LLMPerf-為LLM推理提供可復現的性能指標
翻譯自文章:Reproducible Performance Metrics for LLM inference
結合之前的LLMPerf測試大模型API性能的文章進行查看,效果更佳。
1. 摘要
-
我們見過許多關于LLM性能的聲明;然而,這些聲明往往無法復現。
-
今天,我們發布了LLMPerf(https://github.com/ray-project/llmperf),這是一個開源項目,用于基準測試LLM,以使這些聲明可復現。我們討論了選擇的指標以及如何測量它們。
-
有趣的見解:100個輸入token對延遲的影響與一個輸出token大致相同。如果你想加快速度,減少輸出比減少輸入更有效。
-
我們還展示了這些基準測試在一些當前LLM產品上的結果,并確定了哪些LLM目前最適合什么用途。我們重點關注了Llama 2 70b。
-
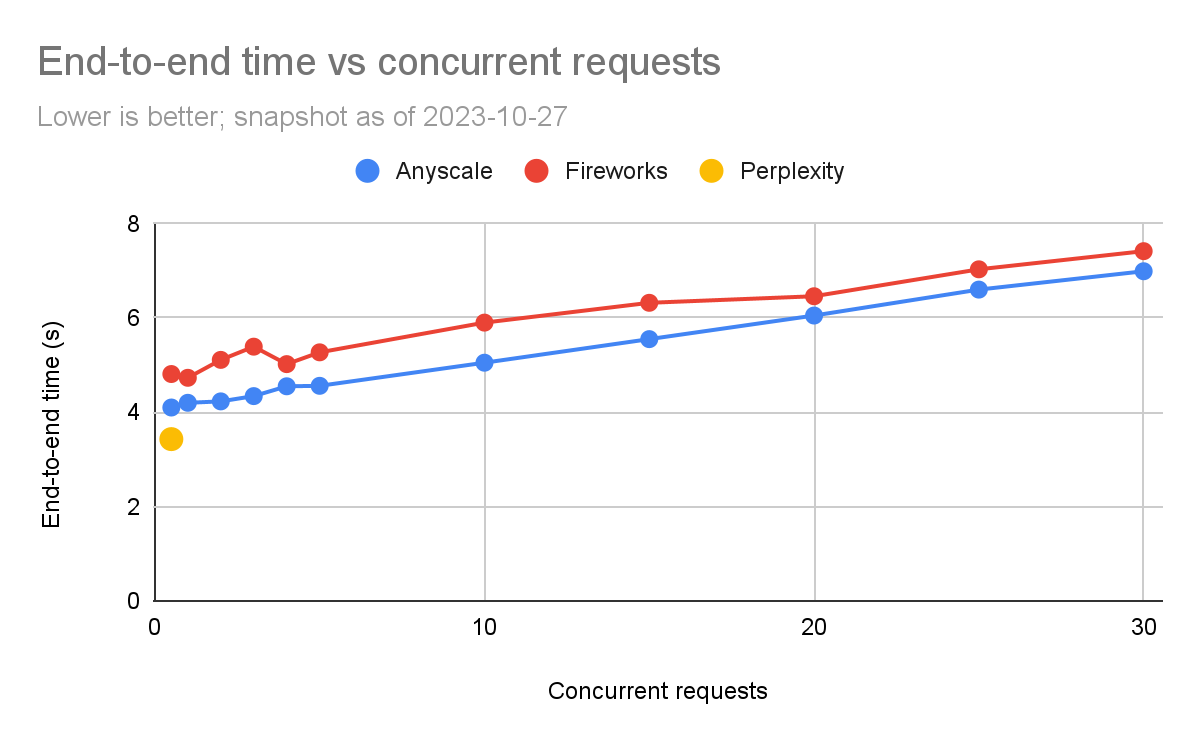
總結我們在每個token價格上的結果:Perplexity beta由于低速率限制,目前尚不適用于生產;Fireworks.ai和Anyscale Endpoints都可行,但Anyscale Endpoints在典型工作負載(550個輸入token,150個輸出token)的平均端到端延遲上便宜15%,快17%。在高負載水平下,Fireworks的首次token時間(TTFT)稍好。
-
特別是對于LLM,性能特性變化迅速,每個用例都有不同的需求,適用情況因人而異。
2. 問題
最近,許多人對其LLM推理性能做出了各種聲明。然而,這些聲明往往無法復現,并且缺乏詳細信息。例如,有一篇帖子僅僅說明了結果是針對“不同輸入大小”的,但其圖表我們根本無法理解。
我們曾考慮發布自己的基準測試結果,但意識到僅僅這樣做只會延續不可復現結果的問題。因此,除了發布結果之外,我們還將我們的內部基準測試工具開源。你可以在這里下載它。README文件中有許多示例展示了如何使用它。
在本文的其余部分,我們將討論我們測量的關鍵指標以及各個供應商在這些指標上的表現。
3. LLM的定量性能指標
LLM的關鍵指標有哪些?我們建議標準化以下指標:
通用指標
以下指標適用于共享公共端點以及專用實例。
每分鐘完成請求數
在幾乎所有情況下,您都需要向系統發出并發請求。這可能是因為您正在處理來自多個用戶的輸入,或者您有批量推理工作負載。
在許多情況下,共享公共端點提供商會在非常低的水平上限制您的請求,除非您與他們達成額外的協議。我們曾見過一些提供商將限制設置為90秒內不超過3個請求。
第一個token的響應時間(TTFT)
在流式應用中,TTFT是指LLM返回第一個token所需的時間。我們不僅關注平均TTFT,還關注其分布情況:P50、P90、P95和P99。
token間延遲(ITL)
token間延遲是指連續token之間的平均時間。我們決定在計算token間延遲時包括TTFT。我們曾見過一些系統在端到端時間內非常晚才開始流式傳輸。
端到端延遲
端到端延遲應大致等于平均輸出token長度乘以token間延遲。
每個典型請求的成本
API提供商通常可以在其他指標和成本之間進行權衡。例如,您可以通過在更多GPU上運行相同的模型或使用更高端的GPU來減少延遲。
4. 專用實例的附加指標
如果您使用專用計算資源運行LLM,例如使用Anyscale Private Endpoints,則有一些額外的標準需要考慮。請注意,將共享LLM實例與專用LLM實例的性能進行比較非常困難:它們的約束條件不同,并且利用率成為一個更加顯著的實際問題。
配置
同樣重要的是要注意,同一個模型可以有不同的配置,從而在延遲、成本和吞吐量之間做出不同的權衡。例如,一個在p4de實例上運行的CodeLlama 34B模型可以配置為8個每個使用1個GPU的副本,4個每個使用2個GPU的副本,2個每個使用4個GPU的副本,或者1個使用所有8個GPU的副本。你還可以配置多GPU用于流水線并行或張量并行。每一種配置都有不同的特性:8個每個使用1個GPU的副本可能具有最低的TTFT(因為有8個“隊列”在等待輸入),而1個使用8個GPU的副本可能具有最高的吞吐量(因為有更多的內存用于批處理并且實際上有8倍的內存帶寬)。
每種配置都會導致不同的基準測試結果。
輸出令牌吞吐量
還有一個重要的標準:總生成令牌吞吐量。這使你能夠進行成本比較。
滿負荷利用時每百萬令牌的成本
為了比較不同配置的成本(例如,你可以在1個A10G GPU、2個A10G GPU或1個A100-40GB GPU上部署一個Llama 2 7B模型等),重要的是考慮給定輸出的總部署成本。在這些比較中,我們將使用AWS一年的預留實例定價。
5. 我們考慮但未包含的指標
當然,還有其他指標可以添加到這個列表中。
預填充時間
由于預填充時間只能通過對第一個令牌生成時間相對于輸入大小的回歸來間接測量,我們選擇在這一輪基準測試中不包括它。我們計劃在未來版本的基準測試中添加預填充時間。
根據我們對當前大多數技術的經驗,預填充時間(獲取輸入令牌、將其加載到GPU并計算注意力值)對延遲的影響不如輸出令牌顯著。
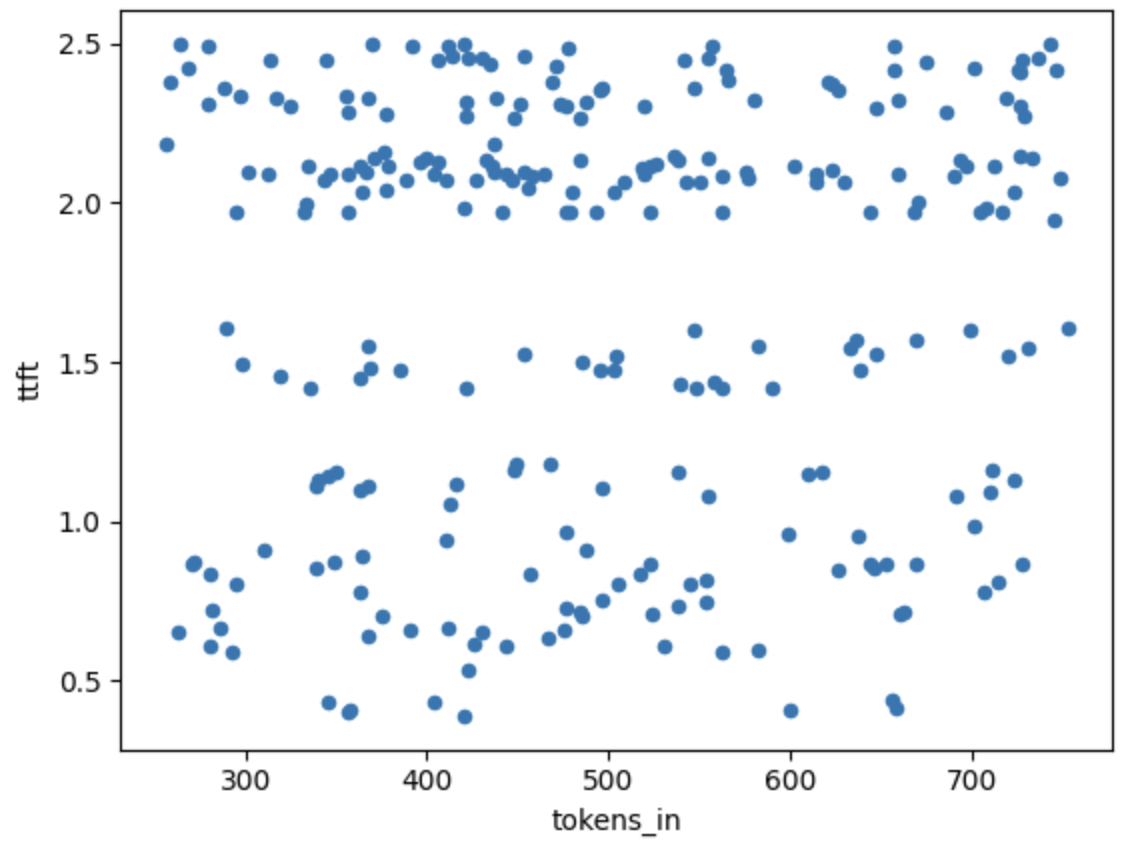
上圖展示了首個令牌生成時間(TTFT)與輸入大小的變化情況。所有樣本均來自單次運行(5個并發請求)。所有這些數據點會被平均,以在下列圖表中給出一個單一的樣本點。
可以看到,在250個令牌輸入到800個令牌輸入之間,輸入令牌數量與TTFT之間似乎沒有明顯關系,并且由于其他原因,TTFT中的隨機噪聲“掩蓋”了這種關系。實際上,我們確實嘗試通過比較550個輸入令牌和3500個輸入令牌的輸出并估計梯度來用回歸法估算這個關系,發現每增加一個輸入令牌會增加0.3-0.7毫秒的端到端時間,而每增加一個輸出令牌會增加30-60毫秒的端到端時間(針對在Anyscale Endpoints上運行的Llama 2 70b)。因此,輸入令牌對端到端延遲的影響約為輸出令牌的1%。我們將在未來回到這一測量。
總吞吐量(包括輸入和生成的令牌)
鑒于預填充時間不可測量,并且所花費的時間更多地取決于生成令牌而不是輸入大小,我們認為關注輸出是正確的選擇。
輸入選擇
在運行此測試時,我們需要選擇用于測試的輸入以及速率。
我們看到有人使用隨機令牌生成固定大小的輸入,然后使用最大令牌硬停來控制輸出大小。我們認為這種方法次優,原因有二:
-
隨機令牌不代表真實數據。因此,某些依賴于數據實際分布的性能優化算法(例如推測解碼)在隨機數據上的表現可能比在真實數據上的表現更差。
-
固定大小不代表真實數據。這意味著某些算法(例如分頁注意力和連續批處理)的優勢不會被體現出來:它們的很多創新在于處理輸入和輸出大小的變化。
因此,我們希望使用“真實”數據。顯然,這因應用而異,但我們至少需要一個平均值作為起點。
輸入大小
為了確定“典型”的輸入和輸出大小,我們查看了來自Anyscale Endpoints用戶的數據。基于這些數據,我們選擇了:
-
平均輸入長度:550個令牌(標準差150個令牌)
-
平均輸出長度:150個令牌(標準差20個令牌)
為了簡化,我們假設輸入和輸出服從正態分布。在未來的工作中,我們將考慮更具代表性的分布,如泊松分布(其在建模令牌分布方面具有更好的屬性,例如,泊松分布在負值時為0)。在計算令牌時,我們始終使用Llama 2快速分詞器來估計系統獨立的令牌數量——例如,我們在以往的研究中注意到,ChatGPT分詞器比Llama分詞器更“高效”(Llama 2為每個詞1.5個令牌,而ChatGPT為每個詞1.33個令牌)。ChatGPT不應該因此受到懲罰。
輸入內容
為了使基準測試具有代表性,我們決定給LLM安排兩個任務。
第一個任務是將數字的文字表示轉換為數字表示。這實際上是一個“校驗和”任務,以確保LLM功能正常:我們應該期望返回值與我們發送的值一致(根據我們的經驗,在運行良好的LLM中,這種情況很少低于97%)。
第二個任務是提供更靈活的輸入和輸出。我們在輸入中包括一定數量的莎士比亞十四行詩的行數,并要求LLM在輸出中選擇一定數量的行數。這給我們提供了實際的令牌和大小分布。我們還可以用這個來對LLM進行“合理性檢查”——我們期望輸出的行看起來與我們提供的行有一定相似度。
并發請求
一個關鍵特性是并發請求的數量。顯然,對于固定的資源集,更多的并發請求會減慢輸出速度。為了測試,我們已將標準化的關鍵數字定為5。
6. LLMPerf
LLMPerf實現了上述測量方法。它也是參數化的(例如允許你更改輸入和輸出大小以匹配你的應用程序,從而可以為你的工作運行提供商的基準測試)。
LLMPerf 可在此獲取:https://github.com/ray-project/LLMPerf
7. LLM產品的基準測試結果
如我們上面提到的,比較按令牌計費的LLM產品(通常是共享的)和按時間單位計費的產品(按時間單位付費)是困難的。對于這些實驗,我們關注我們知道的按令牌計費的產品。因此,我們選擇了在Anyscale、Fireworks和Perplexity上的llama-2-70b-chat產品。
對于Fireworks,我們使用了Developer PRO賬戶(將請求速率限制增加到每分鐘100次)。
每分鐘完成的請求
我們使用這個來測量通過改變并發請求的數量每分鐘可以進行多少請求,并觀察整體時間的變化。然后,我們將完成的請求數量除以完成所有請求所需的時間(以分鐘為單位)。
請注意,這可能略微保守,因為我們將并發請求分批次完成,而不是連續查詢。例如,如果我們正在進行5個并發請求,其中4個在5秒內完成,而另一個在6秒內完成,那么就有1秒時間內并沒有完全達到5個并發請求。
下面的圖表顯示了結果。
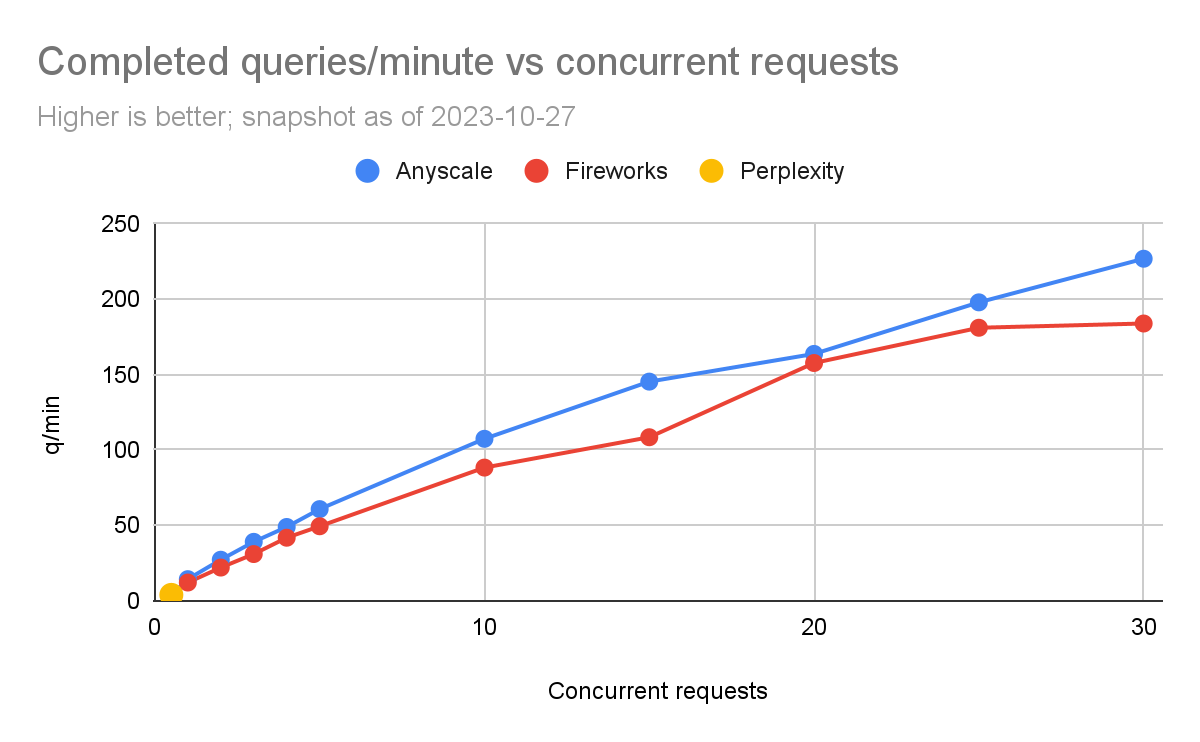
我們不得不處理的一個問題是,Perplexity的速率限制非常低。因此,我們只能在每輪之間加入15秒的暫停,才能完成一個“蘋果對蘋果”的比較。如果少于這個時間,我們會開始從Perplexity獲得異常。我們將這個標記為每秒0.5個并發請求。我們運行實驗直到開始收到異常。
我們可以看到,Fireworks和Anyscale可以擴展到每分鐘完成數百個查詢。Anyscale的擴展性略高一些(每分鐘最多達到227個查詢,而Fireworks為184個查詢)。
第一個token的響應時間(TTFT)
我們比較了每個產品的TTFT。對于流式應用程序,如聊天機器人,TTFT尤為重要。
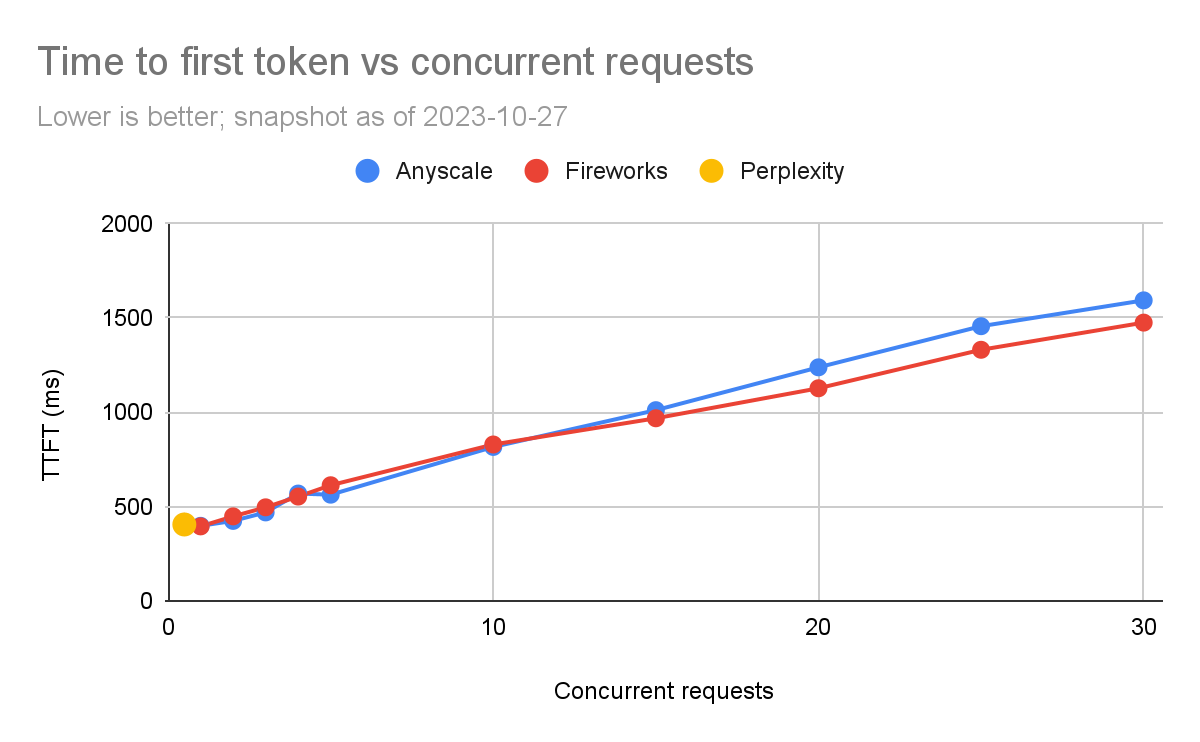
再次地,我們在測試Perplexity時有限制。在低負載水平下,Anyscale的速度較快,但隨著并發請求的增加,Fireworks似乎稍微更好。在5個并發查詢(我們通常關注的數量)時,延遲通常在100毫秒內(563毫秒對比630毫秒)。還必須注意,TTFT在網絡情況下有很高的方差(例如,如果服務部署在附近或遠處的區域)。
token間延遲(ITL)
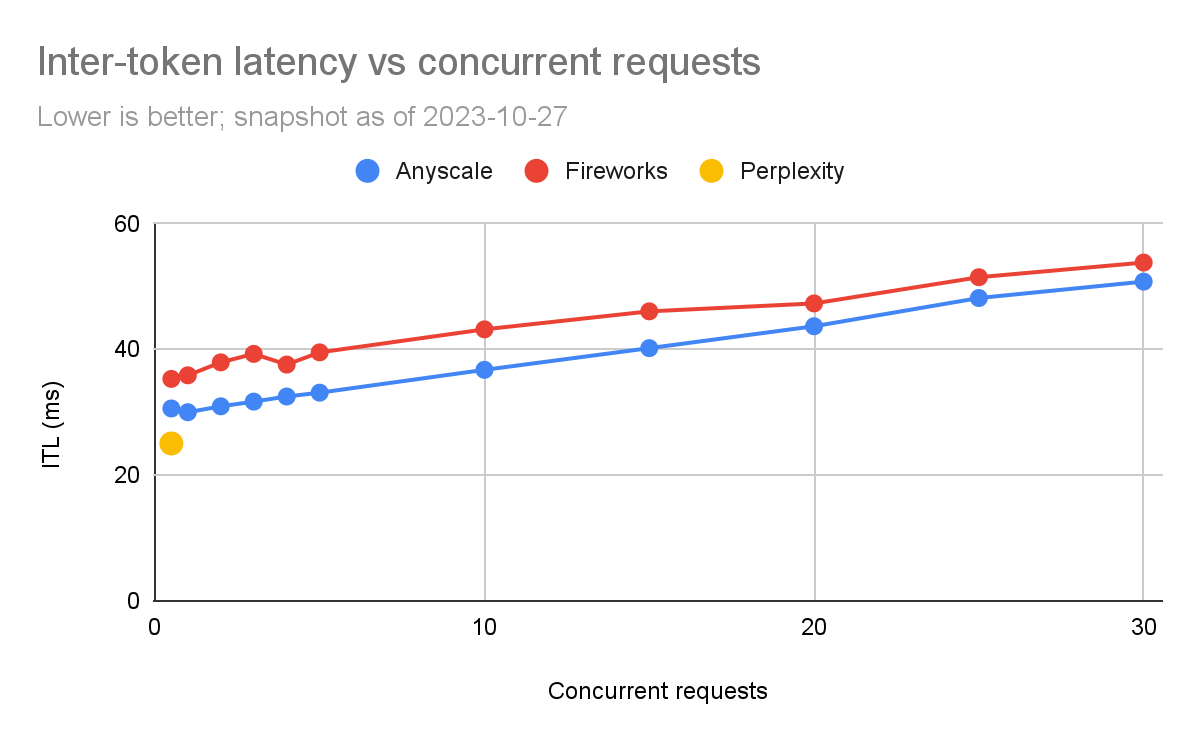
根據上面的內容,我們可以看到Anyscale的令牌間延遲一直比Fireworks好,盡管差異相對較小(約為5%到20%)。
端到端延遲
下面的圖表顯示完成查詢所需的端到端時間。我們可以看到,端到端請求時間在噪聲方面是比較敏感的一個指標。
我們可以看到,在這里,Anyscale的端到端時間一直比Fireworks的好,但隨著負載水平的增加,差距在高負載下會縮小(特別是比例上)。在5個并發查詢時,Anyscale為4.6秒,而Fireworks為5.3秒(快15%)。但是在30個并發查詢時,差異較小(Anyscale快5%)。
每1000個請求的成本
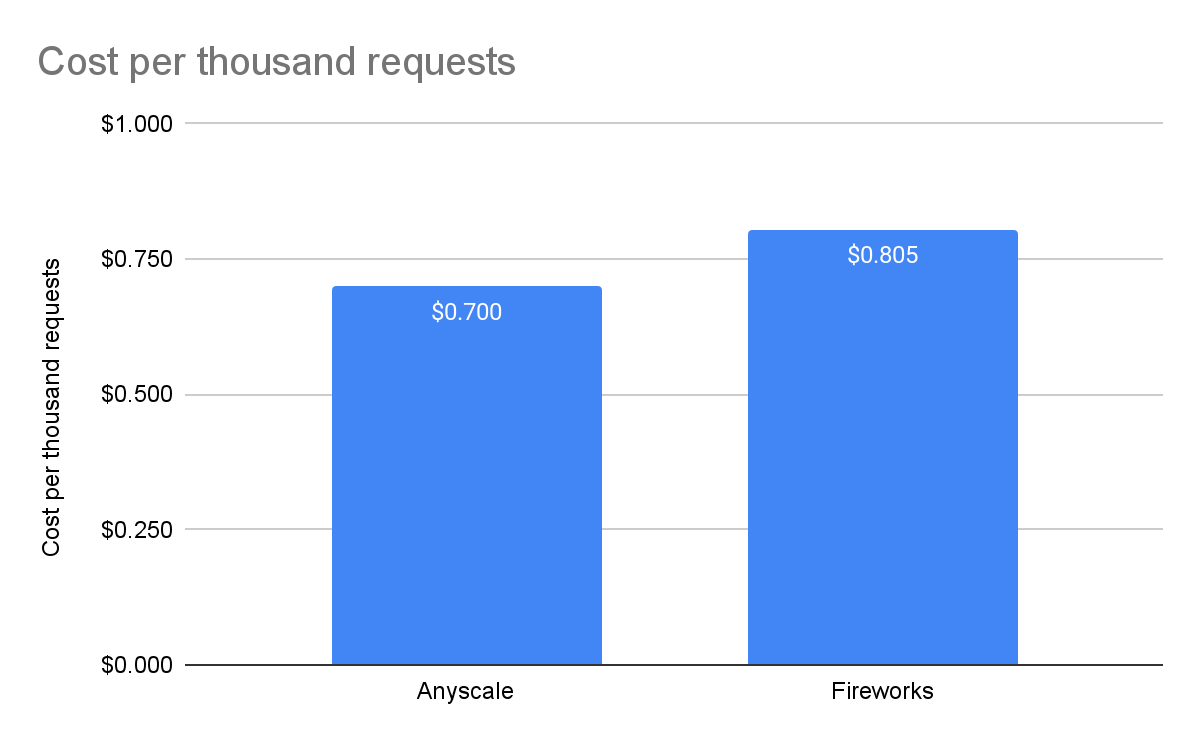
Perplexity處于公開測試階段,因此沒有價格 - 我們無法將其包括在比較中。對于Fireworks,我們使用了他們網站上列出的價格,即每百萬輸入令牌0.7美元,每百萬輸出令牌2.80美元。對于Anyscale Endpoints,我們使用了他們定價頁面上列出的價格,即每百萬令牌1美元,不論輸入還是輸出。
8. 解讀這些結果
現在我們有了這些數據,我們可以確定何時使用每個LLM產品:
-
對于低流量的交互式應用程序(比如聊天機器人),這三個產品都可以勝任。ITL和TTFT足夠小,不會成為主要問題,而且它們之間的差異不大,因為人類閱讀大約每秒5個令牌,即使最慢的產品也是這個速度的6倍。然而,在這種工作負載下,Anyscale是這三個產品中最便宜的,便宜約15%。
-
如果你正在尋找端到端的超低延遲應用程序,并且工作量不是很大,Perplexity在公開測試結束后可能值得考慮。在Perplexity發布價格之前,很難知道這種低延遲的“代價”。
-
如果你有大量的工作負載,Anyscale和Fireworks值得考慮。然而,在這個特定的工作負載下,Anyscale便宜約15%。如果你的輸入到輸出比例很高,例如10個輸入令牌對1個輸出令牌,那么Fireworks會更便宜(Fireworks為每美元89美分,而Anyscale為每美元1美元)。極端摘要可能就是一個這樣的例子。
這些考慮將幫助你根據具體的需求和預算選擇合適的LLM產品。
9. 結論
LLM性能正在以令人難以置信的速度發展。我們希望社區能夠發現LLMPerf基準測試工具在比較輸出方面的有用性。我們將繼續努力改進LLMPerf,特別是使其更容易控制輸入和輸出的分布,希望這將提高透明度和可重現性。我們也希望您能夠使用它來模擬您特定工作負載的成本和性能。
從這個研究中我們看到,并非所有基準測試都適合所有情況,特別是在LLM的情況下,它確實取決于您的具體應用。
本文由 mdnice 多平臺發布


)
—卷積神經網絡(2)》)

)









)



