??前言:本博客僅作記錄學習使用,部分圖片出自網絡,如有侵犯您的權益,請聯系刪除?

目錄
一、數據庫的分類
1.1、SQL
1.2、NoSQL
1.3、如何選擇?
二、ORM魔法
三、使用Flask-SQLALchemy管理數據庫
3.1、連接數據庫服務器
3.2、定義數據庫模型
3.3、創建數據庫和表
四、數據庫操作
4.1、CRUD
4.2、在視圖函數里操作數據庫
五、定義關系
5.1、配置Python Shell上下文
5.2、一對多
5.3、多對一
5.4、一對一
5.5、多對多
六、更新數據庫表
6.1、重新生成表
6.2、使用Flask-Migrate遷移數據庫
6.3、開發時是否要遷移?
七、數據庫進階實踐
7.1、級聯操作
7.2、事件監聽
致謝
數據庫是大多數動態Web程序的基礎設施。常見的數據庫管理系統(DBMS)有:MySQL、PostgreSQL、SQLite、MongoDB等。
一、數據庫的分類
數據庫一般分為兩種,SQL(Structured Query Language,結構化查詢語言)數據庫和NoSQL(Not Only SQL,泛指非關系型)數據庫
1.1、SQL
SQL數據庫指關系型數據庫,常用的SQL DBMS主要包括SQL Server、Oracle、MySQL、PostgreSQL、SQLite等。關系型數據庫使用表來定義數據對象,不同的表之間使用關系連接。
| id | name | sex | occupation |
|---|---|---|---|
| 1 | Nick | Male | Journalist |
| 2 | Amy | Female | Writer |
在SQL數據庫中,每一行代表一條記錄(record),每條記錄又由不同的列(column)組成。在存儲數據前,需要預先定義表模式(schema),以定義表的結構并限定列的輸入數據類型。
基本概念:
- 表(table):存儲數據的特定結構
- 模式(schema):定義表的結構信息
- 列/字段(column/field):表中的列,存儲一系列特定的數據,列組成表
- 行/記錄(raw/record):表中的行,代表一條記錄
-
標量(scalar):指的是單一數據,與之相對的是集合(collection)
1.2、NoSQL
NoSQL是初指No SQL或No Relational,現在NoSQL社區一般會解釋為Not Only SQL。NoSQL數據庫泛指不使用傳統關系型數據庫中的表格形式的數據庫。近年來,NoSQL數據庫越來越流行,被大量應用在實時Web程序和大型程序中。在速度和可擴展性方面有很大優勢,除此之外還擁有無模式、分布式、水平伸縮等特點
最常用的兩種NoSQL數據庫如下:
1.2.1、文檔存儲(document store)
文檔存儲是NoSQL數據庫中最流行的種類,它可作為主數據庫使用。文檔存儲使用的文檔類似SQL數據庫中的記錄,文檔使用類JSON格式來表示數據。常見的文檔存儲DBMS有MongoDB、CouchDB等。1.1的身份信息表中的第一條記錄使用文檔可表示為:
?{id: 1,name: "Nick",sex: "Male",occupation: "Journalist"}1.2.2、鍵值對存儲(key-value store)
鍵值對存儲在形態上類似Python中的字典,通過鍵來存取數據,在讀取上非常快,通常用來存儲臨時內容,作為緩存使用。常見的鍵值對DBMS有Redis、Riak等,其中Redis不僅可以管理鍵值對數據庫,還可以作為緩存后端(cache backed)、圖存儲(graph store)等類型的NoSQL數據庫。
1.3、如何選擇?
- NoSQL 數據庫不需要定義表和列等結構,也不限定存儲的數據格式,在存儲方式上比較靈活,在特定的場景下效率更高。
- SQL 數據庫稍顯復雜,但不容易出錯, 能夠適應大部分的應用場景
- 大型項目通常會同時需要多種數據庫,比如使用MySQL作為主數據庫存儲用戶資料和文章,使用Redis緩存數據,使用MongoDB存儲實時消息。
大多情況,SQL數據庫都能滿足你的需求。為便于測試,我們使用SQLite作為DBMS。
二、ORM魔法
在Web應用程序里使用原生SQL語句操作數據庫主要存在以下問題:
- 手動編寫SQL語句比較乏味,而且視圖函數中加入太多SQL語句會降低代碼的易讀性。另外還會有安全問題,如SQL語句注入
- 常見的開發模式是在開發時使用簡單的SQLite,而在部署時切換到MySQL等更健壯的DBMS。但是對于不同DBMS需要使用不同的Python接口庫,這讓DBMS的切換變得不太容易。
ORM會自動處理參數的轉義,盡可能地避免SQL注入的發生。另外還為不同的DBMS提供統一的接口,讓切換工作變得簡單。ORM扮演翻譯的角色,將我們的Python語言轉換為DBMS能夠讀懂的SQL指令,讓我們能夠使用Python來操控數據庫。
ORM把底層的SQL數據庫實體轉化成高層的Python對象。ORM主要實現了三層映射關系:
- 表--Python類
- 字段(列)--類屬性
- 記錄(行)--類實例
比如,創建一個contacts表來存儲留言,其中包含用戶名稱和電話號碼兩個字段。在SQL中:
?CREATE TABLE contacts(name varchar(100) NOT NULL,phone_number varchar(32),)如果使用ORM:
?from foo_orm import Model, Column, String?class Contact(Model):__tablename__ = 'contacts'name = Column(String(100),nullable=False)phone_number = Column(String(32))要向表中插入一條記錄,需要使用下面的SQL語句:
?INSERT INTO contacts(name,phone_number)VALUES('Grey Li','12345678')使用ORM則只需要創建一個Contact類的實例,傳入對應的參數表示各個列的數據即可。
?contact = Contact(name="Grey Li",phone_number="12345678")除了便于使用,ORM還有下面這些優點:
- 靈活性好。既能使用高層對象來操作數據庫,又支持執行原生SQL語句。
- 提升效率。從高層對象轉換成原生SQL會犧牲一些性能,但這換取的是巨大的效率提升
- 可移植性好。ORM通常支持多種DBMS,只需要稍微改動少量配置
使用Python實現的ORM有SQLALchemy、Peewee、PonyORM等。其中SQLALchemy是Python社區使用最廣泛的ORM之一
三、使用Flask-SQLALchemy管理數據庫
擴展Flask-SQLALchemy集成了SQLALchemy,它簡化了連接數據庫服務器、管理數據庫操作會話等各類工作,讓Flask中的數據處理體驗變得更加輕松。
?pip install flask-sqlalchemy實例化Flask-SQLALchemy提供的SQLALchemy類,傳入 程序實例app以完成擴展的初始化:
?from flask import Flaskfrom flask_sqlalchemy import SQLAlchemy?app = Flask(__name__)?db = SQLAlchemy(app)3.1、連接數據庫服務器
DBMS通常會提供數據庫服務器運行在操作系統中。要連接數據庫服務器,首先要為我們的程序指定數據庫URI(Uniform Resource Identifier,統一資源標識符)。數據庫URI是一串包含各種屬性的字符串,其中包含了各種用于連接數據庫的信息。
常用的數據庫URI格式示例:
| DBMS | URI |
|---|---|
| PostgreSQL | postgresql://username:password@host/databasename |
| MySQL | mysql://username:password@host/databasename |
| Oracle | oracle://username:password@host:port/sidname |
| SQLite(UNIX) | sqlite:absolute/path/to/foo.db |
| SQLite(Windows) | sqlite:///absolute\\path\\to\\foo.db或r'sqlite:///absolute\path\to\foo.db' |
| SQLite(內存型) | sqlite:///或sqlite:///:memory: |
在Flask-SQLALchemy中,數據庫的URI通過配置變量SQLALCHEMY_DATABASE_URI設置,默認為SQLite內存型數據庫(sqlite:///:memory:),SQLite是基于文件的DBMS,不需要設置數據庫服務器,只需要指定數據庫文件的絕對路徑。我們使用app.root_path來定位數據庫文件的路徑,并將數據庫文件命名為data.db:
?import os?app.config['SQLALCHEMY_DATABASE_URI'] = os.getenv('DATABASE_URL','sqlite:///'+os.path.join(app.root_path,'data.db'))在生產環境下更換到其他類型的DBMS時,數據庫URL會包含敏感信息,所有這里優先從環境變量DATABSE_URL獲取。
SQLite的數據庫URI在Linux或macOS系統下的斜線數量是4個;在Windows系統下的URI中的斜線數量為3個。內存型數據庫的斜線固定為3個。文件名不限后綴,常用的命名方式有foo.sqlite,foo.db或是注明版本的foo.sqlite3
設置好數據庫URI后,在Python Shell中導入并查看db對象會得到下面的輸出
>>> from app import db
>>> db
<SQLAlchemy>3.2、定義數據庫模型
用來映射到數據庫表的Python類通常被稱為數據庫模型(model),一個數據庫模型類對應數據庫中的一個表。定義模型即使用Python類定義表模式,并聲明映射關系。所有模型類都需要繼承Flask-SQLALchemy提供的db.Model基類。下面定義一個Note模型類,用來存儲筆記:
class Note(db.Model):id = db.Column(db.Integer,primary_key=True)body = db.Column(db.Text)表的字段(列)由db.Column類的實例表示,字段的類型通過Column類構造方法的第一個參數傳入。常用的SQLALchemy字段類型:
| 字段 | 說明 |
|---|---|
| Integer | 參數 |
| String | 字符串,可選參數length可以用來設置最大長度 |
| Text | 較長的Unicode文本 |
| Date | 日期,存儲Python的datetime.date對象 |
| Time | 時間,存儲Python的datetime.time對象 |
| DateTime | 時間和日期,存儲Python的datetime對象 |
| Interval | 時間間隔,存儲Python的datetime.timedelta對象 |
| Float | 浮點數 |
| Boolen | 布爾值 |
| PickleType | 存儲Pickle列化的Python對象 |
| LargeBinary | 存儲任意二進制數據 |
字段類型一般直接聲明即可,如果需要傳入參數,也可以添加括號。對于類似String的字符串列,有些數據庫會要求限定長度,因此最好為其指定長度。雖然使用Text類型可以存儲相對靈活的變長文本,但從性能上考慮,我們僅在必須的情況下使用Text類型,比如用戶發表的文章和評論等不限長度的內容。
一般情況字段的長度是由程序設計者自定的。但也有特殊約束:比如姓名(英語)的長度一般不超過70個字符,中文名一般不超過20個字符,電子郵件地址的長度不超過254個字符。(當在數據庫模型類中限制了字段的長度后,在接收對應數據的表單類字段里,也需要使用Length驗證器來驗證用戶的輸入數據)。
默認情況下,Flask-SQLALchemy會限制模型類的名稱生成一個表名稱,生成規則如下:
Message --> message # 單個單詞轉換為小寫
FooBar --> foo_bar # 多個單詞轉換為小寫并使用下劃線分隔Note類對應的表名稱即note。若想自己指定名稱,可以通過定義tablename屬性來實現。字段名默認為類屬性名,也可以通過字段類構造方法的第一個參數指定,或使用關鍵字name。根據我們定義的Note模型類,最終生成一個note表,表中包含id和body字段,
常用的SQLALchemy字段參數:
| 參數名 | 說明 |
|---|---|
| primary_key | 如果設為True,該字段為主鍵 |
| unique | 如果設為True,該字段不允許出現重復值 |
| index | 如果設為True,為該字段創建索引,以提高查詢效率 |
| nullable | 確定字段值可否為空,值為True或False,默認值為True |
| default | 為字段設置默認值 |
(不需要在所有列都建立索引。一般來說,取值可能性多(比如姓名)的列,以及經常被用來作為排序參照的列(比如時間戳)更適合建立索引。)
3.3、創建數據庫和表
創建模型類后,我們需要手動創建數據庫和對應的表,也就是我們常說的建庫和建表。這通過我們的db對象調用create_all()方法實現。
$ flask shell
>>> from app import db
>>> db.create_all()如果將模型類定義在單獨的模塊中,那么必須在調用db.create_all()方法前導入相應模塊,以便讓SQLALchemy獲取模型類被創建時生成的表信息,進而正確生成數據表。
通過下面的方式可以查看模型對應的SQL模式(建表語句):
>>> from sqlalchemy.schema import CreateTable
>>> print(CreateTable(Note.__table__))CREATE TABLE note (id INTEGER NOT NULL,body TEXT,PRIMARY KEY (id)
)(我們數據庫和表一旦創建后,之后對模型的改動不會自動作用到實際的表中。如要使改動生效,調用db.drop_all()方法刪除數據庫和表,然后再調用create_all()方法創建)。
我們也可以自定義flask命令完成這個工作:
import click@app.cli.command()
def initdb():db.create_all()click.echo('Initialized database')在命令行輸入flask initdb即可創建數據庫和表:
$ flask initdb
Initialized database.四、數據庫操作
數據庫操作主要是CRUD,即Create(創建)、Read(讀取/查詢)、Update(更新)和Delete(刪除)。
SQLALchemy使用數據庫會話來管理數據庫操作,這里的數據庫會話也稱事務(transaction)。Flask-SQLALchemy自動幫我們創建會話,可以通過db.session屬性獲取
數據庫中的會話代表一個臨時緩存區,對數據庫做出的任何改動都會存放在這里。可以調用add()方法將新創建的對象添加到數據庫會話中,或是對會話中的對象進行更新。只有當你對數據庫會話對象調用commit()方法時,改動才會被提交到數據庫,這確保了數據提交的一致性。另外數據庫會話也支持回滾操作。當你對會話調用rollback()方法時,添加到會話中且未提交的改動都將被撤銷。
4.1、CRUD
默認情況下,Flask-SQLALchemy會自動為模型生成一個__repr()方法。當在Python shell中調用模型的對象時,__reper()方法會返回一條類似“<模型類名 主鍵值>”的字符串,比如<Note2>。為了便于操作,本示例重新定義__repr__()方法,返回一些更有用的信息。
class Note(db.Model):...def __repr__(self):return '<Note %r>' % self.body4.1.1、Create
添加一條新記錄到數據庫主要分為三步:
- 創建Python對象(實例化模型類)作為一條記錄。
- 添加新創建的記錄到數據庫會話
- 提交數據庫會話
# 下面示例向數據庫中添加了三條留言
>>> from app import db,Note
>>> note1 = Note(body='remember Sammy Jankis')
>>> note2 = Note(body='SHAVE')
>>> note3 = Note(body='DON NOT BELIEVE HIS LIES, HE IS THE ONE, KILL HIM')
>>> db.session.add(note1)
>>> db.session.add(note2)
>>> db.session.add(note3)
>>> db.session.commit()除了依次調用add()方法添加多個記錄,也可以使用add_all()方法一次添加包含所有記錄對象的列表。
我們在創建模型類的時候并沒有定義id字段的數據,這是因為主鍵由SQLALchemy管理。模型類對象創建后作為臨時對象(transient),當你提交數據庫會話后,模型類對象才會轉換為數據庫記錄寫入數據庫中,這時模型類對象會自動獲得id值。
4.1.2、Read
使用模型類提供的query屬性附加調用各種過濾方法及查詢方法即可從數據庫中取出數據
一般來說,一個完整的查詢遵循下面的模式:
<模型類>.query.<過濾方法>.<查詢方法>從某個模型出發,通過在query屬性對應的Query對象上附加的過濾方法和查詢函數對模型類對應的表中的記錄進行各種篩選和調整,最終返回包含對應數據庫記錄數據的模型類實例,對返回的實例調用屬性即可獲得對應的字段數據。
SQLALchemy提供了許多查詢方法用來獲取記錄:
| 查詢方法 | 說明 |
|---|---|
| all() | 返回包含所有查詢記錄的列表 |
| first() | 返回查詢的第一條記錄,如果未找到,則返回None |
| one() | 返回第一條記錄,且僅允許有一條記錄。如果記錄數量大于1或小于1,則拋出錯誤 |
| get(ident) | 傳入主鍵值作為參數,返回指定主鍵值的記錄,如果未找到,則返回None |
| count() | 返回查詢結果的數量 |
| one_or_none() | 類似one(),如果結果數量不為1,返回None |
| first_or_404() | 返回查詢的第一條記錄,如果未找到,則返回404錯誤響應 |
| get_or_404(ident) | 傳入主鍵值作為參數,返回指定主鍵值記錄,如果未找到,則返回404錯誤響應 |
| paginate() | 返回一個Pagination對象,可以對記錄進行分頁處理 |
| with_parent(instance) | 傳入模型實例作為參數,返回和這個實例相關聯的對象,后面會詳細介紹 |
示例:all()返回所有記錄:
>>> Note.query.all()
[<Note 'remember Sammy Jankis'>, <Note 'SHAVE'>, <Note 'DON NOT BELIEVE HIS LIES, HE IS THE ONE, KILL HIM'>]first()返回第一條記錄:
>>> note1 = Note.query.first()
>>> note1
<Note 'remember Sammy Jankis'>
>>> note1.body
'remember Sammy Jankis'get()返回指定主鍵值(id字段)的記錄:
>>> note2 = Note.query.get(2)
>>> note2
<Note 'SHAVE'>count()返回記錄的數量:
>>> Note.query.count()
3SQLALchemy還提供許多過濾方法,使用這些過濾方法可以獲取更精確的查詢,比如獲取指定字段值的記錄。對模型類的query屬性存儲的Query對象調用過濾方法將返回一個更精確的Query對象(后面簡稱為查詢對象)。因為每個過濾方法都會返回新的查詢對象,所以過濾器可以疊加使用。
在查詢對象上調用前面介紹的查詢方法,即可獲得一個包含過濾后的記錄的列表。常用的過濾方法有:
| 查詢過濾器的名稱 | 說明 |
|---|---|
| filter() | 使用指定的規則過濾記錄,返回新產生的查詢對象 |
| filter_by() | 使用指定的規則過濾記錄(以關鍵字表達式的形式),返回新產生的查詢對象 |
| order_by() | 根據指定條件對記錄進行排序,返回新產生的查詢對象 |
| limit(limit) | 使用指定的值限制原查詢返回的記錄數量,返回新產生的查詢對象 |
| group_by() | 根據指定條件對記錄進行分組,返回新產生的查詢對象 |
| offset(offset) | 使用指定的值偏移原查詢的結果,返回新產生的查詢對象 |
filter()方法是最基礎的查詢方法。它使用指定的規則來過濾記錄,示例:在數據庫中找出body字段值為"SHAVE"的記錄:
>>> Note.query.filter(Note.body=='SHAVE').first()
<Note 'SHAVE'>直接打印查詢對象或將其轉換為字符串可查看對應的SQL語句:
>>> print(Note.query.filter_by(body='SHAVE'))
SELECT note.id AS note_id, note.body AS note_body
FROM note
WHERE note.body = ?在filter()方法中傳入表達式時,除了"=="以及表示不等于的"!=",其他常用的查詢操作符以及使用示例如下:
LIKE:
filter(Note.body.like('%foo%'))
IN:
filter(Note.body.in_(['foo','bar','baz']))
NOT IN:
filter(~Note.body.in_(['foo','bar','baz']))
AND:
# 使用and_()
from sqlalchemy import and
filter(and_(Note.body == 'foo',Note.title == 'FooBar'))# 或在filter()中加入多個表達式,使用逗號隔開
filter(Note.body == 'foo',Note.title == 'FooBar')# 或疊加調用多個filter()/filter_by()方法
filter(Note.body == 'foo').filter(Note.title == 'FooBar')OR:
from sqlalchemy import or_
filter(or_(Note.body == 'foo',Note.body == 'bar'))和filter方法相比,filter_by()方法更易于使用。在filter_by()方法中,可以使用關鍵字表達式來指定過濾規則。更方便的是,可以在這個過濾器 中直接使用字段名字。
>>> Note.query.filter_by(body='SHAVE').first()
<Note 'SHAVE'>其他方法,后續使用時介紹。
4.1.3、Update
更新一條記錄非常簡單,直接賦值給模型類的字段屬性就可以改變字段值,然后調用commit()方法提交給會話即可。示例:改變一條記錄的body字段的值:
>>> note = Note.query.get(2)
>>> note.body
'SHAVE'
>>> note.body = 'SHAVE LEFT THING'
>>> db.session.commit()4.1.4、Delete
刪除記錄和添加記錄很相似,不過要把add()方法換成delete()方法,最后都需要調用commit()方法提交修改。示例:刪除id(主鍵)為2的記錄:
>>> note = Note.query.get(2)
>>> db.session.delete(note)
>>> db.session.commit()4.2、在視圖函數里操作數據庫
在視圖函數里操作數據庫的方式和我們在Python Shell中練習的大致相同,只不過需要一些額外的工作。比如把查詢結果作為參數傳入模板渲染出來,或是獲取表單的字段值作為提交到數據庫的數據。
4.2.1、Create
為了支持輸入筆記內容,我們先創建一個用于填寫新筆記的表單:
from wtforms import TextAreaField
from flask_wtf import FlaskForm
from wtforms.validators import DataRequiredclass NewNoteForm(FlaskForm):body = TextAreaField('Body',validators=[DataRequired()])submit = SubmitField('Save')我們創建一個new_note視圖,這個視圖負責渲染創建筆記的模板,并處理表單的提交:
@app.route('/new',methods=['GET','POST'])
def new_note():form = NewNoteForm()if form.validate_on_submit():body = form.body.datanote = Note(body=body)db.session.add(note)db.session.commit()flash('Your note is saved.')return redirect(url_for('index'))return render_template('new_note.html',form=form)邏輯:當form.validate_on_submit()返回True時,即表單被提交且驗證通過時,獲取表單body字段的數據,然后創建新的Note實例,將表單中body字段的值作為body參數傳入,最后添加到數據庫會話中并提交會話。這個過程接收用戶通過表單提交的數據并保存到數據庫中,最后我們使用flash()函數發送提示消息并重定向到index視圖。
表單在new_note.html模板中渲染,這里使用前面介紹的form_filed宏渲染表單字段,傳入rows和cols參數來定制<textarea>輸入框的大小:
{% from 'macro.html' import form_field %}
{% block content %}
<h2>New Note</h2><form method="post">{{ form.csrf_token }}{{ form_field(form.body,rows=5,cols=50) }}{{ form.submit }}</form>
{% endblock %}index視圖用來顯示主頁,目前它的所有作用就是渲染主頁對應的模板:
@app.route('/')
def index():return render_template('index.html')在對應的index.html模板中,我們添加一個指向創建新筆記頁面的鏈接:
<h1>Notebook</h1><a href="{{ url_for('new_note') }}">New Note</a>4.2.2、Read
上面為程序添加了新筆記的功能,當在創建筆記的頁面單擊保存后,程序會重定向到主頁,提示的消息告訴你剛剛提交的筆記已經成功保存,可卻無法看到保存后的筆記。為了在主頁列出所有保存的筆記,我們需要修改index視圖:
@app.route('/index')
def index():form = DeleteForm()notes = Note.query.all()return render_template('index.html',notes=notes,form=form)在模板中渲染數據庫記錄:
<h1>Notebook</h1><a href="{{ url_for('new_note') }}">New Note</a><h4>{{ notes|length }} notes:</h4>{% for note in notes %}<div class="note"><p>{{ note.body }}</p></div>{% endfor %}在模板中,我們迭代這個notes列表,調用Note對象的body屬性獲取body字段的值。另外,我們還通過length過濾器獲取筆記的數量。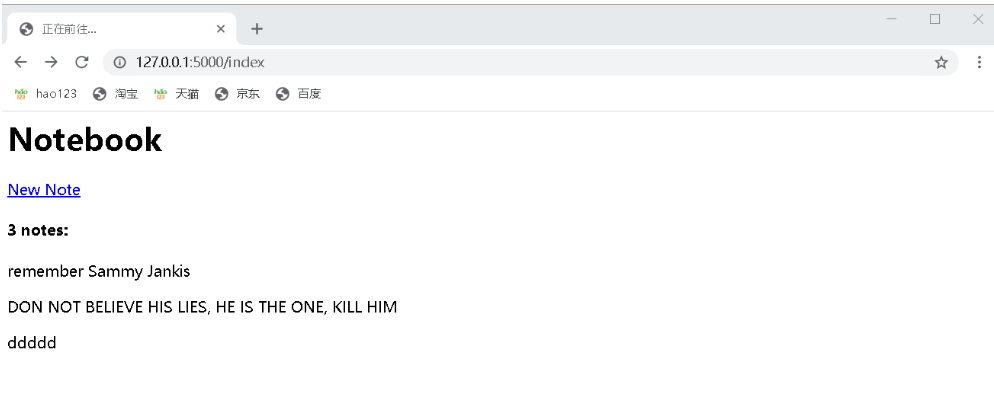
4.2.3、Update
更新一條筆記和創建一條新筆記的實現代碼幾乎完全相同,首先是編輯筆記的表單:
class EditNoteForm(FlaskForm):body = TextAreaField('Body',validators=[DataRequired()])submit = SubmitField('Update')發現這和創建新筆記NewNoteForm唯一的不同是提交字段的標簽參數不同,因此這個表單的定義也可以通過繼承來簡化:
class EditNoteForm(NewNoteForm):submit = SubmitField('Update')用來渲染更新筆記頁面和處理更新表單提交的edit_note視圖:
@app.route('/edit/<int:note_id>',methods=['GET','POST'])
def edit_note(note_id):form = EditNoteForm()note = Note.query.get(note_id)if form.validate_on_submit():note.body = form.body.datadb.session.commit()flash('Your note is update.')return redirect(url_for('index'))form.body.data = note.bodyreturn render_template('edit_note.html',form=form)邏輯:通過URL變量note_id獲取要修改的筆記的主鍵值(id字段),然后我們就可以使用get()方法獲取對應的Note實例。當表單被提交且通過驗證時,我們將表單中body字段的值賦值給note對象的body屬性,然后提交數據庫會話,這樣就完成了更新操作。最后重定向。
注意,在GET請求的執行流程中,我們添加了這行代碼:
form.body.data = note.body因為要添加筆記內容的功能,那么當我們打開修改某個筆記的頁面時,這個頁面的表單中必然要包含筆記原有的內容。
如果手動創建HTML表單,那么可以通過將note記錄傳入模板,然后手動為對應字段填入筆記的原有內容:
<textarea name="body">{{ note.body }}</textarea>其他input元素則通過value屬性來設置輸入框中的值:
<input name="foo" type="text" value="{{ note.title }}">使用WTForms可以省略這些步驟,當我們渲染表單字段時,如果表單字段的data屬性不為空,WTForms會自動把data屬性的值添加到表單字段的value屬性中,作為表單的值填充進去,我們不用手動為value屬性賦值。
模板的內容基本相同,最后的工作是在主頁筆記列表中的每個筆記內容下添加一個編輯按鈕,用來訪問編輯頁面:
{% for note in notes %}<div class="note"><p>{{ note.body }}</p><a class="btn" href="{{ url_for('edit_note',note_id=note.id) }}">Edit</a></div>{% endfor %}4.2.4、Delete
在程序中,刪除的實現也非常簡單,不過這里會有一個誤區。大多數人通常會考慮在筆記內容下添加一個刪除鏈接:
<a href="{{ url_for('delete_note',note_id=note.id) }}">Delete</a>這個鏈接用來指向刪除筆記的detele_note視圖:
@app.route('/delete/<int:note_id>')
def delete_note(note_id):note = Note.query.get(note_id)db.session.delete(note)db.session.commit()flash('Your note is deleted.')return redirect(url_for('index'))雖然這看起來很合理,但這種處理方式會使程序處于CSRF攻擊的風險之中。在前面強調過,防范CSRF攻擊的基本原則是正確使用GET和POST方法。像刪除這類修改數據的操作絕不能通過GET請求實現,正確的做法是為刪除操作創建一個表單:
class DeleteNoteForm(FlaskForm):submit = SubmitField('Delete')這個表單類只有一個提交字段,因為我們只需要在頁面上顯示一個刪除按鈕來提交表單:
@app.route('/delete/<int:note_id>',methods=['POST'])
def delete_note(note_id):form = DeleteNoteForm()if form.validate_on_submit():note = Note.query.get(note_id) # 獲取對應記錄db.session.delete(note) # 刪除記錄db.session.commit() # 提交修改flash('Your note is deleted.')else:abort(400)return redirect(url_for('index'))邏輯:和編輯筆記的視圖類似,這個視圖函數接收note_id(主鍵值)作為參數。如果提交表單且通過驗證(唯一需要被驗證的是CSRF令牌),就使用get()方法查詢對應的記錄,然后調用db.session.delete()方法刪除并提交數據庫會話。如驗證錯誤則使用abort()函數返回400錯誤響應。
因為刪除按鈕要在主頁的筆記內容下添加,我們需要在index視圖中實例化DeleteNoteForm類,然后傳入模板。在index.html中:
{% for note in notes %}<div class="note"><p>{{ note.body }}</p><a class="btn" href="{{ url_for('edit_note',note_id=note.id) }}">Edit</a><form method="post" action="{{ url_for('delete_note',note_id=note.id) }}">{{ form.csrf_token }}{{ form.submit(class='btn') }}</form></div>{% endfor %}我們將表單的action屬性設置為刪除筆記的URL,URL變量note_id的值通過note.id屬性獲取,當單擊提交按鈕時,會將請求發送到action屬性中的URL。添加刪除表單的主要目的就是防止CSRF攻擊,所以不要忘記渲染CSRF令牌字段form.csrf_token。
五、定義關系
在關系型數據庫中,我們可以通過關系讓不同表之間的字段建立聯系。一般來說,定義關系需要兩步:創建外鍵和定義關系屬性。在更復雜的多對多關系中,我們還需要定義關聯表來管理關系。
5.1、配置Python Shell上下文
在上面許多操作中,每一次使用flask shell命令啟動Python Shell后都要從app模塊里導入db對象和相應的模型類。我們可以使用app.shell_context_processor裝飾器注冊一個shell上下文處理函數。和模板上下文處理函數一樣,也需要返回包含變量和變量值的字典:
@app.shell_context_processor
def make_shell_context():return dict(db=db,Note=Note) # 等同于('db':db,'Note':Note)當使用flask shell啟動Python Shell時,所有使用app.shell_context_processor裝飾器注冊的shell上下文處理函數都會被自動執行,這將db和Note對象推送到Python Shell上下文里:
$ flask shell
>>> db
<SQLAlchemy sqlite:///D:\Python Web\Pycharm-project\flask\data.db>
>>> Note
<class 'app.Note'>5.2、一對多
以作者和文章的關系來演示一對多關系:一個作者可以寫作多篇文章。
...
class Author(db.Model):id = db.Column(db.Integer,primary_key=True)name = db.Column(db.String(70),unique=True)phone = db.Column(db.String(20))class Article(db.Model):id = db.Column(db.Integer,primary_key=True)title = db.Column(db.String(50),index=True)body = db.Column(db.Text)我們將在這兩個模型中建立一個簡單的一對多關系,建立這個一對多關系的目的是在表示作者的Author類中添加一個關系屬性articles,作為集合(collection)屬性,當我們對特定的Author對象調用articles屬性會返回所有相關的Article對象。
5.2.1、定義外鍵
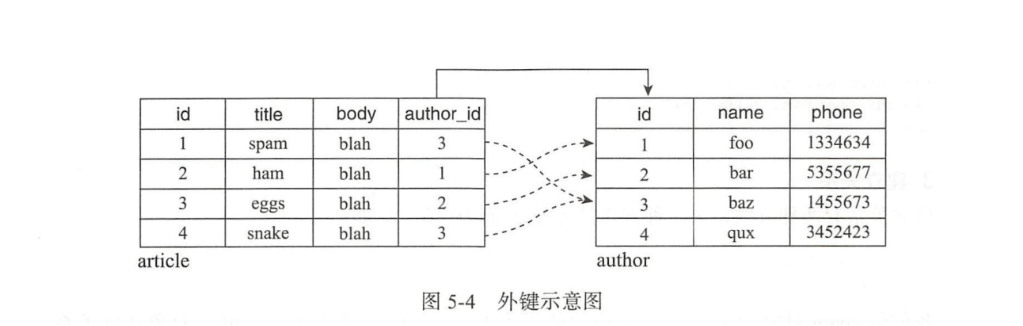
定義關系的第一步是創建外鍵。外鍵是(foreign key)用來在A表存儲B表的主鍵值以便和B表建立聯系的關鍵字段。因為外鍵只能存儲單一數據(標量),所以外鍵總是在"多"這一側定義,多篇文章屬于同一個作者,所以我們需要為每篇文章添加外鍵存儲作者的主鍵值以指向對應的作者。
class Article(db.Model):...author_id = db.Column(db.Integer,db.ForeignKey('author.id'))使用db.ForeignKey類定義外鍵,傳入關系另一側的表名和主鍵字段名,即author.id。實際效果是將article表的author_id的值限制為author表的id列的值。它將用來存儲author表中記錄的主鍵值:
 5.2.2、定義關系屬性
5.2.2、定義關系屬性
定義關系的第二步是使用關系函數定義關系屬性。關系屬性在關系的出發側定義,即一對多關系的“一”這一側。一個作者擁有多篇文章,在Author模型中,我們定義了一個articles屬性來表示對應的多篇文章:
class Author(db.Model):...articles = db.relationship('Article')使用db.relationship()關系函數定義為關系屬性,因為這個關系屬性返回多個記錄,我們稱之為集合關系屬性。relationship()函數的第一個參數為關系另一側的模型名稱,它會告訴SQLALchemy將Author類與Article類建立聯系。
$ flask shell
>>> foo = Author(name='foo')
>>> spam = Article(title='Spam')
>>> ham = Article(title='Ham')
>>> db.session.add(foo)
>>> db.session.add(spam)
>>> db.session.add(ham) 5.2.3、建立關系
建立關系有兩種方式,第一種方式是為外鍵字段賦值,比如:
>>> spam.author_id = 1
>>> db.session.commit()將spam對象的author_id字段的值設為1,這會和id值為1的Author對象建立關系。提交數據庫改動后,如果我們對id為1的foo對象調用articles關系屬性,會看到spam對象包括在返回的Article對象中:
>>> foo.articles
[<Article u'spam>,<Article u'Ham>]另一種方式是通過操作關系屬性,將關系屬性賦給實際的對象即可建立關系。集合關系屬性可以像列表一樣操作,調用append()方法來與一個Article對象建立關系:
>>> foo.articles.append(spam)
>>> foo.articles.append(ham)
>>> db.session.commit()和前面的第一種方式類似,為了讓改動生效,我們需要調用db.session.commit()方法提交數據庫會話。建立關系后,存儲外鍵的author_id自動獲得正確的值,調用author 實例的關系屬性articles時,會獲得所有建立關系的Article對象。
>>> spam.author_id
1
>>> foo.articles
[<Article u'Spam'>,<Article u'Ham'>](之后統一用第二種方式,即通過關系屬性來建立關系)
和append()相對,對關系屬性調用remove()方法可以與對應的Article對象解除關系:
>>> foo.articles.remove(spam)
>>> db.session.commit()
>>> foo.articles
[<Article u'Ham'>]常用的SQLALchemy關系函數參數
| 參數名 | 說明 |
|---|---|
| back_populates | 定義反向引用,用于建立雙向關系,在關系的另一側也必須顯式定義關系屬性 |
| backref | 添加反向引用,自動在另一側建立關系屬性,是back_populates的簡化版 |
| lazy | 指定如何加載相關記錄 |
| uselist | 指定是否使用列表的形式加載記錄,設為False則使用標量(scalar) |
| cascade | 設置級聯操作 |
| order_by | 指定加載相關記錄時的排序方式 |
| secondary | 在多對多關系中指定關聯表 |
| primaryjoin | 指定多對多關系中的一級聯結條件 |
| secondaryjoin | 指定多對多關系中的二級聯結條件 |
當關系屬性被調用時,關系函數會加載相應的記錄,下面列出控制關系記錄加載方式的lazy參數的常用選項:
| 關系加載方式 | 說明 |
|---|---|
| select | 在必要時一次性加載記錄,返回包含記錄的列表(默認值),等同于lazy=True |
| joined | 和父查詢一樣加載記錄,但使用聯結,等同于lazy=False |
| immediate | 一旦父查詢加載就加載 |
| subquery | 類似于joined,不過使用子查詢 |
| dynamic | 不直接加載記錄,而是返回一個包含相關記錄的query對象,以便再繼續附加查詢函數對結果直接進行過濾 |
(dynamic選項僅用于集合關系屬性,不可用于多對一,一對一或是在關系函數中將uselist參數設為False的情況)
(許多教程和示例使用dynamic來動態加載所有集合關系屬性對應的記錄,這是應該避免的行為。使用dynamic加載方式意味著每次操作關系都會執行一次SQL查詢,這會造成潛在的性能問題。大多數情況下我們只需要使用默認值(select),只有在調用關系屬性會返回大量記錄,并且總是需要對關系屬性返回的結果附加額外的查詢才需要使用動態加載(dynamic))。
5.2.4、建立雙向關系
我們在Author類中定義了集合關系屬性articles,用來獲取某個作者擁有的多篇文章記錄。在某些情況下,你也許希望能在Article類中定義一個類似的author關系屬性,當被調用時返回對應的作者記錄,這類返回單個值的關系屬性被稱為標量關系屬性。而這兩側都添加關系屬性獲取對方的關系稱之為雙向關系
雙向關系并不是必須的,但在某些情況下會非常方便。雙向關系的建立很簡單,通過在關系的另一側也創建一個relationship()函數,我們就可以在兩個表之間建立雙向關系。下面使用作家(Writer)和書(Book)的一對多關系進行演示:
class Writer(db.Model):id = db.Column(db.Integer,primary_key= True)name = db.Column(db.String(70),unique=True)books = db.relationship('Book',back_populates='writer')class Book(db.Model):id = db.Column(db.Integer,primary_key=True)title = db.Column(db.String(50),index=True)writer_id = db.Column(db.Integer,db.ForeignKey('writer.id'))writer = db.relationship('Writer',back_populates='books')邏輯:在“多”這一側的Book(書)類中,我們新創建了一個writer關系屬性,這是一個標量關系屬性,調用它會獲取對應的Writer(作者)記錄;而在Writer(作者)類中的books屬性則用來獲取對應的多個Book(書)記錄。在關系函數中,我們使用back_populates參數來連接對方,back_populates參數的值需要設為關系另一側的關系屬性名。
>>> king = Writer(name='Stephen King')
>>> carrie = Book(name='Carrie')
>>> it = Book(name='IT')
>>> db.session.add(King)
>>> db.session.add(carrie)
>>> db.session.add(it)
>>> db.session.commit()設置雙向關系后,除了通過集合屬性books來操作關系,也可使用標量屬性writer來進行關系操作。比如將一個Writer對象賦值給某個Book對象的writer屬性,就會和這個Book對象建立關系:
>>> carrie.writer = king
>>> carrie.writer
<Writer u'Stephen King'>
>>> king.books
[<Book u'Carrie'>]
>>> it.writer = writer
>>> king.books
[<Book u'Carrie'>,<Book u'IT'>]相對的,將某個Book的writer屬性設為None,就會解除與對應Writer對象的關系:
>>> carrie.writer = None
>>> king.books
[<Book u'IT'>]
>>> db.session.commit()需要注意,我們只需要在關系的一側操作關系。當為Book對象的writer屬性賦值后,對應Writer對象的books屬性的返回值也會自動包含這個Book對象。反之,當某個Writer對象被刪除時,對應的Book對象的writer屬性被調用時的返回值也會被置空(即NULL,會返回None)
5.2.5、使用backref簡化關系定義
以一對多關系為例,backref參數用來自動為關系另一側添加關系屬性,作為反向引用,賦予的值會作為關系的另一側的關系屬性名稱。
class Singer(db.Model):id = db.Column(db.Integer,primary_key=True)name = db.Column(db.String(70),unique=True)songs = db.relationship('Song',backref='singer')class Song(db.Model):id = db.Column(db.Integer,primary_key=True)name = db.Column(db.String(50),index=True)singer = db.Column(db.Integer,db.ForeignKey('singer.id'))邏輯:在定義集合屬性songs的關系函數中,我們將backref參數設為singer,這會同時在Song類中添加一個singer標量屬性。這時我們僅需定義一個關系函數,雖然singer是一個“看不見的關系屬性”,但在使用上和定義兩個關系函數并使用back_populates參數的效果完全相同。
注意:backref允許我們僅在關系一側定義另一側的關系屬性,但在某些情況下,我們希望可以對在關系另一側的關系屬性進行設置,這時需要使用backref()函數。backref()函數接收第一個參數作為在關系另一側添加的關系屬性名,其他關鍵字參數會作為關系另一側關系函數的參數傳入。比如:在關系的另一側“看不見的relationship()函數”中將uselist參數設為False:
class Singer(db.Model):...songs = relationship('Song',backref=backref('singer',userlist=False))5.3、多對一
使用居民和城市演示:多個居民住在同一個城市。前面介紹:關系屬性在關系模式的觸發側定義。當出發點在“多”這一側時,我們希望在Citizen類中添加一個關系屬性city來獲取對應的城市對象,因為這個關系屬性返回單個值,我們稱之為標量關系屬性。在定義關系時,外鍵總是在“多”這一側定義,所以在多對一關系中,外鍵和關系屬性都定義在“多”這一側:
class Citizen(db.Model):id = db.Column(db.Integer,primary_key=True)name = db.Column(db.String(70),unique=True)city_id = db.Column(db.Integer,db.ForeignKey('City.id'))city = db.relationship('City')class City(db.Model):id = db.Column(db.Integer,primary_key=True)name = db.Column(db.String(30),unique=True)邏輯:這時定義的city屬性是一個標量屬性(返回單一數據)。當Citizen.city被調用時,SQLALchemy會根據外鍵字段city_id對象并返回,即居民記錄對應的城市記錄。
當建立雙向關系時,如果不使用backref,那么一對多和多對一關系模式在上完全相同,這時可以將一對多和多對一視為同一種關系模式。在后面我們通常都會為一對多或多對一建立雙向關系,這時將弱化這兩種關系的區別,一律稱為一對多關系
5.4、一對一
使用國家和首都演示:每個國家只有一個首都。
一對一關系實際上是通過建立雙向關系的一對多的基礎上轉換而來。我們要確保關系兩側的關系屬性都是標量關系,都只返回單個值,所以要在定義集合屬性的關系函數中將uselist參數設為False,這時一對多關系將被轉換為一對一關系:
class Country(db.Model):id = db.Column(db.Inyeger,primary_key=True)name = db.Column(db.String(30),unique=True)capital = db.relationship('Capital',uselist=False)class Capital(db.Model):id = db.Column(db.Integer,primary_key=True)name = db.Column(db.String(30),unique=True)country_id = db.Column(db.Integer,db.ForeignKey('country.id'))country = db.relationship('Country')邏輯:”多“這一側本身就是標量關系屬性,不用做任何改動。而”一“這一側的集合關系屬性,通過將uselist設為False后,將僅返回對應的單個記錄,而且無法再使用列表語義操作:
>>> china = Country(name='China')
>>> beijing = Captital(name='Beijing')
>>> db.session.add(china)
>>> db.session.add(beijing)
>>> db.sessiom.commit()
>>> china.captital = beijing
>>> china.captital
<Captital 1>
>>> beijing.country
u'China'
>>> tokyo = Capital(name'Tokyo')
>>> china.capital.append(tokyo)
Traceback (most recent call last):File "<console>", line 1, in<module>
AttributeError: 'Captital' object has no attribute 'append'5.5、多對多
使用學生和老師演示多對多關系:每個學生有多個老師,而每個老師有多個學生。
在多對多關系中,每一個記錄都可以與關系另一側的多個記錄建立關系,關系兩側的模型都需要存儲一組外鍵。在SQLALchemy中,我們還需要創建一個關聯表。關聯表不存儲數據,只用來存儲關系兩側模型的外鍵對應關系:
association_table = db.Table('association', db.Column('student_id', db.Integer, db.ForeignKey('student.id')),db.Column('teacher_id', db.Integer, db.ForeignKey('teacher.id')))class Student(db.Model):id = db.Column(db.Integer, primary_key=True)name = db.Column(db.String(70), unique=True)grade = db.Column(db.String(20))teachers = db.relationship('Teacher', secondary=association_table, back_populates='students')class Teacher(db.Model):id = db.Column(db.Integer, primary_key=True)name = db.Column(db.String(70), unique=True)office = db.Column(db.String(20))關聯表使用db.Table定義,傳入的第一個參數是關聯表的名稱。在上述關聯表中定義了兩個外鍵字段:teacher_id字段存儲Teacher類的主鍵,student_id存儲Student類的主鍵。借助關聯表中這個中間人存儲的外鍵對,我們可以把多對多關系分化成兩個一對多關系:
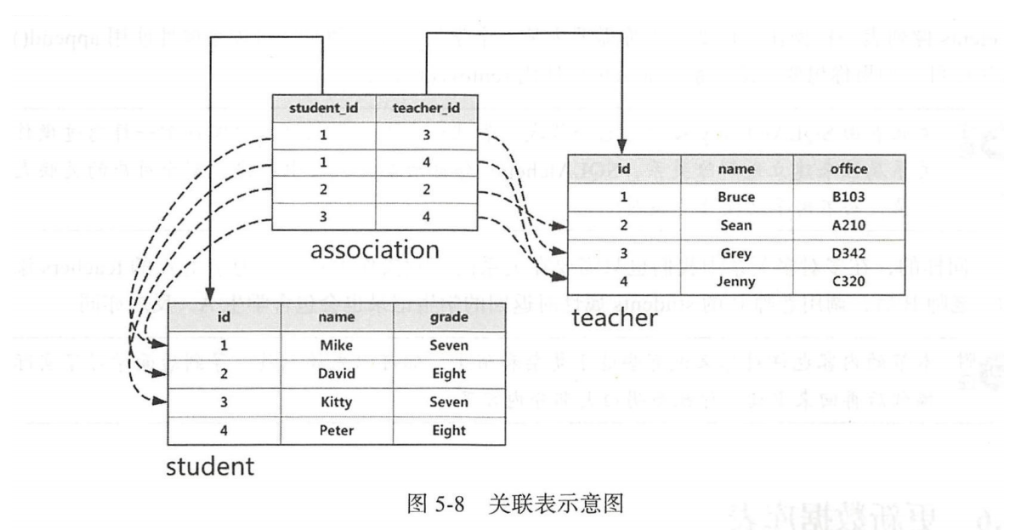 示例:當需要查詢某個學生記錄的多個老師時,先通過學生和管理表的一對多關系查詢所有包含該學生的關聯表記錄,然后就可以從這些記錄中再進一步獲取每個關聯表記錄包含的老師記錄。
示例:當需要查詢某個學生記錄的多個老師時,先通過學生和管理表的一對多關系查詢所有包含該學生的關聯表記錄,然后就可以從這些記錄中再進一步獲取每個關聯表記錄包含的老師記錄。
在Student類中定義一個teachers關系屬性用來獲取老師集合。在多對多關系中定義關系函數,除了第一個參數是關系另一側的模型名稱外,還需要添加一個secondary參數,把這個值設為管理表的名稱。
為了便于實現真正的多對多關系,我們需要建立雙向關系。在Student類上的teachers集合屬性會返回所有關聯的老師記錄,而在Teacher類上的students集合屬性會返回所有相關的學生記錄:
class Student(db.Model):...teachers = db.relationship('Teacher',secondary=association_table,back_populates='students')class Teacher(db.Model):...students = db.relationship('Student',secondary=association_table,back_populates='teachers')除了在聲明關系模式在操作關系時和其他關系模式基本相同。調用關系屬性student.teachers時,SQLALchemy會直接返回關系另一側的Teacher對象,而不是關聯表記錄。和其他關系模式中的集合屬性一樣,我們可以將關系屬性teachers和students像列表一樣操作。比如,當需要為某一個學生添加老師時,對關系屬性使用append()方法即可。解除關系使用remove()方法。
六、更新數據庫表
6.1、重新生成表
使用drop_all()方法刪除表以及其中的數據,然后使用create_all()方法重新創建:
>>> db.drop_all()
>>> db.create_all()為了便于開發,我們修改initdb命令函數的內容,為其增加一個--drop選項來支持刪除表和數據庫后進行重建:
@app.cli.command()
@click.option('--drop',is_flag=True,help='Create after drop.')
def initdb(drop):"""Initialize the database."""if drop:click.confirm('This operation will delete the database,do you want to continue?',abort=True)db.drop_all()click.echo('Drop tables.')db.create_all()click.echo('Initialized database.')現在,執行下面的命令會重建數據庫和表:
$ flask initdb --drop(當使用SQLite時,直接刪除data.db文件和調用drop_all()方法效果相同,更直接不容易出錯)
6.2、使用Flask-Migrate遷移數據庫
不想要數據庫中的數據被刪除掉就使用數據庫遷移來完成。
遷移工具--Alembic來幫我們實現數據庫的遷移,數據庫遷移工具可以在不破壞數據的情況下更新數據庫表的結構。
擴展Flask-Migrate集成了Alembic,提供了一些flask命令來簡化遷移工作:
pip install flask-migrate在程序中,我們實例化Flask-Migrate提供的Migrate類,進行初始化操作:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrateapp = Flask(__name__)
...
db = SQLAlchemy(app)
migrate = Migrate(app,db)6.2.1、創建遷移環境
開始遷移數據庫之前,需要使用下面的命令創建一個遷移環境:
$ flask db init遷移環境只需要創建一次。這會在項目根目錄下創建一個migrations文件夾,其中包含了自動生成的配置文件和遷移版本文件夾
6.2.2、生成遷移腳本
使用migrate子命令可以自動生成遷移腳本:
$ flask db migrate -m "add note timestamp"這條命令:在flask里對數據庫(db)進行遷移。-m選項用來添加遷移備注信息。生成內容示例:
"""add note timestamp
Revision ID: b27e0318b424
"""
from alembic import op
import sqlalchemy as sa
...
def upgrade():# ### commands auto generated by Alembic - please adjust! ###op.add_column('note',sa.Column('timestamp',sa.DateTime(),nullable=True))# ### end Alembic commands ###def downgrade():# ### commands auto generated by Alembic - please adjust! ###op.drop_column('note','timestamp')# ### end Alembic commands ###遷移腳本主要包含了兩個函數:upgrade()函數用來將改動應用到數據庫,函數中包含了向表中添加timestamp字段的命令;而downgrade()函數用來撤銷改動,包含了刪除timesptamp字段的命令。
6.2.3、更新數據庫
生成了遷移腳本后,使用upgrade子命令即可更新數據庫:
>>> $ flask db upgrade若沒有創建數據庫和表,這個命令會自動創建;若已創建,則會在不損壞數據的前提下執行更新。
6.3、開發時是否要遷移?
盡可能讓開發環境和生產環境保持一致。考慮直接在本地使用MySQL或PostgreSQL等性能更高的DBMS,然后設置遷移環境。
七、數據庫進階實踐
7.1、級聯操作
Cascade意為“級聯操作”,就是在操作一個對象的同時,對相關的對象也執行某些操作。示例:
class Post(db.Model):id = db.Column(db.Integer, primary_key=True)title = db.Column(db.String(50), unique=True)body = db.Column(db.Text)comments = db.relationship('Comment', back_populates='post')class Comment(db.Model):id = db.Column(db.Integer, primary_key=True)body = db.Column(db.Text)post_id = db.Column(db.Integer, db.ForeignKey('post.id'))post = db.relationship('Post', back_populates='comments')級聯行為通過關系函數relationship()的cascade參數設置。我們希望在操作Post對象時,處于附屬低位的Comment對象也被相應執行某些操作,這時應該在Post類的關系函數中定義級聯參數。設置了cascade參數的一側將被視為父對象,相關的對象則視為子對象。
cascade通常使用多個組合值,級聯值之間使用逗號分隔:
class Post(db.Model):...comments = relationship('Comment',cascade='save-update,merge,delete')常用的配置組合如下所示:
- save-update、merge(默認值)
- save-update、merge、delete
- all
- all、delete-orphan
當沒有設置cascade參數時,會使用默認值save-update、merge。上面的all等同于除了delete-orphan以為所有可用值的組合,即save-update、merge、refresh-expire、expunge、delete。下面我們會介紹常用的幾個級聯值:
7.1.1、save-update
save-update是默認的級聯行為,當cascade參數設為save-update時,如果使用db.session.add()方法將Post對象添加到數據庫會話時,那么與Post相關聯的Comment對象也將被添加到數據庫會話。
>>> post1 = Post()
>>> comment1 = Comment()
>>> comment2 = Comment()將post1添加到數據庫會話后,只有post1在數據庫會話中:
>>> db.session.add(post1)
>>> post1 in db.session
True
>>> comment1 in db.session
False
>>> comment2 in db.session
False如果我們讓post1與兩個Comment對象建立關系,那么這兩個Comment對象也會自動被添加到數據庫會話中:
>>> post1.comments.append(comment1)
>>> post1.comments.append(comment2)
>>> comment1 in db.session
True
>>> comment2 in db.session
True當調用db.session.commit()數據庫會話時,這三個對象都會被提交到數據庫中。
7.1.2、delete
如果某個Post對象被刪除,那么按照默認的行為,該Post對象相關聯的所有Comment對象都將與這個Post對象取消關聯,外鍵字段的值會被清空。如果Post類的關系函數中cascade參數設為delete時,這些相關的Comment會在關聯的Post對象刪除時被一并刪除。當需要設置delete級聯時,我們會將級聯值設為all或save-update、merge、delete,比如:
class Post(db.Model):...comments = relationship('Comment',cascade='all')示例:
>>> post2 = Post()
>>> comment3 = Comment()
>>> comment4 = Comment()
>>> post2.comments.append(comment3)
>>> post2.comments.append(commetn4)
>>> db.session.add(post2)
>>> db.session.commit()現在共有兩條Post記錄和四條Comment記錄:
>>> Post.query.all()
[<Post 1>,<Post 2>]
>>> Comment.query.all()
[<Comment 1>,<Comment 2>,<Comment 3>,<Comment 4>]如果刪除文章對象Post2,那么對應的兩個評論對象也會一并被刪除:
>>> post2 = Post.query2y.get(2)
>>> db.session.delete(post2)
>>> db.session.commit()
>>> Post.query.all()
[<Post 1>]
>>> Comment.query.all()
[<Comment 1>,<Comment 2>]7.1.3、delete-orphan
這個模式是基于delete級聯的,必須和delete級聯一起使用,通常會設為all、delete-orphan,因為all包含delete。因此當cascade參數設為delete-orphan時,它首先包含delete級聯的行為:當某個Post對象被刪除,所有相 Comment 都將被刪除 delete 級聯) 。除此之外, 當某個Post對象(父對象)與某Comment對象(子對象)解除關系時,也會刪除該 Comment對象, 這個解除關系的對象被稱為孤立對象(orphan object):
class Post(db.Model):...comments = relationship('Comment',cascade='all,delete-orphan')delete和delete-orphan通常會在一對多關系模式中,而且“多”這一側的對象附屬于“一”這一側的對象時使用。尤其是如果“一”這一側的“父”對象不存在了,那么“多”這一側的“子“對象不再有意義的情況。比如,文章和評論。
雖然級聯操作方便,但是容易帶來安全隱患,因此要謹慎使用。默認值能夠滿足大部分情況,所以最好僅在需要的時候才修改它。
7.2、事件監聽
SQLALchemy提供了一個listen_for()裝飾器,可以用來注冊事件回調函數。
listen_for()裝飾器接收兩個參數,target表示監聽的對象,這個對象可以是模型類、類實例或類屬性等。identifier參數表示被監聽事件的標識符,比如,用于監聽屬性的事件標識符有set、append、remove、init_scalar、init_collection等。
# 創建一個Draft模型類表示草稿
class Draft(db.Model):id = db.Column(db.Integer,primary_key=True)body = db.Column(db.Text)edit_time = db.Column(db.Integer,default=0)通過注冊件監聽函數,實現在body列修改時,自動疊加表示被修改次數的edit_ time字段。在SQLAlchemy中,每個事件都會有一個對應的事件方法,不同的事件方法支持不同的參數,被注冊的監聽函數需要接收對應事件方法的 所有參數,所以具體的監聽函數用法因使用的事件而異。設置某個字段值將觸發set事件:
@db.event.listens_for(Draft.body,'set')
def increment_edit_time(target,value,oldvalue,initiator):if target.edit_time is not None:target.edit_time += 1# target參數表示觸發事件的模型類實例,使用target.edit_time即可獲取我們需要疊加的字段。value表示被設置的值,oldvalue表示被取代的舊值。當set事件發生在目標對象Draft.body上時,這個監聽函數就會被執行,從而疊加Draft.edit_time列的值:
>>> draft = Draft(body='init')
>>> db.session.add(draft)
>>> db.session.commit()
>>> draft.edit_time
0
>>> draft.body = 'edited'
>>> draft.edit_time
1
>>> draft.body = 'edited again'
>>> draft.edit_time
2
>>> draft.body = 'edited agian again'
>>> draft.edit_time
3
db.session.commit()除了這種傳統的參數接收方式,即接收所有事件方法接收的參數,還有一種:通過在listen_for()裝飾器中將關鍵字參數name設為True,可以在監聽函數中接收**kwargs作為參數(可變長關鍵字參數)。然后在函數中可以使用參數名作為鍵從kwargs字典中取出對應的參數值:
@db.event.listens_for(Draft.body,'set')
def increment_edit_time(**kwargs):if kwargs['target'].edit_time is not None:kwargs['target'].edit_time += 1SQLALchemy作為SQL工具集本身包含兩大主要組件:SQLALchemy ORM和SQLALchemy Core。前者實現了前面介紹的ORM功能,后者實現了數據庫接口等核心功能,這兩類組件都提供了大量的監聽事件,幾乎覆蓋了整個SQLALchemy使用的生命周期。
致謝
在此,我要對所有為知識共享做出貢獻的個人和機構表示最深切的感謝。同時也感謝每一位花時間閱讀這篇文章的讀者,如果文章中有任何錯誤,歡迎留言指正。?
學習永無止境,讓我們共同進步!!
信息安全等級保護測評標準解讀)






)
三級公立醫院績效考核系統源碼)

![[解決方案]使用微軟拼音打中文卡頓到離譜](http://pic.xiahunao.cn/[解決方案]使用微軟拼音打中文卡頓到離譜)








