目錄
引言
Abstract
文獻閱讀
1、題目
2、引言
3、創新點
4、Motivation
5、naive Lite-HRNet
6、Lite-HRNet
7、實驗
深度學習?解讀SAM(Segment Anything Model)
1、SAM Task
2、SAM Model
2.1、Patch Embedding
2.2、Positiona Embedding?
2.3、Transformer Encoder
總結
引言
本周閱讀了一篇高分辨率人體姿態估計的文獻,人體姿勢估計需要高分辨率表示以實現高性能,過去的高效網絡設計主要從兩個角度出發,一個是從分類網絡中借鑒設計,另一個是通過各種技巧中介空間信息損失,鑒于對模型效率的不斷增加需求,研究了在計算資源有限的情況下開發高效的高分辨率模型的問題。
Abstract
This week, I read a literature on human pose estimation. Human pose estimation requires high-resolution representation to achieve high performance. In the past, efficient network design was mainly based on two perspectives: one was to borrow design from classification networks, and the other was to mediate spatial information loss through various techniques. Given the increasing demand for model efficiency, I studied the problem of developing efficient high-resolution models in the context of limited computing resources.
文獻閱讀
1、題目
Lite-HRNet: A Lightweight High-Resolution Network
2、引言
我們提出了一個高效的高分辨率網絡,Lite-HRNet,用于人體姿態估計。首先,我們簡單地將Shuf Chronenet中的高效shuffle塊應用于HRNet(高分辨率網絡),從而獲得比流行的輕量級網絡(如MobileNet,Shuf Chronenet和Small HRNet)更強的性能。我們發現,大量使用的逐點(1 × 1)卷積在shuffle塊成為計算瓶頸。我們引入了一個輕量級的單元,條件信道加權,以取代昂貴的逐點(1 × 1)卷積在shuf?信道加權的復雜度與信道數成線性關系,低于逐點卷積的二次時間復雜度。我們的解決方案從所有通道和多個分辨率中學習權重,這些權重在HRNet的并行分支中很容易獲得。它使用權重作為跨通道和分辨率交換信息的橋梁,補償逐點(1 × 1)卷積所扮演的角色。Lite-HRNet在人體姿態估計方面表現出優于流行的輕量級網絡的上級結果。此外,Lite-HRNet可以以同樣的輕量級方式輕松應用于語義分割任務。
3、創新點
- 在Lite-HRNet中,通過使用輕量級的條件通道加權操作替代1×1卷積,提高了網絡的性能并減少了計算復雜度。
- 通過引入空間權重和多分辨率權重,有效地提高了網絡的性能,尤其是在COCO和MPII數據集上取得了顯著的AP提升。
- Lite-HRNet通過交叉分辨率權重計算,實現了跨通道和分辨率的信息交換,進一步提升了網絡的容量和性能
4、Motivation
人體姿態估計一般比較依賴于高分辨率的特征表示以獲得較好的性能,基于對模型性能日益增長的需求,本文研究了在計算資源有限的情況下開發高效高分辨率模型的問題。HRNet有很強的表示能力,很適用于對位置敏感的應用,比如語義分割、人體姿態估計和目標檢測。通過簡單地將ShuffleNet中的Shuffle Block應用于Small HRNet,即可得到一個輕量級的HRNet,并且可以獲得超越ShuffleNet、MobileNet的性能。Naive Lite-HRNet的shuffle block存在的大量的?1×1?卷積操作成為了計算瓶頸,因此,如何能替換掉成本較高的?1×1?Conv并且保持甚至取得超越其性能是本文要解決的核心問題。為此,作者提出名為?Lite-HRNet 的網絡,在Lite-HRNet中使用conditional channel weighting模塊替代1×1卷積,以進一步提高網絡的計算效率。
5、naive Lite-HRNet
Shuffle blocks.?ShuffleNet V2 中的 shuffle block 首先將通道分成兩個分區。一個分區經過一個(1×1卷積、3×3 depthwise 卷積和1×1卷積)序列,其輸出與另一個分區連接。最后,串接的通道被 shuffled,如下圖 (a) 所示
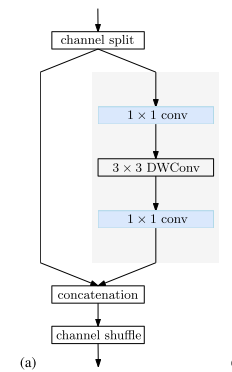
?
HRNet. HRNet 從一個高分辨率卷積 stem 作為 first stage 開始,逐步添加一個高到低分辨率的 stream 作為新的 stage。多分辨率流是并行連接的。主體main body 由一系列 stage 組成。在每個stage,跨分辨率的信息都會反復交換。我們遵循 Small HRNet 的設計,使用更少的層和更小的寬度來形成我們的網絡。Small HRNet 的 stem 由兩個 stride=2 的 3×3 卷積組成。主體中的每個 stage 包含一系列殘差塊和一個多分辨率融合。下圖顯示了Small HRNet 的結構。
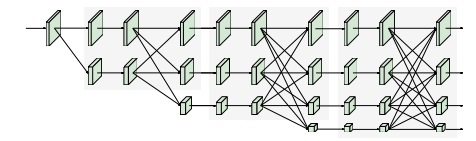
?
Simple combination.?將 shuffle block 替換 Small HRNet 主干中的第二個3×3卷積,并替換所有殘差塊(由兩個3×3卷積形成)。多分辨率融合中的一般卷積被可分離卷積所取代,從而形成一個 naive Lite-HRNet。?
6、Lite-HRNet
(1) 1×1convolution is costly.
1×1卷積在每個位置執行矩陣向量乘法:
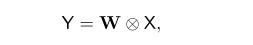
?
其中 X 和 Y 是輸入和輸出 map,W 是1×1卷積kernel。因為shuffle操作和depthwise卷積不做跨通道的信息交換,所以1×1卷積在跨通道交換信息方面起關鍵作用。
C個通道的1×1卷積具有二次時間復雜度 (?? ) ,3×3 depthwise 卷積具有線性時間復雜度 (
?) 。在 shuffle block 中,兩個1×1卷積的復雜度遠高于深度卷積:
??>?
?,通常情況下 C > 5 。表2表示了1×1卷積和depthwise卷積之間的復雜性的比較。
(2) Conditional channel weighting
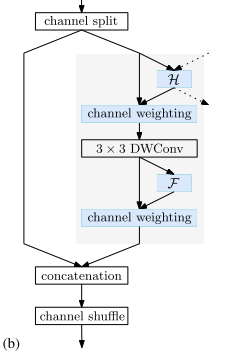
為了進一步降低計算的復雜度,作者提出使用element-wise multiplication operation即Conditional channel weighting來代替?1×1?卷積,此網絡命名為 Lite-HRNet。
對于Lite-HRNet中的第 s 個分支,conditional channel weighting可以表示為:
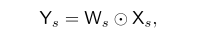
其中,???是?
? 的矩陣,表示weight map,會從不同分辨率的feature map中計算得到,可以起到一個跨通道、跨分辨率的特征交互的作用權重矩陣,它由Cross-resolution Weight Computation和Spatial Weight Computation這兩種方法進行計算。⊙表示元素乘法操作。?
Conditional Channel Weighting的時間復雜度為 ?,遠低于1×1卷積。
使用Conditional Channel Weighting操作替換掉1×1卷積后的Shuffle Block結構如下圖?(b)?所示:
?
(3) Cross-resolution weight computation
在網絡的第 s?個Stage中有 s?個平行分支,每個分支的feature map分辨率不同,共有 s?個weight map分別與這些分支對應,將這 s?個weight map記作??。?
使用 ??表示 s?個分支的feature map,
??表示分辨率最高的feature map,相應地,
??表示第 s?個分辨率的feature map,則有:
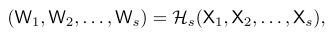
?
其中,??是一個輕量級的函數,它的具體實現過程為:
首先對 ??進行Adaptive Average Pooling(AAP)操作,輸出的feature map尺寸為
??,即:
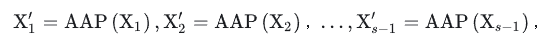
將 AAP 操作得到的{???}和特征
??進行Concat操作,得到?
??;?
對 ??依次進行1×1卷積、ReLU、1×1卷積、sigmoid操作,將輸出結果記作
?,即:
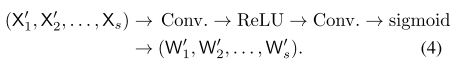
通過上述操作,可以得到 s 個分支的權重矩陣。某個分支中特定位置的權重是由經過AAP操作得到的 ??中同樣位置的值決定的,即由多個分辨率的特征得到。?
之后對 ??使用最近鄰進行上采樣操作,使得權重的分辨率與它們所對應分支的feature map分辨率一致,用于隨后的element-wise channel weighting。
對于第 s 個分支中位置 i 處的特征值,計算公式為:
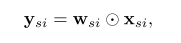
??與所有分支的feature map在位置
??處對應的特征區域有關,因此?
? 包含多種分辨率的特征,通過上式得到的?
? 包含多尺度的特征。?
??在操作時,先使用AAP操作減小了 {
?} 的分辨率,因此在后面的卷積運算中不會引入很大的計算量。
class CrossResolutionWeighting(nn.Module):def __init__(self,channels,ratio=16,conv_cfg=None,norm_cfg=None,act_cfg=(dict(type='ReLU'), dict(type='Sigmoid'))):super().__init__()if isinstance(act_cfg, dict):act_cfg = (act_cfg, act_cfg)assert len(act_cfg) == 2assert mmcv.is_tuple_of(act_cfg, dict)self.channels = channelstotal_channel = sum(channels)self.conv1 = ConvModule(in_channels=total_channel,out_channels=int(total_channel / ratio),kernel_size=1,stride=1,conv_cfg=conv_cfg,norm_cfg=norm_cfg,act_cfg=act_cfg[0])self.conv2 = ConvModule(in_channels=int(total_channel / ratio),out_channels=total_channel,kernel_size=1,stride=1,conv_cfg=conv_cfg,norm_cfg=norm_cfg,act_cfg=act_cfg[1])def forward(self, x):# mini_size即為當前stage中最小分辨率的shape:H_s, W_smini_size = x[-1].size()[-2:] # H_s, W_s# 將所有stage的input均壓縮至最小分辨率,由于最小的一個stage的分辨率已經是最小的了# 因此不需要進行壓縮out = [F.adaptive_avg_pool2d(s, mini_size) for s in x[:-1]] + [x[-1]]out = torch.cat(out, dim=1)out = self.conv1(out) # ReLu激活out = self.conv2(out) # sigmoid激活out = torch.split(out, self.channels, dim=1)out = [# s為原輸入# a為權重,并通過最近鄰插值還原回原輸入尺度s * F.interpolate(a, size=s.size()[-2:], mode='nearest')for s, a in zip(x, out)]return out(4) Spatial Weight Computation
本文在引入跨分辨率信息后,還引入了一個單分辨率內部空間域的增強操作:
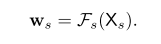 ?
?
權重矩陣???的值在所有空間域位置處都相等,其中
??的實現過程為:?
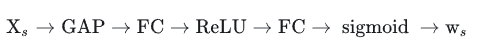 ?
?
其中,Global Average Pooling(GAP)的作用是聚集所有位置的特征。
得到權重矩陣后,根據下式得到第 s 個分支位置 ??處的輸出特征:
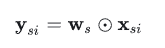 ?
?
根據權重矩陣的計算過程可知,輸出特征的每個元素都和該分支所有輸入特征有關。
class SpatialWeighting(nn.Module):def __init__(self,channels,ratio=16,conv_cfg=None,act_cfg=(dict(type='ReLU'), dict(type='Sigmoid'))):super().__init__()if isinstance(act_cfg, dict):act_cfg = (act_cfg, act_cfg)assert len(act_cfg) == 2assert mmcv.is_tuple_of(act_cfg, dict)self.global_avgpool = nn.AdaptiveAvgPool2d(1)self.conv1 = ConvModule(in_channels=channels,out_channels=int(channels / ratio),kernel_size=1,stride=1,conv_cfg=conv_cfg,act_cfg=act_cfg[0])self.conv2 = ConvModule(in_channels=int(channels / ratio),out_channels=channels,kernel_size=1,stride=1,conv_cfg=conv_cfg,act_cfg=act_cfg[1])def forward(self, x):out = self.global_avgpool(x)out = self.conv1(out)out = self.conv2(out)return x * out?(5) 計算量分析
假設網絡中的某個Stage包含2個分支,輸入特征為X1和X2,X1的尺寸為64×64×40,X2的尺寸為32×32×80。則:1×1卷積、3×3的Depthwise卷積、不同類型的Conditional Channel Weighting(CCW)操作的計算量如下表所示:
 ?
?
由上圖可知,CCW的計算量遠小于1×1卷積。再由(3)和(4)中權重矩陣的計算過程可知,CCW也可以完成多個通道的信息融合,說明了CCW代替1×1卷積以減少網絡的計算需求的有效性。
(6) 實例 Lite-HRNet?
 ?
?
在stem中,有1個步長為2的3×3卷積和1個Shufflt Block。接下來的3個Stage中,每個Stage均包含2個CCW模塊和1個融合模塊。上表中“resolution branch”一欄中表示該Stage包含的feature map的分辨率信息。在上表的最后兩列中,Lite-HRNet-N中的N表示網絡的層數。?
7、實驗
在COCO與MPII數據集上對所提方法的性能進行了評估,參照主流top-down框架,直接估計K個熱圖。
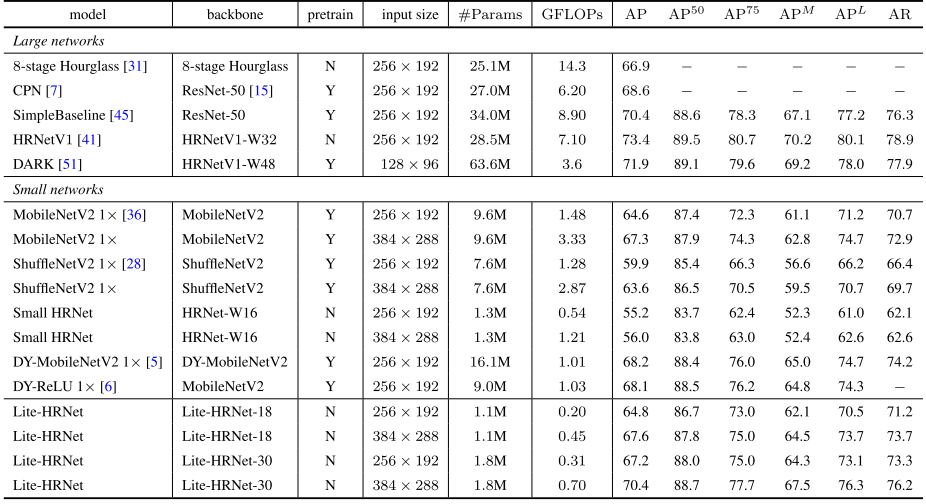 ?
?
上圖給出了COCO驗證集上的性能對比,從中可以看到:
- 輸入為256×192的條件下,Lite-HRNet-30取得了67.2AP指標,優于其他輕量化方案。
- 相比MobileNetV2,性能提升2.6AP,且僅需20%GFLOOs與參數量。
- 相比ShuffleNetV2,,Lite-HRNet-18與Lite-HRNet-30分別獲得了4.9與7 3指標提升,同時具有更低的計算量。
- ?相比Small HRNet-W16,?Lite-HRNet指標提升超10AP。
- 相比大網絡(比如Hourglass、 CPN),所提方法可以取得相當的AP指標且具有極低復雜度。
- Lite HRNet 18與Lite-HRNet 30分別取得了67.6與70.4AP指標。
- 受益于所提高效條件通道加權模塊,Lite-HRNet取得了更佳的精度-計算復雜度均衡。
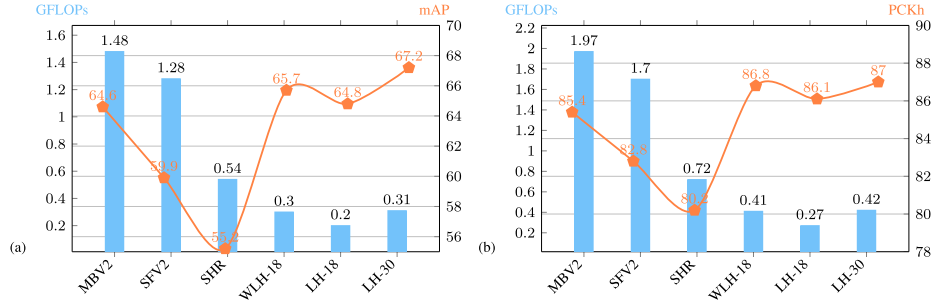 ?
?
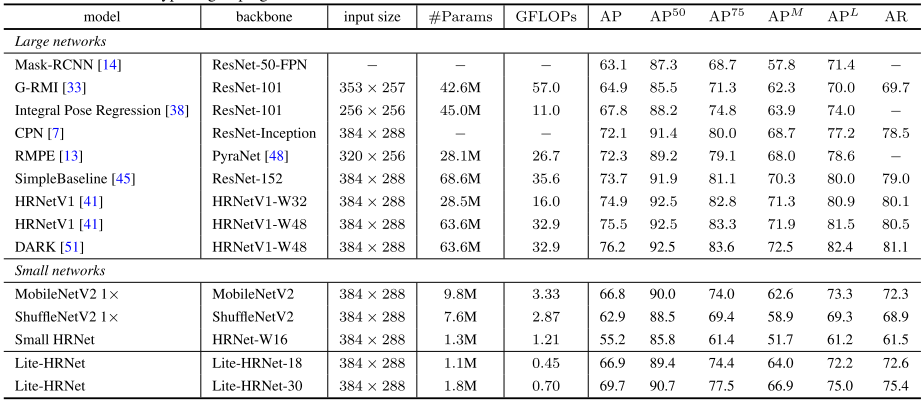 ?
?
?上表給出了COCO-test-dev數據集上的性能對比,可以看到:
- Lite-HRNet-30取得了69.7AP指標, 顯著優于其他輕量網絡,同時具有更低FLOPs和參數量。
- Lite-HRNet-30取得了優于Mask-RCNN、G_ RMI、IPR等大網絡的性能。
- 盡管相比其他大網絡,所提方法仍存在性能差異,但所提方法具有超低的GFLOPs與參數量。
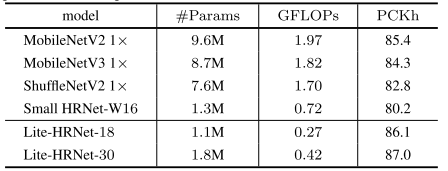 ?
?
上表給出了MPII驗證集上的性能對比,可以看到:
- 相比MobileNet2、?MobileNetV3、ShuffleNetV2、Small HRNet等輕量化模型,所提Lite-HRNet-18取得了更高的精度,同時具有更低的計算復雜度。
- 繼續提升模型大小可以進一 步提升模型的精度,比如Lite-HRNet-30取得了87.0 PCKh@0.5的指標。
 ?
?
最后,所提方法遷移到語義分割任務上的效果,見上表。可以看到:
- Lite-HRNet-18以1.95GFLOPs計算量取得72.8%的mloU指標。
- Lite-HRNet-30以3.02GFLOPs計算量取得75.3%的mloU指標。
- 所提方法優于手工設計網絡(如ICNet、BiSeNet、DFANet等)與NAS網絡(比如CAS、 GAS、FasterSeg等), 同時與SwifNetRN-18性能相當,但具有更低的計算量。
深度學習?解讀SAM(Segment Anything Model)
SAM(Segment Anything Model),顧名思義,即為分割一切!該模型由Facebook的Meta AI實驗室,能夠根據文本指令或圖像識別,實現對任意物體的識別與分割。
1、SAM Task
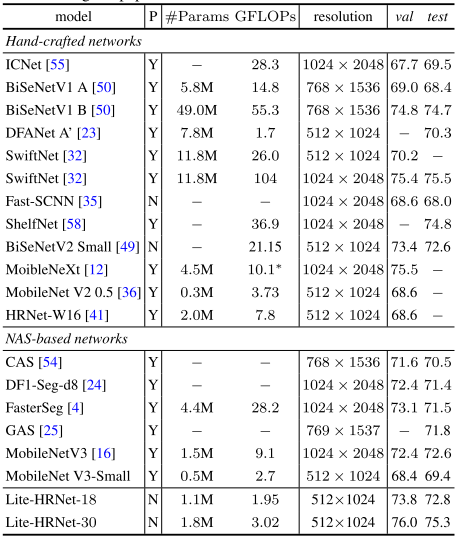
SAM借鑒了NLP領域的Prompt策略,通過給圖像分割任務提供Prompt提示來完成任意目標的快速分割。Prompt類型可以是「前景/背景點集、粗略的框或遮罩、任意形式的文本或者任何指示圖像中需要進行分割」的信息。如下圖(a)所示,模型的輸入是原始的圖像和一些prompt,目標是輸出"valid"的分割,所謂valid,就是當prompt的指向是模糊時,模型能夠輸出至少其中一個mask。
這樣,可以是的SAM能夠適配各種下游任務。例如,給定一個貓的邊界框,SAM能夠輸出其mask,從而和實例分割任務搭配起來。
2、SAM Model
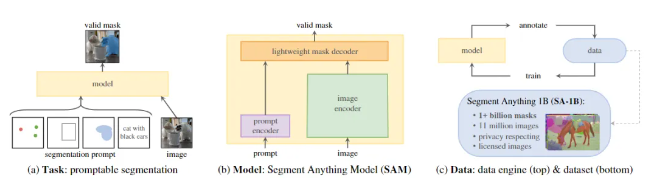
如下圖所示,SAM模型包含三個核心組件,Image Encoder、Prompt Encoder和Mask Decoder。圖像經過Image Encoder編碼,Prompt提示經過Prompt Encoder編碼,兩部分Embedding再經過一個輕量化的Mask Decoder得到融合后的特征。其中,Encoder部分使用的是已有模型,Decoder部分使用Transformer。

Image Encoder
Image Encoder的作用是把圖像映射到特征空間,整體過程如下圖所示。
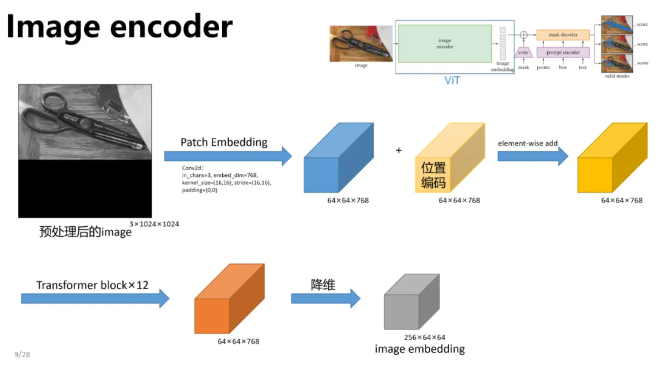
本質上這個Encoder可以是任何網絡結構,在這里使用的是微調的Detectron的ViT,當然它也可以被改成傳統的卷積結構,非常合理。?
2.1、Patch Embedding
輸入圖像通過一個卷積base,將圖像劃分為16x16的patches,步長也為16,這樣feature map的尺寸就縮小了16倍,同時channel從3映射到768。Patch Embedding示意圖如下所示。
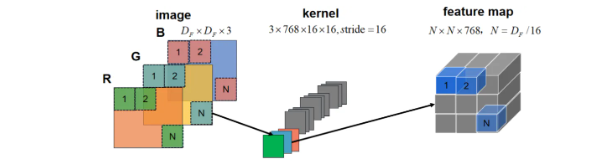
圖像大小決定了patch的數量。?
'''
將輸入的圖像轉換為序列化的特征向量
'''
class PatchEmbed(nn.Module):def __init__(self,# 卷積核大小# 這里是 (16, 16),意味著圖像將被劃分為16x16的patcheskernel_size: Tuple[int, int] = (16, 16),# 卷積的步長,與kernel_size相同,即(16, 16),# 意味著每一步移動16個像素,這樣圖像的尺寸就會減少到原來的1/16stride: Tuple[int, int] = (16, 16),# 控制邊緣填充,這里設置為 (0, 0),意味著沒有額外的填充padding: Tuple[int, int] = (0, 0),# 輸入圖像的通道數,通常為3(RGB圖像)in_chans: int = 3,# 輸出的特征維度,也就是每個patch被編碼為的向量的長度,這里設置為768embed_dim: int = 768,) -> None:'''初始化這個子類實例的屬性'''# PatchEmbed的子類,繼承自nn.Module,用于構建神經網絡模塊super().__init__()self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding)'''前向傳播:接收輸入張量 x,形狀 (B, C, H, W),其中,- B表示批次大小- C 是輸入通道數- H 和 W 是圖像的高度和寬度'''def forward(self, x: torch.Tensor) -> torch.Tensor:# 卷積,將輸入的通道數從 in_chans 轉換為 embed_dimx = self.proj(x)# 將張量的維度順序從 (B, C, H, W) 調整為 (B, H, W, C)x = x.permute(0, 2, 3, 1)return x?Patch Embedding過程在Vision Transformer結構圖中對應下圖所示。
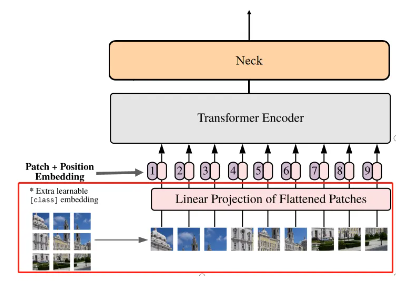
2.2、Positiona Embedding?
經過Patch Embedding后輸出tokens需要加入位置編碼,以保留圖像的空間信息。位置編碼可以理解為一張map,map的行數與輸入序列個數相同,每一行代表一個向量,向量的維度和輸入序列tokens的維度相同,位置編碼的操作是sum,所以維度依舊保持不變。
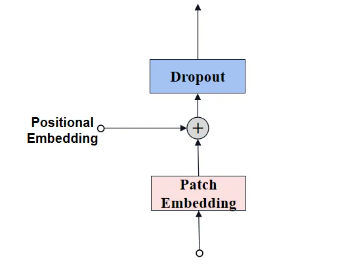
圖像尺寸是1024,因此patch的數量是1024/16=64。
# 在ImageEncoderViT的__init__定義
if use_abs_pos:# 使用預訓練圖像大小初始化絕對位置嵌入self.pos_embed = nn.Parameter(torch.zeros(1, img_size // patch_size, img_size // patch_size, embed_dim))
# 在ImageEncoderViT的forward添加位置編碼
if self.pos_embed is not None:x = x + self.pos_embedPositiona Embedding過程在結構圖中對應的部分:
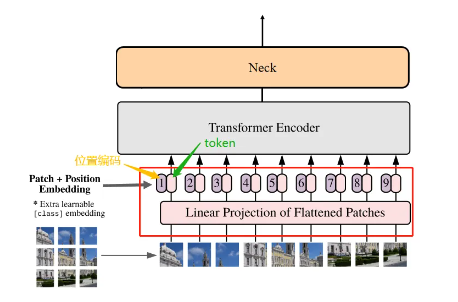
2.3、Transformer Encoder
feature map通過16個Transformer Block,其中12個Block使用了基于Window Partition(就是把特征圖分成14*14的windows做局部的Attention)的注意力機制,以處理局部信息。另外4個Block是全局注意力模塊,它們穿插在Window Partition模塊之間,以捕捉圖像的全局上下文。
# 在ImageEncoderViT的__init__定義
# -----Transformer Encoder-----
# 初始化一個ModuleList,用于存儲Block實例
self.blocks = nn.ModuleList()
# 循環創建Block,depth是Transformer Encoder層數
for i in range(depth):# 創建單個Blockblock = Block(# 輸入的通道數,即每個patch編碼后的向量維度dim=embed_dim,# 自注意力機制中的注意力頭數num_heads=num_heads,# MLP層的通道數相對于輸入通道數的比例mlp_ratio=mlp_ratio,# 是否在QKV全連接層中使用偏置qkv_bias=qkv_bias,# 歸一化層norm_layer=norm_layer,# 激活函數act_layer=act_layer,# 是否使用相對位置編碼use_rel_pos=use_rel_pos,# 相對位置編碼的初始化設置rel_pos_zero_init=rel_pos_zero_init,# 如果當前Block不是全局注意力層,則使用窗口大小,否則使用0window_size=window_size if i not in global_attn_indexes else 0,# 輸入特征的尺寸,基于原始圖像大小和patch大小計算得出input_size=(img_size // patch_size, img_size // patch_size),)# 將創建的Block對象添加到self.blocks列表中self.blocks.append(block)
# -----Transformer Encoder-----Transformer Encoder過程在結構圖中對應的部分:
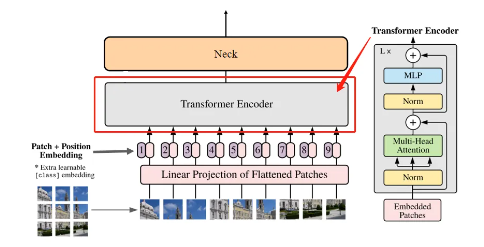
Encoder Block
如上圖右所示,Encoder Block從低到高主要由LayerNorm 、Multi-Head Attention和MLP構成。
class Block(nn.Module):def __init__(self,dim: int, # 輸入通道數num_heads: int, # attention中head的個數mlp_ratio: float = 4.0, # MLP層的通道數相對于輸入通道數的比例。qkv_bias: bool = True, # 如果為True,QKV全連接層包含偏置。norm_layer: Type[nn.Module] = nn.LayerNorm, # 歸一化層act_layer: Type[nn.Module] = nn.GELU, # 激活層use_rel_pos: bool = False, # 是否使用相對位置編碼rel_pos_zero_init: bool = True, # 相對位置編碼的初始化設置window_size: int = 0, # 注意力層的窗口大小input_size: Optional[Tuple[int, int]] = None, # 輸入特征的尺寸) -> None:super().__init__()self.norm1 = norm_layer(dim) # 第一個歸一化層,用于注意力層self.attn = Attention( # Multi-Head Attentiondim,num_heads=num_heads,qkv_bias=qkv_bias,use_rel_pos=use_rel_pos,rel_pos_zero_init=rel_pos_zero_init,input_size=input_size if window_size == 0 else (window_size, window_size),)self.norm2 = norm_layer(dim) #第二個歸一化層,用于MLP之前# MLPself.mlp = MLPBlock(embedding_dim=dim, mlp_dim=int(dim * mlp_ratio), act=act_layer)self.window_size = window_size# 前向傳播def forward(self, x: torch.Tensor) -> torch.Tensor:# 保存輸入張量的副本shortcut = x# 對輸入張量應用第一個歸一化層x = self.norm1(x)# Window partition 對X進行paddingif self.window_size > 0:H, W = x.shape[1], x.shape[2]x, pad_hw = window_partition(x, self.window_size)# Multi-Head Attentionx = self.attn(x)# 如果 window_size > 0,使用window_unpartition去除窗口分區的padding,恢復原始尺寸if self.window_size > 0:x = window_unpartition(x, self.window_size, pad_hw, (H, W))# 將注意力層的輸出與輸入張量相加,實現殘差連接x = shortcut + x# 對經過第二個歸一化層的張量應用MLP層,再次使用殘差連接x = x + self.mlp(self.norm2(x))# 返回最終的張量 xreturn x
?Partition操作
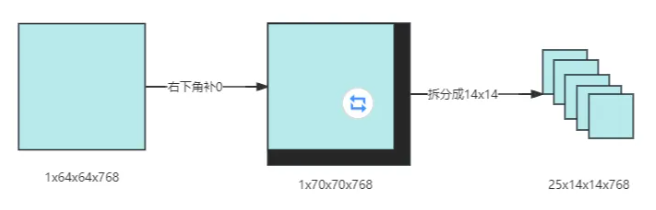
在非全局注意力的Block中,為了適應14x14的窗口大小,輸入特征圖需要進行補邊(padding)和拆分操作。具體流程如下:
-
輸入特征圖:輸入特征圖的初始尺寸為 1x64x64x768。
-
確定最小可整除尺寸:窗口大小為14*14,要找到能夠被14整除的最小特征圖尺寸。對于寬度和高度,我們需要找到大于等于64且能被14整除的最小數。這兩個數分別是70(64+6)和70(64+6),所以最小可整除特征圖的尺寸是 1x70x70x768。
-
padding:為了將特征圖尺寸從 64x64 擴展到 70x70,我們需要在右下角填充 6x6 的區域,因為70-64=6。這種padding方式確保了窗口可以在特征圖的邊緣正確地劃分。
-
拆分特征圖:將padding后的特征圖1x70x70x768按照窗口大小14x14進行拆分。因為70/14=5,所以特征圖可以被拆分為 5x5個14x14的窗口,總共5x5=25個窗口。每個窗口的尺寸為14x14x768。
如下圖所示
# 將輸入張量x分割成指定大小的窗口
def window_partition(x: torch.Tensor, window_size: int) -> Tuple[torch.Tensor, Tuple[int, int]]:# 獲取輸入張量形狀# B表示批次大小,H和W表示高和寬,C表示通道數B, H, W, C = x.shape# 計算填充高度和寬度 pad_h 和 pad_w,以使得輸入尺寸能被window_size整除# 避免在分割時產生非完整的窗口pad_h = (window_size - H % window_size) % window_sizepad_w = (window_size - W % window_size) % window_size# 如果需要填充,使用F.pad函數在寬度和高度方向上進行填充if pad_h > 0 or pad_w > 0:x = F.pad(x, (0, 0, 0, pad_w, 0, pad_h))# 更新填充后張量的高度和寬度 Hp 和 WpHp, Wp = H + pad_h, W + pad_w# 張量重塑為:B,Hp/S,S,Wp/S,S,C,這樣可以將輸入張量分割成多個窗口x = x.view(B, Hp // window_size, window_size, Wp // window_size, window_size, C)# 調整張量的形狀,使其由B,Hp/S,Wp/S,S,S,C-->B*Hp*Wp/(S*S),S,S,C# 這樣每個窗口都在張量的連續部分windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)# 返回一個包含所有窗口的張量和原始張量的填充后尺寸 (Hp, Wp)return windows, (Hp, Wp)?Unpartition操作
在非全局注意力的Block中,將attention層輸出的特征圖1x70x70x768轉化為1x64x64x768的特征圖,實際上是通過切片操作x = x[:1, :64, :64, :],從1x70x70x768的特征圖中取出左上角的1x64x64x768部分。

# 用于將window_partition函數分割的窗口重新組合回原始尺寸的張量
def window_unpartition(# 獲取輸入張量 windows 的形狀,以及窗口大小 window_sizewindows: torch.Tensor, window_size: int, pad_hw: Tuple[int, int], hw: Tuple[int, int]
) -> torch.Tensor:# 原始尺寸的填充高度和寬度Hp, Wp = pad_hw# 原始尺寸的無填充高度和寬度H, W = hw# 從窗口張量的總大小中計算出原始批量大小 BB = windows.shape[0] // (Hp * Wp // window_size // window_size)# 重塑窗口張量:B*Hp*Wp/(S*S),S,S,C-->B,Hp/S,Wp/S,S,S,Cx = windows.view(B, Hp // window_size, Wp // window_size, window_size, window_size, -1)# 再次重塑張量:B,Hp/S,Wp/S,S,S,C-->B,Hp,Wp,Cx = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, Hp, Wp, -1)# 如果原始尺寸小于填充后的尺寸if Hp > H or Wp > W:# 通過切片 x[:, :H, :W, :] 去除填充部分,只保留原始大小的區域x = x[:, :H, :W, :].contiguous()# B,H,W,C# 返回合并后的張量,其形狀為 (B,H,W,C),即原始的批量大小、高度、寬度和通道數return xEncoder Block過程如下圖所示:
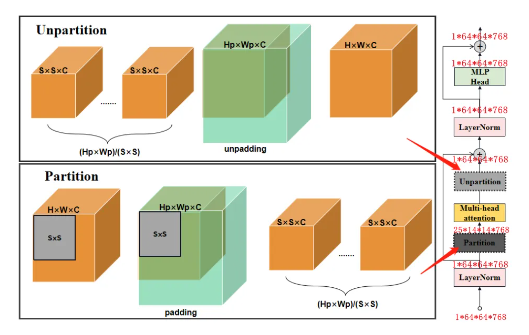
window_partition將輸入特征的尺寸從(H, W)調整為(S, S)的窗口,其中S是窗口大小。這種調整是為了在多頭注意力(Multi-Head Attention)中將相對位置嵌入添加到注意力圖(attn)。然而,并非所有Transformer Block都需要在注意力圖中嵌入相對位置信息。 window_unpartition 函數的作用是將經過注意力計算的窗口特征重新組合回原始尺寸(S×S–>H×W)。 Hp和Wp是S的整數倍。?
Multi-Head Attention
先來看Attention,結構如下圖所示。
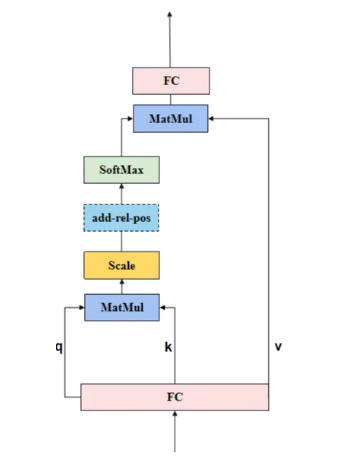
Attention中q、k和v的作用:

代碼實現如下:
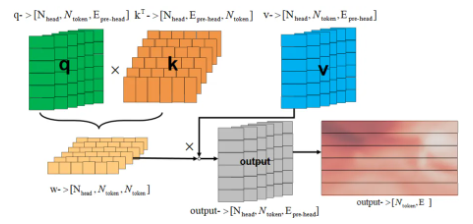
class Attention(nn.Module):"""Multi-head Attention block with relative position embeddings."""def __init__(self,dim: int, # 輸入通道數num_heads: int = 8, # head數目qkv_bias: bool = True, # 是否在QKV線性變換中使用偏置項,默認為Trueuse_rel_pos: bool = False, #是否使用相對位置編碼,默認為Falserel_pos_zero_init: bool = True, #如果使用相對位置編碼,是否以零初始化,默認為Trueinput_size: Optional[Tuple[int, int]] = None, # 可選參數,用于指定相對位置編碼的尺寸,只有在使用相對位置編碼時才需要) -> None:super().__init__()self.num_heads = num_heads #輸入head數目head_dim = dim // num_heads #每個head維度self.scale = head_dim**-0.5 #用于縮放注意力得分的因子,以避免數值溢出,取值為head_dim的平方根的倒數#一個全連接層(nn.Linear),將輸入映射到Q、K、V的組合self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)# 一個全連接層,用于將注意力機制的輸出投影回原始維度self.proj = nn.Linear(dim, dim)self.use_rel_pos = use_rel_posif self.use_rel_pos: # 使用相對位置編碼assert (input_size is not None), "Input size must be provided if using relative positional encoding."# 初始化水平方向(rel_pos_h)和垂直方向(rel_pos_w)的相對位置嵌入# 2S-1,Epos# 輸入尺寸為(H, W),則水平方向的位置嵌入長度為2*H-1,垂直方向的位置嵌入長度為2*W-1# 每個位置嵌入的維度為head_dim# 這些位置嵌入以模型參數的形式定義(nn.Parameter),意味著它們會在訓練過程中被學習和更新self.rel_pos_h = nn.Parameter(torch.zeros(2 * input_size[0] - 1, head_dim))self.rel_pos_w = nn.Parameter(torch.zeros(2 * input_size[1] - 1, head_dim))def forward(self, x: torch.Tensor) -> torch.Tensor:# 輸入張量x的形狀為(B, H, W, C),其中B是批次大小,H和W是高度和寬度,C是通道數(即dim)B, H, W, _ = x.shape# 使用qkv層將x轉換為Q、K、V的組合,然后通過重塑和重新排列來準備多頭注意力計算# qkv with shape (3, B, nHead, H * W, C)qkv = self.qkv(x).reshape(B, H * W, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)# q, k, v with shape (B * nHead, H * W, C)q, k, v = qkv.reshape(3, B * self.num_heads, H * W, -1).unbind(0)# attn with shape (B * nHead, H * W, H * W)# 計算注意力分數# q * self.scale: q是查詢向量(query vectors),形狀為(B * nHead, H * W, C),其中B是批次大小,nHead是注意力頭的數量,H * W是序列的長度,C是每個位置的特征維度# self.scale是用于縮放注意力分數的因子,通常取head_dim的平方根的倒數,以防止數值過大# 乘以self.scale是為了穩定計算并防止梯度消失# k.transpose(-2, -1): k是鍵向量(key vectors),形狀與q相同。transpose(-2, -1)是對k進行轉置操作,即將最后一個和倒數第二個維度互換,目的是讓q和k在計算點積時的維度匹配。轉置后的k形狀變為(B * nHead, C, H * W)# 將q和轉置后的k進行矩陣乘法。計算每個查詢位置q與所有鍵位置k的點積,生成一個形狀為(B * nHead, H * W, H * W)的注意力分數矩陣attn。每個位置i和j的注意力分數表示q_i與k_j的相似度attn = (q * self.scale) @ k.transpose(-2, -1)# 如果啟用了相對位置編碼if self.use_rel_pos:# (H, W)代表輸入序列的尺寸,這里假設H和W是相等的(S×S),即輸入是一個正方形網格(例如,圖像的像素網格)# attn: 上述計算得到的注意力分數矩陣,形狀為(B * nHead, H * W, H * W)# q: 查詢向量,形狀為(B * nHead, H * W, C)# self.rel_pos_h和self.rel_pos_w: 分別表示水平和垂直方向上的相對位置嵌入,形狀分別為(2 * S - 1, head_dim)# (H, W): 輸入序列的尺寸,用于指導相對位置嵌入的計算attn = add_decomposed_rel_pos(attn, q, self.rel_pos_h, self.rel_pos_w, (H, W), (H, W))# 生成的注意力分數矩陣attn隨后會經過Softmax函數,將每個位置的分數歸一化到[0, 1]區間,形成一個概率分布attn = attn.softmax(dim=-1)# 加權求和: # 使用attn @ v計算加權和,其中@表示矩陣乘法,v是值向量(value vectors),形狀為(B * nHead, H * W, C)# 注意力權重矩陣attn(形狀為(B * nHead, H * W, H * W))與v按元素相乘后,再進行矩陣乘法,得到加權后的值向量,形狀為(B * nHead, H * W, C)# 使用.view()將加權后的值向量重塑為(B, self.num_heads, H, W, -1),然后使用.permute(0, 2, 3, 1, 4)進行重排,將self.num_heads移動到第四個維度。最后,使用.reshape(B, H, W, -1)將結果進一步重塑為(B, H, W, -1),與輸入張量的形狀一致,但保留了多頭注意力的輸出x = (attn @ v).view(B, self.num_heads, H, W, -1).permute(0, 2, 3, 1, 4).reshape(B, H, W, -1)# 使用self.proj(一個全連接層,形狀為(dim, dim))對上述處理后的張量進行線性投影,以將其投影回原始的特征維度x = self.proj(x)# 最終,返回經過線性投影的張量x作為注意力模塊的輸出return x?在多頭注意力(Multi-Head Attention)模塊中,輸入特征F(N×E)表示一個序列,其中N是序列中的元素數量,E是每個元素的特征維度。具體流程如下。
- 首先將每個token的qkv特征維度embed_dim均拆分到每個head上。

- 每個head分別通過q和k計算得到權重w,權重w和v得到輸出output,合并所有head的output得到最終的output?
get_rel_pos用于計算查詢(query)和鍵(key)之間在二維空間中的相對位置編碼,如下圖所示。
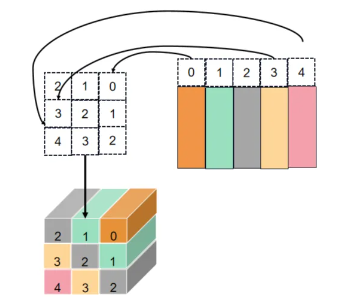
實現代碼:
def get_rel_pos(q_size: int, k_size: int, rel_pos: torch.Tensor) -> torch.Tensor:# 表示查詢(query)和鍵(key)在二維空間中的最大相對距離# max(q_size, k_size):取查詢的寬度q_size和鍵的寬度k_size中的較大值# 如果q_size和k_size都為S,則最大的正向距離是S-1,最大的負向距離也是S-1,所以總的最大距離是2 * S# - 1:減去1是因為在計算相對位置時,0被包含在內,所以最大距離是2 * S - 1max_rel_dist = int(2 * max(q_size, k_size) - 1)# 如果rel_pos的形狀的第0個維度(即長度)不等于max_rel_dist,說明需要進行插值if rel_pos.shape[0] != max_rel_dist:# 使用F.interpolate進行線性插值rel_pos_resized = F.interpolate(# 1,N,Ep --> 1,Ep,N --> 1,Ep,2S-1# 將rel_pos重塑為(1, N, Ep),其中N是原始的長度,Ep是每個位置編碼的特征維度# 通過permute(0, 2, 1)進行轉置,使其形狀變為(1, Ep, N)rel_pos.reshape(1, rel_pos.shape[0], -1).permute(0, 2, 1),# 設置插值的目標長度為max_rel_distsize=max_rel_dist,# 指定插值方法為線性插值mode="linear",)# Ep,2S-1 --> 2S-1,Ep# 插值后的rel_pos形狀為(1, Ep, max_rel_dist),通過reshape(-1, max_rel_dist)將其重塑為(Ep, max_rel_dist)# 再通過permute(1, 0)轉置為(max_rel_dist, Ep)rel_pos_resized = rel_pos_resized.reshape(-1, max_rel_dist).permute(1, 0)else:# 如果rel_pos的長度與max_rel_dist相等,說明已經足夠覆蓋所有可能的相對位置,因此直接使用rel_pos,不進行任何處理rel_pos_resized = rel_pos# 如果q和k長度值不同,則用短邊長度縮放坐標# 創建查詢坐標q_coords# torch.arange(q_size)生成一個從0到q_size - 1的整數序列,表示q_size個位置# [:, None]在序列末尾添加一個維度,使其形狀為(q_size, 1),這樣可以方便與一個標量進行逐元素乘法# max(k_size / q_size, 1.0)計算比例因子,如果k_size大于q_size,則使用k_size / q_size,否則使用1.0# 這確保了在q_size小于k_size的情況下,q_coords的坐標會被適當放大,以匹配k_coords的尺度q_coords = torch.arange(q_size)[:, None] * max(k_size / q_size, 1.0)# 創建鍵坐標k_coordsk_coords = torch.arange(k_size)[None, :] * max(q_size / k_size, 1.0)# S,S# 計算了查詢(query)和鍵(key)在二維空間中的相對坐標relative_coords# (q_coords - k_coords):每個查詢位置相對于每個鍵位置的水平距離# (k_size - 1) * max(q_size / k_size, 1.0):計算了一個偏移量,用于確保相對坐標在正確的范圍內# (q_coords - k_coords) + (k_size - 1) * max(q_size / k_size, 1.0):將計算出的差值和偏移量相加,得到最終的相對坐標relative_coordsrelative_coords = (q_coords - k_coords) + (k_size - 1) * max(q_size / k_size, 1.0)# tensor索引是tensor時,即tensor1[tensor2]# 假設tensor2某個具體位置值是2,則tensor1[2]位置的tensor1切片替換tensor2中的2# tensor1->shape 5,5,3 tensor2->shape 2,2,3 tensor1切片->shape 5,3 tensor1[tensor2]->shape 2,2,3,5,3# tensor1->shape 5,5 tensor2->shape 3,2,3 tensor1切片->shape 5 tensor1[tensor2]->shape 3,2,3,5# 2S-1,Ep-->S,S,Epreturn rel_pos_resized[relative_coords.long()]
?add_decomposed_rel_pos為atten注意力特征添加相對位置的嵌入特征,如下圖所示。
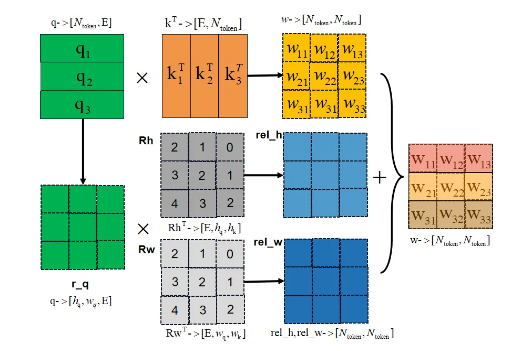
def add_decomposed_rel_pos(# 注意力分數矩陣attn: torch.Tensor,q: torch.Tensor,rel_pos_h: torch.Tensor,rel_pos_w: torch.Tensor,q_size: Tuple[int, int],k_size: Tuple[int, int],
) -> torch.Tensor:# S,Sq_h, q_w = q_sizek_h, k_w = k_size# rel_pos_h -> 2S-1×Epos# 查詢(query)和鍵(key)在高度方向上的相對位置編碼Rh = get_rel_pos(q_h, k_h, rel_pos_h)# 查詢(query)和鍵(key)在寬度方向上的相對位置編碼Rw = get_rel_pos(q_w, k_w, rel_pos_w)# 重塑q為(B, q_h, q_w, dim)B, _, dim = q.shaper_q = q.reshape(B, q_h, q_w, dim)# 計算相對位置加權# 計算rel_h和rel_w,這兩個張量表示在每個位置上,查詢與相對位置編碼的加權和# B,q_h,q_w,k_hrel_h = torch.einsum("bhwc,hkc->bhwk", r_q, Rh)# B,q_h, q_w, k_wrel_w = torch.einsum("bhwc,wkc->bhwk", r_q, Rw)# 合并注意力分數和相對位置編碼# 將attn重塑為(B, q_h, q_w, k_h, k_w),然后與rel_h和rel_w按元素相加# 將attn重塑為(B, q_h, q_w, k_h, k_w),然后與rel_h和rel_w按元素相加attn = (# B,q_h, q_w, k_h, k_wattn.view(B, q_h, q_w, k_h, k_w) + rel_h[:, :, :, :, None] + rel_w[:, :, :, None, :]).view(B, q_h * q_w, k_h * k_w)return attn?Multi-Head Attention模塊為注意力特征嵌入了相對位置特征(add_decomposed_rel_pos):

Neck Convolution?
最后,通過兩層卷積(Neck)將通道數降低至256,生成最終的Image Embedding。其結構圖如下所示。
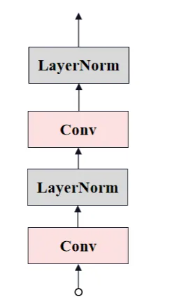
?代碼實現如下:
# neck: nn.Sequential,它包含兩個卷積層和兩個LayerNorm2d)
self.neck = nn.Sequential(# 1x1的卷積層,用于將輸入通道數從embed_dim減小到out_chans# 1x1卷積主要用于通道間的信息融合,而不改變特征圖的空間尺寸nn.Conv2d(embed_dim,out_chans,kernel_size=1,# 不使用偏置項bias=False,),# 歸一化層,用于規范化輸出通道的均值和方差,提高模型的穩定性和收斂速度# out_chans:歸一化層的通道數LayerNorm2d(out_chans),# 3x3的卷積層nn.Conv2d(# 使用out_chans作為輸入和輸出通道數out_chans,out_chans,kernel_size=3,# 輸入和輸出的特征圖尺寸保持不變,避免尺寸收縮padding=1,# 不使用偏置bias=False,),# 第二個歸一化層,再次對輸出進行規范化LayerNorm2d(out_chans),
)
# 歸一化
class LayerNorm2d(nn.Module):def __init__(self, num_channels: int, eps: float = 1e-6) -> None:super().__init__()# 創建了兩個可學習的參數:weight和bias# weight初始化為全1,bias初始化為全0self.weight = nn.Parameter(torch.ones(num_channels))self.bias = nn.Parameter(torch.zeros(num_channels))self.eps = epsdef forward(self, x: torch.Tensor) -> torch.Tensor:# 沿著通道維度求均值,keepdim=True保留維度,使得u的形狀與x相同,除了通道維度的大小為1u = x.mean(1, keepdim=True) # dim=1維度求均值并保留通道# 計算標準化因子 s,即減去均值后的平方差的平均值,也保留通道維度s = (x - u).pow(2).mean(1, keepdim=True)# 歸一化,將每個像素的值減去均值 u,然后除以標準差的平方根加上一個小的常數 eps 以保證數值穩定性x = (x - u) / torch.sqrt(s + self.eps)# 應用可學習的權重和偏置x = self.weight[:, None, None] * x + self.bias[:, None, None]return xPrompt Encoder?
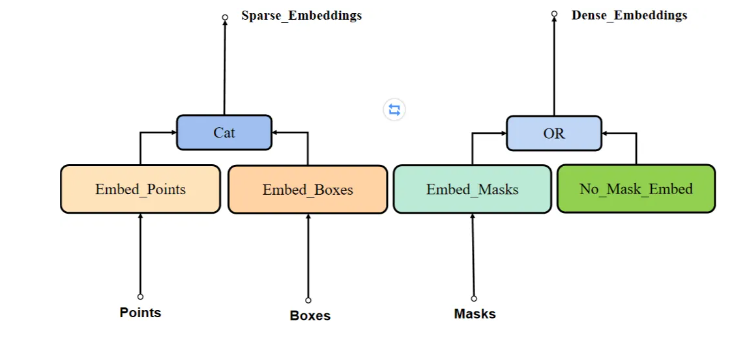
SAM模型中Prompt Encoder網絡結構如下圖所示。主要包括三步驟:
-
Embed_Points:標記點編碼(標記點由點轉變為向量)
-
Embed_Boxes:標記框編碼(標記框由點轉變為向量)
-
Embed_Masks:mask編碼(mask下采樣保證與Image Encoder輸出一致)
Embed_Points?
Embed_Points結構如下圖所示。
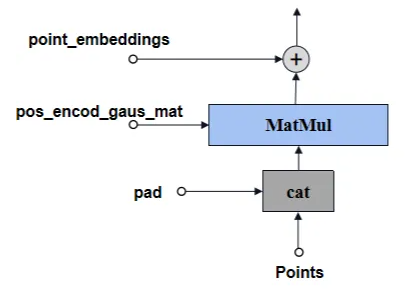
標記點預處理,將channel由2變為embed_dim(MatMul:forward_with_coords),然后再加上位置編碼權重。其中,
-
2:坐標(h,w)
-
embed_dim:提示編碼的channel
代碼實現:
# 將輸入的點坐標和對應的標簽轉化為高維的嵌入表示,以便于后續的模型處理
def _embed_points(self,points: torch.Tensor,labels: torch.Tensor,pad: bool,
) -> torch.Tensor:# 將輸入的點坐標points的每個坐標值增加0.5,以將坐標從像素的左上角移動到像素中心points = points + 0.5# points和boxes聯合則不需要padif pad:# 在點坐標 points 和標簽 labels 中添加一個填充項# 以保持批次處理的一致性,即使某些樣本的點數量少于最大數量。# 填充的點坐標為(0,0),標簽為-1padding_point = torch.zeros((points.shape[0], 1, 2), device=points.device) # B,1,2padding_label = -torch.ones((labels.shape[0], 1), device=labels.device) # B,1points = torch.cat([points, padding_point], dim=1) # B,N+1,2labels = torch.cat([labels, padding_label], dim=1) # B,N+1# 根據調整后的點坐標和輸入圖像的尺寸生成位置編碼# 生成的嵌入維度:B,N+1,2f# 2f 表示每個點位置編碼的維度,是通過某種函數(如正弦或余弦函數)從原始的2D坐標擴展而來point_embedding = self.pe_layer.forward_with_coords(points, self.input_image_size) # 根據標簽 labels 的值,對每個點的嵌入進行調整。# labels為-1是非標記點,設為非標記點權重point_embedding[labels == -1] = 0.0point_embedding[labels == -1] += self.not_a_point_embed.weight# labels為0是背景點,加上背景點權重point_embedding[labels == 0] += self.point_embeddings[0].weight# labels為1是目標點,加上目標點權重point_embedding[labels == 1] += self.point_embeddings[1].weightreturn point_embeddingEmbed_Boxes
Embed_Boxes結構如下圖所示
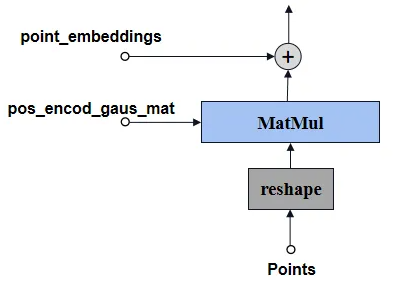
?標記框(Bounding Box)一般有兩個點,編碼步驟如下:
-
將輸入的邊界框坐標張量boxes從BxNx4轉換為BxNx2x2;
-
再使用point embedding編碼的方式,得到corner_embedding;
-
加上之前生成的可學習的embeding向量。
最后輸出的corner_embedding大小為Nx2x256。
代碼實現:
# 將輸入的邊界框(boxes)轉換為高維的嵌入表示
def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:# 將坐標從像素的左上角移動到像素中心boxes = boxes + 0.5# 將輸入的邊界框坐標張量boxes從BxN*4轉換為B*Nx2x2# 其中B是批次大小,N是每個樣本中的邊界框數量coords = boxes.reshape(-1, 2, 2)# 對每個邊界框的角點坐標進行位置編碼corner_embedding = self.pe_layer.forward_with_coords(coords, self.input_image_size) ## 分別對每個邊界框的起始點和末尾點的嵌入向量加上特定的權重corner_embedding[:, 0, :] += self.point_embeddings[2].weightcorner_embedding[:, 1, :] += self.point_embeddings[3].weight# 返回加權后嵌入向量,形狀為 B*Nx2xembed_dim,其中 embed_dim 是位置編碼的維度return corner_embeddingEmbed_Mask?
mask提示允許我們直接在原圖上指示感興趣區域來引導模型。這些mask通過卷積操作被轉換為與圖像嵌入空間相匹配的特征,然后與圖像嵌入相加結合,為模型提供分割的精確位置信息。
如果沒有使用mask提示,則將一組可學習向量(no_mask_embed,1*256)expand為1x256×64×64后替代,使得在處理序列數據時,即使沒有具體的mask信息,也能有一個統一的處理方式。
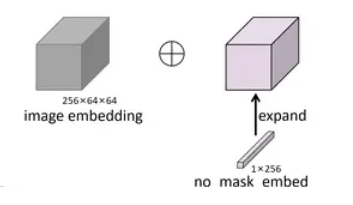
# 在PromptEncoder的forward定義
'''
首先獲取no_mask_embed權重矩陣,并將其重塑成一個形狀為(1, num_embeddings, 1, 1)的四維張量。再利用.expand方法將這個張量擴展到與圖像編碼相同的尺寸。bs是batch大小,-1是一個占位符,它會自動計算出
num_embeddings的值以保持張量的元素總數不變。self.image_embedding_size[0]和self.image_embedding_size[1]分別表示圖像編碼的寬度和高度。
'''
self.no_mask_embed = nn.Embedding(1, embed_dim) # embed_dim=256
dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1, 1).expand(bs, -1, self.image_embedding_size[0], self.image_embedding_size[1]))?如果有配置mask,Embed_Masks結構如下圖所示
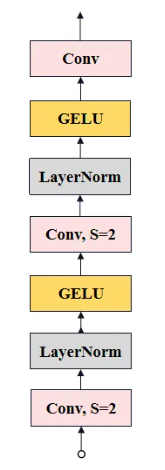
已知輸入mask是Nx1x256x256,經過3層卷積,最后得到與Image Embedding一樣的size:
首先,mask進入一個1x2x2x4的卷積,stride=2;LN;再進入一個4x2x2x16的卷積,stride=2;LN;最后再進入一個16x1x1x256的卷積;得到最后的mask_embedding的size為Nx256x64x64,最終mask_embedding作為dense_embedding輸出,大小為Nx256x64x64。
mask的輸出尺寸是Image Encoder模塊輸出的圖像編碼尺寸的4倍,因此為了保持一致,需要4倍下采樣。
代碼實現
# 將輸入的掩模(mask)張量轉換為一個低分辨率的嵌入表示
# 掩模 masks 是一個形狀為 BxCxHxW 的張量
# 其中 B 是批次大小,C 是通道數(通常為1,因為掩模通常只有一通道),H 和 W 分別是高度和寬度。
def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor:# mask下采樣4倍mask_embedding = self.mask_downscaling(masks)# 返回下采樣并轉換后的掩模嵌入,其形狀為 B*embed_dim*H'*W',其中 H' 和 W' 是下采樣后的高度和寬度return mask_embedding# mask_downscaling包括多個卷積層、層歸一化(LayerNorm2d)和激活函數,目的是減少掩模的空間維度,同時增加通道維度
self.mask_downscaling = nn.Sequential(# 將通道數從1減少到mask_in_chans//4,同時使用2x2的卷積核和步長2進行下采樣,降低了空間分辨率nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2),# 規范化通道維度上的特征LayerNorm2d(mask_in_chans // 4),# 激活函數,引入非線性activation(),# 將通道數恢復到 mask_in_chans,再次使用2x2的卷積核和步長2進行下采樣,進一步降低空間分辨率nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),# LayerNorm2d 層和激活函數LayerNorm2d(mask_in_chans),activation(),# 將通道數增加到 embed_dim,通常是為了與模型的其他部分保持一致nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1),)?PositionEmbeddingRandom
用于將標記點和標記框的坐標進行提示編碼預處理。就是將64x64個坐標點歸一化后,與隨機高斯矩陣相乘(2x128),再將結果分別進行sin和cos,最后再拼到一起,輸出的大小為256x64x64,與image_embedding大小基本一致了。
class PositionEmbeddingRandom(nn.Module):"""Positional encoding using random spatial frequencies."""def init(self, num_pos_feats: int = 64, scale: Optional[float] = None) -> None:super().init()if scale is None or scale <= 0.0:scale = 1.0# 構建一個2x128的隨機矩陣作為位置編碼高斯矩陣self.register_buffer("positional_encoding_gaussian_matrix",scale * torch.randn((2, num_pos_feats)),)def _pe_encoding(self, coords: torch.Tensor) -> torch.Tensor:"""Positionally encode points that are normalized to [0,1]."""# assuming coords are in [0, 1]^2 square and have d_1 x ... x d_n x 2 shapecoords = 2 * coords - 1# 矩陣乘法:64x64xx2 @ 2x128 ---> 64x64x128coords = coords @ self.positional_encoding_gaussian_matrixcoords = 2 * np.pi * coords# outputs d_1 x ... x d_n x C shape# cat, 最后一個維度上拼接:64x64x256return torch.cat([torch.sin(coords), torch.cos(coords)], dim=-1)def forward(self, size: Tuple[int, int]) -> torch.Tensor:"""Generate positional encoding for a grid of the specified size."""h, w = sizedevice: Any = self.positional_encoding_gaussian_matrix.device# 構造一個64x64的全1矩陣grid = torch.ones((h, w), device=device, dtype=torch.float32)# 行、列累加y_embed = grid.cumsum(dim=0) - 0.5x_embed = grid.cumsum(dim=1) - 0.5# 行列累加結果歸一化y_embed = y_embed / hx_embed = x_embed / w# 行列拼接:64x64x2,編碼后的結果是64x64x256pe = self._pe_encoding(torch.stack([x_embed, y_embed], dim=-1))# 最后輸出256x64x64return pe.permute(2, 0, 1) # C x H x WMask Decoder
Mask Decoder網絡結構參數配置如下
def __init__(self,*,# transformer通道數transformer_dim: int,# 用于預測mask的Transformer網絡模塊transformer: nn.Module,# 消除掩碼歧義預測的掩碼數量,默認為3num_multimask_outputs: int = 3,# 激活函數,默認為GELUactivation: Type[nn.Module] = nn.GELU,# MLP用于預測掩模質量的深度iou_head_depth: int = 3,# MLP的隱藏層通道數iou_head_hidden_dim: int = 256,
) -> None:super().__init__()self.transformer_dim = transformer_dim #存儲傳入的transformer_dim# 存儲傳入的transformer模塊self.transformer = transformer# 存儲掩碼預測的輸出數量self.num_multimask_outputs = num_multimask_outputs# 用于表示IoU(Intersection over Union)的嵌入層,大小為1×transformer_dim# 可學習的iou tokens:1x256self.iou_token = nn.Embedding(1, transformer_dim)# 包含IoU token在內的總mask token數量# # num_mask_tokens = 3 + 1 = 4, transformer_dim = 256# 輸出一個4x256的矩陣self.num_mask_tokens = num_multimask_outputs + 1# 存儲所有mask token的嵌入層,大小為num_mask_tokens×transformer_dimself.mask_tokens = nn.Embedding(self.num_mask_tokens, transformer_dim)#----- upscaled -----# 用于4倍上采樣的序列,包含兩個轉置卷積層,每個上采樣2倍,中間夾著LayerNorm和激活函數self.output_upscaling = nn.Sequential(nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2), #轉置卷積 上采樣2倍LayerNorm2d(transformer_dim // 4),activation(),nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2),activation(),)# ----- upscaled -----# 多層感知機(MLP)模塊# 一個模塊列表,包含了num_mask_tokens個MLP,每個MLP用于處理不同mask的輸出self.output_hypernetworks_mlps = nn.ModuleList([MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)for i in range(self.num_mask_tokens)])# ----- MLP -----# ----- MLP -----# 一個MLP,用于預測IoU,輸入是transformer_dim,經過iou_head_hidden_dim的隱藏層,輸出是num_mask_tokensself.iou_prediction_head = MLP(transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth)# ----- MLP -----
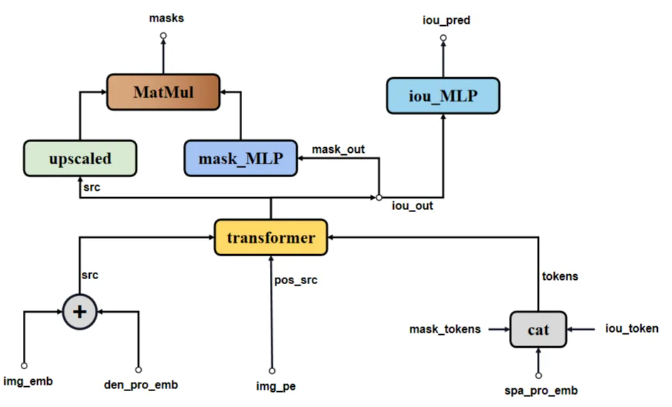
SAM模型Mask Decoder網絡結構如下圖所示。
-
spa_pro_emb(sparse embedding)、iou_token、mask_token合并成一個tokens,作為point_embeddings。
-
spa_pro_emb: point、bbox prompt合并后的產物,一般為NxXx256。
-
iou_token:可學習參數,大小為1x256。
-
mask_token:可學習參數,大小為4x256。
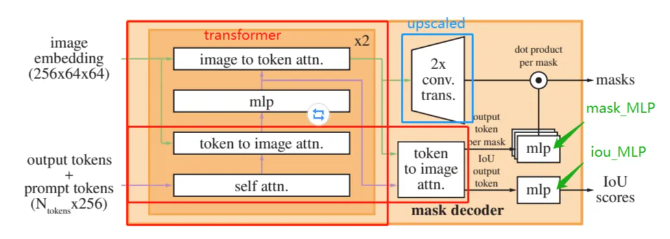
原論文中Mask Decoder模塊各部分結構示意圖如下。
Mask Decoder網絡在特征提取中的基本步驟如下:
-
transformer:將來自編碼器的圖像特征與額外的提示信息(如掩碼提示或查詢向量)融合,以捕捉目標區域的上下文信息。
-
upscaled:對粗略mask src進行上采樣,使其與原始圖像尺寸相匹配,以便進行更精細的mask預測。
-
mask_MLP:通過一系列全連接層,對上采樣后的特征進行變換,計算出針對每個像素的mask概率。這些層可以設計為學習如何為每個mask通道分配權重,從而生成最終的mask輸出。
-
iou_MLP:評估生成的mask與真實mask之間的重疊程度,即預測mask的質量。
def forward(self,# image encoder 圖像特征image_embeddings: torch.Tensor,# 位置編碼# 256x64x64image_pe: torch.Tensor,# 標記點和標記框的嵌入編碼sparse_prompt_embeddings: torch.Tensor,# 輸入mask的嵌入編碼dense_prompt_embeddings: torch.Tensor,# 是否輸出多個maskmultimask_output: bool,
) -> Tuple[torch.Tensor, torch.Tensor]:# 將這些特征融合,通過Transformer和后續的上采樣及MLP層,生成掩膜預測和IoU分數masks, iou_pred = self.predict_masks(image_embeddings=image_embeddings,image_pe=image_pe,sparse_prompt_embeddings=sparse_prompt_embeddings,dense_prompt_embeddings=dense_prompt_embeddings,)# 如果multimask_output為True,表示需要輸出多個掩模,選取索引為1到num_multimask_outputs的所有掩模if multimask_output:mask_slice = slice(1, None)# 否則,如果multimask_output為False,僅輸出第一個掩模(通常是最高得分的掩模)else:mask_slice = slice(0, 1)# 根據multimask_output選擇后的掩模,維度調整為(batch_size, num_selected_masks, height, width)masks = masks[:, mask_slice, :, :]# 根據multimask_output選擇后的IoU預測,維度調整為(batch_size, num_selected_masks)iou_pred = iou_pred[:, mask_slice]return masks, iou_pred
def predict_masks(self,# image embedding: 是image encoder的輸出,大小為為1x256x64x64image_embeddings: torch.Tensor,# image_pe位置編碼也拓展成Nx256x64x64的矩陣image_pe: torch.Tensor,sparse_prompt_embeddings: torch.Tensor,dense_prompt_embeddings: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:# 首先將iou token和mask token 拼接得到一個5x256的矩陣,再將其拓展到與sparse embedding一個維度Nx5x256# 1,E and 4,E --> 5,Eoutput_tokens = torch.cat([self.iou_token.weight, self.mask_tokens.weight], dim=0)# 再將拓展后的矩陣與sparse embedding拼接得到tokens,其大小Nx(5+X)x256# 5,E --> B,5,Eoutput_tokens = output_tokens.unsqueeze(0).expand(sparse_prompt_embeddings.size(0), -1, -1)# 再與稀疏矩陣拼接,假設稀疏矩陣只有point為Nx2x256,拼接之后則為Nx(5+2)x256# B,5,E and B,N,E -->B,5+N,E N是點的個數(標記點和標記框的點)tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)# 將image embedding(1x256x64x64)拓展成稠密prompt的維度:Nx256x64x64# B,C,H,Wsrc = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)#將拓展后的image embedding直接與稠密prompt相加:Nx256x64x64# B,C,H,W + 1,C,H,W ---> B,C,H,Wsrc = src + dense_prompt_embeddings# # 將256x64x64的位置編碼,拓展成Nx256x64x64# 1,C,H,W---> B,C,H,Wpos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)b, c, h, w = src.shape# ----- transformer -----# Run the transformer:這里使用的TwoWayTransformer,有必要對輸入再說明一下# src:image_bedding + dense_prompt(mask),Nx256x64x64# pos_src: 位置編碼,Nx256x64x64# tokens: iou_tokens + mask_tokens + sparse_prompt(point/bbox),Nx(5+x)x256# B,N,Chs, src = self.transformer(src, pos_src, tokens)# ----- transformer -----# # 后處理iou_token_out = hs[:, 0, :]mask_tokens_out = hs[:, 1: (1 + self.num_mask_tokens), :]# 通過上采樣層將Transformer輸出的掩模部分恢復到(batch_size, channels, height, width)的形狀# B,N,C-->B,C,H,Wsrc = src.transpose(1, 2).view(b, c, h, w)# ----- upscaled -----# 4倍上采樣upscaled_embedding = self.output_upscaling(src)# ----- upscaled -----# 對每個mask token,通過其對應的MLP得到一個權重張量,使用這些權重與上采樣后的特征張量進行點乘,得到掩模預測(batch_size, num_mask_tokens, height, width)hyper_in_list: List[torch.Tensor] = []# ----- mlp -----for i in range(self.num_mask_tokens):# mask_tokens_out[:, i, :]: B,1,C# output_hypernetworks_mlps: B,1,chyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]))# B,n,chyper_in = torch.stack(hyper_in_list, dim=1)# ----- mlp -----b, c, h, w = upscaled_embedding.shape# B,n,c × B,c,N-->B,n,h,wmasks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)# ----- mlp -----# 通過IoU預測頭(MLP)對IoU token的輸出進行處理,得到(batch_size, num_mask_tokens)的IoU分數# iou_token_out: B,1,niou_pred = self.iou_prediction_head(iou_token_out)# ----- mlp -----# 返回預測的掩模和IoU分數# masks: B,n,h,w# iou_pred: B,1,nreturn masks, iou_predtransformer
Mask Decoder由多個重復堆疊TwoWayAttention Block和1個Multi-Head Attention組成。
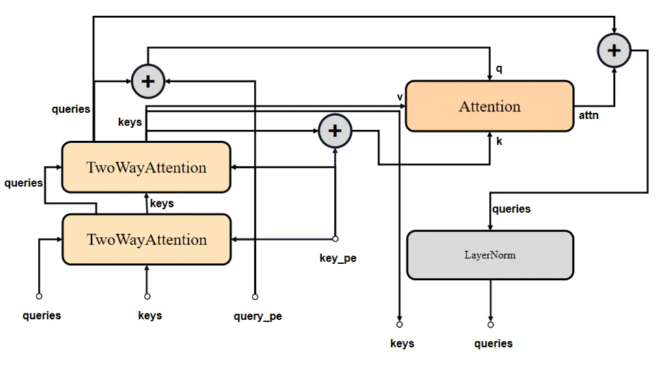
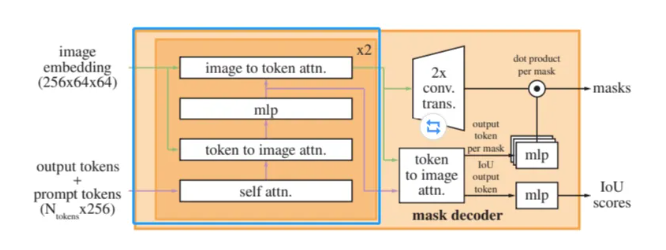
TwoWayAttention Block
TwoWayAttention Block由LayerNorm 、Multi-Head Attention和MLP構成。所謂的TwoWay:即是兩輪次循環,第一次point_embedding自注意,第二次則加上上一輪輸出的queries進行attention。
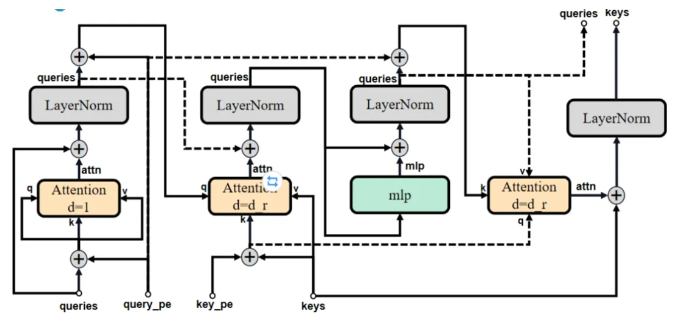
原論文中TwoWayAttention部分示意圖。
?
class TwoWayAttentionBlock(nn.Module):def __init__(self,embedding_dim: int, # 輸入特征維度num_heads: int, # 注意力頭的數量,決定了注意力機制的并行度mlp_dim: int = 2048, # MLP(多層感知機)中間層的維度,用于特征變換和非線性增強activation: Type[nn.Module] = nn.ReLU, # 激活函數類型,默認為ReLUattention_downsample_rate: int = 2, # 下采樣比率# 是否在第一層自注意力中跳過位置編碼的殘差連接skip_first_layer_pe: bool = False,) -> None:super().__init__()# 自注意力模塊,用于增強queries內部的信息交互self.self_attn = Attention(embedding_dim, num_heads)# norm1/2/3/4: LayerNorm層,用于穩定訓練和加速收斂self.norm1 = nn.LayerNorm(embedding_dim)# cross_attn_token_to_image和cross_attn_image_to_token: 交叉注意力模塊,分別讓標記點特征關注圖像特征,以及圖像特征反過來關注標記點特征self.cross_attn_token_to_image = Attention(embedding_dim, num_heads, downsample_rate=attention_downsample_rate)self.norm2 = nn.LayerNorm(embedding_dim)# mlp: 多層感知機模塊,增加模型的表達能力self.mlp = MLPBlock(embedding_dim, mlp_dim, activation)self.norm3 = nn.LayerNorm(embedding_dim)self.norm4 = nn.LayerNorm(embedding_dim)self.cross_attn_image_to_token = Attention(embedding_dim, num_heads, downsample_rate=attention_downsample_rate)self.skip_first_layer_pe = skip_first_layer_pe# 前向傳播def forward(self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor) -> Tuple[Tensor, Tensor]:# queries:標記點編碼相關(原始標記點編碼經過一系列特征提取)# keys:原始圖像編碼相關(原始圖像編碼經過一系列特征提取)# query_pe:原始標記點編碼# key_pe:原始圖像位置編碼# 第一輪本身queries==query_pe沒比較再"殘差"# 首先對queries應用自注意力,若skip_first_layer_pe=True,直接使用queries進行自注意力計算;否則,將queries與query_pe相加后進行自注意力計算,并殘差連接回queries,之后進行LayerNormif self.skip_first_layer_pe:queries = self.self_attn(q=queries, k=queries, v=queries)else:q = queries + query_peattn_out = self.self_attn(q=q, k=q, v=queries)queries = queries + attn_outqueries = self.norm1(queries)# 調整queries和keys(圖像特征)加上各自的位置編碼,然后通過cross_attn_token_to_image交叉注意力層,使標記點特征關注圖像特征,結果與原始queries殘差連接并進行LayerNormq = queries + query_pek = keys + key_peattn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys)queries = queries + attn_outqueries = self.norm2(queries)# MLP block:將更新后的queries通過MLP模塊進行非線性變換,結果與原queries殘差連接并進行LayerNormmlp_out = self.mlp(queries)queries = queries + mlp_outqueries = self.norm3(queries)# 交叉注意力(圖像到標記點):再次調整queries和keys加上位置編碼,但這次通過cross_attn_image_to_token讓圖像特征關注標記點特征,更新后的keys與原始keys殘差連接并進行LayerNormq = queries + query_pek = keys + key_peattn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries)keys = keys + attn_outkeys = self.norm4(keys)return queries, keysAttention?
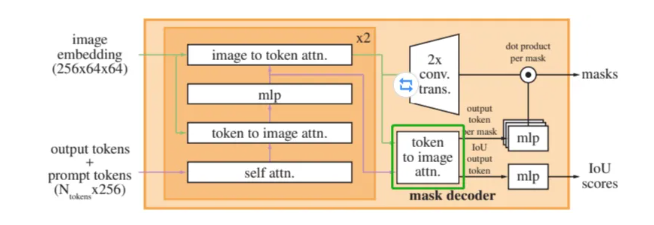
Mask Decoder的Attention與ViT的Attention有些細微的不同:
-
Mask Decoder的Attention是3個FC層分別接受3個輸入獲得q、k和v。
-
ViT的Attention是1個FC層接受1個輸入后將結果均拆分獲得q、k和v。
如下圖所示。
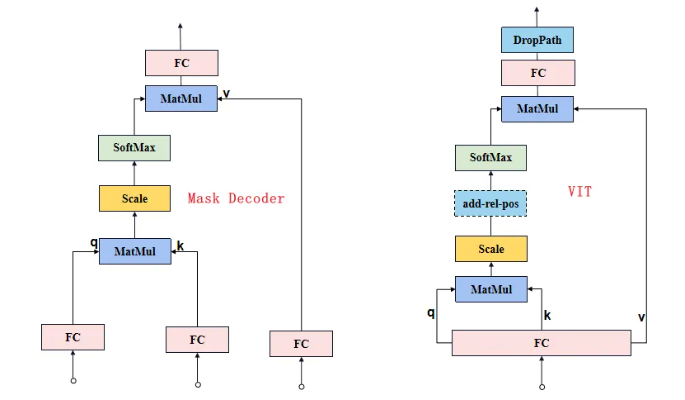
?原論文中Attention部分示意圖
class Attention(nn.Module):def __init__(self,embedding_dim: int, # 輸入特征的維度num_heads: int, # attention的head數downsample_rate: int = 1, # 下采樣) -> None:super().__init__()self.embedding_dim = embedding_dim# 內部維度self.internal_dim = embedding_dim // downsample_rateself.num_heads = num_headsassert self.internal_dim % num_heads == 0, "num_heads must divide embedding_dim."# 四個線性層(全連接層):用于生成query向量、key向量、value向量self.q_proj = nn.Linear(embedding_dim, self.internal_dim)self.k_proj = nn.Linear(embedding_dim, self.internal_dim)self.v_proj = nn.Linear(embedding_dim, self.internal_dim)# 用于將注意力機制后的輸出投影回原始的特征維度self.out_proj = nn.Linear(self.internal_dim, embedding_dim)# 將輸入張量分解為多頭注意力所需的形狀def _separate_heads(self, x: Tensor, num_heads: int) -> Tensor:b, n, c = x.shapex = x.reshape(b, n, num_heads, c // num_heads)return x.transpose(1, 2) # B x N_heads x N_tokens x C_per_head# 在注意力計算后重新組合這些頭部def _recombine_heads(self, x: Tensor) -> Tensor:b, n_heads, n_tokens, c_per_head = x.shapex = x.transpose(1, 2)return x.reshape(b, n_tokens, n_heads * c_per_head) # B x N_tokens x Cdef forward(self, q: Tensor, k: Tensor, v: Tensor) -> Tensor:# 輸入投影:分別使用q_proj、k_proj和v_proj對query、key和value進行線性變換q = self.q_proj(q)k = self.k_proj(k)v = self.v_proj(v)# 分離頭部:將變換后的query、key和value張量按照num_heads進行重塑,以便進行多頭注意力計算# B,N_heads,N_tokens,C_per_headq = self._separate_heads(q, self.num_heads)k = self._separate_heads(k, self.num_heads)v = self._separate_heads(v, self.num_heads)# 注意力計算:# 計算query和key的點積,然后除以c_per_head的平方根進行歸一化,以防止數值過大_, _, _, c_per_head = q.shapeattn = q @ k.permute(0, 1, 3, 2) # B,N_heads,N_tokens,C_per_head# 歸一化Scaleattn = attn / math.sqrt(c_per_head)# 應用softmax函數得到注意力權重attn = torch.softmax(attn, dim=-1)# 使用注意力權重對value進行加權求和,得到注意力輸出out = attn @ v# # B,N_tokens,C# 重新組合頭部:將多頭注意力輸出合并回原始的特征維度。out = self._recombine_heads(out)# 輸出投影:最后,通過out_proj將輸出投影回原始的embedding_dimout = self.out_proj(out)return out
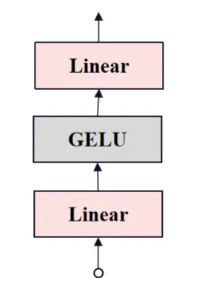
transformer_MLP
transformer中MLP的結構如下圖所示
# MLPBlock類是一個簡單的多層感知機(MLP)模塊,由兩個全連接層(Linear)和一個激活函數組成
class MLPBlock(nn.Module):def __init__(self,# 輸入的維度,通常是特征向量的長度embedding_dim: int,# MLP中間層的寬度,可以設置為比輸入維度更大的值以增加模型的表達能力mlp_dim: int,# 激活函數,這里默認使用GELUact: Type[nn.Module] = nn.GELU,) -> None:super().__init__()# 第一個全連接層,將輸入從embedding_dim維度變換到mlp_dim維度self.lin1 = nn.Linear(embedding_dim, mlp_dim)# 第二個全連接層,將mlp_dim維度的結果變換回embedding_dim維度,以保持與輸入相同的維度self.lin2 = nn.Linear(mlp_dim, embedding_dim)# 激活函數實例,用于在全連接層之間引入非線性self.act = act()# 接收輸入張量x,將其傳遞給lin1,然后應用激活函數act。# 將激活函數的輸出傳遞給lin2,得到最終的輸出張量def forward(self, x: torch.Tensor) -> torch.Tensor:return self.lin2(self.act(self.lin1(x)))upscaled
這個上采樣過程將Transformer的輸出特征圖恢復到更接近輸入圖像的分辨率,以便于生成掩模預測。upscaled的結構如下圖所示。
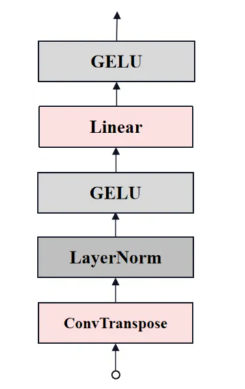
# 在MaskDecoder的__init__定義
# output_upscaling是一個序列模塊,用于上采樣Transformer輸出的特征圖
self.output_upscaling = nn.Sequential(# 使用nn.ConvTranspose2d,輸入通道數為transformer_dim,輸出通道數為transformer_dim // 4,內核大小為2,步長為2# 將特征圖的尺寸放大兩倍,同時將通道數減半# 內核大小為2的轉置卷積相當于上采樣2倍,步長為2確保輸出尺寸翻倍nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2), #轉置卷積 上采樣2倍# 層歸一化(LayerNorm2d)LayerNorm2d(transformer_dim // 4),# 激活函數activation(),# 再次使用nn.ConvTranspose2d,輸入通道數為transformer_dim // 4,輸出通道數為transformer_dim // 8,內核大小為2,步長為2。這一步繼續將特征圖的尺寸放大兩倍,同時通道數再次減半nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2),# 重復激活函數的過程,以進一步增強非線性表達activation(),
)
# 在MaskDecoder的predict_masks添加位置編碼
upscaled_embedding = self.output_upscaling(src)?mask_MLP
此處的MLP基礎模塊不同于ViT的MLP(transformer_MLP)基礎模塊
# 在MaskDecoder的__init__定義
# output_hypernetworks_mlps是一個nn.ModuleList,包含了多個多層感知機(MLP)。每個MLP的目的是根據輸入的mask_tokens_out生成特定掩模的超網絡權重
self.output_hypernetworks_mlps = nn.ModuleList([# transformer_dim: Transformer的輸出維度,也是輸入到MLP的通道數# transformer_dim // 8: MLP的輸出通道數,用于生成超網絡的權重# 3: MLP的中間層維度,用于增加模型的表達能力MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)for i in range(self.num_mask_tokens)]
)
# 在MaskDecoder的predict_masks添加位置編碼
# 對于self.num_mask_tokens個掩模token,遍歷output_hypernetworks_mlps列表
for i in range(self.num_mask_tokens):# mask_tokens_out[:, i, :]: B,1,C# output_hypernetworks_mlps: B,1,c# 對每個掩模token,應用對應的MLP,輸入是mask_tokens_out中對應位置的特征,輸出為B, 1, c形狀的張量,其中c是超網絡的輸出通道數# 將每個MLP的輸出收集到hyper_in_list列表中hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]))
# B,n,c
# 將hyper_in_list堆疊成一個B, n, c形狀的張量hyper_in,其中n是掩模token的數量
hyper_in = torch.stack(hyper_in_list, dim=1)
# 獲取upscaled_embedding的形狀b, c, h, w,其中b是批次大小,c是通道數,h和w是高度和寬度
b, c, h, w = upscaled_embedding.shape
# B,n,c × B,c,N-->B,n,h,w
# 執行矩陣乘法(@運算符)將hyper_in(B, n, c)與upscaled_embedding(在通道維度上展平為B, c, h * w)相結合
# 計算每個掩模token的超網絡權重與上采樣特征圖的點積,得到B, n, h * w形狀的張量
# 通過view操作將結果轉換回B, n, h, w形狀,生成了masks張量,表示每個掩模token對應的預測掩模
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)?iou_MLP
此處的MLP基礎模塊不同于ViT的MLP(transformer_MLP)基礎模塊
# 在MaskDecoder的__init__定義
# 一個多層感知機(MLP)模塊,其目的是預測每個掩模token對應的IoU(Intersection over Union,交并比)值,以評估預測掩模與真實掩模的重合程度
self.iou_prediction_head = MLP(# transformer_dim: 輸入到MLP的特征維度,通常與Transformer的輸出維度相同# iou_head_hidden_dim: MLP中間層的維度,用于增強模型的表達能力# self.num_mask_tokens: 輸出維度,即預測的掩模令牌數量,每個令牌對應一個IoU預測值transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth
)
# 在MaskDecoder的predict_masks添加位置編碼
iou_pred = self.iou_prediction_head(iou_token_out)MaskDeco_MLP
Mask Decoder中MLP的結構如下圖所示
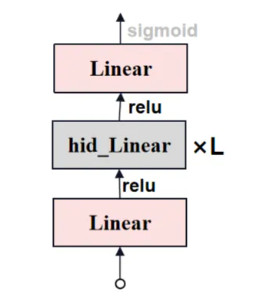
'''
定義了一個多層感知機,它包含一個可配置的隱藏層數目、輸入和輸出維度,并可以選擇是否在輸出層應用Sigmoid激活函數
'''
class MLP(nn.Module):def __init__(self,input_dim: int, # 輸入特征的維度,即輸入張量的通道數hidden_dim: int, # 隱藏層的通道數,中間層的寬度output_dim: int, # 輸出特征的維度,即輸出張量的通道數num_layers: int, # 多層感知機的層數,包括輸入層和輸出層sigmoid_output: bool = False, # 一個布爾值,表示是否在輸出層應用Sigmoid激活函數,默認為False) -> None:'''內部組件'''super().__init__()# 存儲輸入的層數self.num_layers = num_layers# 一個列表,包含num_layers - 1個hidden_dim,用于構建中間層的線性變換h = [hidden_dim] * (num_layers - 1)# 一個nn.ModuleList,包含num_layers個線性層(全連接層),每個層的輸入和輸出通道數由h和input_dim、output_dim決定self.layers = nn.ModuleList(nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]))self.sigmoid_output = sigmoid_outputdef forward(self, x):# 對輸入張量x,遍歷layers列表中的每個線性層for i, layer in enumerate(self.layers):# 如果當前層不是最后一層,應用ReLU激活函數(F.relu)x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)# 如果sigmoid_output為True,最后對輸出應用Sigmoid激活函數if self.sigmoid_output:x = F.sigmoid(x)return x?
總結
通過本周閱讀文獻和代碼的結合,初步對該文獻有了一定的了解,接下來會對其深入理解。



)





)



)

![[暈事]今天做了件暈事35 VM發送給gateway太多ARP,導致攻擊檢查?](http://pic.xiahunao.cn/[暈事]今天做了件暈事35 VM發送給gateway太多ARP,導致攻擊檢查?)



)