Redis
set get del keys
redis中有哪些數據類型
string
最大512m
key層級
redis的key允許有多個單詞形成層級結構,多個單詞之間用‘:’隔開
set get del keys
hash
本身在redis中存儲方式就為key-value, 而hash數據結構中value又是一對key-value
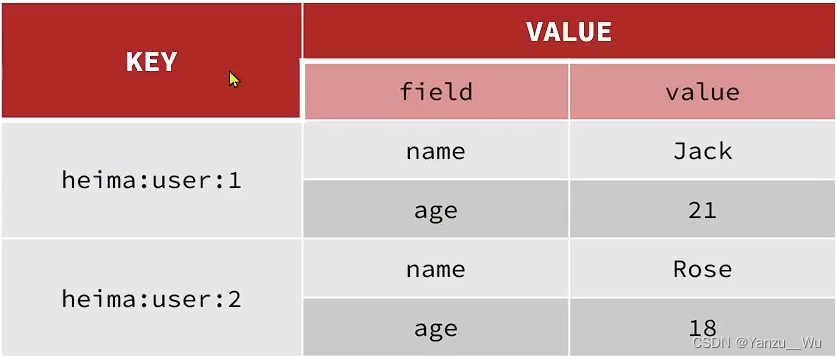
hset key field value
hget key field
hdel
hkeys
list
雙向鏈表,元素可重復
lpush key element
lpop key?
rpush? key element
rpop key
lrange key start end
set
底層是hash表
無序,不可重復
查找快,支持交際并集差集等集合操作
SADD key member
SREM key member
SISMEMBER
SMEMBERS
SINTER key1 key2 交集
SDIFF key1 key2 差集
SUNION key1 key2 并集?
sorted set
底層是跳表+hash表
sorted中每個元素都帶score屬性,根據score屬性排序
特點:可排序,元素不可重復,查詢速度快
ZADD key score member
ZREM ket member
ZDIFF,ZINTER,ZUNION:求差集,交集,并集
持久化是什么,持久化aof和rdb
redis是基于內存的,因此如果遭遇斷電的情況,會導致數據丟失,這對一個數據庫而言是致命的
持久化就是指將Redis服務器中的數據保存到磁盤上,以防止數據在服務器重啟或宕機時丟失。
redis有兩種方式保障數據,一個是rdb(redis database),另一個是aof(Append only file)
rdb是每隔一定的時間間隔,對數據庫進行一次快照,并保存至磁盤中
aof是在執行寫命令是,不僅會將數據寫入到內存中,還會將寫操作追加到aof文件中,它會以日志的形式來記錄每一個寫操作,在redis重啟后,通過重新執行aof文件中的命令,來恢復數據
緩存穿透,緩存擊穿,緩存雪崩
緩存穿透、緩存擊穿和緩存雪崩是三種常見的緩存相關問題,它們有著不同的特點和原因:
1、緩存穿透是指,客戶端查詢到了根本不存在的數據,使得這個請求直達存儲層,導致負載過大造成數據庫宕機。2、緩存擊穿主要是指一個非常大的熱點數據緩存失效導致所有請求直達存儲層,導致服務崩潰。3、緩存雪崩是指某一時刻緩存層無法繼續提供服務,導致所有請求直達存儲層,造成數據庫宕機。
?
-
緩存穿透(Cache Penetration):
- 定義:緩存穿透是指惡意用戶或者非法請求頻繁訪問緩存中不存在的數據,導致這些請求直接穿透緩存層,直接訪問后端存儲系統。
- 原因:通常是因為用戶查詢了不存在的數據,或者攻擊者故意發起惡意請求。這種情況下,每次請求都會直接訪問后端存儲系統,造成系統資源浪費和性能下降。
- 解決方案:可以通過在緩存層增加布隆過濾器等機制來過濾掉不存在的請求,或者在后端存儲系統中添加空值緩存來防止穿透。
-
緩存擊穿(Cache Breakdown):
- 定義:緩存擊穿是指某一個熱點數據突然失效或者被刪除,導致大量的請求直接訪問后端存儲系統,造成后端存儲系統負載劇增和性能下降的情況。
- 原因:通常是因為某一個熱點數據的緩存失效了,或者緩存設置了較短的過期時間。當大量請求同時到達時,會直接訪問后端存儲系統,造成擊穿現象。
- 解決方案:延長熱點數據緩存時間:針對熱點數據,可以將其緩存設置為永久有效,或者設置一個較長的過期時間,以減少因緩存失效而導致的擊穿問題。? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?加鎖:在緩存失效時,可以使用分布式鎖等機制來避免同時訪問后端存儲系統,從而降低因擊穿而導致的請求壓力。
-
緩存雪崩(Cache Avalanche):
- 定義:緩存雪崩是指緩存中的大量數據同時失效,導致大量請求直接訪問后端存儲系統,造成后端存儲系統負載劇增和性能下降的情況。
- 原因:通常是因為緩存中的數據過期時間設置過于集中,或者緩存服務器故障等原因導致大量緩存同時失效。當大量請求同時到達時,會直接訪問后端存儲系統,造成雪崩現象。
- 解決方案:隨機過期時間:對緩存中的數據設置隨機的過期時間,可以避免大量緩存同時失效,從而減少緩存雪崩的發生。? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?熱點數據預熱:在緩存中預先加載熱點數據,可以避免因緩存失效而導致的大量請求直接訪問后端存儲系統。可以通過定時任務或者手動觸發的方式進行熱點數據的預熱。
redis 為什么讀取速度那么塊
Redis 讀取速度快的主要原因有以下幾點:
-
內存存儲:Redis 將數據存儲在內存中,讀取數據時直接從內存中獲取,而不需要像傳統數據庫一樣進行磁盤 I/O 操作,因此讀取速度非常快。
-
單線程模型:Redis 使用單線程模型來處理客戶端請求,避免了多線程之間的上下文切換和鎖競爭,提高了讀取速度。
-
非阻塞 I/O:Redis 使用非阻塞 I/O 處理網絡請求,當客戶端發起讀取請求時,Redis 會立即返回數據,而不需要等待數據讀取完成,進一步提高了讀取速度。
-
高效的數據結構:Redis 提供了豐富而高效的數據結構,如字符串、哈希、列表、集合、有序集合等,這些數據結構的實現都經過了優化,能夠在內存中高效存儲和訪問數據。
-
事件驅動:Redis 使用事件驅動模型處理客戶端請求,采用事件循環機制監聽和處理事件,避免了線程阻塞和等待,提高了系統的并發處理能力和讀取速度。
-
預編譯指令:Redis 采用了預編譯的方式處理客戶端請求,將一些常用的操作編譯成底層的指令,減少了解析和執行的時間,提高了讀取速度。
為什么redis6.0要引入多線程
Redis 6.0引入多線程主要是為了提高性能和利用多核處理器的能力。在傳統的Redis版本中,采用單線程的事件循環模型,這意味著無法充分利用多核處理器的優勢
通過引入多線程,Redis可以將工作負載分布到多個線程上,從而更好地利用多核處理器的能力。這樣可以提高Redis在多核處理器上的并發性能和吞吐量,使其更適合處理大規模的并發請求。
在Redis 6.0中,引入了多線程處理網絡 I/O 操作,但主要的數據處理仍然是在單線程中完成的。這種設計被稱為“多線程非阻塞 I/O”。
在這種模型下,Redis的主線程仍然負責執行命令的解析、執行以及數據處理等核心任務,而多個 I/O 線程負責處理網絡 I/O 操作,如接受新的客戶端連接、讀取和寫入數據等。這樣可以在一定程度上提高網絡 I/O 的并發處理能力,減少了主線程在等待 I/O 完成時的空閑時間,從而提升了整體的性能表現。
采用多線程處理網絡 I/O 操作的好處在于可以更充分地利用多核處理器的優勢,提高了 Redis 在處理大量并發連接時的性能表現。同時,這種設計也避免了傳統多線程模型中因線程切換而帶來的額外開銷和復雜性。
)










)



SQL優化基礎(三):看懂執行計劃順序)



