Python 機器學習 基礎 之 模型評估與改進 【模型評估與改進 / 交叉驗證】的簡單說明
目錄
Python 機器學習 基礎 之 模型評估與改進 【模型評估與改進 / 交叉驗證】的簡單說明
一、簡單介紹
二、模型評估與改進
三、交叉驗證
附錄
一、參考文獻
一、簡單介紹
Python是一種跨平臺的計算機程序設計語言。是一種面向對象的動態類型語言,最初被設計用于編寫自動化腳本(shell),隨著版本的不斷更新和語言新功能的添加,越多被用于獨立的、大型項目的開發。Python是一種解釋型腳本語言,可以應用于以下領域: Web 和 Internet開發、科學計算和統計、人工智能、教育、桌面界面開發、軟件開發、后端開發、網絡爬蟲。
Python 機器學習是利用 Python 編程語言中的各種工具和庫來實現機器學習算法和技術的過程。Python 是一種功能強大且易于學習和使用的編程語言,因此成為了機器學習領域的首選語言之一。Python 提供了豐富的機器學習庫,如Scikit-learn、TensorFlow、Keras、PyTorch等,這些庫包含了許多常用的機器學習算法和深度學習框架,使得開發者能夠快速實現、測試和部署各種機器學習模型。
Python 機器學習涵蓋了許多任務和技術,包括但不限于:
- 監督學習:包括分類、回歸等任務。
- 無監督學習:如聚類、降維等。
- 半監督學習:結合了有監督和無監督學習的技術。
- 強化學習:通過與環境的交互學習來優化決策策略。
- 深度學習:利用深度神經網絡進行學習和預測。
通過 Python 進行機器學習,開發者可以利用其豐富的工具和庫來處理數據、構建模型、評估模型性能,并將模型部署到實際應用中。Python 的易用性和龐大的社區支持使得機器學習在各個領域都得到了廣泛的應用和發展。
二、模型評估與改進
機器學習模型的評估與改進是確保模型性能的關鍵步驟。下面是一些常見的方法和技術,用于評估和改進機器學習模型:
1)交叉驗證
交叉驗證是一種評估模型性能的常用方法,特別是在數據集較小或需要防止過擬合的情況下。
from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_irisiris = load_iris() X, y = iris.data, iris.targetmodel = LogisticRegression(max_iter=200) scores = cross_val_score(model, X, y, cv=5)print("Cross-validation scores:", scores) print("Mean cross-validation score:", scores.mean())2) 網格搜索和隨機搜索
網格搜索(Grid Search)和隨機搜索(Random Search)用于超參數優化,以找到最佳的超參數組合。
from sklearn.model_selection import GridSearchCVparam_grid = {'C': [0.1, 1, 10, 100], 'solver': ['lbfgs', 'saga']} grid_search = GridSearchCV(LogisticRegression(max_iter=200), param_grid, cv=5)grid_search.fit(X, y) print("Best parameters:", grid_search.best_params_) print("Best cross-validation score:", grid_search.best_score_)3)學習曲線
學習曲線用于診斷模型的學習情況,幫助確定模型是否存在過擬合或欠擬合問題。
from sklearn.model_selection import learning_curve import matplotlib.pyplot as plttrain_sizes, train_scores, test_scores = learning_curve(model, X, y, cv=5) train_scores_mean = train_scores.mean(axis=1) test_scores_mean = test_scores.mean(axis=1)plt.plot(train_sizes, train_scores_mean, label="Training score") plt.plot(train_sizes, test_scores_mean, label="Cross-validation score") plt.xlabel("Training examples") plt.ylabel("Score") plt.legend() plt.show()4) 驗證曲線
驗證曲線用于觀察不同超參數對模型性能的影響。
from sklearn.model_selection import validation_curveparam_range = np.logspace(-3, 3, 7) train_scores, test_scores = validation_curve(model, X, y, param_name="C", param_range=param_range, cv=5)train_scores_mean = train_scores.mean(axis=1) test_scores_mean = test_scores.mean(axis=1)plt.plot(param_range, train_scores_mean, label="Training score") plt.plot(param_range, test_scores_mean, label="Cross-validation score") plt.xlabel("Parameter C") plt.ylabel("Score") plt.xscale("log") plt.legend() plt.show()5)特征選擇
特征選擇用于選擇對模型性能有顯著影響的特征,去除不相關或冗余的特征。
from sklearn.feature_selection import SelectKBest, f_classifselector = SelectKBest(f_classif, k=2) X_new = selector.fit_transform(X, y)print("Selected features shape:", X_new.shape)6)管道(Pipeline)
管道用于將多個處理步驟整合到一起,確保在交叉驗證和網格搜索中,數據處理步驟與模型一起執行。
from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScalerpipeline = Pipeline([('scaler', StandardScaler()),('classifier', LogisticRegression(max_iter=200)) ])param_grid = {'classifier__C': [0.1, 1, 10, 100]} grid_search = GridSearchCV(pipeline, param_grid, cv=5)grid_search.fit(X, y) print("Best parameters:", grid_search.best_params_) print("Best cross-validation score:", grid_search.best_score_)7) 模型評估指標
根據具體任務選擇合適的評估指標,如分類任務中的準確率、精確率、召回率、F1-score,回歸任務中的均方誤差、
等。
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_scorey_pred = model.predict(X) print("Accuracy:", accuracy_score(y, y_pred)) print("Precision:", precision_score(y, y_pred, average='macro')) print("Recall:", recall_score(y, y_pred, average='macro')) print("F1 Score:", f1_score(y, y_pred, average='macro'))通過這些方法和技術,機器學習模型的性能可以得到有效的評估和改進。選擇合適的方法取決于具體的任務和數據集的特點。
到目前為止,為了評估我們的監督模型,我們使用?train_test_split?函數將數據集劃分為訓練集和測試集,在訓練集上調用?fit?方法來構建模型,并且在測試集上用?score?方法來評估這個模型——對于分類問題而言,就是計算正確分類的樣本所占的比例。
from sklearn.datasets import make_blobs
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split# 創建一個模擬數據集
X, y = make_blobs(random_state=0)
# 將數據和標簽劃分為訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# 將模型實例化,并用它來擬合訓練集
logreg = LogisticRegression().fit(X_train, y_train)
# 在測試集上評估該模型
print("Test set score: {:.2f}".format(logreg.score(X_test, y_test)))Test set score: 0.88
請記住,之所以將數據劃分為訓練集和測試集,是因為我們想要度量模型對前所未見的新數據的泛化 性能。我們對模型在訓練集上的擬合效果不感興趣,而是想知道模型對于訓練過程中沒有見過的數據的預測能力。
本節我們將從兩個方面進行模型評估。我們首先介紹交叉驗證,然后討論評估分類和回歸性能的方法,其中前者是一種更可靠的評估泛化性能的方法,后者是在默認度量(score 方法給出的精度和 R2 )之外的方法。
我們還將討論網格搜索,這是一種調節監督模型參數以獲得最佳泛化性能的有效方法。
三、交叉驗證
交叉驗證 (cross-validation)是一種評估泛化性能的統計學方法,它比單次劃分訓練集和測試集的方法更加穩定、全面。在交叉驗證中,數據被多次劃分,并且需要訓練多個模型。最常用的交叉驗證是 k 折交叉驗證 (k -fold cross-validation),其中 k 是由用戶指定的數字,通常取 5 或 10。在執行 5 折交叉驗證時,首先將數據劃分為(大致)相等的 5 部分,每一部分叫作折 (fold)。
交叉驗證(Cross-Validation)是機器學習中用于評估模型性能的一種技術。它通過將數據集劃分為多個子集,反復訓練和驗證模型,從而有效地評估模型在未見數據上的表現。以下是交叉驗證的主要方法和步驟:
交叉驗證的主要方法
k折交叉驗證(k-Fold Cross-Validation):
- 將數據集分成k個互不重疊的子集(折),每個子集大小相同。
- 進行k次訓練和驗證,每次使用k-1個子集進行訓練,剩余的一個子集進行驗證。
- 計算k次驗證結果的平均值作為模型的性能指標。
留一法交叉驗證(Leave-One-Out Cross-Validation, LOOCV):
- 是k折交叉驗證的一種特殊情況,其中k等于樣本數量。
- 每次選擇一個樣本作為驗證集,其余樣本作為訓練集。
- 適用于小數據集,但計算開銷較大。
分層k折交叉驗證(Stratified k-Fold Cross-Validation):
- 類似于k折交叉驗證,但在每個折內保持類別分布的一致性。
- 適用于類別不平衡的數據集。
時間序列交叉驗證(Time Series Split):
- 適用于時間序列數據。
- 保持數據的時間順序,防止未來數據泄露到訓練集中。
- 逐步增加訓練集的大小,同時將驗證集設為緊跟在訓練集之后的一段時間。
交叉驗證的優點和局限性
優點:
- 防止過擬合和欠擬合:通過在多個不同的數據集上訓練和驗證模型,交叉驗證可以有效檢測過擬合和欠擬合問題。
- 更穩定和可靠的性能估計:相比單次劃分訓練集和測試集,交叉驗證提供了更穩定和可靠的模型性能估計。
- 充分利用數據:在不同的折中,所有數據點都被用作訓練集和驗證集,充分利用了數據。
局限性:
- 計算開銷大:特別是對于大型數據集或復雜模型,交叉驗證的計算開銷較大。
- 不適用于時間序列數據:標準的交叉驗證方法不適用于時間序列數據,需要使用時間序列交叉驗證方法。
通過交叉驗證,可以更全面地評估模型的性能,從而更好地選擇模型和調節超參數,提高模型在實際應用中的表現。
接下來訓練一系列模型。使用第 1 折作為測試集、其他折(2~5)作為訓練集來訓練第一個模型。利用 2~5 折中的數據來構建模型,然后在 1 折上評估精度。之后構建另一個模型,這次使用 2 折作為測試集,1、3、4、5 折中的數據作為訓練集。利用 3、4、5 折作為測試集繼續重復這一過程。對于將數據劃分為訓練集和測試集的這 5 次劃分 ,每一次都要計算精度。最后我們得到了 5 個精度值。整個過程如圖 5-1 所示。
import mglearn
import matplotlib.pyplot as pltmglearn.plots.plot_cross_validation()plt.tight_layout()
plt.savefig('Images/01CrossValidation-01.png', bbox_inches='tight')
plt.show()
通常來說,數據的前五分之一是第 1 折,第二個五分之一是第 2 折,以此類推。
1、scikit-learn?中的交叉驗證
scikit-learn?是利用?model_selection?模塊中的?cross_val_score?函數來實現交叉驗證的。cross_val_score?函數的參數是我們想要評估的模型、訓練數據與真實標簽。我們在?iris?數據集上對?LogisticRegression?進行評估:
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegressioniris = load_iris()
logreg = LogisticRegression()scores = cross_val_score(logreg, iris.data, iris.target)
print("Cross-validation scores: {}".format(scores))Cross-validation scores: [0.96666667 1. 0.93333333 0.96666667 1. ]
默認情況下,cross_val_score 執行 3 折交叉驗證,返回 3 個精度值。可以通過修改 cv 參數來改變折數:
scores = cross_val_score(logreg, iris.data, iris.target, cv=5)
print("Cross-validation scores: {}".format(scores))Cross-validation scores: [0.96666667 1. 0.93333333 0.96666667 1. ]
總結交叉驗證精度的一種常用方法是計算平均值:
print("Average cross-validation score: {:.2f}".format(scores.mean()))Average cross-validation score: 0.97
我們可以從交叉驗證平均值中得出結論,我們預計模型的平均精度約為 96%。觀察 5 折交叉驗證得到的所有 5 個精度值,我們還可以發現,折與折之間的精度有較大的變化,范圍為從 100% 精度到 90% 精度。這可能意味著模型強烈依賴于將某個折用于訓練,但也可能只是因為數據集的數據量太小。
2、交叉驗證的優點
使用交叉驗證而不是將數據單次劃分為訓練集和測試集,這種做法具有下列優點:
首先,
train_test_split對數據進行隨機劃分。想象一下,在隨機劃分數據時我們很“幸運”,所有難以分類的樣例都在訓練集中。在這種情況下,測試集將僅包含“容易分類的”樣例,并且測試集精度會高得不切實際。相反,如果我們“不夠幸運”,則可能隨機地將所有難以分類的樣例都放在測試集中,因此得到一個不切實際的低分數。但如果使用交叉驗證,每個樣例都會剛好在測試集中出現一次:每個樣例位于一個折中,而每個折都在測試集中出現一次。因此,模型需要對數據集中所有樣本的泛化能力都很好,才能讓所有的交叉驗證得分(及其平均值)都很高。對數據進行多次劃分,還可以提供我們的模型對訓練集選擇的敏感性信息。對于
iris數據集,我們觀察到精度在 90% 到 100% 之間。這是一個不小的范圍,它告訴我們將模型應用于新數據時在最壞情況和最好情況下的可能表現。與數據的單次劃分相比,交叉驗證的另一個優點是我們對數據的使用更加高效。在使用
train_test_split時,我們通常將 75% 的數據用于訓練,25% 的數據用于評估。在使用 5 折交叉驗證時,在每次迭代中我們可以使用 4/5(80%)的數據來擬合模型。在使用 10 折交叉驗證時,我們可以使用 9/10(90%)的數據來擬合模型。更多的數據通常可以得到更為精確的模型。
交叉驗證的主要缺點:
是增加了計算成本。現在我們要訓練?k?個模型而不是單個模型,所以交叉驗證的速度要比數據的單次劃分大約慢?k?倍。
重要的是要記住,交叉驗證不是一種構建可應用于新數據的模型的方法。
交叉驗證不會返回一個模型。在調用?cross_val_score?時,內部會構建多個模型,但交叉驗證的目的只是評估給定算法在特定數據集上訓練后的泛化性能好壞。
3、分層?k?折交叉驗證和其他策略
將數據集劃分為?k?折時,從數據的前?k?分之一開始劃分(正如上一節所述),這可能并不總是一個好主意。例如,我們來看一下?iris?數據集:
from sklearn.datasets import load_iris
iris = load_iris()
print("Iris labels:\n{}".format(iris.target))Iris labels: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 11 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 22 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 22 2]
如你所見,數據的前三分之一是類別 0,中間三分之一是類別 1,最后三分之一是類別 2。想象一下在這個數據集上進行 3 折交叉驗證。第 1 折將只包含類別 0,所以在數據的第一次劃分中,測試集將只包含類別 0,而訓練集只包含類別 1 和 2。由于在 3 次劃分中訓練集和測試集中的類別都不相同,因此這個數據集上的 3 折交叉驗證精度為 0。這沒什么幫助,因為我們在 iris 上可以得到比 0% 好得多的精度。
由于簡單的 k 折策略在這里失效了,所以 scikit-learn 在分類問題中不使用這種策略,而是使用分層 k 折交叉驗證 (stratified k -fold cross-validation)。在分層交叉驗證中,我們劃分數據,使每個折中類別之間的比例與整個數據集中的比例相同,如圖 5-2 所示。
mglearn.plots.plot_stratified_cross_validation()plt.tight_layout()
plt.savefig('Images/01CrossValidation-02.png', bbox_inches='tight')
plt.show()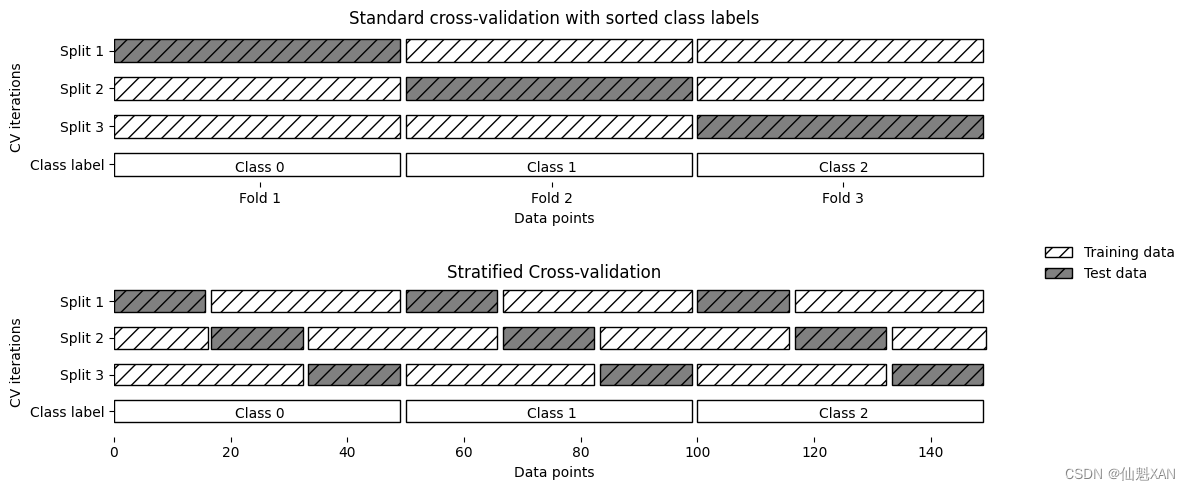
舉個例子,如果 90% 的樣本屬于類別 A 而 10% 的樣本屬于類別 B,那么分層交叉驗證可以確保,在每個折中 90% 的樣本屬于類別 A 而 10% 的樣本屬于類別 B。
使用分層?k?折交叉驗證而不是?k?折交叉驗證來評估一個分類器,這通常是一個好主意,因為它可以對泛化性能做出更可靠的估計。在只有 10% 的樣本屬于類別 B 的情況下,如果使用標準?k?折交叉驗證,很可能某個折中只包含類別 A 的樣本。利用這個折作為測試集的話,無法給出分類器整體性能的信息。
對于回歸問題,scikit-learn?默認使用標準?k?折交叉驗證。也可以嘗試讓每個折表示回歸目標的不同取值,但這并不是一種常用的策略,也會讓大多數用戶感到意外。
1)對交叉驗證的更多控制
我們之前看到,可以利用?cv?參數來調節?cross_val_score?所使用的折數。但?scikit-learn?允許提供一個交叉驗證分離器?(cross-validation splitter)作為?cv?參數,來對數據劃分過程進行更精細的控制。對于大多數使用場景而言,回歸問題默認的?k?折交叉驗證與分類問題的分層?k?折交叉驗證的表現都很好,但有些情況下你可能希望使用不同的策略。比如說,我們想要在一個分類數據集上使用標準?k?折交叉驗證來重現別人的結果。為了實現這一點,我們首先必須從?model_selection?模塊中導入?KFold?分離器類,并用我們想要使用的折數來將其實例化:
from sklearn.model_selection import KFold
kfold = KFold(n_splits=5)然后我們可以將?kfold?分離器對象作為?cv?參數傳入?cross_val_score?:
print("Cross-validation scores:\n{}".format(cross_val_score(logreg, iris.data, iris.target, cv=kfold)))Cross-validation scores: [1. 1. 0.86666667 0.93333333 0.83333333]
通過這種方法,我們可以驗證,在?iris?數據集上使用 3 折交叉驗證(不分層)確實是一個非常糟糕的主意:
kfold = KFold(n_splits=3)
print("Cross-validation scores:\n{}".format(cross_val_score(logreg, iris.data, iris.target, cv=kfold)))請記住,在?iris?數據集中每個折對應一個類別,因此學不到任何內容。解決這個問題的另一種方法是將數據打亂來代替分層,以打亂樣本按標簽的排序。可以通過將?KFold?的?shuffle?參數設為?True?來實現這一點。如果我們將數據打亂,那么還需要固定?random_state?以獲得可重復的打亂結果。否則,每次運行?cross_val_score?將會得到不同的結果,因為每次使用的是不同的劃分(這可能并不是一個問題,但可能會出人意料)。在劃分數據之前將其打亂可以得到更好的結果:
kfold = KFold(n_splits=3, shuffle=True, random_state=0)
print("Cross-validation scores:\n{}".format(cross_val_score(logreg, iris.data, iris.target, cv=kfold)))
Cross-validation scores: [0.98 0.96 0.96]
2)留一法交叉驗證
另一種常用的交叉驗證方法是留一法?(leave-one-out)。你可以將留一法交叉驗證看作是每折只包含單個樣本的?k?折交叉驗證。對于每次劃分,你選擇單個數據點作為測試集。這種方法可能非常耗時,特別是對于大型數據集來說,但在小型數據集上有時可以給出更好的估計結果:
from sklearn.model_selection import LeaveOneOut
loo = LeaveOneOut()
scores = cross_val_score(logreg, iris.data, iris.target, cv=loo)
print("Number of cv iterations: ", len(scores))
print("Mean accuracy: {:.2f}".format(scores.mean()))Number of cv iterations: 150 Mean accuracy: 0.97
3)打亂劃分交叉驗證
另一種非常靈活的交叉驗證策略是打亂劃分交叉驗證?(shuffle-split cross-validation)。在打亂劃分交叉驗證中,每次劃分為訓練集取樣?train_size?個點,為測試集取樣?test_size?個(不相交的)點。將這一劃分方法重復?n_iter?次。圖 5-3 顯示的是對包含 10 個點的數據集運行 4 次迭代劃分,每次的訓練集包含 5 個點,測試集包含 2 個點(你可以將?train_size?和?test_size?設為整數來表示這兩個集合的絕對大小,也可以設為浮點數來表示占整個數據集的比例):
mglearn.plots.plot_shuffle_split()plt.tight_layout()
plt.savefig('Images/01CrossValidation-03.png', bbox_inches='tight')
plt.show()
下面的代碼將數據集劃分為 50% 的訓練集和 50% 的測試集,共運行 10 次迭代? :
from sklearn.model_selection import ShuffleSplit
shuffle_split = ShuffleSplit(test_size=.5, train_size=.5, n_splits=10)
scores = cross_val_score(logreg, iris.data, iris.target, cv=shuffle_split)
print("Cross-validation scores:\n{}".format(scores))
Cross-validation scores: [0.92 0.97333333 0.94666667 0.96 0.94666667 0.960.96 0.93333333 0.96 0.96 ]
打亂劃分交叉驗證可以在訓練集和測試集大小之外獨立控制迭代次數,這有時是很有幫助的。它還允許在每次迭代中僅使用部分數據,這可以通過設置?train_size?與?test_size?之和不等于 1 來實現。用這種方法對數據進行二次采樣可能對大型數據上的試驗很有用。
ShuffleSplit?還有一種分層的形式,其名稱為?StratifiedShuffleSplit?,它可以為分類任務提供更可靠的結果。
4)分組交叉驗證
另一種非常常見的交叉驗證適用于數據中的分組高度相關時。比如你想構建一個從人臉圖片中識別情感的系統,并且收集了 100 個人的照片的數據集,其中每個人都進行了多次拍攝,分別展示了不同的情感。我們的目標是構建一個分類器,能夠正確識別未包含在數據集中的人的情感。你可以使用默認的分層交叉驗證來度量分類器的性能。但是這樣的話,同一個人的照片可能會同時出現在訓練集和測試集中。對于分類器而言,檢測訓練集中出現過的人臉情感比全新的人臉要容易得多。因此,為了準確評估模型對新的人臉的泛化能力,我們必須確保訓練集和測試集中包含不同人的圖像。
為了實現這一點,我們可以使用?GroupKFold?,它以?groups?數組作為參數,可以用來說明照片中對應的是哪個人。這里的?groups?數組表示數據中的分組,在創建訓練集和測試集的時候不應該將其分開,也不應該與類別標簽弄混。
數據分組的這種例子常見于醫療應用,你可能擁有來自同一名病人的多個樣本,但想要將其泛化到新的病人。同樣,在語音識別領域,你的數據集中可能包含同一名發言人的多條記錄,但你希望能夠識別新的發言人的講話。
下面這個示例用到了一個由?groups?數組指定分組的模擬數據集。這個數據集包含 12 個數據點,且對于每個數據點,groups?指定了該點所屬的分組(想想病人的例子)。一共分成 4 個組,前 3 個樣本屬于第一組,接下來的 4 個樣本屬于第二組,以此類推:
from sklearn.model_selection import GroupKFold
from sklearn.datasets import make_blobs# 創建模擬數據集
X, y = make_blobs(n_samples=12, random_state=0)
# 假設前3個樣本屬于同一組,接下來的4個屬于同一組,以此類推
groups = [0, 0, 0, 1, 1, 1, 1, 2, 2, 3, 3, 3]
# 使用 GroupKFold 進行交叉驗證
scores = cross_val_score(logreg, X, y, groups=groups, cv=GroupKFold(n_splits=3))
print("Cross-validation scores:\n{}".format(scores))Cross-validation scores: [0.75 0.6 0.66666667]
樣本不需要按分組進行排序,我們這么做只是為了便于說明。基于這些標簽計算得到的劃分如圖 5-4 所示。如你所見,對于每次劃分,每個分組都是整體出現在訓練集或測試集中:
mglearn.plots.plot_group_kfold()plt.tight_layout()
plt.savefig('Images/01CrossValidation-04.png', bbox_inches='tight')
plt.show()
scikit-learn 中還有很多交叉驗證的劃分策略,適用于更多的使用場景 [ 你可以在?scikit-learn?的用戶指南頁面查看這些內容(3.1. Cross-validation: evaluating estimator performance — scikit-learn 1.5.0 documentation?)]。但標準的?KFold?、StratifiedKFold?和?GroupKFold?是目前最常用的幾種。
附錄
一、參考文獻
參考文獻:[德] Andreas C. Müller [美] Sarah Guido 《Python Machine Learning Basics Tutorial》






)
:AVL樹)
建模、調優)


)






)
