隨著人工智能技術的不斷發展,AI作畫逐漸成為了一個熱門話題。AI作畫,即利用人工智能算法生成繪畫作品,不僅僅是技術的展示,更是藝術與科技結合的創新體現。本文將深入探討AI作畫的核心算法原理,并通過實例幫助讀者更好地理解和掌握這一技術。
文章最后,給大家推薦中文版AI繪畫軟件。
一、AI作畫的基本原理
AI作畫的核心算法主要有兩種:生成對抗網絡(GANs)和變分自編碼器(VAEs)。這兩種算法在圖像生成和處理方面各有特色和優勢。
1. 生成對抗網絡(GANs)
生成對抗網絡(Generative Adversarial Networks, GANs)是由Ian Goodfellow等人在2014年提出的一種深度學習模型。它采用了一種獨特的雙網絡結構,包含生成器(Generator)和判別器(Discriminator),兩者相互對抗,通過競爭與協作,不斷提高生成圖像的質量。GANs自提出以來,在圖像生成、視頻生成、圖像修復等領域展現出了強大的應用潛力。
1.1 GANs的基本架構
GANs的核心思想是兩個神經網絡之間的博弈,這種博弈機制可以類比為偽造者和鑒定者之間的對抗:
-
生成器(G):生成器的任務是接受一個隨機噪聲向量(通常是從標準正態分布中采樣的向量),并將其轉換為一幅圖像。生成器試圖生成的圖像能夠欺騙判別器,使其認為這些圖像是真實的。
-
判別器(D):判別器的任務是區分輸入圖像是真實的還是生成的。它接受一幅圖像作為輸入,輸出一個概率值,表示該圖像是真實圖像的概率。判別器的目標是最大化對真實圖像的識別準確度,同時最小化對生成圖像的識別準確度。
1.2 GANs的訓練過程
GANs的訓練過程是一個交替優化的過程,包括以下步驟:
-
初始化:隨機初始化生成器和判別器的權重。
-
訓練判別器:
- 從真實圖像數據集中隨機采樣一批真實圖像。
- 從生成器的輸入噪聲空間中采樣一批隨機噪聲,并通過生成器生成一批假圖像。
- 將真實圖像和生成的假圖像輸入判別器,計算判別器對真實圖像和生成圖像的判別損失。
- 優化判別器的參數,最小化判別器對真實圖像和假圖像的判別損失。
-
訓練生成器:
- 從生成器的輸入噪聲空間中采樣一批隨機噪聲,并通過生成器生成一批假圖像。
- 將生成的假圖像輸入判別器,計算判別器對這些假圖像的輸出。
- 優化生成器的參數,最大化判別器認為這些假圖像為真實圖像的概率。
-
重復上述步驟:生成器和判別器不斷交替優化,生成器逐漸生成更逼真的圖像,判別器不斷提高區分真實圖像和生成圖像的能力。
1.3 數學表達
GANs的目標是解決以下最小化最大化問題:

其中:
- 𝑥x?表示真實圖像,從真實數據分布?𝑝data(𝑥)pdata?(x)?中采樣。
- 𝑧z?表示生成器的輸入噪聲,從噪聲分布?𝑝𝑧(𝑧)pz?(z)?中采樣。
- 𝐺(𝑧)G(z)?表示生成器生成的圖像。
- 𝐷(𝑥)D(x)?表示判別器對輸入圖像?𝑥x?的判別結果。
生成器 𝐺G 試圖最小化判別器 𝐷D 的判別能力,使得 𝐷(𝐺(𝑧))D(G(z)) 接近 1,而判別器 𝐷D 則試圖最大化其區分能力,使得 𝐷(𝐺(𝑧))D(G(z)) 接近 0。
1.4 生成對抗網絡的改進與變種
自GANs提出以來,研究者們針對其訓練不穩定、易模式崩潰等問題提出了多種改進和變種,以下是幾種重要的改進:
-
DCGANs(深度卷積GANs):將卷積神經網絡(CNN)引入GANs,使得生成器和判別器能夠處理高維圖像數據。
-
WGAN(Wasserstein GAN):通過引入Wasserstein距離,解決了原始GANs訓練不穩定的問題,使得訓練過程更加平滑和穩定。
-
CycleGAN:實現了圖像到圖像的翻譯任務,如將馬的照片轉換為斑馬的照片,或將夏季的景色轉換為冬季的景色,且不需要成對的訓練數據。
-
StyleGAN:由NVIDIA提出,能夠生成高質量、高分辨率的圖像,其生成的人臉圖像在逼真度和細節處理上達到了新的高度。
1.5 示例:使用GANs生成藝術作品
以著名的DeepArt.io為例,該平臺利用GANs將用戶上傳的照片轉化為特定藝術風格的繪畫作品。用戶可以選擇不同的藝術風格,如梵高的《星空》或莫奈的《睡蓮》,系統會根據選擇的風格生成對應的藝術作品。這一過程不僅展示了GANs在圖像生成方面的強大能力,也為普通用戶提供了一個創造個性化藝術作品的機會。
總之,生成對抗網絡(GANs)作為一種創新性的深度學習模型,通過生成器和判別器之間的對抗訓練,能夠生成高質量的圖像。其在藝術創作、圖像修復、圖像生成等領域的廣泛應用,展現了人工智能在視覺生成方面的巨大潛力和發展前景。
2. 變分自編碼器(VAEs)
變分自編碼器(Variational Autoencoders, VAEs)是一類生成模型,通過學習數據的潛在表示來生成新數據。它們在圖像生成、異常檢測、數據壓縮等領域有著廣泛的應用。與生成對抗網絡(GANs)不同,VAEs依賴于概率圖模型和變分推理方法,是一種對數據分布進行顯式建模的生成方法。
2.1 VAEs的基本架構
變分自編碼器由兩個主要部分組成:編碼器(Encoder)和解碼器(Decoder)。與傳統自編碼器不同,VAEs在潛在空間上引入了概率分布的概念,使其具有更好的生成能力。
-
編碼器(Encoder):編碼器將輸入數據(如圖像)映射到潛在空間中的概率分布。具體來說,編碼器輸出潛在變量的均值 𝜇μ 和標準差 𝜎σ,從而定義一個高斯分布 𝑞(𝑧∣𝑥)q(z∣x)。編碼器的目標是近似真實的后驗分布 𝑝(𝑧∣𝑥)p(z∣x)。
-
解碼器(Decoder):解碼器從潛在空間中采樣潛在變量 𝑧z,并將其轉換回原始數據空間,從而生成新的數據。解碼器的目標是最大化生成數據與真實數據的相似度。
2.2 變分自編碼器的訓練過程
VAEs的訓練過程基于變分推理,通過優化證據下界(Evidence Lower Bound, ELBO)來逼近真實的后驗分布。訓練過程包括以下步驟:
-
輸入數據:從訓練數據集中采樣一批數據點 𝑥x。
-
編碼:通過編碼器將數據 𝑥x 映射到潛在空間,得到均值 𝜇μ 和標準差 𝜎σ。
-
采樣:從高斯分布 𝑞(𝑧∣𝑥)q(z∣x) 中采樣潛在變量 𝑧z。為了實現可微分的采樣過程,通常使用重參數化技巧,即 𝑧=𝜇+𝜎?𝜖z=μ+σ??,其中 𝜖? 是從標準正態分布中采樣的噪聲。
-
解碼:通過解碼器將采樣的潛在變量 𝑧z 轉換為生成數據 𝑥^x^。
-
計算損失:損失函數由重構誤差和KL散度兩部分組成:
- 重構誤差(Reconstruction Error):度量生成數據?𝑥^x^?與真實數據?𝑥x?之間的差異,通常采用均方誤差(MSE)或交叉熵損失。
- KL散度(KL Divergence):度量近似后驗分布?𝑞(𝑧∣𝑥)q(z∣x)?與先驗分布?𝑝(𝑧)p(z)?之間的差異。先驗分布通常設定為標準正態分布。
-
優化:通過梯度下降優化損失函數,更新編碼器和解碼器的參數。
2.3 數學表達
VAEs的目標是最大化證據下界(ELBO):
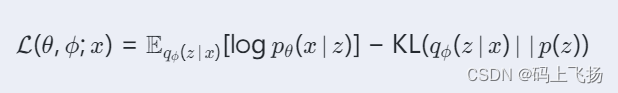
其中:
- 𝑥x?是輸入數據。
- 𝑧z?是潛在變量。
- 𝑞𝜙(𝑧∣𝑥)q??(z∣x)?是編碼器定義的近似后驗分布。
- 𝑝𝜃(𝑥∣𝑧)pθ?(x∣z)?是解碼器定義的生成分布。
- 𝑝(𝑧)p(z)?是先驗分布,通常為標準正態分布。
通過最大化ELBO,可以同時最小化重構誤差和KL散度,從而實現高質量的生成效果。
2.4 變分自編碼器的改進與應用
自提出以來,VAEs在多個方面得到了改進,以提高其生成質量和訓練穩定性。以下是幾種重要的改進:
-
β-VAE:通過引入調節因子 𝛽β,權衡重構誤差和KL散度的比例,增強生成結果的多樣性和解釋性。
-
Conditional VAE(CVAE):在輸入數據上附加條件信息(如標簽),使得生成的樣本符合特定的條件分布,廣泛應用于圖像標注和風格轉換等任務。
-
VQ-VAE(Vector Quantized VAE):結合離散潛在變量的量化技術,提高生成圖像的細節表現能力。
2.5 示例:使用VAE進行手寫數字生成
以MNIST手寫數字數據集為例,訓練一個簡單的VAE模型來生成手寫數字。以下是訓練過程的簡要步驟:
-
數據預處理:將MNIST數據集中的圖像歸一化,并劃分為訓練集和測試集。
-
模型構建:定義編碼器和解碼器網絡結構,編碼器輸出潛在變量的均值和標準差,解碼器將潛在變量映射回圖像空間。
-
訓練模型:通過優化ELBO,訓練VAE模型,使其能夠生成與MNIST數字相似的手寫數字圖像。
-
生成圖像:訓練完成后,從標準正態分布中采樣潛在變量,通過解碼器生成新圖像。
通過上述過程,可以生成與MNIST數據集中真實數字相似的手寫數字圖像,展示了VAE在圖像生成方面的強大能力。
總之,變分自編碼器(VAEs)作為一種基于概率模型的生成方法,通過學習數據的潛在表示,實現了高質量的數據生成。其在圖像生成、異常檢測、數據壓縮等領域的廣泛應用,展示了人工智能在生成建模方面的巨大潛力和發展前景。
二、AI作畫算法的實際應用
隨著人工智能技術的發展,AI作畫算法在多個領域得到了廣泛應用,不僅在藝術創作中表現出色,還在商業、娛樂、醫療等領域發揮了重要作用。以下是一些具體的應用場景和實例。
1. 藝術創作
AI藝術家和創意合作:AI作畫算法可以與人類藝術家合作,創造出前所未有的藝術作品。通過生成對抗網絡(GANs)或變分自編碼器(VAEs),AI可以根據輸入的圖像風格生成新的藝術作品。例如,法國藝術團體Obvious利用GANs創作的肖像畫《Edmond de Belamy》,在佳士得拍賣行以超過43萬美元的價格售出,成為首個被拍賣的AI生成藝術品。這表明,AI在藝術市場上也有著巨大的潛力。
自動風格遷移:AI可以將一種藝術風格應用到另一種圖像上,這種技術被稱為風格遷移(Style Transfer)。例如,利用神經網絡,AI可以將梵高的畫風應用到一張普通的照片上,使其看起來像是一幅梵高的畫作。這項技術不僅可以用于個人創作,還可以應用于廣告設計、影視制作等領域,幫助創意團隊快速生成具有特定風格的視覺內容。
2. 商業應用
品牌推廣和廣告設計:在商業領域,AI作畫算法被廣泛用于品牌推廣和廣告設計。AI可以根據品牌的視覺識別系統自動生成海報、廣告圖像等,使得設計過程更加高效。例如,Adobe的Sensei平臺利用AI技術幫助設計師快速生成和調整設計元素,提高了創意團隊的工作效率。
定制化產品設計:AI還可以根據客戶的需求生成定制化的設計產品。比如,時尚品牌可以利用AI技術根據客戶的偏好設計獨特的服裝圖案和款式,家具公司可以利用AI生成個性化的家居設計方案,滿足客戶的個性化需求。
3. 娛樂與媒體
電影和游戲制作:在影視和游戲制作中,AI作畫算法可以生成高質量的場景和角色圖像,降低制作成本和時間。Pixar和Disney等大型影視公司已經開始探索利用AI技術輔助動畫制作,提高動畫制作的效率和質量。游戲開發公司也利用AI生成逼真的游戲場景和角色,使游戲更加生動和引人入勝。
虛擬現實和增強現實:AI在虛擬現實(VR)和增強現實(AR)中的應用也十分廣泛。AI可以生成逼真的虛擬場景和對象,提升用戶的沉浸體驗。例如,AI可以根據用戶的環境生成適合的AR內容,使得AR應用更加靈活和互動。
4. 醫療領域
醫學影像處理:AI作畫算法在醫學影像處理方面也有重要應用。AI可以生成和增強醫學圖像,幫助醫生更準確地進行診斷。例如,AI可以將低分辨率的MRI圖像增強為高分辨率圖像,幫助醫生更清晰地觀察病變部位,提高診斷的準確性。
手術模擬和培訓:AI生成的3D圖像和虛擬現實技術結合,可以用于手術模擬和培訓。醫生可以在虛擬環境中進行手術練習,提高手術技能和應急處理能力。這不僅提高了醫生的手術水平,還減少了手術過程中的風險。
5. 教育與研究
藝術教育:AI作畫算法在藝術教育中也有廣泛應用。通過AI生成的藝術作品,學生可以學習和模仿不同風格的藝術創作,提高藝術創作能力。同時,AI還可以幫助教師快速生成教學材料,提高教學效率。
科學研究:在科學研究中,AI可以生成各種模擬圖像和數據,輔助研究人員進行實驗分析和數據可視化。例如,在天文學中,AI可以根據觀測數據生成宇宙的模擬圖像,幫助研究人員更好地理解宇宙的結構和演化。
結論
AI作畫算法通過生成高質量的圖像和藝術作品,已經在多個領域得到了廣泛應用。從藝術創作到商業設計,從醫療影像到教育研究,AI在各個領域展示了其強大的生成能力和創新潛力。隨著技術的不斷發展,AI作畫算法將會在更多領域發揮重要作用,推動人工智能技術的進步和應用拓展。
三、AI作畫的發展前景
隨著人工智能技術的不斷進步,AI作畫領域展現出廣闊的發展前景。以下是對AI作畫未來可能的技術發展、應用拓展和社會影響的詳細探討。
1. 技術發展方向
更高的生成質量:未來,AI作畫算法將在圖像生成的質量和細節處理上取得顯著進步。通過更復雜的神經網絡架構和更大規模的訓練數據,AI可以生成更加逼真和高分辨率的圖像。例如,最新的生成對抗網絡(GANs)和變分自編碼器(VAEs)模型正在不斷優化,以提高圖像的細節表現和真實性。
多模態融合:AI作畫算法將向多模態方向發展,不僅僅局限于圖像生成,還將結合聲音、文本等多種數據形式。例如,通過結合自然語言處理技術,AI可以根據描述性文本生成相應的圖像。這種多模態融合技術將極大拓展AI作畫的應用場景,使其更加智能和多樣化。
實時生成與交互:未來的AI作畫技術將更加注重實時性和交互性。用戶可以通過簡單的指令和交互界面,實時生成和調整圖像內容。這種技術將為用戶帶來更加便捷和高效的創作體驗,廣泛應用于個性化設計、娛樂創作等領域。
2. 應用拓展
教育領域的深入應用:隨著AI作畫技術的發展,其在教育領域的應用將更加廣泛和深入。AI可以生成豐富多樣的教學材料,幫助學生更好地理解和掌握知識。例如,在美術教育中,AI可以模擬不同藝術家的創作風格,幫助學生學習和模仿。此外,AI還可以輔助教師進行個性化教學,針對學生的學習特點生成專屬的學習資源。
醫療影像與診斷:在醫療領域,AI作畫技術將繼續發揮重要作用。通過生成和增強醫學圖像,AI可以幫助醫生更準確地進行診斷和治療。例如,AI可以根據醫學影像生成3D模型,輔助醫生進行手術規劃和模擬。同時,AI還可以通過分析大量醫學圖像數據,發現潛在的病變和異常,提供早期預警和診斷支持。
虛擬現實和增強現實:AI作畫技術將在虛擬現實(VR)和增強現實(AR)領域得到更廣泛的應用。AI可以生成高度逼真的虛擬場景和對象,提升用戶的沉浸體驗。例如,在游戲和娛樂領域,AI可以實時生成動態場景和角色,使用戶的互動體驗更加豐富和多樣化。在工業和教育培訓中,AI生成的虛擬環境可以模擬真實場景,提供更直觀和高效的培訓體驗。
創意產業的變革:AI作畫技術將推動創意產業的變革和創新。通過自動生成高質量的視覺內容,AI可以顯著降低創作成本和時間,提高創意團隊的工作效率。例如,在電影和動畫制作中,AI可以輔助生成場景設計和角色造型,加快制作周期。同時,AI還可以為藝術家提供靈感和創作輔助,推動藝術創作的多樣化和創新性。
3. 社會影響
重新定義藝術創作:AI作畫技術的發展將重新定義藝術創作的概念和實踐。盡管AI生成的作品在技術層面上與人類創作沒有本質區別,但其創作過程和思維方式卻截然不同。這將引發關于藝術本質和創造力的深刻思考和討論。未來,AI與人類藝術家的合作將越來越普遍,共同探索藝術創作的新形式和新可能。
推動就業市場轉型:隨著AI作畫技術的普及,相關領域的就業市場將發生轉型和調整。一方面,傳統的設計和創作崗位可能受到一定沖擊,另一方面,新的就業機會將不斷涌現。例如,AI模型的開發、訓練和維護需要大量專業人才,同時,AI生成內容的應用和管理也需要新的職業角色。教育和培訓系統將需要適應這種變化,為未來的就業市場培養合適的人才。
倫理和版權問題:AI作畫技術的發展也帶來了倫理和版權方面的挑戰。AI生成的作品是否具有版權,其創作權應該歸屬于誰,這些問題亟需法律和制度的明確規定。此外,AI技術的濫用可能帶來虛假信息和內容泛濫的問題,社會需要建立相應的監管機制,確保AI技術的合理使用和健康發展。
結語
AI作畫技術在未來將繼續快速發展,推動技術、應用和社會的多方面變革。盡管面臨諸多挑戰,但其潛力和前景無疑是巨大的。隨著技術的不斷進步和應用的深入,AI作畫將為人類社會帶來更多創新和價值,成為未來人工智能領域的重要組成部分。
結論
AI作畫是一項令人興奮的技術,它不僅推動了藝術創作的創新,也展示了人工智能在視覺生成方面的強大潛力。通過深入理解AI作畫的核心算法原理,讀者可以更好地掌握這一技術,并在實際應用中發揮其巨大潛力。未來,隨著技術的不斷發展,AI作畫將為我們的生活帶來更多驚喜和創意。








)







:靜態、友元和內部類)

)
