目錄
- 1. 引言
- 2. RAG技術概述
- 2.1 RAG技術的定義
- 2.2 RAG技術的工作原理
- 2.3 RAG技術的優勢
- 2.4 RAG技術的應用場景
- 3. RAG的工作流程
- 3.1 輸入處理
- 3.2 索引建立
- 3.3 信息檢索
- 3.4 文檔生成
- 3.5 融合與優化
- 4. RAG范式的演變
- 4.1 初級 RAG 模型
- 4.2 高級 RAG 模型
- 4.3 模塊化 RAG 模型
- 優化技術
- 5. RAG系統的核心組成部分
- 5.1 檢索技術
- 5.2 文本生成
- 5.3 增強技術
- 5.4 RAG與微調的比較
- 6. RAG 模型評估解析
- 6.1 評估重要性
- 6.2 評估方法
- 6.3 評估內容
- 6.4 評估維度
- 6.5 評估工具
- 6.6 評估實踐
- 7. RAG研究的挑戰與前景
- 7.1 關鍵挑戰
- 7.2 前景與方向
- 7.3 未來工作
- 8. 結語
1. 引言
在人工智能的不斷演進中,大語言模型(LLMs)已成為解決復雜問題的關鍵工具。但它們在處理需要最新信息或專業知識的任務時,受限于靜態知識庫,影響了內容的準確性和時效性。為了克服這一局限,檢索增強生成(RAG)技術應運而生,它通過整合實時數據和外部知識庫,顯著提高了AI響應的質量和信息的更新速度。
RAG技術代表了AI領域的一個創新突破,為開發者和研究者提供了一種全新的解決方案。它與傳統的預訓練語言模型不同,能夠動態檢索最新信息,生成更準確、豐富、可靠的輸出,特別適合知識密集型任務和快速適應新知識的應用場景。
2. RAG技術概述
在人工智能的宏偉藍圖中,檢索增強生成(RAG)技術正逐漸成為支撐知識密集型應用的基石。本章將帶您領略RAG技術的精髓,從其定義、工作原理到在現代AI領域的應用場景,全面解析這一創新技術的核心價值。
2.1 RAG技術的定義
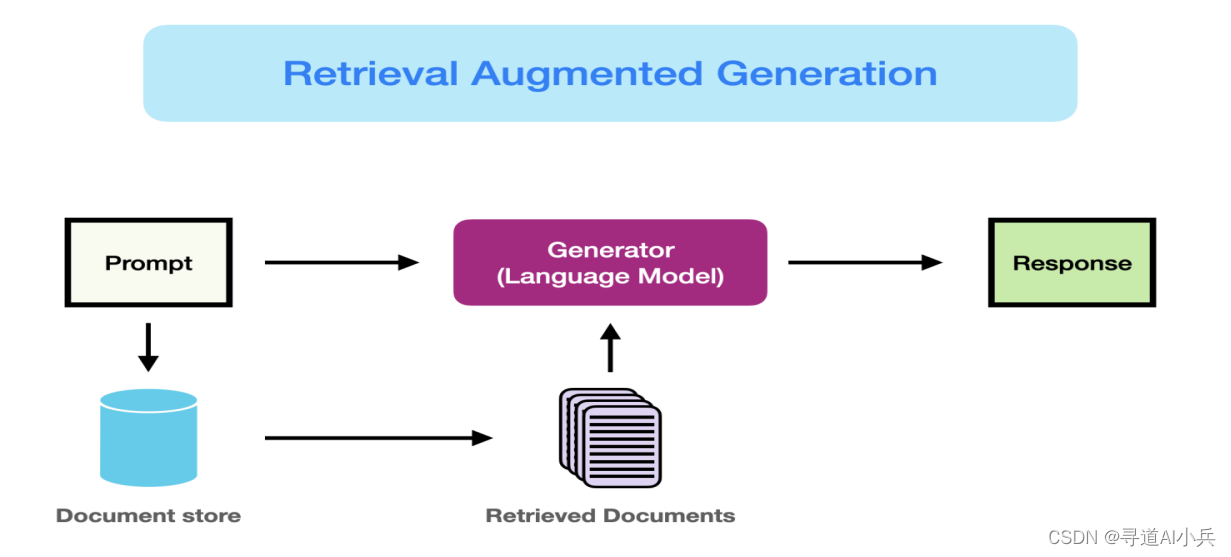
RAG技術是一種融合了檢索和生成的先進方法,它通過結合大語言模型(LLMs)的文本生成能力與外部知識庫的檢索功能,生成準確、豐富、時效性強的文本輸出。與傳統的預訓練語言模型相比,RAG能夠動態地引入最新的信息,突破了靜態知識庫的局限。
2.2 RAG技術的工作原理
RAG技術的核心在于其創新的工作流程,該流程包括以下幾個關鍵步驟:
- 輸入處理:接收并解析用戶的查詢或任務需求。
- 信息檢索:根據輸入內容,從知識庫中檢索相關文檔或數據。
- 上下文融合:將檢索到的信息與原始輸入結合,形成豐富的上下文。
- 文本生成:利用融合后的上下文,指導語言模型生成回答或內容。
2.3 RAG技術的優勢
RAG技術之所以在AI領域受到重視,主要得益于以下幾個方面的優勢:
- 動態知識更新:能夠實時引入最新信息,保持知識的時效性。
- 提高準確性:通過檢索補充信息,減少生成內容的誤差。
- 增強領域專業性:針對特定領域優化,提供深度的專業服務。
- 提升可擴展性:模塊化設計使其能夠靈活適應不同的應用需求。
2.4 RAG技術的應用場景
RAG技術的廣泛應用前景正在逐步展開,以下是一些典型的應用場景:
- 智能對話系統:提供更加人性化、信息豐富的交互體驗。
- 自動化內容創作:輔助生成新聞報道、博客文章等各類文本內容。
- 復雜問題解答:在專業領域內提供準確的問題解答服務。
- 企業信息分析:為企業決策提供基于最新數據的洞察和分析。
3. RAG的工作流程
RAG技術的高效性能源自其精細的工作流程設計。本章將詳細解析RAG技術的工作流程,包括輸入處理、索引建立、信息檢索、文檔生成等關鍵環節,以及這些環節是如何協同工作,共同實現RAG技術的強大功能的。
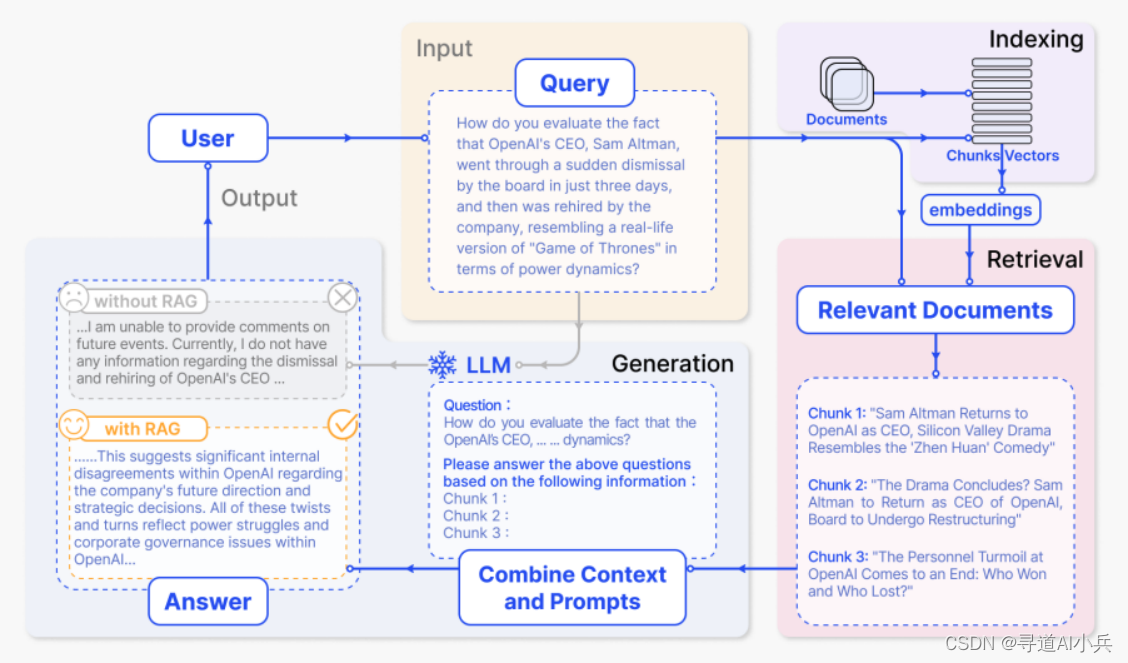
3.1 輸入處理
RAG工作流程的第一步是輸入處理,這一階段涉及到對用戶查詢的接收和解析。系統首先需要理解用戶的意圖和需求,這通常通過自然語言處理(NLP)技術來實現。輸入處理的目的是將用戶的自然語言查詢轉化為機器可理解的形式,為后續的檢索工作打下基礎。
3.2 索引建立
索引建立是RAG系統中的另一個關鍵步驟。在此階段,系統會創建一個索引,該索引包含了大量文檔或數據的嵌入向量。這些向量能夠捕捉文檔的關鍵特征,并使得系統能夠快速檢索到與用戶查詢相關的信息。索引的質量和效率直接影響到檢索結果的相關性。
3.3 信息檢索
信息檢索是RAG技術的核心環節之一。在這一階段,系統會根據輸入處理和索引建立階段得到的信息,檢索出與用戶查詢最相關的文檔或數據片段。檢索過程通常涉及到計算查詢與索引中各個文檔之間的相似度,并根據這些相似度對文檔進行排序。
3.4 文檔生成
一旦檢索到相關信息,RAG系統就會進入文檔生成階段。在這一階段,系統將使用檢索到的文檔和原始查詢作為輸入,指導語言模型生成回答或內容。這一過程需要確保生成的文本不僅準確反映了檢索到的信息,同時也符合用戶的原始意圖。
3.5 融合與優化
在文檔生成之后,RAG系統通常會進行融合與優化,以提高輸出文本的質量和相關性。這可能包括去除冗余信息、調整文本結構、增強邏輯連貫性等操作。融合與優化的目標是生成流暢、準確、易于理解的文本。
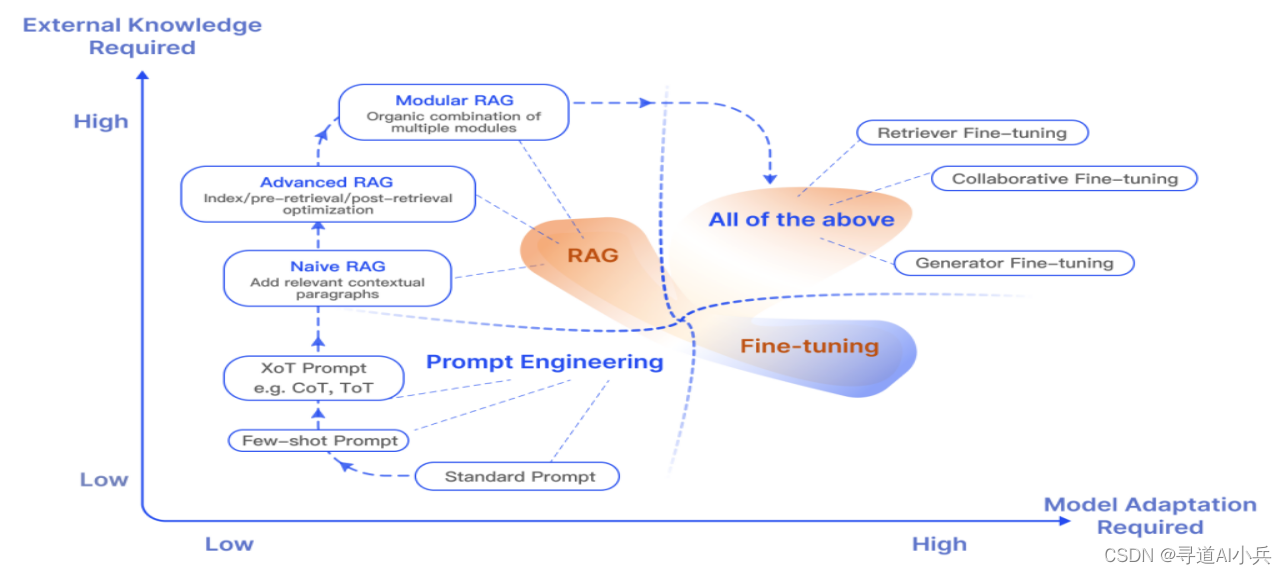
4. RAG范式的演變
RAG(Retrieval-Augmented Generation)模型隨著人工智能技術的發展而不斷演進,以滿足更廣泛的應用需求和解決更復雜的問題。以下是對RAG技術演進歷程的提煉和整理
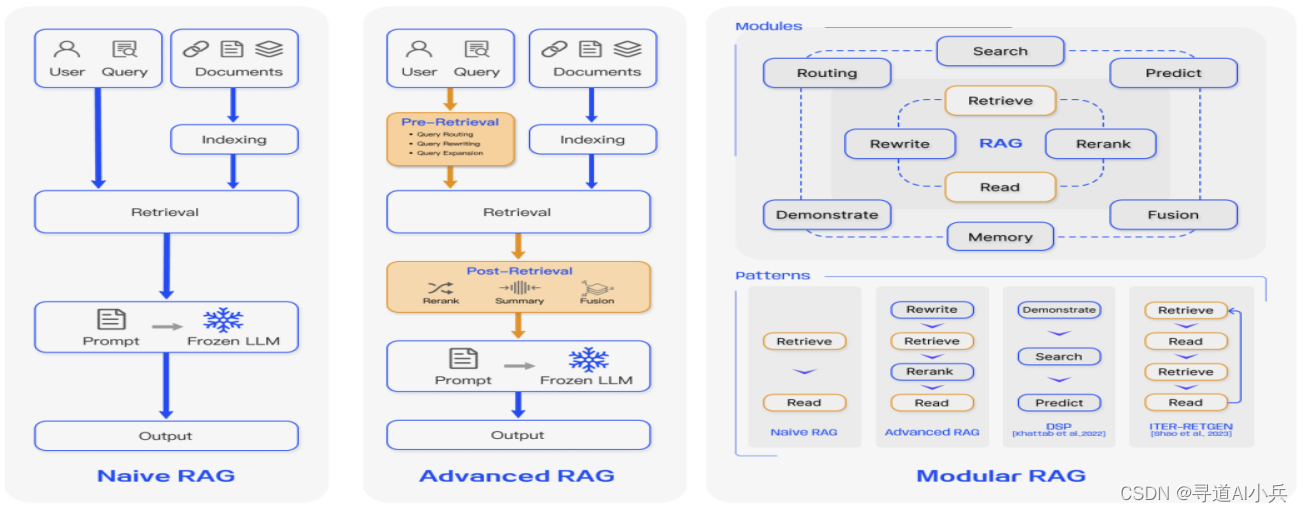
4.1 初級 RAG 模型
- 特點:采用傳統過程,包括索引建立、文檔檢索和內容生成。
- 局限:存在精確度和召回率低的問題,可能檢索到過時信息,導致準確性和可靠性下降。
- 挑戰:處理信息重復、冗余,以及生成內容的風格和語調一致性。
4.2 高級 RAG 模型
- 優化:在檢索前、檢索時和檢索后各個過程進行優化,提高檢索質量。
- 方法:通過優化索引結構、添加元數據、改進對齊方式和混合檢索方法提升數據質量。
- 技術:使用動態嵌入模型和微調技術,提高檢索的相關性,解決上下文窗口限制和減少噪音。
4.3 模塊化 RAG 模型
- 性能:通過增強功能模塊提升性能,如加入相似性檢索的搜索模塊。
- 靈活性:根據任務需求添加、替換或調整模塊,實現更高的多樣性和靈活性。
- 擴展:包括搜索、記憶、融合、路由、預測和任務適配等多種模塊。
優化技術
- 混合式搜索探索:結合關鍵詞搜索與語義搜索,檢索相關且富含上下文的信息。
- 遞歸式檢索與查詢引擎:逐步檢索更大的內容塊,平衡檢索效率與信息豐富度。
- StepBack-prompt 提示技術:引導模型進行更深入的推理過程。
- 子查詢策略:將大查詢任務拆分為小問題,利用不同數據源解答。
- 假設性文檔嵌入技術 (HyDE):優化檢索效果,通過假設性回答檢索相似文檔。
RAG技術的演進反映了其在適應性和功能性方面的持續進步,從初級模型到模塊化設計,RAG不斷優化以應對更復雜的應用場景和挑戰。
5. RAG系統的核心組成部分
RAG系統的高效運作依賴于其精心設計的核心組成部分。本章將深入探討檢索、生成和增強這三大環節,以及它們是如何協同工作來提升RAG系統的整體性能和應用靈活性。
5.1 檢索技術
在RAG系統中,檢索是關鍵環節,負責從大數據中找出最有價值的信息。我們可以通過多種方法提升檢索器的效能。
提升語義理解
- 數據分塊策略:選擇與數據內容和應用需求相匹配的數據分塊方式,考慮用戶問題長度和模型的詞元限制,以提高檢索效率。
- 嵌入模型微調:針對特定領域對嵌入模型進行微調,確保系統能準確理解用戶查詢,提高檢索的相關性。
查詢與文檔的精準匹配
- 查詢重寫:使用Query2Doc、ITER-RETGEN和HyDE等工具,通過技術手段改寫查詢,增強與文檔的匹配度。
- 查詢嵌入優化:調整查詢的嵌入表示,確保與任務相關的潛在空間對齊,提升查詢效果。
檢索器與大語言模型的協同優化
- 優化檢索技術:分析大語言模型(LLM)反饋,利用適應性增強檢索技術(AAR)、REPLUG和UPRISE等方法,進一步完善檢索系統。
- 引入輔助工具:加入PRCA、RECOMP和PKG等外部工具,輔助優化信息對齊過程,確保檢索結果與LLM預期一致。
通過這些策略,RAG系統的檢索器能夠更深入地理解查詢意圖,更準確地匹配相關文檔,從而與大語言模型實現更高效的協同工作。這些方法共同推動了RAG技術在處理大規模數據時的性能和應用范圍。
5.2 文本生成
在RAG系統中,文本生成環節負責將檢索到的信息轉化為流暢、連貫的文本輸出,是整個系統的關鍵組成部分。
檢索后處理與模型固定
- 目的:在不改變大語言模型(LLM)的前提下,通過后處理技術提升檢索結果的質量。
- 方法:
- 信息簡化:去除冗余,解決長文本處理限制,提高文本生成質量。
- 結果優先排序:優先展示最相關信息,增強檢索準確性。
針對RAG系統的LLM微調
- 目的:提升RAG系統效率,確保生成文本的自然流暢性,并有效融合檢索信息。
- 方法:對生成文本過程進行細致調整或微調,以適應RAG系統特定需求。
通過這些策略,RAG系統能夠優化文本生成過程,生成既準確又具有可讀性的輸出。這要求系統不僅要在檢索階段獲取相關信息,還要在生成階段對信息進行有效整合和表達。
5.3 增強技術
增強技術在RAG(檢索增強生成模型)中扮演著至關重要的角色,它涉及到將檢索到的信息高效地融合到任務生成過程中。
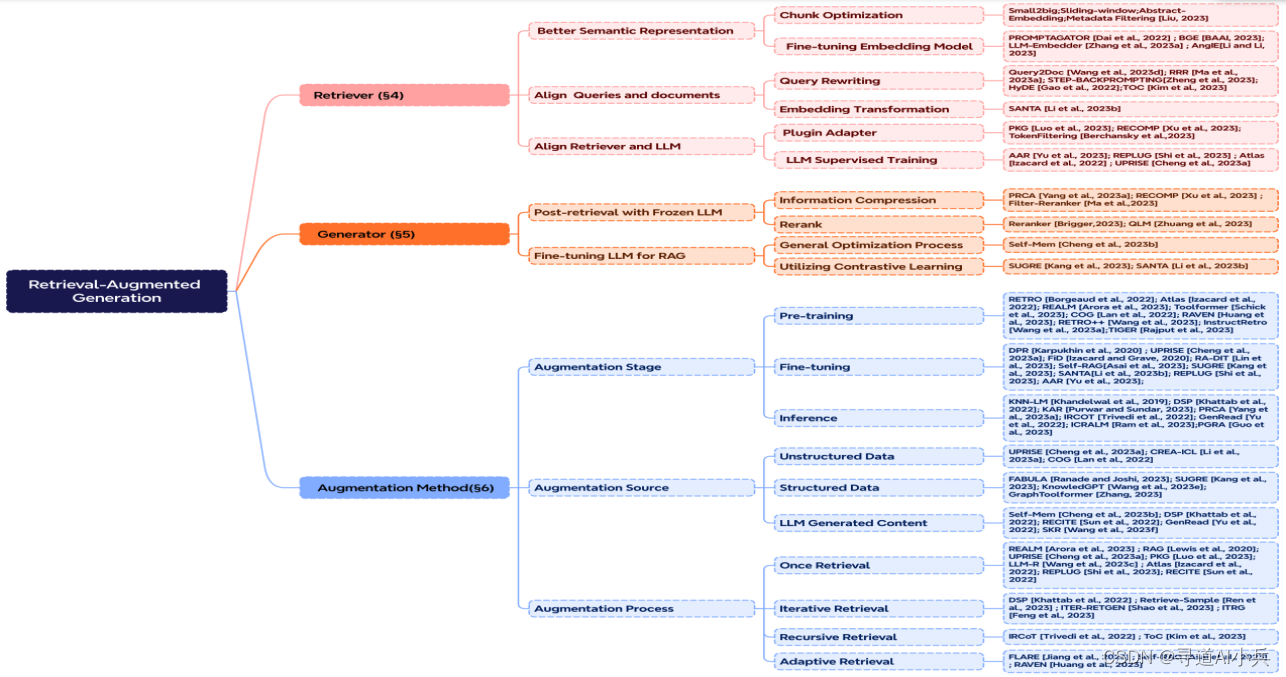
1、增強階段
- 預訓練:如RETRO示例,利用檢索增強進行大規模預訓練,引入基于外部知識的編碼器。
- 微調:結合RAG進行微調,進一步提升系統性能。
- 推理:根據任務需求,采用多種技術優化RAG應用效果。
2、增強數據源
- 分類:數據源分為非結構化數據、結構化數據和由大語言模型生成的數據,選擇對模型效果影響重大。
3、增強過程
- 迭代檢索:通過多輪檢索深化和豐富信息內容,適用于RETRO和GAR-meets-RAG等模型。
- 遞歸檢索:一次檢索輸出成為另一次檢索的輸入,逐步挖掘復雜查詢信息,適用于學術研究和法律分析,如IRCoT和Tree of Clarifications。
- 自適應檢索:根據需求調整檢索過程,選擇最佳時機和內容進行檢索,如FLARE和Self-RAG研究。
通過這些增強技術,RAG模型能夠更有效地利用檢索到的信息,提升生成任務的性能和準確性。這要求對數據源進行精心選擇,并在不同階段應用適當的檢索和融合策略。
5.4 RAG與微調的比較
RAG(檢索增強生成)與微調是兩種提升大語言模型性能的方法,各有特點和適用場景。以下是對RAG與微調的比較的精煉概述:
1、RAG的優勢
- 新知識融合:RAG特別適合整合新知識,通過檢索最新信息來增強模型的回答。
- 適用場景:適用于需要快速適應新知識、定制化反饋的任務。
2、微調的優勢
- 內部知識優化:通過微調,模型可以更好地適應特定任務,優化內部知識結構。
- 輸出格式和指令執行:提升模型的輸出格式適應性和復雜指令的執行能力。
3、相輔相成
- 結合使用:RAG和微調可以結合使用,共同提升模型在復雜知識密集型任務中的性能和效率。
4、提示工程(Prompting Engineering)
- 模型優勢發揮:通過精心設計的提示,發揮模型本身的優勢,優化輸出結果。
5、獨特特性
- 圖表展示:RAG與其他模型優化方法相比,具有獨特的特性,如更強的檢索能力和新知識整合能力。
RAG和微調各有所長,選擇使用哪種方法或兩者結合使用,取決于特定任務的需求和目標。通過合理利用這兩種技術,可以顯著提升大語言模型在多樣化任務中的表現。
6. RAG 模型評估解析
評估RAG(檢索增強生成)模型對于理解并提升其在不同應用場景下的性能至關重要。
6.1 評估重要性
- 評估幫助深入理解RAG模型性能,指導改進。
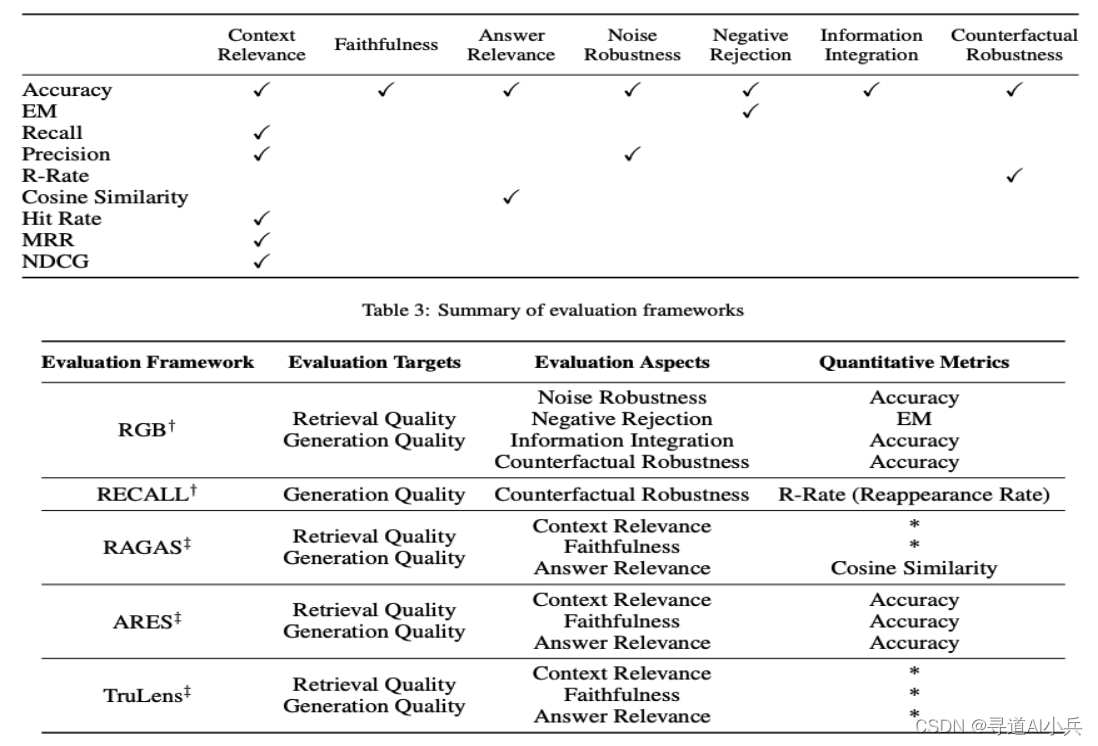
6.2 評估方法
- 使用特定任務的指標,如F1分數和準確率(EM)。
- 采用推薦系統和信息檢索領域的評估指標,例如NDCG和命中率。
6.3 評估內容
- 檢索內容質量:評估檢索到的信息的精確度和相關度。
- 生成文本質量:考量相關性、有害內容篩選和準確性。
6.4 評估維度
- 三個主要質量指標:
- 上下文相關性:檢索信息的準確性和相關性。
- 答案忠實度:答案對檢索到的上下文的忠實反映。
- 答案相關性:答案與提出問題之間的契合度。
- 四大能力:
- 對噪聲的魯棒性。
- 負面信息的排除。
- 信息整合能力。
- 面對假設情況的魯棒性。
6.5 評估工具
- 使用多個基準測試,如RGB和RECALL。
- 開發自動化評估工具,如RAGAS、ARES和TruLens。
6.6 評估實踐
- 評估可以手動或自動進行。
- 一些系統使用大語言模型確定質量指標。
RAG模型的評估是一個多維度、多方法的過程,涉及從檢索到生成的各個環節。通過這些評估實踐,可以全面理解模型性能,并為進一步優化提供依據。
7. RAG研究的挑戰與前景
RAG(檢索增強生成)技術的研究和發展面臨一系列挑戰,同時也展現出廣闊的應用前景。
7.1 關鍵挑戰
- 上下文長度問題:需調整RAG以有效捕獲相關和關鍵的上下文信息,應對大語言模型處理更廣上下文的需求。
- 系統魯棒性:提高RAG系統處理相反信息和對抗性信息的能力,確保性能穩定。
- 混合方法探索:研究者正探索如何將RAG與特定調整模型結合,以實現最優效果。
- 擴展LLM作用:提升大語言模型在RAG系統中的功能和能力。
- 規模化法則探究:解決大語言模型規模化法則在RAG系統中的應用問題。
- 生產級RAG挑戰:實現性能、效率、數據安全和隱私保護等方面工程上的卓越,以部署生產級RAG系統。
- 多模態RAG發展:探索RAG技術在圖像、音頻、視頻等非文本領域的應用。
7.2 前景與方向
- 評價機制完善:開發細致評估上下文相關性、創新性、內容多樣性、準確性的工具,提高RAG的解釋性研究和工具開發。
7.3 未來工作
- 增強檢索、補充和生成過程:通過不同方法持續增強RAG系統的性能。
- 擴展應用領域:將RAG技術應用于更廣泛的任務和領域。
RAG研究的挑戰與前景表明,盡管存在諸多難題,但通過不斷的技術創新和研究探索,RAG技術有望實現更廣泛的應用,并推動人工智能領域的發展。
8. 結語
本文深入探討了檢索增強生成(RAG)技術,這一技術通過整合實時數據和外部知識庫,顯著提升了人工智能在知識檢索和文本生成方面的能力。RAG技術以其動態知識更新和準確性,在AI領域中展現出巨大潛力。
隨著專用工具和服務的推出,如LangChain、LlamaIndex等,RAG系統的構建和應用變得更加便捷。這些工具不僅推動了RAG技術的普及,也為研究人員和開發者提供了豐富的資源。

🎯🔖更多專欄系列文章:AI大模型RAG應用探索實踐
😎 作者介紹:我是尋道AI小兵,資深程序老猿,從業10年+、互聯網系統架構師,目前專注于AIGC的探索。
📖 技術交流:建立有技術交流群,可以掃碼👇 加入社群,500本各類編程書籍、AI教程、AI工具等你領取!
如果文章內容對您有所觸動,別忘了點贊、?關注,收藏!加入我,讓我們攜手同行AI的探索之旅,一起開啟智能時代的大門!


)
















)