💡💡💡本專欄所有程序均經過測試,可成功執行💡💡💡
專欄目錄:《YOLOv8改進有效漲點》專欄介紹 & 專欄目錄 | 目前已有40+篇內容,內含各種Head檢測頭、損失函數Loss、Backbone、Neck、NMS等創新點改進
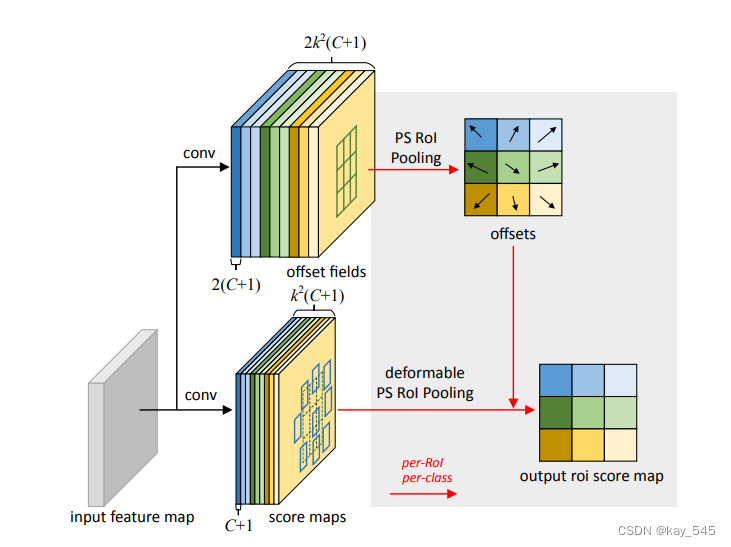
卷積神經網絡(CNN)由于其構建模塊中固定的幾何結構,天生就局限于對幾何變換的建模。為此,引入了兩個新的模塊來增強CNN的變換建模能力,即可變形卷積和可變形RoI池化。兩者都是基于在模塊的空間采樣位置增加附加偏移量的思想,并從目標任務中學習這些偏移量,而不需要額外的監督。這些新模塊可以很容易地替換現有CNNs中的普通對應模塊,并且可以通過標準的反向傳播輕松地進行端到端的訓練,從而產生可變形卷積網絡。文章在介紹主要的原理后,將手把手教學如何進行模塊的代碼添加和修改,并將修改后的完整代碼放在文章的最后,方便大家一鍵運行,小白也可輕松上手實踐。以幫助您更好地學習深度學習目標檢測YOLO系列的挑戰。
專欄地址:YOLOv8改進——更新各種有效漲點方法——點擊即可跳轉
目錄
1.原理
2. 將C2f_DCN添加到YOLOv8中
2.1 Deformable Convolutional Networks代碼實現
2.2 更改init.py文件
2.3 添加yaml文件
2.4 在task.py中進行注冊
2.5 執行程序
3. 完整代碼分享
4. GFLOPs
5. 進階
6. 總結
1.原理

論文地址:Deformable Convolutional Networks——點擊即可跳轉
官方代碼:官方代碼倉庫——點擊即可跳轉
可變形卷積網絡 (DCN) 旨在通過引入可變形卷積和可變形 RoI(感興趣區域)池化模塊來增強卷積神經網絡 (CNN) 的建模能力。這些模塊旨在解決 CNN 在處理幾何變換方面的局限性。以下是 DCN 主要原理的概述:
可變形卷積網絡的關鍵原理:
幾何變換:
-
標準 CNN 難以處理縮放、旋轉和變形等幾何變換,因為它們的卷積操作基于固定網格結構。
-
DCN 通過允許卷積網格根據輸入圖像特征進行調整和變形來解決這個問題。
可變形卷積:
-
標準卷積:使用固定網格對輸入特征圖進行采樣。例如,3x3 內核對輸入特征圖中的九個固定點進行采樣。
-
可變形卷積:在標準網格采樣位置引入可學習的偏移量。這些偏移量是從前面的特征圖中學習到的,使網格能夠變形并適應圖像中對象的形狀和比例。 -實現:將偏移量應用于網格點,并使用雙線性插值在這些新位置進行采樣以處理分數偏移。
可變形 RoI 池化:
標準 RoI 池化:
將給定的 RoI 劃分為固定的空間箱,并在每個箱內應用最大池化以將該區域轉換為固定大小的特征圖。 -可變形 RoI 池化:將可學習的偏移量添加到箱化位置,使池化操作能夠適應 RoI 內對象的形狀。 -實現:偏移量是通過額外的卷積層學習到的,并在池化操作期間應用以動態調整箱位。
訓練和集成:
可變形卷積和 RoI 池化都可以在任何 CNN 架構中取代其標準對應物。
-
偏移學習過程引入的附加參數使用反向傳播進行端到端訓練。
-
可變形卷積網絡可輕松集成到最先進的 CNN 架構(如 ResNet 和 Inception-ResNet)中,用于對象檢測和語義分割等任務。
優點:
-
靈活性: 通過允許采樣網格和 RoI 區域變形,DCN 可以更準確地模擬復雜的幾何變換和對象形狀的變化。
-
性能: 實證結果表明,DCN 顯著提高了對象檢測和分割等復雜視覺任務的性能,尤其是對于具有不同尺度和變形的對象。
視覺插圖:
-
可變形卷積: 采樣點不是固定的 3x3 網格,而是根據學習到的偏移進行位移,從而產生更靈活和自適應的感受野。
-
可變形 RoI 池化:動態調整 RoI 箱以更好地適應對象的形狀,從而增強池化操作的有效性。
應用:
-
對象檢測:更好地處理不同大小和形狀的對象。
-
語義分割:提高復雜場景中像素標記的準確性。
綜上所述,DCN 通過引入可變形卷積和 RoI 池化增強了 CNN 的幾何變換建模能力。這些模塊為網絡提供了根據輸入特征調整其結構的能力,從而提高了各種計算機視覺任務的性能。
2. 將C2f_DCN添加到YOLOv8中
2.1 Deformable Convolutional Networks代碼實現
關鍵步驟一: 將下面代碼粘貼到在/ultralytics/ultralytics/nn/modules/block.py中,并在該文件的__all__中添加“C2f_DCN”
*注:代碼過長,只放置部分代碼,需要可以查看第三部分的完整代碼
class DCNv2(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, stride=1,padding=1, dilation=1, groups=1, deformable_groups=1):super(DCNv2, self).__init__()self.in_channels = in_channelsself.out_channels = out_channelsself.kernel_size = (kernel_size, kernel_size)self.stride = (stride, stride)self.padding = (padding, padding)self.dilation = (dilation, dilation)self.groups = groupsself.deformable_groups = deformable_groupsself.weight = nn.Parameter(torch.empty(out_channels, in_channels, *self.kernel_size))self.bias = nn.Parameter(torch.empty(out_channels))out_channels_offset_mask = (self.deformable_groups * 3 *self.kernel_size[0] * self.kernel_size[1])self.conv_offset_mask = nn.Conv2d(self.in_channels,out_channels_offset_mask,kernel_size=self.kernel_size,stride=self.stride,padding=self.padding,bias=True,)self.bn = nn.BatchNorm2d(out_channels)self.act = Conv.default_actself.reset_parameters()def forward(self, x):offset_mask = self.conv_offset_mask(x)o1, o2, mask = torch.chunk(offset_mask, 3, dim=1)offset = torch.cat((o1, o2), dim=1)mask = torch.sigmoid(mask)x = torch.ops.torchvision.deform_conv2d(x,self.weight,offset,mask,self.bias,self.stride[0], self.stride[1],self.padding[0], self.padding[1],self.dilation[0], self.dilation[1],self.groups,self.deformable_groups,True)x = self.bn(x)x = self.act(x)return xdef reset_parameters(self):n = self.in_channelsfor k in self.kernel_size:n *= kstd = 1. / math.sqrt(n)self.weight.data.uniform_(-std, std)self.bias.data.zero_()self.conv_offset_mask.weight.data.zero_()self.conv_offset_mask.bias.data.zero_()class Bottleneck_DCN(nn.Module):# Standard bottleneck with DCNdef __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expandsuper().__init__()c_ = int(c2 * e) # hidden channelsif k[0] == 3:self.cv1 = DCNv2(c1, c_, k[0], 1)else:self.cv1 = Conv(c1, c_, k[0], 1)if k[1] == 3:self.cv2 = DCNv2(c_, c2, k[1], 1, groups=g)else:self.cv2 = Conv(c_, c2, k[1], 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))可變形卷積網絡 (DCN) 以一種將適應性引入標準卷積神經網絡操作的方式處理數據。
可變形卷積網絡中的主要處理流程
輸入數據:
-
網絡的輸入通常是一張圖像或一批圖像。
初始卷積層:
-
輸入圖像通過初始標準卷積層處理以提取基本特征。這些層的功能與傳統 CNN 中的層類似,應用固定網格卷積操作。
可變形卷積層:
-
在初始特征提取之后,應用可變形卷積層。
-
偏移生成:對于特征圖上的每個位置,使用單獨的卷積操作來預測采樣網格的偏移量。這會產生一個動態學習的偏移場。
-
可變形采樣:使用預測的偏移量,調整卷積的采樣網格。卷積運算不是從固定位置采樣,而是從偏移定義的位置采樣,這些偏移通常是分數,需要雙線性插值。
-
卷積運算:然后使用新的變形網格位置應用卷積運算,生成具有增強的對輸入幾何結構的適應性的輸出特征圖。
可變形 RoI 池化(用于對象檢測/分割任務):
-
RoI 提取:根據區域提議網絡 (RPN) 等方法生成的提議,從特征圖中提取感興趣區域 (RoI)。
-
RoI 的偏移生成:與可變形卷積類似,預測 RoI 箱的偏移。
-
可變形箱化:根據學習到的偏移量調整 RoI 池化中的箱,使池化區域能夠適應 RoI 內對象的形狀和位置。
-
池化操作:在這些調整后的箱內執行最大池化或平均池化,以為每個 RoI 生成固定大小的特征圖。
后續卷積層:
-
可變形卷積和/或 RoI 池化層的輸出將輸入到后續卷積層和全連接層中,具體取決于特定架構(例如 ResNet、Faster R-CNN)。
-
這些層繼續處理特征圖以執行分類、邊界框回歸和分割等任務。
輸出層:
-
網絡的最后幾層產生所需的輸出,例如用于對象檢測的類別分數和邊界框坐標,或用于語義分割的逐像素分類。
訓練:
-
使用反向傳播對包括可變形模塊在內的網絡進行端到端訓練。
-
使用適合特定任務的損失函數(例如,分類的交叉熵損失、邊界框回歸的平滑 L1 損失)來指導訓練過程。
-
除了標準卷積參數外,還學習了可變形卷積和 RoI 池化層的偏移量和權重。
優點
-
適應性:網絡可以適應不同的物體形狀和尺度,從而提高涉及不同幾何變換的任務的性能。
-
提高性能:實證結果表明,DCN 在物體檢測和語義分割等任務中的表現優于傳統 CNN。
結論
DCN 通過引入可變形卷積和 RoI 池化增強了傳統 CNN,使其更有能力處理復雜的幾何變化。這種適應性對于提高各種計算機視覺任務的性能至關重要。
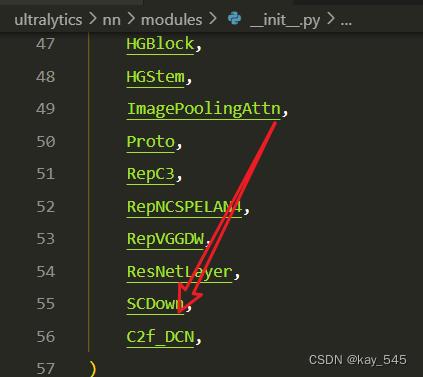
2.2 更改init.py文件
關鍵步驟二:修改modules文件夾下的__init__.py文件,先導入函數
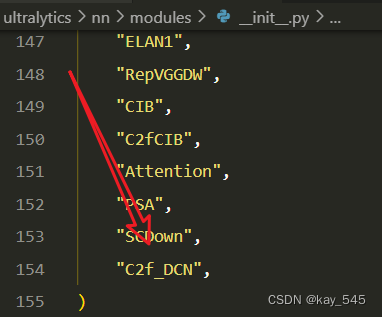
然后在下面的__all__中聲明函數
2.3 添加yaml文件
關鍵步驟三:在/ultralytics/ultralytics/cfg/models/v8下面新建文件yolov8_DCN.yaml文件,粘貼下面的內容
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [ 0.33, 0.25, 1024 ] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [ -1, 1, Conv, [ 64, 3, 2 ] ] # 0-P1/2- [ -1, 1, Conv, [ 128, 3, 2 ] ] # 1-P2/4- [ -1, 3, C2f_DCN, [ 128, True ] ] - [ -1, 1, Conv, [ 256, 3, 2 ] ] # 3-P3/8- [ -1, 6, C2f_DCN, [ 256, True ] ]- [ -1, 1, Conv, [ 512, 3, 2 ] ] # 5-P4/16- [ -1, 6, C2f_DCN, [ 512, True ] ]- [ -1, 1, Conv, [ 1024, 3, 2 ] ] # 7-P5/32- [ -1, 3, C2f_DCN, [ 1024, True ] ]- [ -1, 1, SPPF, [ 1024, 5 ] ] # 9# YOLOv8.0n head
head:- [ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ]- [ [ -1, 6 ], 1, Concat, [ 1 ] ] # cat backbone P4- [ -1, 3, C2f_DCN, [ 512 ] ] # 12- [ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ]- [ [ -1, 4 ], 1, Concat, [ 1 ] ] # cat backbone P3- [ -1, 3, C2f_DCN, [ 256 ] ] # 15 (P3/8-small)- [ -1, 1, Conv, [ 256, 3, 2 ] ]- [ [ -1, 12 ], 1, Concat, [ 1 ] ] # cat head P4- [ -1, 3, C2f_DCN, [ 512 ] ] # 18 (P4/16-medium)- [ -1, 1, Conv, [ 512, 3, 2 ] ]- [ [ -1, 9 ], 1, Concat, [ 1 ] ] # cat head P5- [ -1, 3, C2f_DCN, [ 1024 ] ] # 21 (P5/32-large)- [ [ 15, 18, 21 ], 1, Detect, [ nc ] ] # Detect(P3, P4, P5)溫馨提示:本文只是對yolov8基礎上添加模塊,如果要對yolov8n/l/m/x進行添加則只需要指定對應的depth_multiple 和 width_multiple。
# YOLOv8n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple# YOLOv8s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple# YOLOv8l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple# YOLOv8m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple# YOLOv8x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple2.4 在task.py中進行注冊
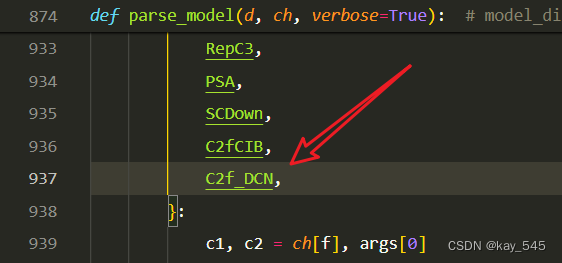
關鍵步驟四:在parse_model函數中進行注冊,添加C2f_DCN,
2.5 執行程序
關鍵步驟五:在ultralytics文件中新建train.py,將model的參數路徑設置為yolov8_DCN.yaml的路徑即可
from ultralytics import YOLO# Load a model
# model = YOLO('yolov8n.yaml') # build a new model from YAML
# model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)model = YOLO(r'/projects/ultralytics/ultralytics/cfg/models/v8/yolov8_DCN.yaml') # build from YAML and transfer weights# Train the model
model.train(device = [3], batch=16)建議大家寫絕對路徑,確保一定能找到
🚀運行程序,如果出現下面的內容則說明添加成功🚀
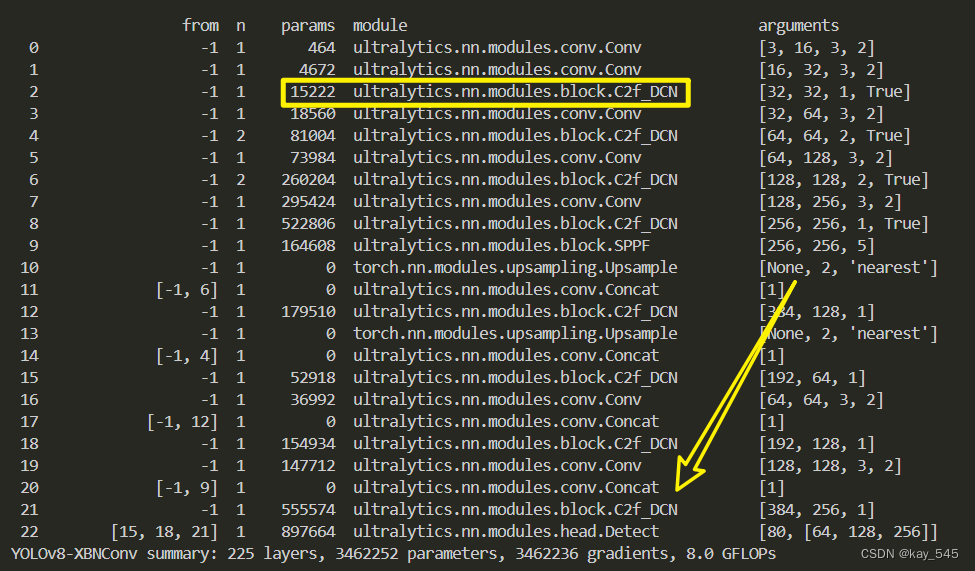
3. 完整代碼分享
https://pan.baidu.com/s/1kN1rW_tmKbefMKIkUXcqLw?pwd=ybu6提取碼: ybu6?
4. GFLOPs
關于GFLOPs的計算方式可以查看:百面算法工程師 | 卷積基礎知識——Convolution
未改進的YOLOv8nGFLOPs

改進后的GFLOPs
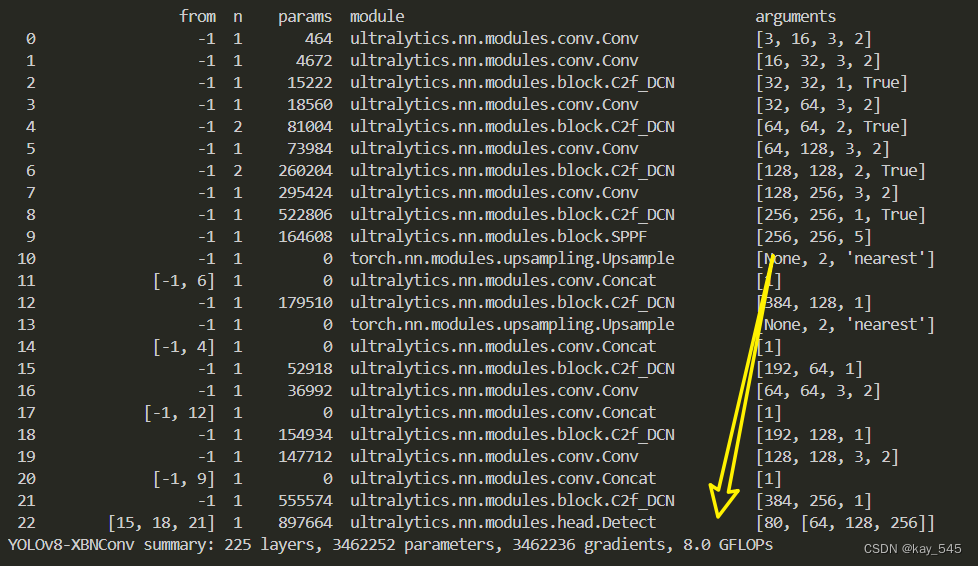
5. 進階
可以結合損失函數和注意力機制進行改進
6. 總結
可變形卷積網絡 (DCN) 通過引入可變形卷積和可變形 RoI(感興趣區域)池化模塊增強了傳統的卷積神經網絡 (CNN)。這些模塊允許采樣網格和 RoI 區域通過學習偏移量動態適應輸入圖像中對象的形狀和比例。這種適應性使網絡能夠更有效地處理幾何變換和變化,從而顯著提高對象檢測和語義分割等復雜視覺任務的性能。 ?















)

)
)
