翻譯:“Entity Extraction from Resume using Mistral-7b for Knowledge Graphs” | by Tejpal Kumawat | Feb, 2024 | Medium[1]
在快速發展的自然語言處理(NLP)領域,從非結構化文本源中準確提取和分析信息的能力變得越來越重要。這種能力最具挑戰性和相關性的應用之一就是處理簡歷以創建知識圖譜。簡歷是密集而復雜的文檔,包含大量有關應聘者職業經歷、技能和資質的信息。然而,要準確有效地提取這些信息,需要先進的 NLP 技術。
這就是 "使用 Mistral-7b-Instruct-v2 for Knowledge Graphs 從簡歷中提取實體 "發揮作用的地方。Mistral-7b-Instruct-v2 是一種先進的語言教學模型,它通過識別和分類關鍵實體(如姓名、組織、職位名稱、技能和教育詳情),提供了一種創新的簡歷解析方法。通過利用 Mistral-7b 的指令功能,我們不僅可以高精度地提取這些實體,還能以有利于創建綜合知識圖譜的方式對它們進行結構化處理。
知識圖譜可以組織和可視化實體之間的關系,提供數據的整體視圖,這對招聘、人才管理和職位匹配等各種應用都有極大的價值。在本博客中,我們將深入探討 Mistral-7b-instruct 如何改變簡歷分析流程、實體提取背后的技術基礎以及從提取的數據中構建知識圖譜的步驟。我們還將探討這項技術對未來人力資源和招聘分析的潛在好處和影響。
這就是典型的知識圖譜:
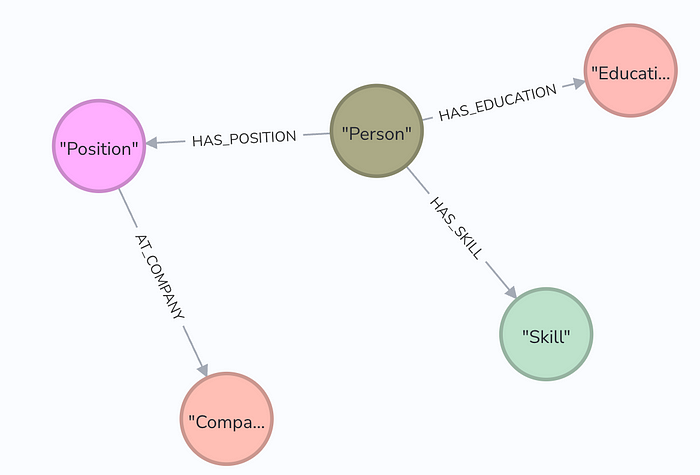
None
由于數據隱私的原因,我們可能無法使用 openAI 或其他可用的 API。那么問題來了,我們該如何使用離線模型來準確地完成這項任務呢?
我們將使用 https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2,這是我們的用例模型。
我們將一步一步地從簡歷中獲取相關實體。
第 1 步:從 PDF 或圖片中提取文本。
我沒有展示實現這一點的代碼,但如果您有 PDF 文件,可以使用 Pymupdf;如果您有簡歷圖片,可以使用 Pytesseract。
簡歷文本是我們的用例:
text="Developer?<span?class=\"hl\">Developer</span>?Developer?-?TATA?CONSULTANTCY?SERVICE?Batavia,?OH?Relevant?course?work??Database?Systems,?Database?Administration,?Database?Security?&?Auditing,?Computer?Security,Computer?Networks,?Programming?&?Software?Development,?IT,?Information?Security?Concept?&?Admin,??IT?System?Acquisition?&?Integration,?Advanced?Web?Development,?and?Ethical?Hacking:?Network?Security?&?Pen?Testing.?Work?Experience?Developer?TATA?CONSULTANTCY?SERVICE?June?2016?to?Present?MRM?(Government?of?ME,?RI,?MS)?Developer?????Working?with?various?technologies?such?as?Java,?JSP,?JSF,?DB2(SQL),?LDAP,?BIRT?report,?Jazz?version?control,?Squirrel?SQL?client,?Hibernate,?CSS,?Linux,?and?Windows.?Work?as?part?of?a?team?that?provide?support?to?enterprise?applications.?Perform?miscellaneous?support?activities?as?requested?by?Management.?Perform?in-depth?research?and?identify?sources?of?production?issues.???SPLUNK?Developer??Supporting?the?Splunk?Operational?environment?for?Busine...OF?COMMERCE?-?BANGKOK,?TH?June?1997?to?May?2001?Skills?Db2?(2?years),?front?end?(2?years),?Java?(2?years),?Linux?(2?years),?Splunk?(2?years),?SQL?(3?years)?Certifications/Licenses?Splunk?Certified?Power?User?V6.3?August?2016?to?Present?CERT-112626?Splunk?Certified?Power?User?V6.x?May?2017?to?Present?CERT-168138?Splunk?Certified?User?V6.x?May?2017?to?Present?CERT?-181476?Driver's?License?Additional?Information?Skills??∑????SQL,?PL/SQL,?Knowledge?of?Data?Modeling,?Experience?on?Oracle?database/RDBMS.??∑????????Database?experience?on?Oracle,?DB2,?SQL?Sever,?MongoDB,?and?MySQL.??∑????????Knowledge?of?tools?including?Splunk,?tableau,?and?wireshark.??∑????????Knowledge?of?SCRUM/AGILE?and?WATERFALL?methodologies.??∑????????Web?technology?included:?HTML5,?CSS3,?XML,?JSON,?JavaScript,?node.js,?NPM,?GIT,?express.js,?jQuery,?Angular,?Bootstrap,?and?Restful?API.??∑????????Working?Knowledge?in?JAVA,?J2EE,?and?PHP.??Operating?system?Experience?included:?Windows,?Mac?OS,?Linux?(Ubuntu,?Mint,?Kali)"第二步:提取實體。
您可以使用 Google Colab 運行下面的代碼,我使用的是 AWS 實例。
為了按照模式實現我們的提取目標,我將使用一系列提示鏈,每個提示鏈只關注一項任務--提取特定實體。通過這種方式,可以避免令牌限制。同時,提取的質量也會很好。
必要的庫:
import?torch
from?transformers?import?AutoTokenizer,?AutoModelForCausalLM下載模型:
model_name?=?"mistralai/Mistral-7B-Instruct-v0.2"
tokenizer?=?AutoTokenizer.from_pretrained(model_name)
model?=?AutoModelForCausalLM.from_pretrained(model_name,trust_remote_code=True,torch_dtype=torch.float16,#?load_in_8bit=True,#?load_in_4bit=True,device_map="auto",use_cache=True,
)設置 Langchain 和配置模型
from?langchain.prompts.few_shot?import?FewShotPromptTemplate
from?langchain.prompts.prompt?import?PromptTemplatefrom?transformers?import?AutoTokenizer,?TextStreamer,?pipeline,LlamaForCausalLM,AutoModelForCausalLM
from?langchain?import?HuggingFacePipeline,?PromptTemplate
DEVICE?=?"cuda:0"?if?torch.cuda.is_available()?else?"cpu"
streamer?=?TextStreamer(tokenizer,?skip_prompt=True,?skip_special_tokens=True)text_pipeline?=?pipeline("text-generation",model=model,tokenizer=tokenizer,max_new_tokens=5000,do_sample=False,repetition_penalty=1.15,streamer=streamer
)llm?=?HuggingFacePipeline(pipeline=text_pipeline,?model_kwargs={"temperature":?0.1})現在我們可以使用 LLM 了、
個人相關信息
提示
person_prompt_tpl="""From?the?Resume?text?for?a?job?aspirant?below,?extract?Entities?strictly?as?instructed?below
1.?First,?look?for?the?Person?Entity?type?in?the?text?and?extract?the?needed?information?defined?below:`id`?property?of?each?entity?must?be?alphanumeric?and?must?be?unique?among?the?entities.?You?will?be?referring?this?property?to?define?the?relationship?between?entities.?NEVER?create?new?entity?types?that?aren't?mentioned?below.?Document?must?be?summarized?and?stored?inside?Person?entity?under?`description`?propertyEntity?Types:label:'Person',id:string,role:string,description:string?//Person?Node
2.?Description?property?should?be?a?crisp?text?summary?and?MUST?NOT?be?more?than?100?characters
3.?If?you?cannot?find?any?information?on?the?entities?&?relationships?above,?it?is?okay?to?return?empty?value.?DO?NOT?create?fictious?data
4.?Do?NOT?create?duplicate?entities
5.?Restrict?yourself?to?extract?only?Person?information.?No?Position,?Company,?Education?or?Skill?information?should?be?focussed.
6.?NEVER?Impute?missing?values
Example?Output?JSON:
{{"entities":?[{{"label":"Person","id":"person1","role":"Prompt?Developer","description":"Prompt?Developer?with?more?than?30?years?of?LLM?experience"}}]}}Question:?Now,?extract?the?Person?for?the?text?below?-{text}Answer:
"""這將幫助我們以 json 格式獲取有關個人的信息,并使用我們顯示的指令。
from?langchain.chains?import?LLMChain
prompttemplate=PromptTemplate(template=person_prompt_tpl,input_variables=['text'])
chain=LLMChain(llm=llm,prompt=prompttemplate)
import?time
t1=time.time()
result=chain(text)
t2=time.time()print(t2-t1)輸出 → 個人信息
{
"entities":[{"label":"Person","id":"developer1","role":"Developer","description":"Experienced?developer?with?expertise?in?Java,?JSP,?JSF,?DB2(SQL),?LDAP,?BIRT?report,?Jazz?version?control,?Squirrel?SQL?client,?Hibernate,?CSS,?Linux,?and?Windows.?Has?worked?as?a?Splunk?Developer?supporting?the?Splunk?Operational?environment?for?Business?Solutions?Unit."}
]
}這太棒了,我們在想要的表單中獲得了關于此人的標簽、身份、角色和描述。
2. 個人教育信息:
提示
edu_prompt_tpl="""From?the?Resume?text?for?a?job?aspirant?below,?extract?Entities?strictly?as?instructed?below
1.?Look?for?Education?entity?type?and?generate?the?information?defined?below:`id`?property?of?each?entity?must?be?alphanumeric?and?must?be?unique?among?the?entities.?You?will?be?referring?this?property?to?define?the?relationship?between?entities.?NEVER?create?other?entity?types?that?aren't?mentioned?below.?You?will?have?to?generate?as?many?entities?as?needed?as?per?the?types?below:Entity?Definition:label:'Education',id:string,degree:string,university:string,graduationDate:string,score:string,url:string?//Education?Node
2.?If?you?cannot?find?any?information?on?the?entities?above,?it?is?okay?to?return?empty?value.?DO?NOT?create?fictious?data
3.?Do?NOT?create?duplicate?entities?or?properties
4.?Strictly?extract?only?Education.?No?Skill?or?other?Entities?should?be?extracted
5.?DO?NOT?MISS?out?any?Education?related?entity
6.?NEVER?Impute?missing?values
Output?JSON?(Strict):
{{"entities":?[{{"label":"Education","id":"education1","degree":"Bachelor?of?Science","graduationDate":"May?2022","score":"0.0"}}]}}Question:?Now,?extract?Education?information?as?mentioned?above?for?the?text?below?-{text}Answer:
"""
from?langchain.chains?import?LLMChain
prompttemplate=PromptTemplate(template=edu_prompt_tpl,input_variables=['text'])
chain=LLMChain(llm=llm,prompt=prompttemplate)
import?time
t1=time.time()
result=chain(text)
t2=time.time()print(t2-t1)產出 → 有關個人的教育情況:
{
"entities":?[{"label":?"Education","id":?"education1","degree":?"Master?of?Science?in?Information?Technology","university":?"KENNESAW?STATE?UNIVERSITY","graduationDate":?"May?2015"},{"label":?"Education","id":?"education2","degree":?"Master?of?Business?Administration?in?International?Business","university":?"AMERICAN?INTER?CONTINENTAL?UNIVERSITY?ATLANTA","graduationDate":?"December?2005"},{"label":?"Education","id":?"education3","degree":?"Bachelor?of?Arts?in?Public?Relations","university":?"THE?UNIVERSITY?OF?THAI?CHAMBER?OF?COMMERCE","graduationDate":?"May?2001"}
]
}這真是令人難以置信,我們得到了包含個人所有教育信息的 json。
3. 個人技能信息
提示
skill_prompt_tpl="""From?the?Resume?text?below,?extract?Entities?strictly?as?instructed?below
1.?Look?for?prominent?Skill?Entities?in?the?text.?The`id`?property?of?each?entity?must?be?alphanumeric?and?must?be?unique?among?the?entities.?NEVER?create?new?entity?types?that?aren't?mentioned?below:Entity?Definition:label:'Skill',id:string,name:string,level:string?//Skill?Node
2.?NEVER?Impute?missing?values
3.?If?you?do?not?find?any?level?information:?assume?it?as?`expert`?if?the?experience?in?that?skill?is?more?than?5?years,?`intermediate`?for?2-5?years?and?`beginner`?otherwise.
Example?Output?Format:
{{"entities":?[{{"label":"Skill","id":"skill1","name":"Neo4j","level":"expert"}},{{"label":"Skill","id":"skill2","name":"Pytorch","level":"expert"}}]}}Question:?Now,?extract?entities?as?mentioned?above?for?the?text?below?-
{text}Answer:
"""
from?langchain.chains?import?LLMChain
prompttemplate=PromptTemplate(template=skill_prompt_tpl,input_variables=['text'])
chain=LLMChain(llm=llm,prompt=prompttemplate)
import?time
t1=time.time()
result=chain(text)
t2=time.time()print(t2-t1)輸出 → 個人技能信息:
{
"entities":[{"label":"Skill","id":"skill1","name":"Java","level":"expert"},{"label":"Skill","id":"skill2","name":"JSP","level":"expert"},{"label":"Skill","id":"skill3","name":"JSF","level":"expert"},{"label":"Skill","id":"skill4","name":"DB2","level":"intermediate"},{"label":"Skill","id":"skill5","name":"Linux","level":"expert"},{"label":"Skill","id":"skill6","name":"Windows","level":"intermediate"},{"label":"Skill","id":"skill7","name":"SQL","level":"expert"},{"label":"Skill","id":"skill8","name":"Oracle","level":"intermediate"},{"label":"Skill","id":"skill9","name":"MySQL","level":"intermediate"},{"label":"Skill","id":"skill10","name":"MongoDB","level":"beginner"},{"label":"Skill","id":"skill11","name":"HTML5","level":"expert"},{"label":"Skill","id":"skill12","name":"CSS3","level":"expert"},
...id":"skill15","name":"JavaScript","level":"expert"},{"label":"Skill","id":"skill16","name":"Node.js","level":"expert"},{"label":"Skill","id":"skill17","name":"NPM","level":"expert"},{"label":"Skill","id":"skill18","name":"GIT","level":"expert"},{"label":"Skill","id":"skill19","name":"express.js","level":"expert"},{"label":"Skill","id":"skill20","name":"jQuery","level":"expert"},{"label":"Skill","id":"skill21","name":"Angular","level":"expert"},{"label":"Skill","id":"skill22","name":"Bootstrap","level":"expert"},{"label":"Skill","id":"skill23","name":"Restful?API","level":"expert"},{"label":"Skill","id":"skill24","name":"PHP","level":"intermediate"},{"label":"Skill","id":"skill25","name":"SCRUM/AGILE","level":"expert"},{"label":"Skill","id":"skill26","name":"WATERFALL?methodologies","level":"expert"}
]
}好了,我們以 Json 的形式獲得了這個人的所有技能、
在這里,我們可以繪制如上圖所示的知識圖譜。
希望對你有用。



















