辦公自動化-Python如何提取Word標題并保存到Excel中?
- 應用場景
- 需求分析
- 實現思路
- 實現過程
- 安裝依賴庫
- 打開需求文件
- 獲取word中所有標題
- 去除不需要的標題
- 創建工作簿和工作表
- 分割標題
- 功能名稱存入測試對象
- GN-TC+需求標識符存入測試項標識
- 存入需求標識符
- 完整源碼
- 實現效果
- 學習總結
應用場景
-
為啥要提這個話題呢?測試小伙伴遇到一個問題,他的痛點是想把需求文檔(word版)中的需求標識符、功能名稱,挨個復制到測試計劃中;
-
這對他來說是非常痛苦的,如果需求文檔內容過于龐大,對他來說,需要好幾天才能復制完這些標識符;
-
具體的比如以下word:

-
他想把以上word標題中的標識符和名稱復制到如下表格中:
| 測試對象 | 測試項標識 | 需求標識 |
|---|---|---|
| 組織管理 | GN-TC-US-ADMIN-ZZGL | US-ADMIN-ZZGL |
| 組織管理 | GN-TC-US-ADMIN-ZZGL | US-ADMIN-ZZGL |
| 組織管理 | GN-TC-US-ADMIN-ZZGL | US-ADMIN-ZZGL |
| 組織管理 | GN-TC-US-ADMIN-ZZGL | US-ADMIN-ZZGL |
| 組織管理 | GN-TC-US-ADMIN-ZZGL | US-ADMIN-ZZGL |
- 針對這個簡單的需求如何用python來實現呢?
需求分析
- 需求的標題為:序號+[標識符]+功能名稱;
- 測試計劃中表格內容:
| 字段 | 說明 |
|---|---|
| 測試對象 | 對應需求中的功能名稱 |
| 測試項標識 | GN-TC+需求中的標識符 |
| 需求標識符 | 需求中的標識符 |
- 經過分析,其實就是把需求中的標題提取出來,然后進行分割,分別寫入測試計劃對應的表格中即可。
實現思路
- 打開指定目錄下的需求文檔;
- 獲取需求文檔中的所有標題;
- 當標題中只有符號“[” 和 "]"時列表;
- 創建excel工作簿;
- 新建工作表;
- 給工作標添加表頭,比如測試對象、測試項標識、需求標識;
- 分割獲取到的標題并存入excel對應的表頭下。
實現過程
安裝依賴庫
- 我們使用Python的python-docx庫和openpyxl庫進行以上內容實現;
- 那么需要安裝這兩個庫:
pip install python-docx
pip install openpyxl
- 如果沒有網絡,需要在本地單獨安裝,python-docx有以下兩個依賴 lxml和typing-extensions:
C:\Users\Administrator>pip install python-docx
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: python-docx in d:\python37\lib\site-packages (1.1.0)
Requirement already satisfied: lxml>=3.1.0 in d:\python37\lib\site-packages (from python-docx) (4.6.3)
Requirement already satisfied: typing-extensions in d:\python37\lib\site-packages (from python-docx) (4.7.1)
- 如果沒有網絡,需要在本地單獨安裝,openpyxl有以下兩個依賴 jdcal和 et-xmlfile:
C:\Users\Administrator>pip install openpyxl
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: openpyxl in d:\python37\lib\site-packages (3.0.5)
Requirement already satisfied: jdcal in d:\python37\lib\site-packages (from openpyxl) (1.4.1)
Requirement already satisfied: et-xmlfile in d:\python37\lib\site-packages (from openpyxl) (1.0.1)
打開需求文件
- 需要導入對應的庫;
- 文件名稱寫自己的需求文件即可;
import docx
from openpyxl import Workbookdoc = docx.Document("./XX需求.docx")
獲取word中所有標題
- 先創建和列表用于存放標題;
headings = []for para in doc.paragraphs:if para.style.name.startswith('Heading'):headings.append(para.text)
print(headings)
- 此時會輸出所有的標題:
['XX管理系統', '[US-ADMIN]ADMIN', '[US-ADMIN-ZZGL]組織管理',
'[US-ADMIN-ZZGL-YHGL]用戶管理', '功能描述', '輸入輸出',
'數據流向', '[US-ADMIN-ZZGL-JGYHGL]機構用戶管理', '功能描述',
'輸入輸出', '數據流向', ' [US-ADMIN-PZGL]配置管理',
'[US-ADMIN-PZGL-ZZJG]組織機構', '功能描述', '輸入輸出',
'數據流向', '[US-ADMIN-PZGL-GWXX]崗位信息', '功能描述',
'輸入輸出', '數據流向', ' [US-ADMIN-PZGL-JSXX]角色信息','功能描述', '輸入輸出', '數據流向', ' [US-AQGLY]SUPERADMIN','[US-SUPERADMIN-XTPZ]系統配置', ' [US-SUPERADMIN-XTPZ-PZGL]配置管理','功能描述', '輸入輸出', '數據流向', '[US-SUPERADMIN-YHPZ]用戶配置','[US-SUPERADMIN-YHPZ-YHJS]用戶角色', '功能描述', '輸入輸出', '數據流向', '[ US-SUPERADMIN-YHPZ-QXFP]權限分配', '功能描述', '數據流向', '[US-SUPERADMIN-YHPZ-CZMM]重置密碼', '功能描述', '輸入輸出', '數據流向', '[US-SUPERADMIN-RZ]日志', '功能描述', '輸入輸出', '數據流向']
去除不需要的標題
- 以上獲取所有標題后,有的不是我們想要的;
- 比如功能描述、輸入輸出、數據流向等標題是不需要的;
- 我們需要的標題是比如[US-SUPERADMIN-RZ]日志;
- 標題獲取后判斷是否有符號“[” 和 “]”,如果有,再存入列表;
headings = []for para in doc.paragraphs:if para.style.name.startswith('Heading'):if '[' in para.text or ']' in para.text:headings.append(para.text)
print(headings)
- 此時就去掉了多余的標題內容:
['[US-ADMIN]ADMIN', '[US-ADMIN-ZZGL]組織管理',
'[US-ADMIN-ZZGL-YHGL]用戶管理', '[US-ADMIN-ZZGL-JGYHGL]機構用戶管理',
' [US-ADMIN-PZGL]配置管理', '[US-ADMIN-PZGL-ZZJG]組織機構','[US-ADMIN-PZGL-GWXX]崗位信息', ' [US-ADMIN-PZGL-JSXX]角色信息', ' [US-AQGLY]SUPERADMIN', '[US-SUPERADMIN-XTPZ]系統配置', ' [US-SUPERADMIN-XTPZ-PZGL]配置管理', '[US-SUPERADMIN-YHPZ]用戶配置', '[US-SUPERADMIN-YHPZ-YHJS]用戶角色', '[ US-SUPERADMIN-YHPZ-QXFP]權限分配', '[US-SUPERADMIN-YHPZ-CZMM]重置密碼', '[US-SUPERADMIN-RZ]日志']
創建工作簿和工作表
- 創建一個工作簿;
- 然后在工作簿中創建一個工作表;
- 并在工作表中設置表頭為測試對象、測試項標識、需求標識;
wb = Workbook()sheet = wb.create_sheet("data")# ws = wb.active
headers = ['測試對象', '測試項標識', '需求標識符']
for col_num, header in enumerate(headers, start=1):sheet.cell(row=1, column=col_num, value=header)
分割標題
- 去掉標題中的左書名號"[";
- 使用右書名號“]”進行分割,左邊即為需求標識符,右邊即為功能名稱;
- 拼接測試項標題為GN-TC+需求標識符:
c3 = []
c5 = []
c7 = []
for content in headings:c1 = content.strip('[')c2 = c1.split(']')[0]c3.append(c2)c4 = c1.split(']')[1]c5.append(c4)c6 = 'GN-TC-' + c2c7.append(c6)print(c1)
print(c3)
print(c5)
print(c7)
- 其中c1為去掉所有左書名號:
US-ADMIN]ADMIN
US-ADMIN-ZZGL]組織管理
US-ADMIN-ZZGL-YHGL]用戶管理
US-ADMIN-ZZGL-JGYHGL]機構用戶管理[US-ADMIN-PZGL]配置管理
US-ADMIN-PZGL-ZZJG]組織機構
US-ADMIN-PZGL-GWXX]崗位信息[US-ADMIN-PZGL-JSXX]角色信息[US-AQGLY]SUPERADMIN
US-SUPERADMIN-XTPZ]系統配置[US-SUPERADMIN-XTPZ-PZGL]配置管理
US-SUPERADMIN-YHPZ]用戶配置
US-SUPERADMIN-YHPZ-YHJS]用戶角色US-SUPERADMIN-YHPZ-QXFP]權限分配
US-SUPERADMIN-YHPZ-CZMM]重置密碼
US-SUPERADMIN-RZ]日志
- c3所有需求標識符:
['US-ADMIN', 'US-ADMIN-ZZGL', 'US-ADMIN-ZZGL-YHGL','US-ADMIN-ZZGL-JGYHGL', ' [US-ADMIN-PZGL', 'US-ADMIN-PZGL-ZZJG', 'US-ADMIN-PZGL-GWXX', ' [US-ADMIN-PZGL-JSXX', ' [US-AQGLY','US-SUPERADMIN-XTPZ', ' [US-SUPERADMIN-XTPZ-PZGL', 'US-SUPERADMIN-YHPZ','US-SUPERADMIN-YHPZ-YHJS', ' US-SUPERADMIN-YHPZ-QXFP', 'US-SUPERADMIN-YHPZ-CZMM', 'US-SUPERADMIN-RZ']
- c5功能名稱:
['ADMIN', '組織管理', '用戶管理', '機構用戶管理',
'配置管理', '組織機構', '崗位信息', '角色信息',
'SUPERADMIN', '系統配置', '配置管理', '用戶配置',
'用戶角色', '權限分配', '重置密碼', '日志']
- c7測試項名稱:
[
'GN-TC-US-ADMIN',
'GN-TC-US-ADMIN-ZZGL',
'GN-TC-US-ADMIN-ZZGL-YHGL',
'GN-TC-US-ADMIN-ZZGL-JGYHGL',
'GN-TC-US-ADMIN-PZGL',
'GN-TC-US-ADMIN-PZGL-ZZJG',
'GN-TC-US-ADMIN-PZGL-GWXX',
'GN-TC-US-ADMIN-PZGL-JSXX',
'GN-TC-US-AQGLY',
'GN-TC-US-SUPERADMIN-XTPZ',
'GN-TC-US-SUPERADMIN-XTPZ-PZGL',
'GN-TC-US-SUPERADMIN-YHPZ',
'GN-TC-US-SUPERADMIN-YHPZ-YHJS',
'GN-TC-US-SUPERADMIN-YHPZ-QXFP',
'GN-TC-US-SUPERADMIN-YHPZ-CZMM',
'GN-TC-US-SUPERADMIN-RZ']
功能名稱存入測試對象
for i, heading in enumerate(c5):sheet.cell(row=i+2, column=1, value=heading)
GN-TC+需求標識符存入測試項標識
for i, heading in enumerate(c7):sheet.cell(row=i+2, column=2, value=heading)
存入需求標識符
for i, heading in enumerate(c3):sheet.cell(row=i+2, column=3, value=heading)
完整源碼
# -*- coding:utf-8 -*-
# 作者:蟲無涯
# 日期:2024/5/23
# 文件名稱:test_word.pyimport docx
from openpyxl import Workbookdoc = docx.Document("./XX需求.docx")headings = []for para in doc.paragraphs:if para.style.name.startswith('Heading'):if '[' in para.text or ']' in para.text:headings.append(para.text)
# print(headings)wb = Workbook()sheet = wb.create_sheet("data")# ws = wb.active
headers = ['測試對象', '測試項標識', '需求標識符']
for col_num, header in enumerate(headers, start=1):sheet.cell(row=1, column=col_num, value=header)# print(headings)c3 = []
c5 = []
c7 = []
for content in headings:c1 = content.strip('[')c2 = c1.split(']')[0]c3.append(c2)c4 = c1.split(']')[1]c5.append(c4)c6 = 'GN-TC-' + c2c7.append(c6)
# print(c1)
# print(c3)
# print(c5)
# print(c7)for i, heading in enumerate(c5):sheet.cell(row=i+2, column=1, value=heading)for i, heading in enumerate(c7):sheet.cell(row=i+2, column=2, value=heading)for i, heading in enumerate(c3):sheet.cell(row=i+2, column=3, value=heading)wb.save('./data.xlsx')
實現效果
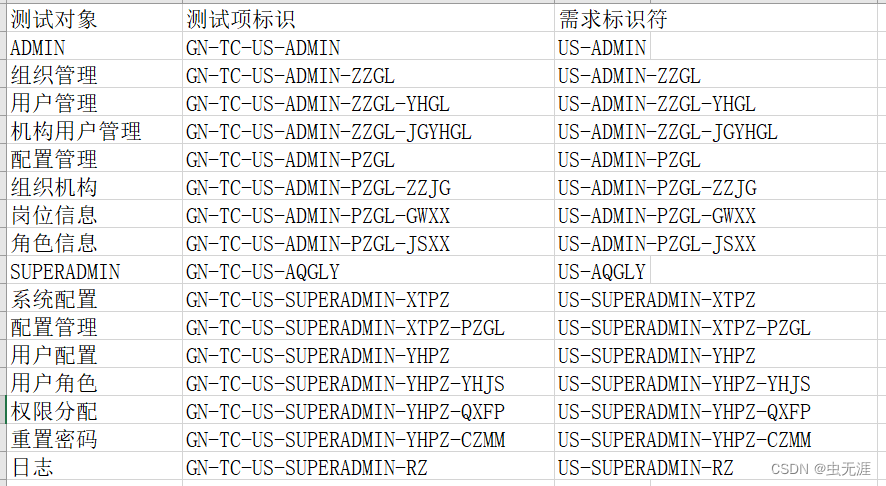
學習總結
以上還有優化的空間,比如:
- 字符串中間有空格或者其他多余的內容如何處理?
- 新建的excel如何對表頭進行字體、顏色等設置?
- 表格列寬如何調整?
- 整個表格字體如何設置?
等等。



![c語言:利用隨機函數產生20個[120, 834] 之間互不相等的隨機數, 并利用選擇排序法將其從小到大排序后輸出(每行輸出5個)](http://pic.xiahunao.cn/c語言:利用隨機函數產生20個[120, 834] 之間互不相等的隨機數, 并利用選擇排序法將其從小到大排序后輸出(每行輸出5個))
)











![BUUCTF---misc---[MRCTF2020]ezmisc](http://pic.xiahunao.cn/BUUCTF---misc---[MRCTF2020]ezmisc)


