?摘要:本系列教程專注于自然語言處理(NLP)中的基礎元素,包括去停用詞、詞性標注以及命名實體識別。這些步驟是文本預處理和分析不可或缺的組成部分。我們將通過具體的實例和技術演示,講解如何使用Python及其相關庫(如NLTK)進行有效的文本數據處理。從去除無關詞匯到識別關鍵實體,提供詳細的操作指導和實際應用案例,幫助讀者提升在文本挖掘和數據分析領域的技能。
目錄
一、查看停用詞表
二、過濾停用詞
三、詞性標注
?四、基于NLTK的正則表達式分塊與可視化
五、命名實體識別
六、數據清洗實例
停用詞(Stop words)是指在文本預處理中被移除的常見單詞,因為它們對于文本的分析和處理通常沒有實際意義或貢獻。這些詞往往是語境中的功能性詞匯,如介詞(例如“在”,“對于”)、冠詞(“一個”,“這個”)和連詞(“和”,“但是”)。停用詞的去除有助于減少數據的維度,從而提升文本挖掘算法的效率和準確性,尤其是在進行詞頻統計、關鍵詞提取或構建詞袋模型時。不同語言有不同的停用詞列表,且根據應用場景的不同,停用詞列表的內容也會有所調整。
一、查看停用詞表
NLTK提供的停用詞表涵蓋了多種語言,可以用來移除不同語言文本中的停用詞。



二、過濾停用詞
首先,通過將單詞轉換為小寫來創建列表 test_words,確保單詞的大小寫一致性。接著,將 test_words 轉換為集合 test_words_set,以去除重復元素。然后,使用列表生成式從 test_words_set 中過濾掉英語停用詞,生成新列表 filtered。最后,通過計算 test_words_set 和英語停用詞集合的交集,確認哪些停用詞被從 test_words_set 中移除,以優化文本分析結果。

?
三、詞性標注
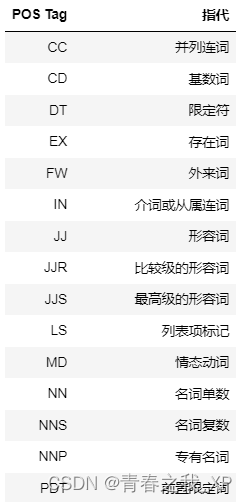
詞性標注是自然語言處理中的一個重要步驟,它涉及將單詞分配到相應的詞類,如名詞、動詞、形容詞等。下表總結了常見的詞性標注符號(POS Tag)及其對應的指代,并對tokens中包含的詞使用nltk中的pos_tag函數進行了詞性標注。


?四、基于NLTK的正則表達式分塊與可視化
使用NLTK庫中的RegexpParser模塊根據指定的語法規則對句子進行分塊。在這個例子中,"the" (DT) - 限定詞、"little" (JJ) - 形容詞、"yellow" (JJ) - 形容詞、"dog" (NN) - 名詞、"died" (VBD) - 動詞,過去式。語法規則表示名詞短語(NP)可以由一個可選的限定詞(DT)、零個或多個形容詞(JJ)和一個名詞(NN)組成。通過這個規則,代碼將句子分成了名詞短語和其他部分。最后,代碼調用matplotlib庫將分塊結果可視化,以便更好地理解和分析句子的結構。

五、命名實體識別
在自然語言處理(NLP)的過程中,首先使用word_tokenize函數將句子分解成基本的語言單位,即單詞列表。隨后,pos_tag函數對這些單獨的單詞進行詞性標注,為每個單詞分配一個對應的詞性縮寫,從而形成單詞及其詞性的元組列表。這些準備工作完成后,ne_chunk函數進一步分析這個已標注的單詞列表,專門識別并標記出文本中的命名實體,如人名、地點、組織名稱等。

六、數據清洗實例
本部分進行了一個文本數據清洗的實例分析,對原始文本數據進行了徹底的數據清洗,以去除噪聲并突出顯示關鍵信息。首先是通過正則表達式去除HTML標簽、特殊符號(如推特句柄和話題標簽)以及貨幣符號。接下來,移除了文本中的超鏈接和一些常見的英文縮寫形式。此外,還去除了多余的空格,并且刪除了長度為1或2的單詞,這通常包括了一些不太具有分析價值的詞。進一步使用了NLTK庫來實現自動分詞,并將分詞后的結果與英語停用詞列表進行對比,從而剔除了諸如“is”、“and”和“the”這樣的常見詞匯。這些詞匯雖然在文本中頻繁出現,但對于理解文本的主題和結構通常幫助不大。最終,經過這些細致的清洗步驟,得到了一個清晰、整潔的文本數據集,這將為后續的分析工作提供堅實的基礎。
?
import re
from nltk.corpus import stopwords
# 輸入數據
s = ' RT @Amila #Test\nTom\'s newly listed Co & Mary\'s unlisted Group to supply tech for nlTK.\nh $TSLA $AAPL https:// t.co/x34afsfQsh'#指定停用詞
cache_english_stopwords = stopwords.words('english')def text_clean(text):print('原始數據:', text, '\n')# 去掉HTML標簽(e.g. &)text_no_special_entities = re.sub(r'\&\w*;|#\w*|@\w*', '', text)print('去掉特殊標簽后的:', text_no_special_entities, '\n')# 去掉一些價值符號text_no_tickers = re.sub(r'\$\w*', '', text_no_special_entities) print('去掉價值符號后的:', text_no_tickers, '\n')# 去掉超鏈接text_no_hyperlinks = re.sub(r'https?:\/\/.*\/\w*', '', text_no_tickers)print('去掉超鏈接后的:', text_no_hyperlinks, '\n')# 去掉一些專門名詞縮寫,簡單來說就是字母比較少的詞text_no_small_words = re.sub(r'\b\w{1,2}\b', '', text_no_hyperlinks) print('去掉專門名詞縮寫后:', text_no_small_words, '\n')# 去掉多余的空格text_no_whitespace = re.sub(r'\s\s+', ' ', text_no_small_words)text_no_whitespace = text_no_whitespace.lstrip(' ') print('去掉空格后的:', text_no_whitespace, '\n')# 分詞tokens = word_tokenize(text_no_whitespace)print('分詞結果:', tokens, '\n') # 去停用詞list_no_stopwords = [i for i in tokens if i not in cache_english_stopwords]print('去停用詞后結果:', list_no_stopwords, '\n')# 過濾后結果text_filtered =' '.join(list_no_stopwords) # ''.join() would join without spaces between words.print('過濾后:', text_filtered)text_clean(s)結果如下:

?
(高級進階))

)

)






)



工廠方法模式(pattern of factory method))



