這是我的第309篇原創文章。
一、引言
基于CNN(卷積神經網絡)和Bi-LSTM(雙向長短期記憶網絡)的單變量時間序列預測是一種結合空間特征提取和時間依賴建模的方法。以下是一個基于Python和TensorFlow/Keras實現的示例,展示了如何構建和訓練這種混合模型來進行時間序列預測。
二、實現過程
2.1 讀取數據集
# 讀取數據集
data = pd.read_csv('data.csv')
# 將日期列轉換為日期時間類型
data['Month'] = pd.to_datetime(data['Month'])
# 將日期列設置為索引
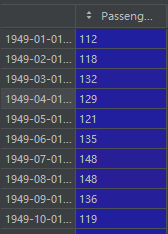
data.set_index('Month',?inplace=True)data:
2.2 劃分數據集
#?拆分數據集為訓練集和測試集
train_size = int(len(data) * 0.8)
train_data = data[:train_size]
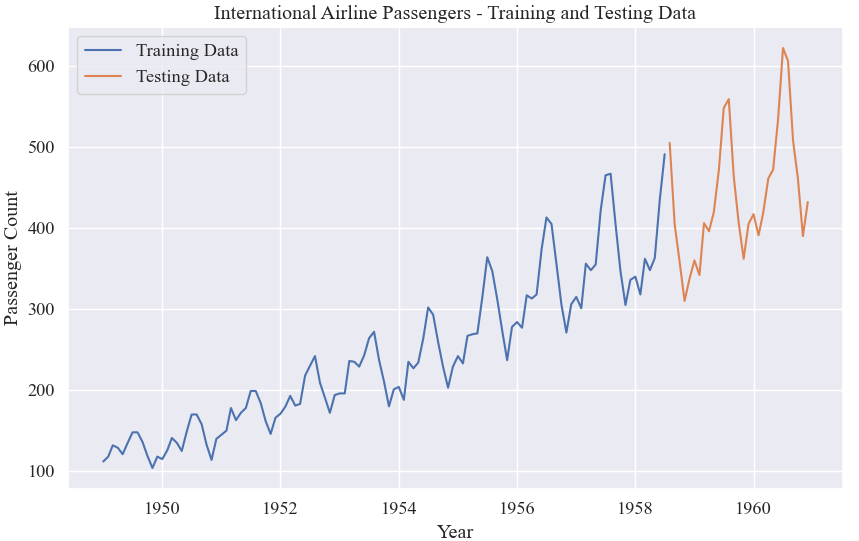
test_data = data[train_size:]# 繪制訓練集和測試集的折線圖
plt.figure(figsize=(10, 6))
plt.plot(train_data, label='Training Data')
plt.plot(test_data, label='Testing Data')
plt.xlabel('Year')
plt.ylabel('Passenger Count')
plt.title('International Airline Passengers - Training and Testing Data')
plt.legend()
plt.show()共144條數據,8:2劃分:訓練集115,測試集29。
訓練集和測試集:
2.3 歸一化
# 將數據歸一化到 0~1 范圍
scaler = MinMaxScaler()
train_data_scaler = scaler.fit_transform(train_data.values.reshape(-1, 1))
test_data_scaler?=?scaler.transform(test_data.values.reshape(-1,?1))2.4 構造數據集
# 定義滑動窗口函數
def create_dataset(data, look_back=1):pass# 定義滑動窗口大小
window_size?=?3
# 創建滑動窗口數據集
X_train, Y_train = create_dataset(train_data_scaler, look_back)
X_test,?Y_test?=?create_dataset(test_data_scaler,?look_back)2.5 建立模擬合模型進行預測
#?構建模型
model = Sequential()
model.add(TimeDistributed(Conv1D(filters=64, kernel_size=1, activation='relu', input_shape=(None, X_train.shape[0], X_train.shape[1],1))))
model.add(TimeDistributed(MaxPooling1D(pool_size=1)))
model.add(TimeDistributed(...))
model.add(Bidirectional(LSTM(4, activation='relu')))
model.add(Dense(1))my_model.compile(loss='mean_squared_error', optimizer='adam')
my_model.fit(X_train, Y_train, epochs=50, batch_size=1, verbose=2)
# 打印模型
model.summary()# 使用模型進行預測
train_predictions = model.predict(X_train)
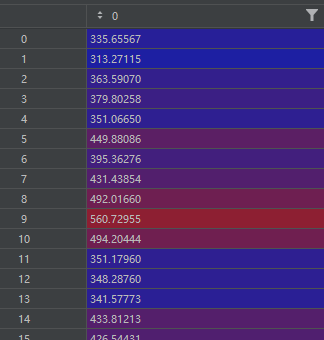
test_predictions?=?model.predict(X_test)test_predictions:
2.6 預測效果展示
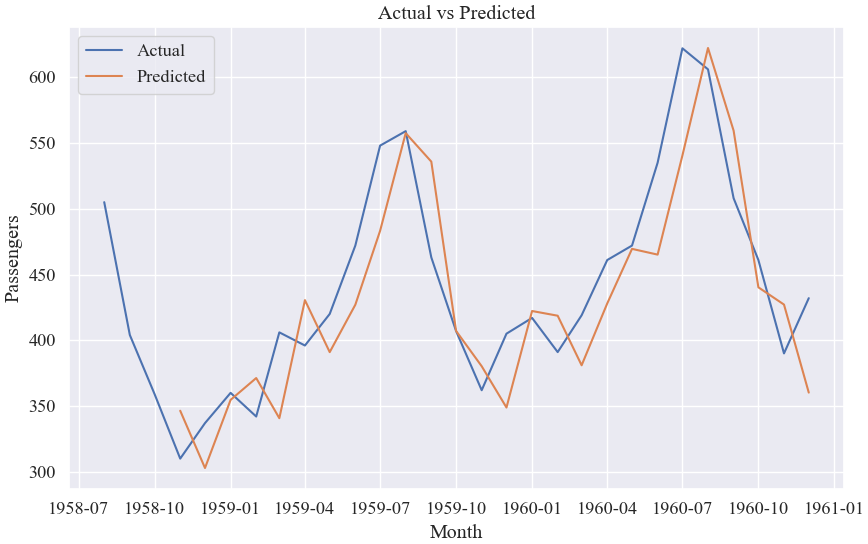
# 繪制測試集預測結果的折線圖
plt.figure(figsize=(10, 6))
plt.plot(test_data, label='Actual')
plt.plot(list(test_data.index)[-len(test_predictions):], test_predictions, label='Predicted')
plt.xlabel('Month')
plt.ylabel('Passengers')
plt.title('Actual vs Predicted')
plt.legend()
plt.show()測試集真實值與預測值:
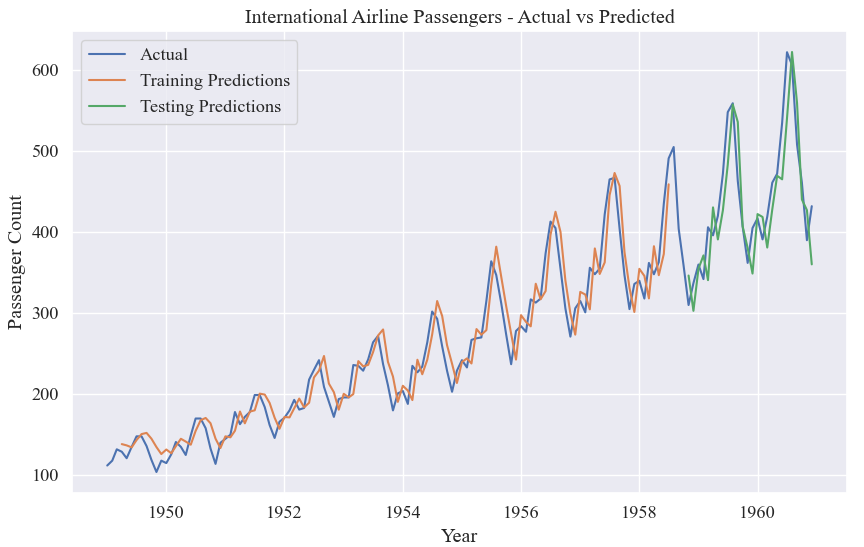
# 繪制原始數據、訓練集預測結果和測試集預測結果的折線圖
plt.figure(figsize=(10, 6))
plt.plot(data, label='Actual')
plt.plot(list(train_data.index)[look_back:train_size], train_predictions, label='Training Predictions')
plt.plot(list(test_data.index)[-(len(test_data)-look_back):], test_predictions, label='Testing Predictions')
plt.xlabel('Year')
plt.ylabel('Passenger Count')
plt.title('International Airline Passengers - Actual vs Predicted')
plt.legend()
plt.show()原始數據、訓練集預測結果和測試集預測結果:
作者簡介:
讀研期間發表6篇SCI數據挖掘相關論文,現在某研究院從事數據算法相關科研工作,結合自身科研實踐經歷不定期分享關于Python、機器學習、深度學習、人工智能系列基礎知識與應用案例。致力于只做原創,以最簡單的方式理解和學習,關注我一起交流成長。需要數據集和源碼的小伙伴可以關注底部公眾號添加作者微信。


















)
