自大模型(LLM)誕生以來,苦于其高成本高消耗的訓練模式,學界和業界也在努力探索更為高效的參數微調方法。其中Low-Rank Adaptation(LoRA)自其誕生以來,就因其較低的資源消耗而受到廣泛關注和使用。
LoRA通過學習低秩擾動(low-rank perturbations),從而在使用大模型適配下游任務時,只需要訓練少量的參數即可達到一個很好的效果。盡管LoRA在資源效率上有明顯優勢,但其在處理復雜領域任務時的性能表現如何,尚未有定論。本文旨在填補這一空缺,以編程和數學兩個具有挑戰性的領域任務為例,探討LoRA與全參數微調的性能。
論文標題:
LoRA Learns Less and Forgets Less
論文鏈接:
https://arxiv.org/pdf/2405.09673
3.5研究測試:
hujiaoai.cn
4研究測試:
askmanyai.cn
Claude-3研究測試:
hiclaude3.com
?
LoRA方法概述
LoRA的思想非常簡單,對于神經網絡中的某些線性層(比如 Transformer 架構中的多頭自注意力的權重矩陣 Q,K,V 或者前饋神經網絡層的 W),不是直接對這些大參數矩陣的所有元素進行更新,而是引入較小的矩陣 A 和 B,并使得這些較小的矩陣 A 和 B 的乘積可以近似描述原始矩陣 W 的變化。
由于r遠遠小于d,k,僅的參數需要運算,這遠遠小于更新原參數矩陣所需的運算量。而當訓練好新的參數后,利用重參數(reparametrization)的方式,將新參數和原模型參數合并,這樣既能在新任務上到達微調整個模型的效果,又不會在推斷的時候增加推理的耗時。

實驗設置
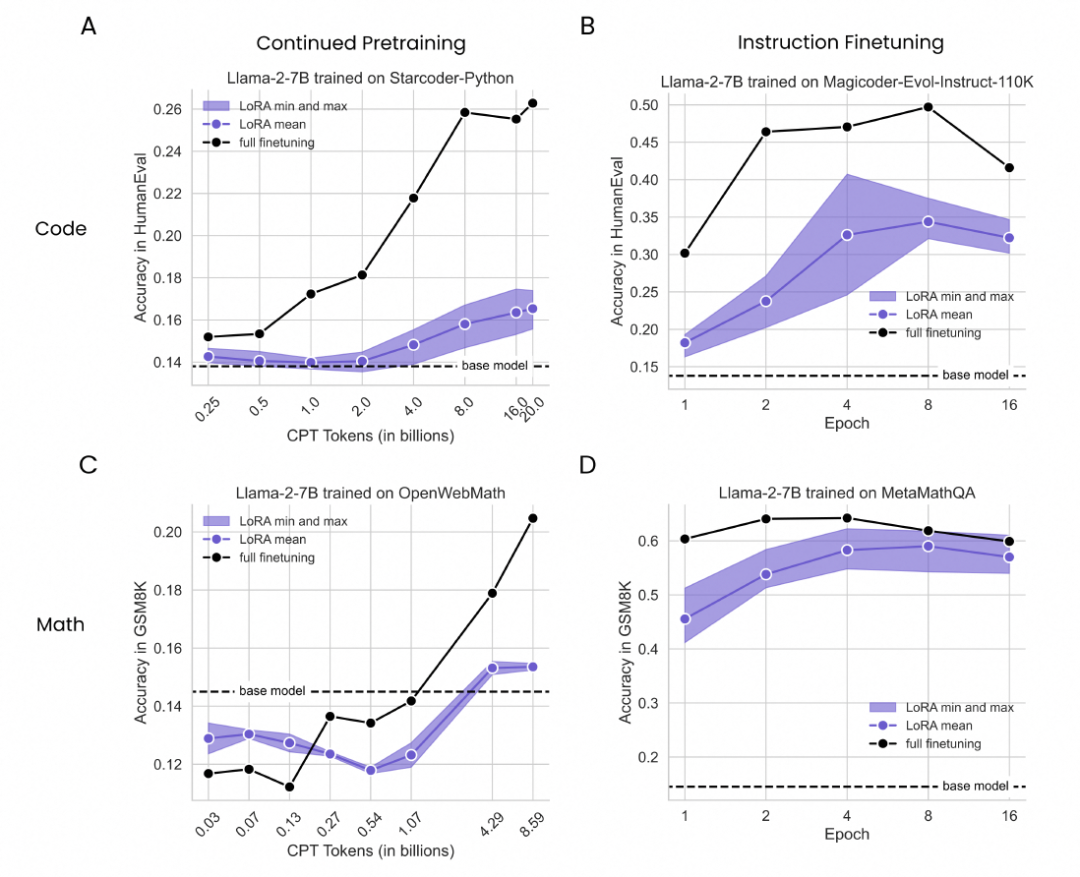
本文選定了編程和數學兩類任務,并分別采用了Starcoder數據的Python部分(20B tokens)和OpenWebMath數據的子集(8.59B tokens)用于編程和數學任務的持續預訓練(Continue Pretraining, CPT); Magicoder-Evol-Instruct-110k數據(72.97M tokens)和MetaMathQA數據(103M tokens)用于編程和數學任務的指令微調(Instruction Finetuning)。對應地,本文選用了HumanEval(164個問題)和GSM8K數據集的測試部分(1319個樣本)作為編程和數學任務的測評數據集。
此外,本文還采用了HellaSwag、WinoGrande和ARC-Challenge數據集,分別用于評估經過不同訓練方式后,模型對于推理、常識推斷和科學概念的遺忘程度。
實驗結果
1. 在編程和數學任務中的表現
在編程和數學任務中,LoRA相比全參數微調表現出明顯的劣勢。盡管如此,LoRA在數學任務中表現稍好,能夠在一定程度上縮小與全參數微調之間的差距。例如,在編程的持續預訓練設定下,使用16B tokens的LoRA在HumanEval基準測試中的最高得分為0.175,而全參數微調在使用1B tokens時的得分就已經達到了0.172,更是在16B tokens達到0.25以上。在數學的指令微調設定下,LoRA在4個訓練周期后的GSM8K得分為0.622,與全參數微調的效果峰值僅相差了2個百分點(0.642)。
2. 在遺忘問題上的表現
總的來說,LoRA在遺忘問題上表現出比全參數微調更好的性能。此外,實驗還發現:(1)相比于持續預訓練,指令微調帶來了更嚴重的遺忘問題;(2)在編程任務上訓練以后,帶來的遺忘相比在數學任務上訓練要更為嚴重;(3)隨著訓練數據量的增大,遺忘問題趨于嚴重。

下圖中的點表示不同訓練階段的個體模型在下游任務(編程/數學)和遺忘方面的表現,相比全參數微調,LoRA學會的東西較少(y軸上的值較低),但遺忘也相對更少(x軸上的值更高)。

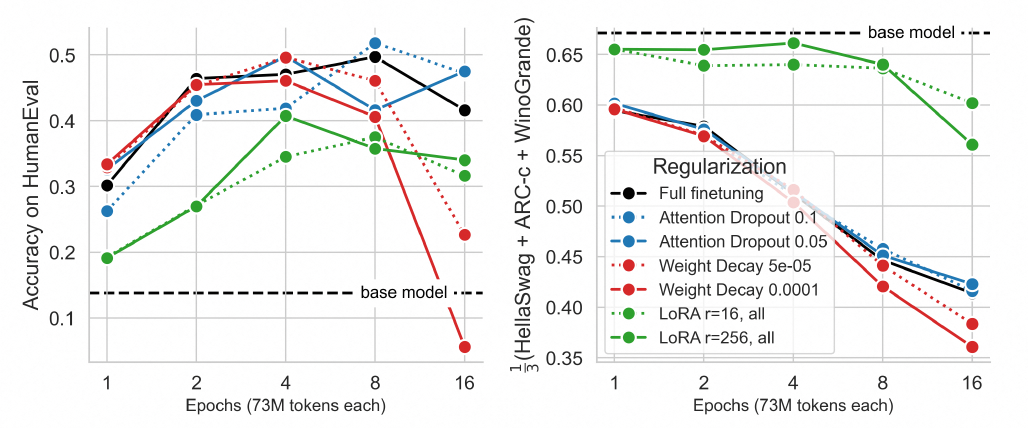
3. LoRA的正則化特性
LoRA提供了比經典正則化技術,如權重衰減和dropout,更強的正則化效果。盡管在下游任務上LoRA的表現低于大多數正則化方法(左圖),但在遺忘上又優于所有正則化方法(右圖)。
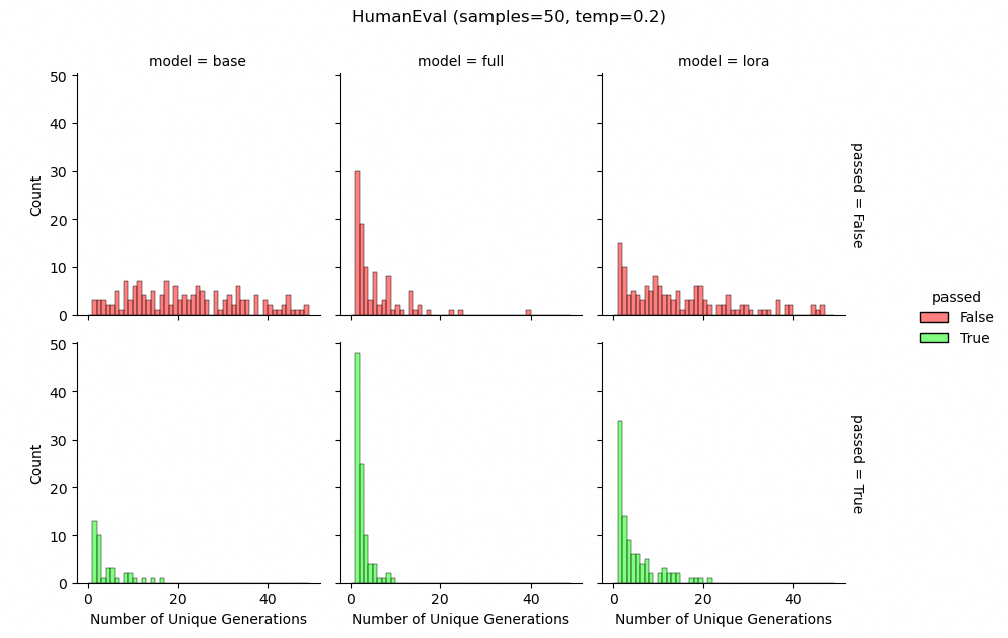
此外,在對編程任務的指令微調設定下,LoRA在生成多樣性上表現更好,維持了與基礎模型更相似的多樣化解決方案。這表明LoRA在輸出層面提供了正則化,有助于保持更多樣化的生成結果。
4. 對編程和數學的全參數微調不會學習低階擾動
本文探討了全參數微調在編程和數學任務中,是否傾向于學習低秩擾動。這是對LoRA方法的一個核心假設的檢驗,即微調大模型時,權重矩陣的擾動通常是低秩的。
通過對基礎模型的權重矩陣、全參數微調后的權重矩陣,以及兩者之間的差異(擾動)進行奇異值分解(Singular Value Decomposition,SVD)分析,發現即使是在早期的訓練階段(例如0.25B tokens時),全參數微調產生的權重矩陣擾動的秩也比典型LoRA高10到100倍。而隨著訓練數據的增加,擾動的秩也隨之增加。此外,多層感知機(MLP)模塊的擾動秩通常比注意力(Attention)模塊的秩要高。模型的第一層和最后一層相比中間層傾向于有更低的秩。
在編程和數學任務中,全參數微調通常不會學習到低秩的權重擾動,這與LoRA方法的假設相悖。這部分的研究結果對LoRA方法在面對類似編程或數學等復雜任務時的有效性提出了質疑。它表明,為了在這些領域達到與全參數微調相當的性能,可能需要考慮更高秩的擾動,這可能會影響LoRA方法的內存效率和適用性。
一方面,本文發現全參數微調找到的權重擾動遠非低秩,這表明LoRA的低秩擾動假設可能不適用于所有情況。另一方面,本文也討論了所用譜分析方法的局限性,指出全參數微調傾向于找到高秩解并不意味著低秩解是不可能的,而是說它們通常不是微調過程中的首選。
結論與實踐建議
LoRA的最佳實踐
LoRA作為一種參數高效的微調方法,盡管在某些情況下未能達到全參數微調的性能,但它在正則化和保持源性能方面表現出色。根據研究,LoRA在學習率選擇上表現出較高的敏感性。與全參數微調相比,LoRA需要更高的學習率才能實現最佳性能,但學習率過高又可能會導致訓練發散。此外,選擇要學習擾動的“目標模塊”比選擇秩大小(rank)更為重要。選擇“所有”(Attention、MLP和它們的聯合)模塊的微調效果優于僅針對“MLP”或“Attention”模塊的微調。
如果要使用LoRA,本文推薦在指令微調階段使用,而不是在持續預訓練階段,并建議至少訓練四個周期(epochs),以充分利用LoRA的潛力。盡管秩的影響較為微妙,但較高的秩(例如256)通常優于較低的秩(例如16),在性能和內存使用之間尋找平衡點,如果內存資源有限,可以選擇較低的秩。
由于LoRA在保持輸出多樣性方面也顯示出優勢,在生成任務中,與全參數微調相比,LoRA能夠維持更高的解決方案多樣性,這對于避免過擬合和增強模型泛化能力是非常有益的。
LoRA的未來研究方向及應用場景
盡管LoRA在某些領域的性能不如全微調,但其在正則化和減少遺忘方面的潛力表明,它仍然是一個值得進一步研究的工具。未來的研究可以探索如何優化LoRA的配置,例如通過自動化搜索最優的學習率和目標模塊配置。
另一個重要的研究方向是探索LoRA在不同模型大小和復雜性條件下的表現。初步研究表明,模型規模可能會影響LoRA與全參數微調之間的性能差距,未來可以在更大或更小的模型上驗證這一點。
總之,LoRA作為一種節省資源的微調方法,在保持模型多樣性和減少遺忘方面具有獨特優勢,值得在未來研究和應用中得到進一步的探索和優化。


)

)
)




安裝)









)
