節前,我們星球組織了一場算法崗技術&面試討論會,邀請了一些互聯網大廠朋友、參加社招和校招面試的同學.
針對算法崗技術趨勢、大模型落地項目經驗分享、新手如何入門算法崗、該如何準備、面試常考點分享等熱門話題進行了深入的討論。
匯總合集:《大模型實戰寶典》(2024版)正式發布!
我們已經進入了一個大規模使用大型語言模型(LLM)的年代。無論是簡單的搜索引擎還是功能廣泛的聊天機器人,LLM都在滿足各類業務需求方面發揮了重要作用。
企業經常需要的一種工具是問答(QA)機器人。這是一種由AI驅動的工具,能夠快速回答用戶輸入的問題。
在本文中,我們將開發一種結合RAG和文本轉語音(TTS)功能的QA-LLM機器人。
我們該如何實現呢?讓我們一探究竟。
項目結構
在這個項目中,我們將遵循以下結構。

項目將遵循以下步驟:
- 使用 Docker 部署開源的 Weaviate 向量數據庫。
- 閱讀《保險手冊》PDF 文件,并使用 HuggingFace 公共托管的嵌入模型對數據進行嵌入。
- 將嵌入存儲到 Weaviate 向量存儲(知識庫)中。
- 使用 HuggingFace 公共托管的嵌入模型和生成模型開發 RAG 系統。
- 使用 ElevenLabs 的文本轉語音模型將 RAG 輸出轉換為音頻。
- 使用 Streamlit 創建前端。
總體來說,我們將遵循這 6 個步驟來創建帶有 RAG 和 TTS 的問答工具。
現在開始吧。
準備工作
在開始之前,我們需要準備一些包含所有需求的 Python 文件,以確保我們的應用程序能夠正常運行。
首先,我們需要 HuggingFace API 訪問令牌,因為我們將使用托管在那里的模型。如果你已經在 HuggingFace 注冊,可以在令牌頁面獲取它們。
此外,我們將使用 ElevenLabs 的文本轉語音模型。因此,請注冊他們的免費帳戶并獲取 API 密鑰。
拿到這兩個 API 密鑰后,你需要創建一個 .env 文件來存儲這些密鑰。將以下代碼填入該文件:
ELEVENLABS_API_KEY= 'Your-ElevenLabs-API'
HUGGINGFACEHUB_API_TOKEN = 'Your-HuggingFace-API'
接下來,我們將通過安裝所有必要的包來設置環境:
pip install langchain langchain-community langchain-core weaviate-client elevenlabs streamlit python-dotenv huggingface_hub sentence-transformers
準備工作完成后,讓我們開始創建應用程序。
部署 Weaviate 向量數據庫
對于本教程,你需要安裝 Docker Desktop。如果還沒有安裝,可以在 Docker 網站上下載安裝程序。
為了輕松部署 Weaviate 向量數據庫,我們將遵循 Weaviate 的設置建議。在部署過程中,我們將使用 docker-compose 進行部署,你可以在下面的代碼中看到:
version: '3.4'
services:weaviate:command:- --host- 0.0.0.0- --port- '8081'- --scheme- httpimage: cr.weaviate.io/semitechnologies/weaviate:1.24.10ports:- 8081:8081- 50051:50051volumes:- weaviate_data:/var/lib/weaviaterestart: on-failure:0environment:QUERY_DEFAULTS_LIMIT: 25AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'PERSISTENCE_DATA_PATH: '/var/lib/weaviate'DEFAULT_VECTORIZER_MODULE: 'none'ENABLE_MODULES: 'text2vec-cohere,text2vec-huggingface,text2vec-palm,text2vec-openai,generative-openai,generative-cohere,generative-palm,ref2vec-centroid,reranker-cohere,qna-openai'CLUSTER_HOSTNAME: 'node1'
volumes:weaviate_data:
在你選擇的環境中,創建一個名為 docker-compose.yml 的文件,并復制上述代碼。上述代碼將從 Weaviate 拉取鏡像,并包含所有相關模塊。這段代碼還將通過 PERSISTENCE_DATA_PATH 提供數據持久化。Weaviate 向量存儲也會暴露在端口 8081。
一切準備就緒后,在終端中運行以下代碼:
docker-compose up

在 Docker Desktop 中,你應該會看到類似上面的容器。這樣,我們已經設置好了開源向量數據庫。
構建保險手冊知識庫
項目的下一部分是使用 LangChain、HuggingFace 和 Weaviate 構建知識庫。此部分的目標是構建一個向量數據庫,該數據庫包含來自《保險手冊》的嵌入結果,可以從應用程序中訪問。
首先,我們將設置 Weaviate 客戶端和嵌入模型。可以使用以下代碼進行設置:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Weaviate
import weaviateclient = weaviate.Client(url="http://localhost:8081",
)model_name = "sentence-transformers/all-mpnet-base-v2"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}hf = HuggingFaceEmbeddings(model_name=model_name,model_kwargs=model_kwargs,encode_kwargs=encode_kwargs
)
在上面的代碼中,我們通過連接到 localhost:8081 來設置 Weaviate 客戶端,并使用簡單的 mpnet 句子轉換模型設置 HuggingFace 嵌入模型。
接下來,我們將使用 LangChain 讀取《保險手冊》PDF 并將文本數據分割成一定的塊。
loader = PyPDFLoader("Insurance_Handbook_20103.pdf")
pages = loader.load_and_split()text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=50,length_function=len,is_separator_regex=False,
)texts = text_splitter.split_documents(pages)
full_texts = [i.page_content for i in texts]
分割文本數據非常重要,因為它有助于處理模型的文本大小限制,并確保每個文本段都是有意義且上下文完整的。如果覺得結果不好,可以嘗試調整 chunk_size 和 chunk_overlap 參數。
最后,我們將嵌入的文本數據存儲在 Weaviate 向量數據庫中,使用以下代碼:
vector_db = Weaviate.from_texts(full_texts, hf, client=client, by_text=False, index_name='BookOfInsurance', text_key='intro'
)
這樣,我們已經構建好了知識庫。如果你想測試數據庫,可以使用以下代碼進行相似性搜索:
print(vector_db.similarity_search("What is expense ratio?", k=3))
最后,記得關閉 Weaviate 客戶端:
client.close()
開發基于 RAG 和文本轉語音 (TTS) 的 QA-LLM 工具
在創建工具之前,我們需要設置一些實用文件。
實用文件設置
首先,我們將設置 LLM 生成模型與 LangChain 和 HuggingFace 的連接。寫這篇文章時,連接過程中存在一個 bug,因此我們需要開發一個惰性連接以避免使用 HuggingFace 令牌登錄。
我們會將以下代碼保存到 utils 文件夾中的 hf_lazyclass.py 文件中:
from langchain_community.llms.huggingface_endpoint import HuggingFaceEndpoint
from langchain_core.pydantic_v1 import root_validator
from langchain_core.utils import get_from_dict_or_envclass LazyHuggingFaceEndpoint(HuggingFaceEndpoint):"""LazyHuggingFaceEndpoint"""@root_validator()def validate_environment(cls, values):"""Validate that package is installed; SKIP API token validation."""try:from huggingface_hub import AsyncInferenceClient, InferenceClientexcept ImportError:msg = ("Could not import huggingface_hub python package. ""Please install it with `pip install huggingface_hub`.")raise ImportError(msg) # noqa: B904huggingfacehub_api_token = get_from_dict_or_env(values, "huggingfacehub_api_token", "HUGGINGFACEHUB_API_TOKEN")values["client"] = InferenceClient(model=values["model"],timeout=values["timeout"],token=huggingfacehub_api_token,**values["server_kwargs"],)values["async_client"] = AsyncInferenceClient(model=values["model"],timeout=values["timeout"],token=huggingfacehub_api_token,**values["server_kwargs"],)return values
接下來,我們將創建文本轉語音類文件,命名為 tts_speech.py,內容如下:
import os
import uuid
from elevenlabs import VoiceSettings
from elevenlabs.client import ElevenLabsELEVENLABS_API_KEY = os.getenv("ELEVENLABS_API_KEY")
client = ElevenLabs(api_key=ELEVENLABS_API_KEY,
)def text_to_speech_file(text: str) -> str:# Calling the text_to_speech conversion API with detailed parametersresponse = client.text_to_speech.convert(voice_id="pNInz6obpgDQGcFmaJgB", # Adam pre-made voiceoptimize_streaming_latency="0",output_format="mp3_22050_32",text=text,model_id="eleven_turbo_v2", # use the turbo model for low latency, for other languages use the `eleven_multilingual_v2`voice_settings=VoiceSettings(stability=0.0,similarity_boost=1.0,style=0.0,use_speaker_boost=True,),)save_file_path = f"{uuid.uuid4()}.mp3"# Writing the audio to a filewith open(save_file_path, "wb") as f:for chunk in response:if chunk:f.write(chunk)print(f"{save_file_path}: A new audio file was saved successfully!")return save_file_path
以上代碼中,我們使用了預設的聲音,你可以在 ElevenLabs 的 Voice Lab 中找到適合工具的聲音。
開發工具
這一部分將結合所有內容,通過 Streamlit 前端展示 RAG 和 TTS 模型。
首先,設置生成模型和 Weaviate 向量數據庫連接:
import streamlit as st
import weaviate
from langchain_community.vectorstores import Weaviate
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
from dotenv import load_dotenv
import os
from utils.hf_lazyclass import LazyHuggingFaceEndpoint
from utils.tts_speech import text_to_speech_fileload_dotenv()
hf_token = os.getenv("HUGGINGFACEHUB_API_TOKEN")client = weaviate.Client(url="http://localhost:8081",
)
repo_id = "mistralai/Mistral-7B-Instruct-v0.2"llm = LazyHuggingFaceEndpoint(repo_id=repo_id, max_new_tokens=128, temperature=0.5, huggingfacehub_api_token=hf_token
)model_name = "sentence-transformers/all-mpnet-base-v2"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}hf = HuggingFaceEmbeddings(model_name=model_name,model_kwargs=model_kwargs,encode_kwargs=encode_kwargs
)
以上代碼中,我們初始化了 Weaviate 客戶端、生成 LLM 模型和 HuggingFace 嵌入模型。在這個例子中,我使用 Mistral Instruct LLM 模型作為生成 LLM 模型。
接下來,使用以下代碼設置 RAG 系統:
response = client.schema.get()weaviate_vectorstore = Weaviate(client=client, index_name=response['classes'][0]['class'], text_key="intro", by_text=False, embedding=hf)
retriever = weaviate_vectorstore.as_retriever()qa_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever
)
最后,我們使用以下代碼設置了 Streamlit 文件,使其能夠接受文本輸入并提供音頻輸出。
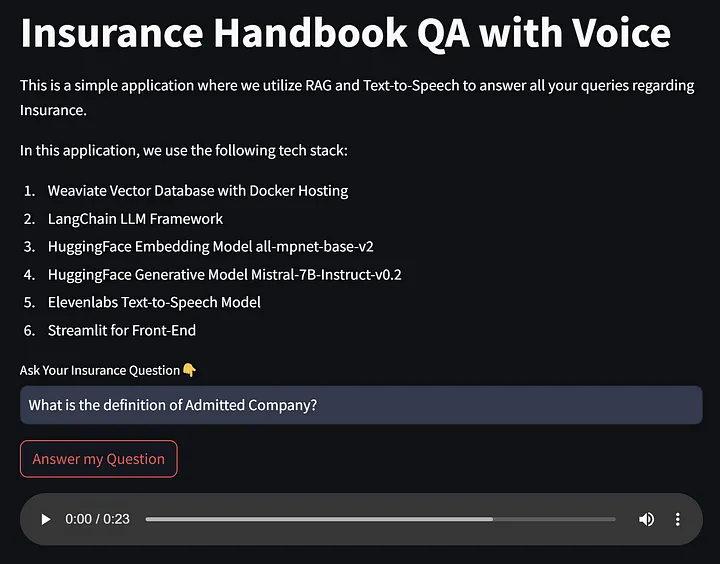
st.title('Insurance Handbook QA with Voice')st.write("""
這是一個簡單的應用程序,我們利用 RAG 和文本轉語音來回答您關于保險的所有問題。在這個應用程序中,我們使用以下技術棧:1. Weaviate 向量數據庫與 Docker 主機
2. LangChain LLM 框架
3. HuggingFace 嵌入模型 all-mpnet-base-v2
4. HuggingFace 生成模型 Mistral-7B-Instruct-v0.2
5. Elevenlabs 文本轉語音模型
6. Streamlit 用于前端
""")if 'prompt' not in st.session_state:st.session_state.prompt = ''if 'audiofile' not in st.session_state:st.session_state.audiofile = '' query = st.text_input("請輸入您的保險問題👇", "")
if st.button("回答我的問題"):st.session_state.prompt = queryresponse = qa_chain.invoke(query)st.session_state.audiofile = text_to_speech_file(response['result'])st.audio(st.session_state.audiofile, format="audio/mpeg", loop = False)
如果一切順利,讓我們運行這個 Streamlit 文件。您應該會看到頁面和下面的圖像類似。

好的,請把音頻文件上傳,我會幫你處理翻譯。如果需要,我也可以提供文字翻譯。請告訴我你的具體需求。
這就是全部。你可以調整模型、語音和前端頁面,使其更加有趣。你還可以為你所需的領域構建自己的知識庫。
結論
我們已經探索了如何使用RAG(檢索增強生成)和文本轉語音技術來構建我們的問答工具。通過結合開源工具和模型,我們可以構建一個企業所需要的高級工具。
技術交流群
前沿技術資訊、算法交流、求職內推、算法競賽、面試交流(校招、社招、實習)等、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企開發者互動交流~
我們建了算法崗技術與面試交流群, 想要獲取最新面試題、了解最新面試動態的、需要源碼&資料、提升技術的同學,可以直接加微信號:mlc2040。加的時候備注一下:研究方向 +學校/公司+CSDN,即可。然后就可以拉你進群了。
方式①、微信搜索公眾號:機器學習社區,后臺回復:加群
方式②、添加微信號:mlc2040,備注:技術交流
用通俗易懂方式講解系列
-
《大模型面試寶典》(2024版) 正式發布!
-
《大模型實戰寶典》(2024版)正式發布!
-
用通俗易懂的方式講解:自然語言處理初學者指南(附1000頁的PPT講解)
-
用通俗易懂的方式講解:1.6萬字全面掌握 BERT
-
用通俗易懂的方式講解:NLP 這樣學習才是正確路線
-
用通俗易懂的方式講解:28張圖全解深度學習知識!
-
用通俗易懂的方式講解:不用再找了,這就是 NLP 方向最全面試題庫
-
用通俗易懂的方式講解:實體關系抽取入門教程
-
用通俗易懂的方式講解:靈魂 20 問幫你徹底搞定Transformer
-
用通俗易懂的方式講解:圖解 Transformer 架構
-
用通俗易懂的方式講解:大模型算法面經指南(附答案)
-
用通俗易懂的方式講解:十分鐘部署清華 ChatGLM-6B,實測效果超預期
-
用通俗易懂的方式講解:內容講解+代碼案例,輕松掌握大模型應用框架 LangChain
-
用通俗易懂的方式講解:如何用大語言模型構建一個知識問答系統
-
用通俗易懂的方式講解:最全的大模型 RAG 技術概覽
-
用通俗易懂的方式講解:利用 LangChain 和 Neo4j 向量索引,構建一個RAG應用程序
-
用通俗易懂的方式講解:使用 Neo4j 和 LangChain 集成非結構化知識圖增強 QA
-
用通俗易懂的方式講解:面了 5 家知名企業的NLP算法崗(大模型方向),被考倒了。。。。。
-
用通俗易懂的方式講解:NLP 算法實習崗,對我后續找工作太重要了!。
-
用通俗易懂的方式講解:理想汽車大模型算法工程師面試,被問的瑟瑟發抖。。。。
-
用通俗易懂的方式講解:基于 Langchain-Chatchat,我搭建了一個本地知識庫問答系統
-
用通俗易懂的方式講解:面試字節大模型算法崗(實習)
-
用通俗易懂的方式講解:大模型算法崗(含實習)最走心的總結
-
用通俗易懂的方式講解:大模型微調方法匯總
參考鏈接:https://pub.towardsai.net/crafting-qa-tool-with-reading-abilities-using-rag-and-text-to-speech-d4208330a1e4




)



SQL優化基礎(三):看懂執行計劃順序)









)
