:::tips
此文檔是LangChain官方教程的實踐總結:
https://python.langchain.com/v0.2/docs/tutorials/rag/
實踐前你需要準備:
OPENAI_API_KEY Generator:根據檢索到的信息和用戶的查詢生成自然語言的回答。
LANGCHAIN_API_KEY 密切監控和評估您的應用程序,以便您可以快速、自信地開發。
py 環境準備(conda)。
:::
簡介
我們將在網站上構建一個 QA 應用程序。我們將使用的具體網站是 Lilian Weng 的 LLM Powered Autonomous Agents 博客文章,該網站允許我們提出有關帖子內容的問題。
一步一步成功
數據收集
我們需要首先加載博客文章內容。為此,我們可以使用 DocumentLoaders,它們是從源加載數據并返回文檔列表的對象。 Document 是一個帶有一些 page_content (str) 和 metadata (dict) 的對象。
在本例中,我們將使用 WebBaseLoader,它使用 urllib 從 Web URL 加載 HTML,并使用 BeautifulSoup 將其解析為文本。我們可以通過 bs_kwargs 將參數傳遞給 BeautifulSoup 解析器來自定義 HTML -> 文本解析(請參閱 BeautifulSoup 文檔)。在這種情況下,只有類為“post-content”、“post-title”或“post-header”的 HTML 標記是相關的,因此我們將刪除所有其他標記。
import bs4
from langchain_community.document_loaders import WebBaseLoader# Only keep post title, headers, and content from the full HTML.
bs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content"))
loader = WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),bs_kwargs={"parse_only": bs4_strainer},
)
docs = loader.load()len(docs[0].page_content)
43131
print(docs[0].page_content[:500])
######LLM Powered Autonomous AgentsDate: June 23, 2023 | Estimated Reading Time: 31 min | Author: Lilian WengBuilding agents with LLM (large language model) as its core controller is a cool concept. Several proof-of-concepts demos, such as AutoGPT, GPT-Engineer and BabyAGI, serve as inspiring examples. The potentiality of LLM extends beyond generating well-written copies, stories, essays and programs; it can be framed as a powerful general problem solver.
Agent System Overview#
In
數據分塊
我們加載的文檔長度超過 42k 個字符。這太長了,無法適應許多模型的上下文窗口。即使對于那些可以在其上下文窗口中容納完整帖子的模型,模型也可能很難在很長的輸入中找到信息。
為了解決這個問題,我們將把 Document 分割成塊以進行嵌入和向量存儲。這應該可以幫助我們在運行時僅檢索博客文章中最相關的部分。
在本例中,我們將把文檔分成 1000 個字符的塊,塊之間有 200 個字符的重疊。重疊有助于降低將語句與與其相關的重要上下文分開的可能性。我們使用 RecursiveCharacterTextSplitter,它將使用常見的分隔符(如換行符)遞歸地分割文檔,直到每個塊的大小合適。這是針對一般文本用例推薦的文本分割器。
我們設置 add_start_index=True ,以便將初始文檔中每個分割文檔開始的字符索引保留為元數據屬性“start_index”。
from langchain_text_splitters import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200, add_start_index=True
)
all_splits = text_splitter.split_documents(docs)len(all_splits)
66
len(all_splits[0].page_content)
969
all_splits[10].metadata
{'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/','start_index': 7056}
文本嵌入+存儲
現在我們需要為 66 個文本塊建立索引,以便我們可以在運行時搜索它們。最常見的方法是嵌入每個文檔分割的內容并將這些嵌入插入向量數據庫(或向量存儲)中。當我們想要搜索分割時,我們采用文本搜索查詢,將其嵌入,并執行某種“相似性”搜索,以識別與查詢嵌入最相似的嵌入的存儲分割。最簡單的相似性度量是余弦相似性——我們測量每對嵌入(高維向量)之間角度的余弦。
我們可以使用 Chroma 矢量存儲和 OpenAIEmbeddings 模型將所有文檔分割嵌入并存儲在單個命令中。
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddingsvectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
檢索
現在讓我們編寫實際的應用邏輯。我們想要創建一個簡單的應用程序,它接受用戶問題,搜索與該問題相關的文檔,將檢索到的文檔和初始問題傳遞給模型,然后返回答案。
首先,我們需要定義搜索文檔的邏輯。 LangChain 定義了一個 Retriever 接口,它包裝了一個索引,該索引可以在給定字符串查詢的情況下返回相關的 Documents 。
最常見的 Retriever 類型是 VectorStoreRetriever,它使用向量存儲的相似性搜索功能來促進檢索。任何 VectorStore 都可以通過 VectorStore.as_retriever() 輕松轉換為 Retriever :
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 6})retrieved_docs = retriever.invoke("What are the approaches to Task Decomposition?")len(retrieved_docs)
6
print(retrieved_docs[0].page_content)
Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.
Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.
生成
我們使用 gpt-3.5-turbo OpenAI 聊天模型,但任何 LangChain LLM 或 ChatModel 都可以替換。
import osos.environ["OPENAI_API_KEY"] = "your openai api key"from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo-0125")
我們使用已簽入 LangChain 提示中心的 RAG 提示。rlm/rag-prompt
from langchain import hubprompt = hub.pull("rlm/rag-prompt")
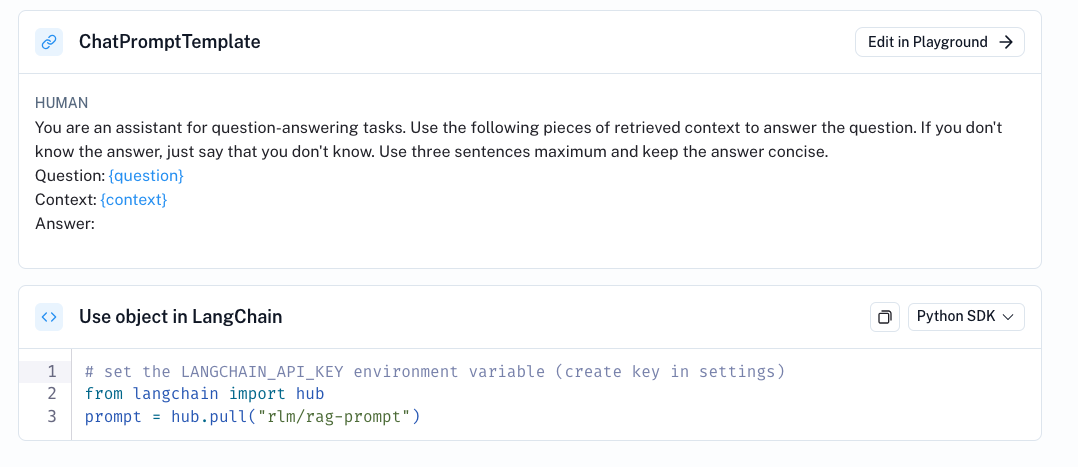
組裝鏈
我們將使用 LCEL Runnable 協議來定義鏈,使我們能夠
- 以透明的方式將組件和功能連接在一起
- 在 LangSmith 中自動追蹤我們的鏈條
- 開箱即用地進行流式、異步和批量呼叫。
import osos.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "your langchain api key"
os.environ["OPENAI_API_KEY"] = "your openai api key"from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo-0125")
import bs4
from langchain import hub
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))),
)
docs = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")def format_docs(docs):return "\n\n".join(doc.page_content for doc in docs)rag_chain = ({"context": retriever | format_docs, "question": RunnablePassthrough()}| prompt| llm| StrOutputParser()
)response = rag_chain.invoke("What is Agent System Overview?")print(response)
調用
我詢問了兩個問題
- What is Task Decomposition?

- What is Agent System Overview?

剖析 LCEL(鏈) 以了解發生了什么
首先:這些組件中的每一個( retriever 、 prompt 、 llm 等)都是 Runnable 的實例。這意味著它們實現相同的方法 - 例如同步和異步 .invoke 、 .stream 或 .batch - 這使它們更容易連接在一起。它們可以通過 | 運算符連接到 RunnableSequence(另一個 Runnable)。
當遇到 | 運算符時,LangChain 會自動將某些對象轉換為可運行對象。此處, format_docs 被轉換為 RunnableLambda,帶有 “context” 和 “question” 的字典被轉換為 RunnableParallel。細節并不重要,重要的是每個對象都是一個 Runnable。
讓我們跟蹤輸入問題如何流經上述可運行對象:
正如我們在上面看到的, prompt 的輸入預計是一個帶有鍵 “context” 和 “question” 的字典。因此,該鏈的第一個元素構建了可運行對象,它將根據輸入問題計算這兩個值:
- retriever | format_docs 將問題傳遞給檢索器,生成Document對象,然后傳遞給 format_docs 生成字符串;
- RunnablePassthrough() 不變地傳遞輸入問題。
然后 chain.invoke(question) 將構建一個格式化的提示,準備進行推理。
最后一步是 llm ,它運行推理,以及 StrOutputParser() ,它只是從 LLM 的輸出消息中提取字符串內容。
遇到的問題
USER_AGENT

不阻塞運行,解決方案:
添加下面代碼
user_agent = "MyPythonApp/1.0 (Language=Python/3.9; Platform=Linux/Ubuntu20.04)"
os.environ["USER_AGENT"] = user_agent
SSLError
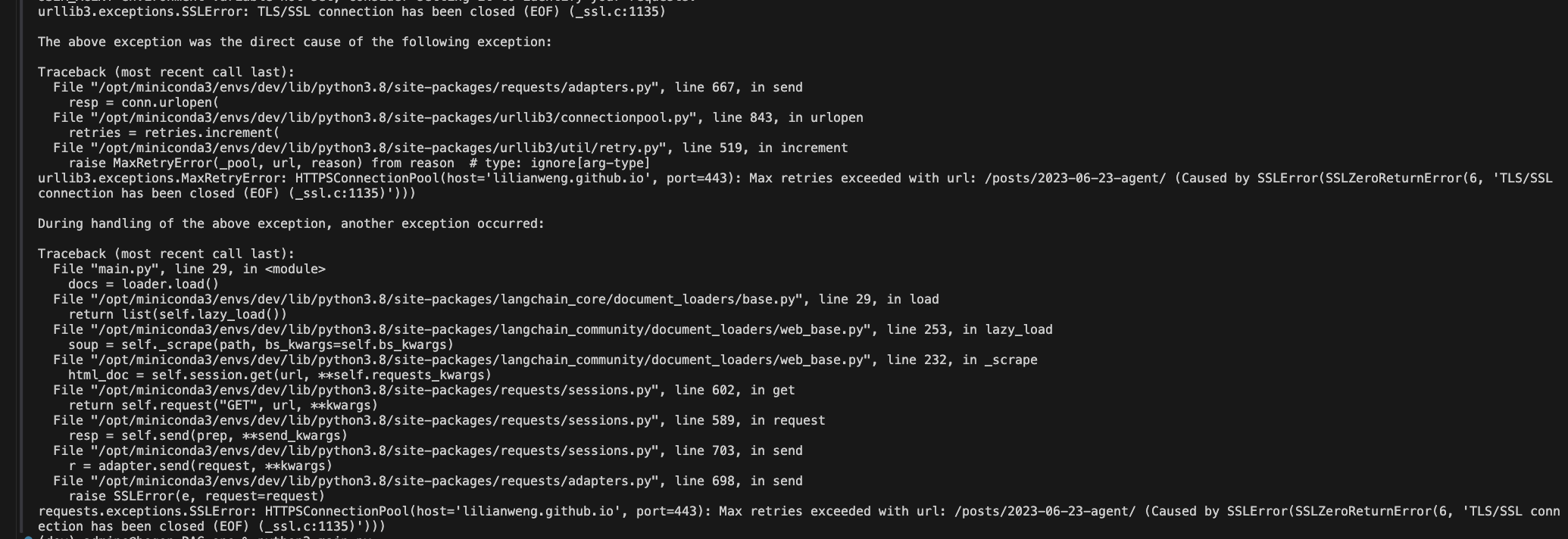
阻塞運行,解決方案:
換個代理。
LangSmith展示

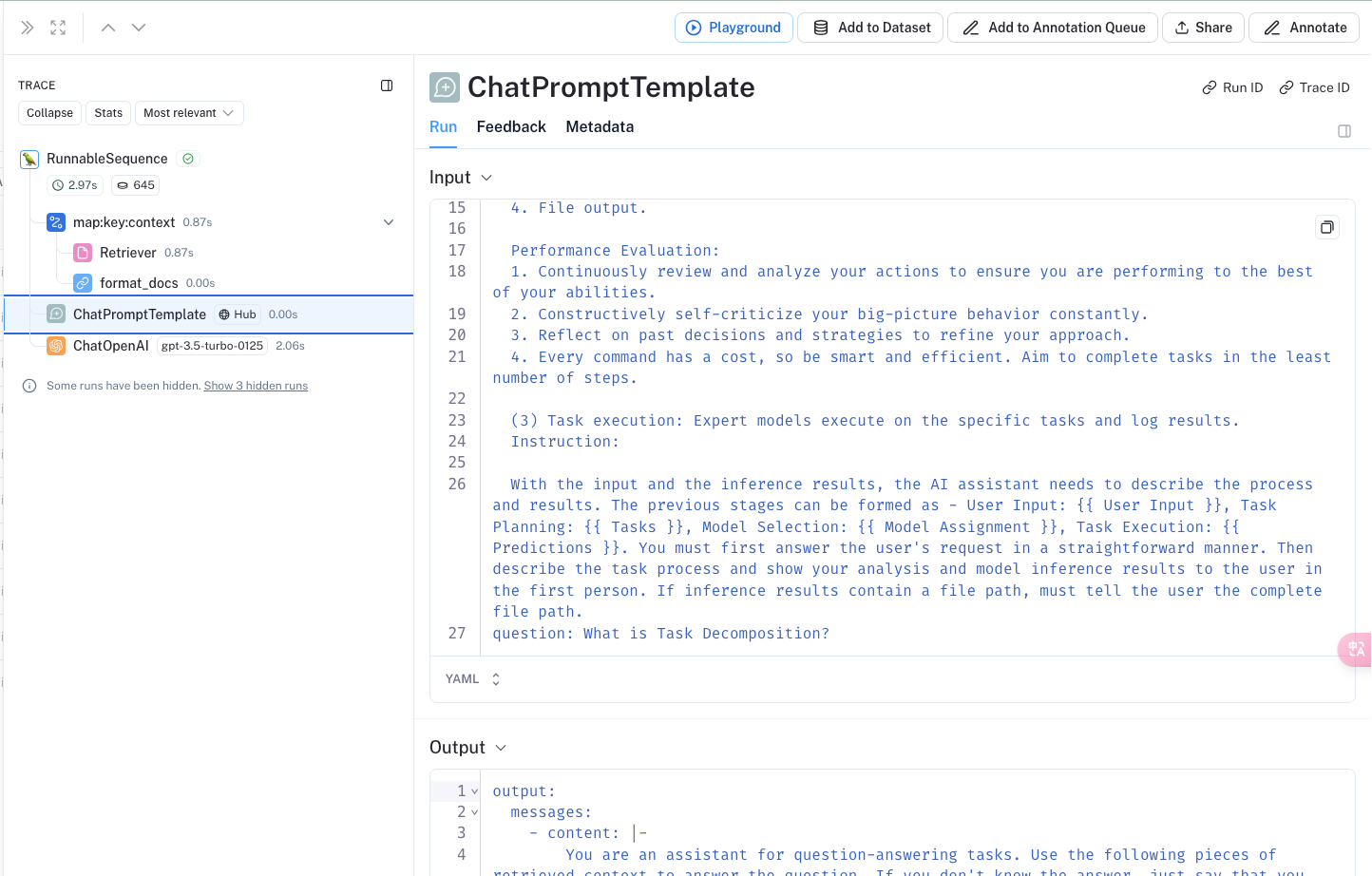
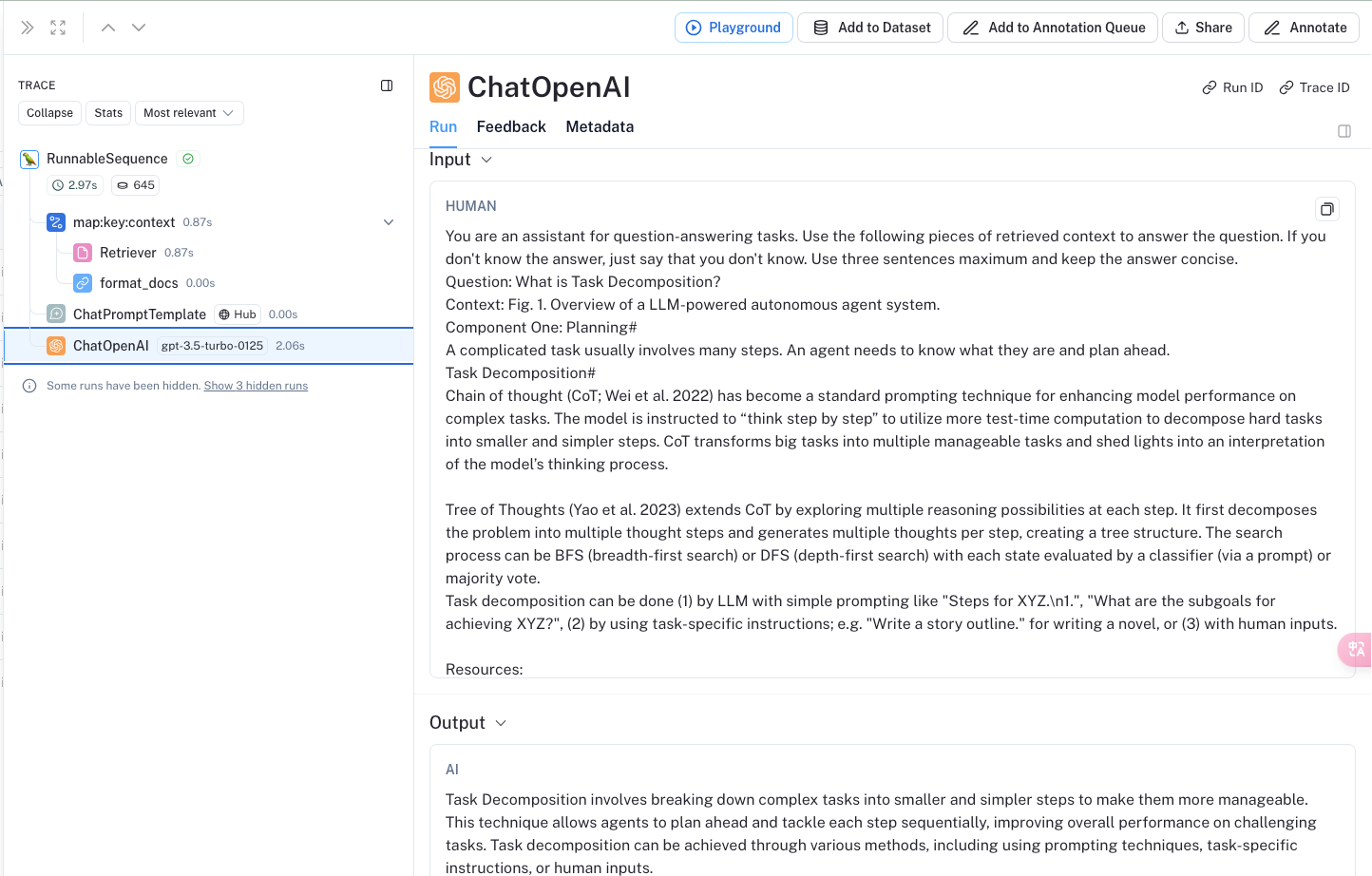

(高級進階))

)

)






)



工廠方法模式(pattern of factory method))


