文章目錄
- 📕索引底層數據結構與算法
- 📙索引數據結構
- 📘二叉樹
- 📘紅黑樹
- 📘Hash
- 📘B-Tree
- 📘B+Tree
- 📙表在不同存儲引擎的存儲結構
- 📘MyISAM存儲引擎索引實現
- 📚文件結構
- 📚非聚集索引
- 📘InnoDB存儲引擎索引實現
- 📚文件結構
- 📚聚集索引
- 📙為什么DBA總推薦使用整型自增主鍵做索引
- 📙為什么非主鍵索引結構葉子節點存儲的是主鍵值?
- 📙MySQL最左前綴優化原則是怎么回事
📕索引底層數據結構與算法
📙索引數據結構
📘二叉樹
二叉樹數據結構
📘紅黑樹
紅黑樹的數據結構
📘Hash
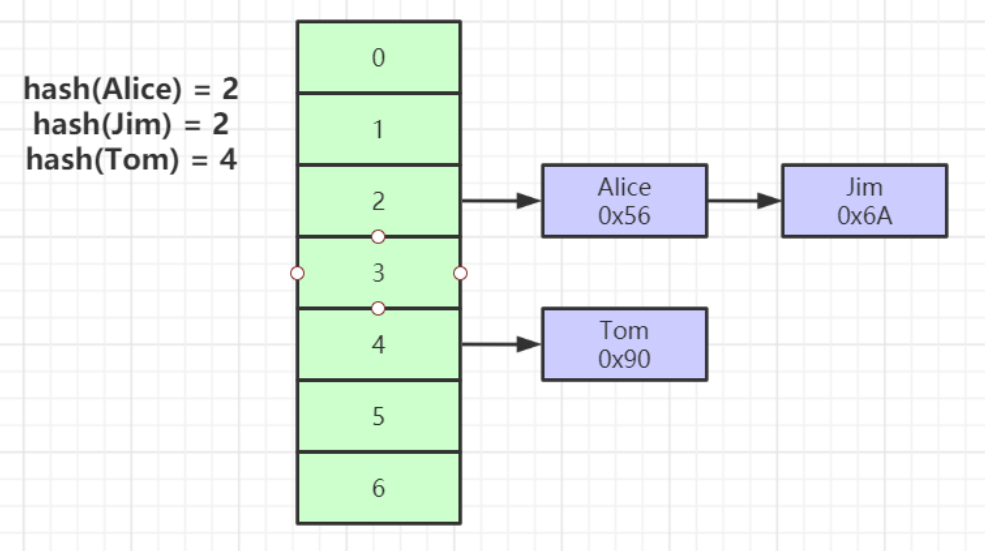
- 對索引的key進行一次hash計算就可以定位出數據存儲的位置,很多時候Hash索引要比B+Tree索引更高效
- 僅能滿足 “=”,“IN”,不支持范圍查詢,hash沖突問題。
📘B-Tree
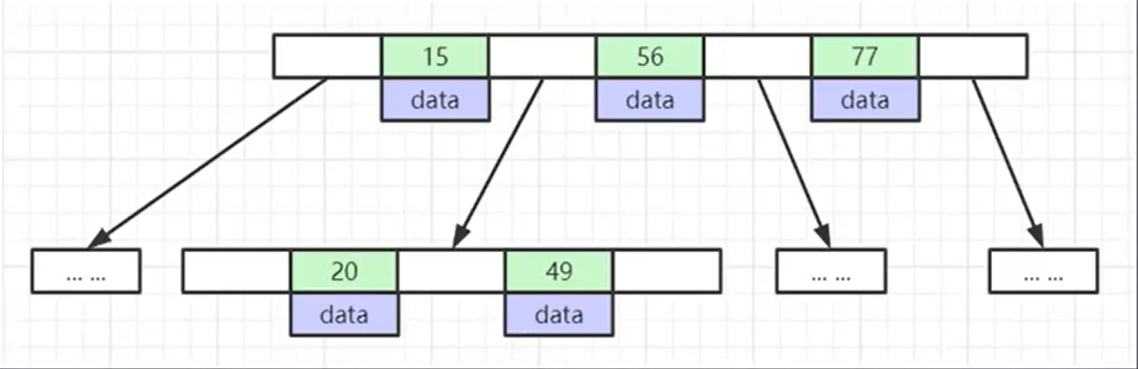
- 索引元素不重復
- 從左到右遞增排列。
📘B+Tree
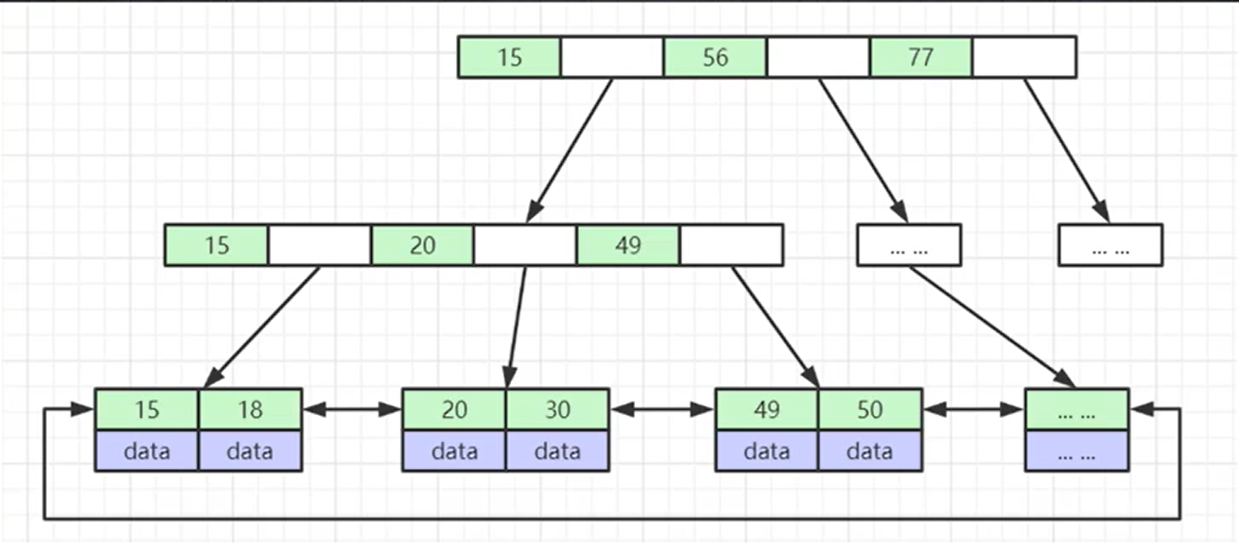
- 非葉子節點不存儲data,只存儲索引(冗余),可以放更多的索引
- 葉子節點包含所有索引字段
- 葉子節點用指針連接,提高區間訪問的性能
- 可以支持范圍查詢,有雙向指針,假如查詢Col1>30通過雙向指針直接可以查詢出來大于30的數據,而不是像B-Tree一樣需要重新從根節點查詢。
📙表在不同存儲引擎的存儲結構
📘MyISAM存儲引擎索引實現
📚文件結構
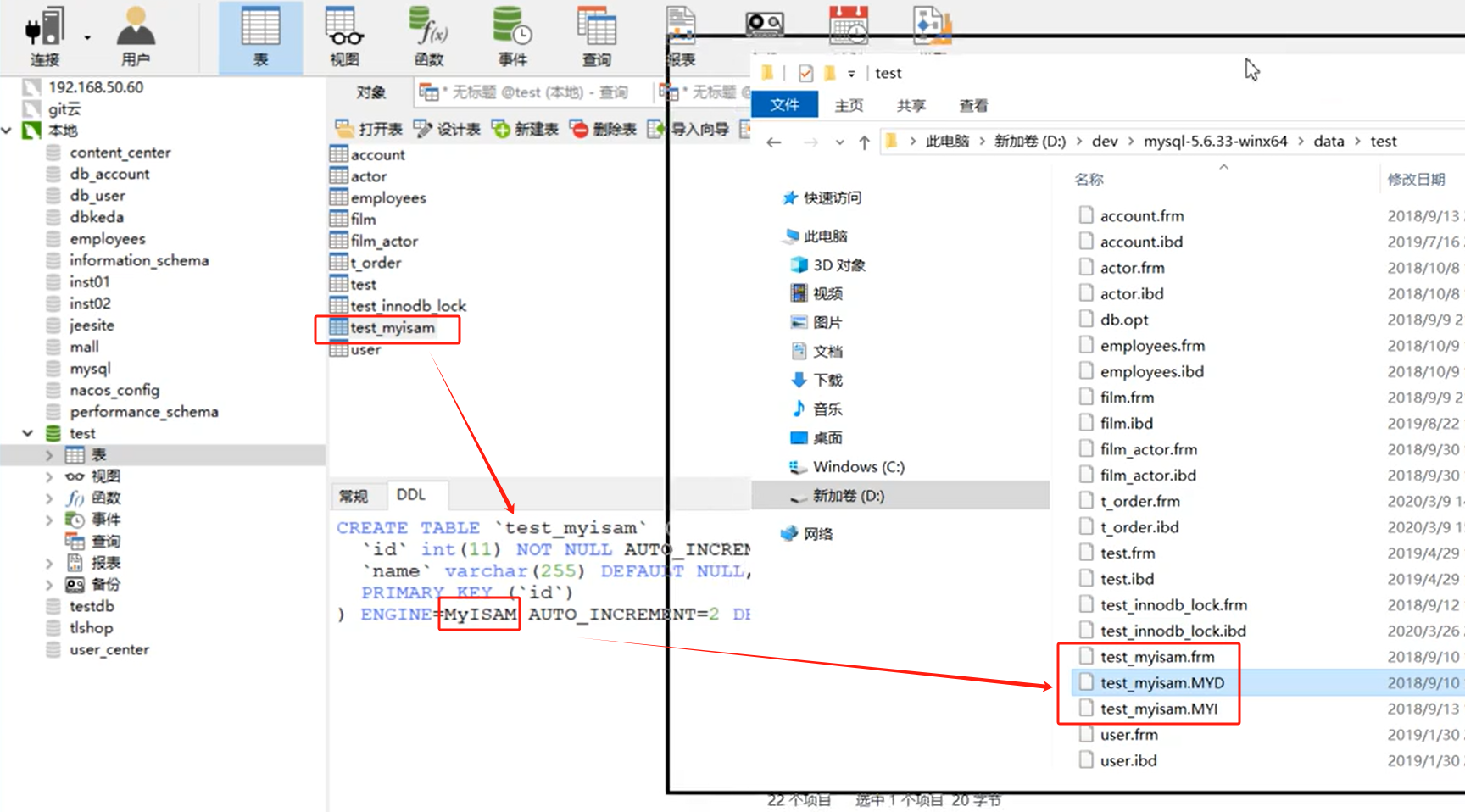
- .frm結尾的文件:表結構文件
- .MYD結尾的文件:數據文件
- .MYI結尾的文件:索引文件
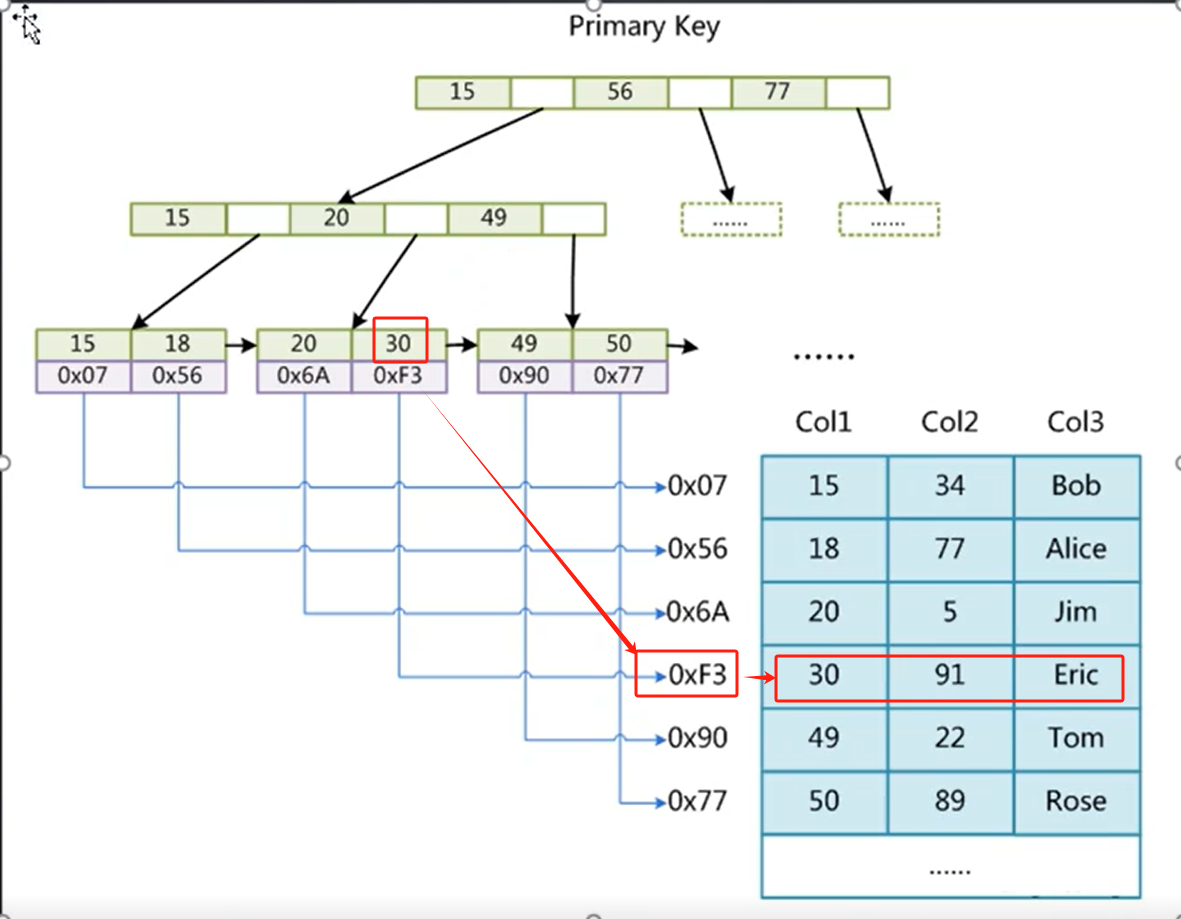
📚非聚集索引
假設查詢Col1=30,這個時候會先去.MYI結尾的索引文件找到磁盤地址0XF3,然后再去.MYD結尾的數據文件獲取這一行數據。索引和數據分開存儲就叫做非聚集索引。
📘InnoDB存儲引擎索引實現
📚文件結構
- .frm結尾的文件:表結構文件
- .ibd結尾的文件:數據和索引文件,按照B+Tree組織的一個索引結構文件
📚聚集索引
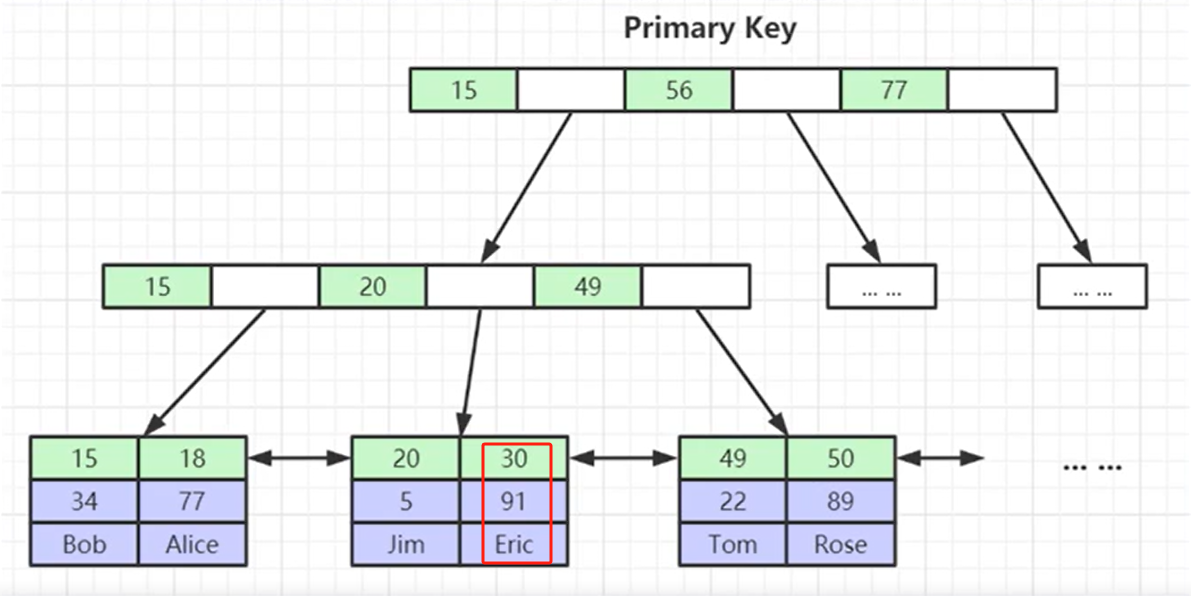
葉節點包含整行記錄,例如Col1=30會把其他行(Col2、Col3)的數據放到一起,這就是聚集索引。從結構上來說,聚集索引直接就獲取到了整行數據性能比非聚集索引效率更高。
📙為什么DBA總推薦使用整型自增主鍵做索引
前面提到 InnoDB存儲引擎中.ibd文件必須要用B+Tree來組織索引結構。
- 如果表里面有主鍵,那么就可以直接使用主鍵作為B+Tree來組織索引結構。
- 如果表里面沒有創建主鍵,它會從表中選擇一列所以數據不重復的列作為主鍵。
- 如果沒有選到不重復的列,這個時候MySQL才會自增隱藏列作為主鍵。
- 通常情況都會自己選擇一列作為主鍵,而不是交由MySQL自增隱藏列,減少MySQL的工作。
選擇整型效率更快。
- 如果以字符串作為主鍵,那么要逐個字符對比ASCII碼,這種工作模式在對比過程中,如果二個對比結果前面相同,就最后一個字符不相同,浪費的性能還是很高的。
- 整型存儲的空間更小,會節約硬件資源。
假設我先插入8后插入7,即非自增插入數據,這個B+Tree結果是如何變化的呢?
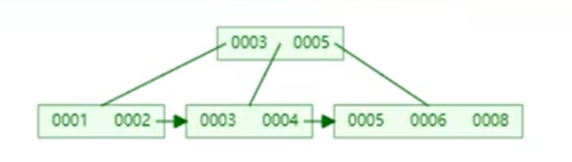 5/6/8這個大節點放滿了,插入7
5/6/8這個大節點放滿了,插入7
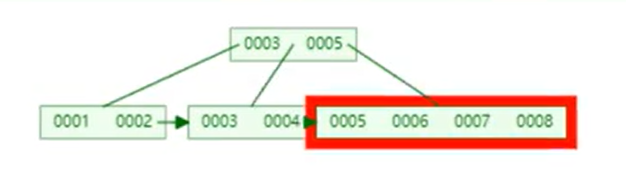 放不下了,進行拆分平衡
放不下了,進行拆分平衡
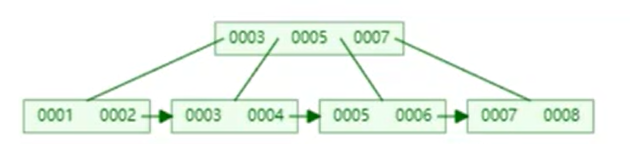 假設后面插入9/10這種自增的數據,B+Tree會直接往后面開一個節點,性能比對來說,肯定是自增的會高一些。
假設后面插入9/10這種自增的數據,B+Tree會直接往后面開一個節點,性能比對來說,肯定是自增的會高一些。
📙為什么非主鍵索引結構葉子節點存儲的是主鍵值?
非主鍵索引結構葉子節點存儲主鍵值的原因主要有兩個:
- 保持一致性:當數據庫表進行DML(數據操縱語言,如INSERT、UPDATE、DELETE)操作時,同一行記錄的頁地址可能會發生改變。由于非主鍵索引保存的是主鍵的值,而非實際的數據記錄,因此當數據記錄發生移動或變更時,非主鍵索引無需進行更改,只需保持與主鍵值的對應關系即可,從而保持索引的一致性。
- 節省存儲空間:在InnoDB存儲引擎中,數據本身已經按照主鍵索引的B+樹結構進行存儲。如果非主鍵索引也存儲整行數據,那么每個非主鍵索引都會存儲一份數據,這將導致大量的數據冗余和存儲空間的浪費。而只存儲主鍵值的方式可以極大地節省存儲空間,因為主鍵索引已經包含了完整的數據記錄。
非主鍵索引通過存儲主鍵值,可以在查詢時通過主鍵值快速定位到數據記錄所在的位置,從而提高查詢效率。
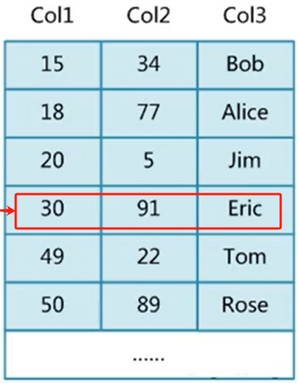
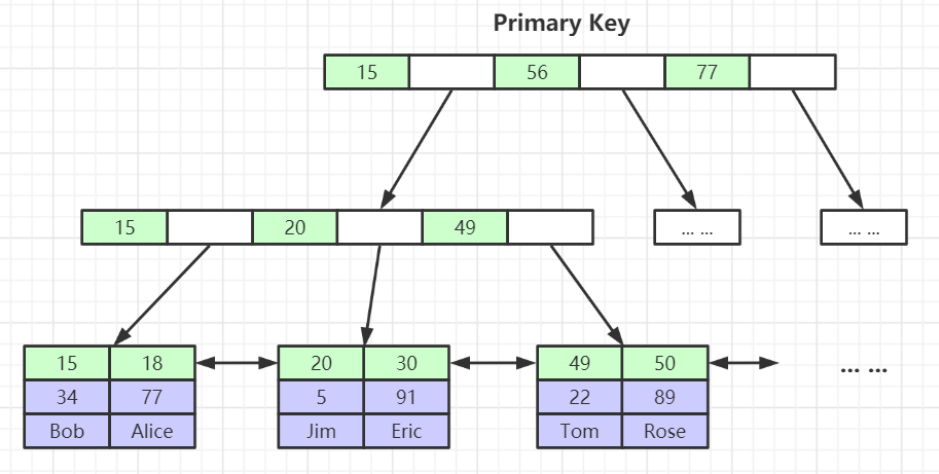
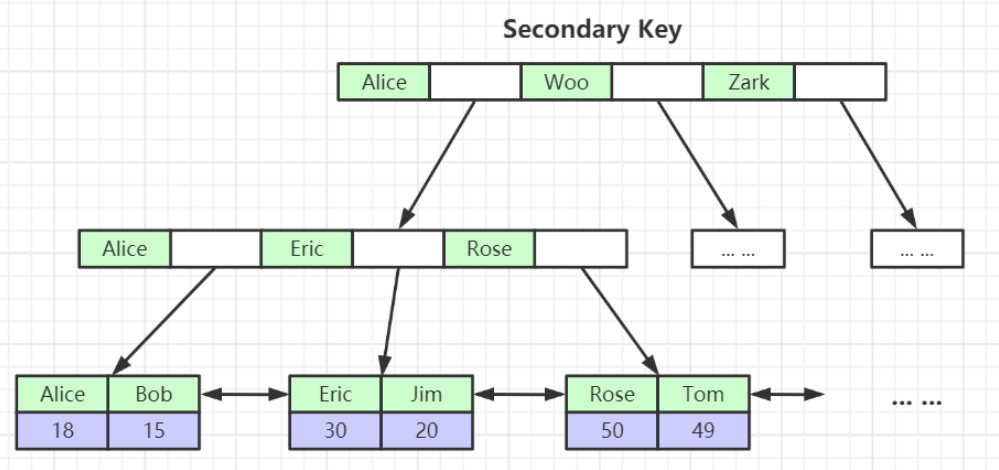 先用二級索引找到主鍵索引,然后使用主鍵索引回表去查詢對應的數據。
先用二級索引找到主鍵索引,然后使用主鍵索引回表去查詢對應的數據。
📙MySQL最左前綴優化原則是怎么回事
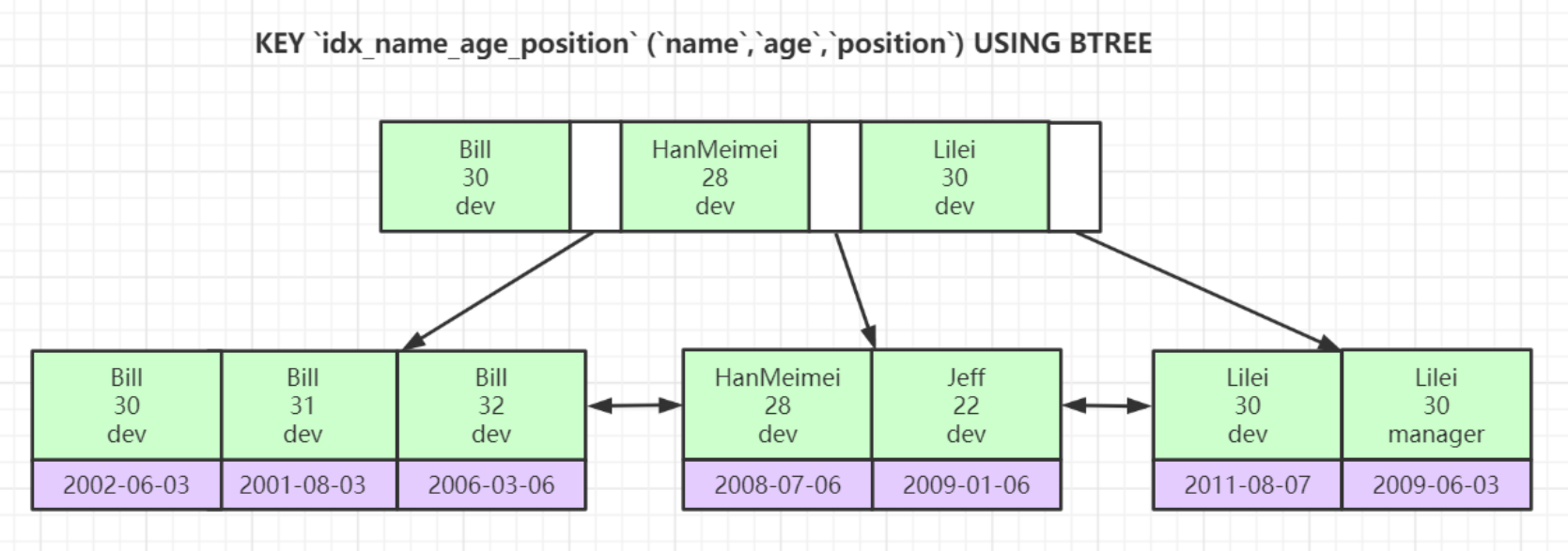
- 先對比name大小,比較字符大小,HanMeimei<Jeff
- 然后對比age大小,比較年齡大小,30<31<32
- 最后對比position大小,dev<manager
EXPLAIN SELECT * FROM employees WHERE name = 'Bill' and age = 31;
EXPLAIN SELECT * FROM employees WHERE age = 30 AND position = 'dev';
EXPLAIN SELECT * FROM employees WHERE position = 'manager';|
根據上述的聯合索引,分析上述SQL,只有第一條SQL會走索引。
- 聯合索引遵循最左前綴原則,先使用name進行查找,這是name已經排好序了,直接可以查詢。
- 然后使用age去查找,發現30,31,32,28,22,30,30,這個是沒有排序的,就走全表掃描了。
- 后面就不會使用position繼續查找了。



:Python的連接與操作)

)
和LockSupport.park())






技術探討)




)
