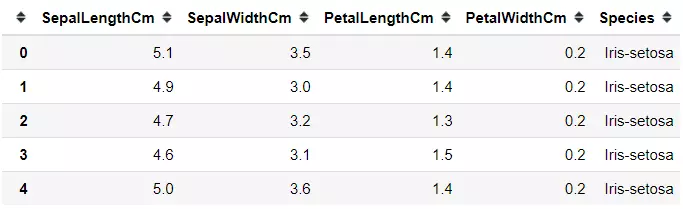
Iris數據集是機器學習任務中常用的分類實驗數據集,由Fisher在1936收集整理。 Iris中文名是安德森鳶尾花卉數據集,英文全稱是Anderson’s Iris data set,是一類多重變量分析的數據集。Iris一共包含150個樣本,分為3類,每類50個數據,每個數據包含4個屬性。可通過花萼長度,花萼寬度,花瓣長度,花瓣寬度4個屬性預測鳶尾花卉屬于(Setosa,Versicolour,Virginica)三個種類中的哪一類。
樣本局部截圖:
我們可以通過以下方法從sklearn庫加載該數據集。
dataset = load_iris()
SVM應用案例之數據劃分
我們通常使用 train_test_split() 函數來隨機劃分樣本數據為訓練集和測試集,這樣做的好處是隨機客觀的劃分數據,減少人為因素。
其中該函數中包含的參數為:
train_data:待劃分樣本數據
train_target:待劃分樣本數據的結果(標簽)
test_size:測試數據占樣本數據的比例,若整數則樣本數量
random_state:設置隨機數種子,保證每次都是同一個隨機數。若為0或不填,則每次得到數據都不一樣 具體實現如下:
x_train,x_test,y_train,y_test = train_test_split(data_x,data_y,test_size=0.3)
SVM核心算法實現
sklearn庫是機器學習領域當中最知名的 python 模塊之一。他包含了很多種機器學習的內容,如分類,回歸,數據處理,模型選擇等等,用途廣泛且非常方便,其中就包括了支持向量機模型,我們可以輕松地調用sklearn庫中封裝好的svm函數實現操作,具體操作如下:
from sklearn import svm;//調用sklearn庫中的svm函數clf = svm.SVC();//調用svm函數中的SVC核心算法
SVM應用案例之評價指標
在分類任務中,常有的評價指標如下圖所示。
針對二分類問題,即將實例分成正類(positive)或負類(negative),在實際分類中會出現以下四種情況: (1)若一個實例是正類,并且被預測為正類,即為真正類(True Positive TP) (2)若一個實例是正類,但是被預測為負類,即為假負類(False Negative FN) (3)若一個實例是負類,但是被預測為正類,即為假正類(False Positive FP) (4)若一個實例是負類,并且被預測為負類,即為真負類(True Negative TN)
我們常用準確率來衡量分類器正確的樣本與總樣本數之間的關系。 具體公式為
?Accuracy?=TP+TN+FP+FNTP+TN?
在本次應用案例中,我們通過比較預測值與真實值來統計預測正確的數目,具體實現如下:
cnt = 0 //初始化為零for i in range(len(y_test)): //通過循環來遍歷尋找預測正確的數目if y_predict[i] == y_test[i]:cnt +=1print(cnt/len(y_predict)) //由預測正確的數目除以總數目得到準確率accuracy。
第1關任務——代碼題
from sklearn import svm # 加載sklearn庫來調用svm算法
from sklearn.datasets import load_iris #加載sklearn庫中的數據集
from sklearn.model_selection import train_test_split #劃分測試集訓練集#1.加載數據集
################# Begin #################
datas = load_iris()
################# End #################
data_x = datas.data #定義數據
data_y = datas.target #定義標簽#2.劃分訓練集和測試集
################# Begin #################
x_train,x_test,y_train,y_test = train_test_split(data_x,data_y,test_size=0.3)
################# End ##################3.調用svm函數
################# Begin #################
from sklearn import svm;
clf = svm.SVC();
################# End #################clf = clf.fit(x_train,y_train) #開始訓練svm模型
a = clf.predict(x_test) #開始測試cnt = 0
for i in range(len(y_test)): #評價預測的結果if a[i] == y_test[i]:cnt +=1
print(cnt/len(a))

)




)


)




)



 unplugin-vue-router 實用教程)