SELFIE: Refurbishing Unclean Samples for Robust Deep Learning
摘要:
由于深度神經網絡具有極高的表達能力,其副作用是即使在標簽噪聲極高的情況下也能完全記住訓練數據。為了克服對噪聲標簽的過度擬合,我們提出了一種名為 SELFIE 的新型魯棒訓練方法。我們的主要想法是有選擇地翻新和利用可以高精度修正的不干凈樣本,從而逐步增加可用訓練樣本的數量。利用這一設計優勢,SELFIE 有效地防止了錯誤修正帶來的噪聲積累風險,并充分利用了訓練數據。為了驗證 SELFIE 的優越性,我們使用四個真實世界或合成數據集進行了大量實驗。結果表明,與兩種最先進的方法相比,SELFIE 顯著改善了絕對測試誤差。
介紹:
隨著可用數據集規模的快速增長,深度神經網絡在圖像分類(Krizhevsky 等人,2012 年)和物體檢測(Redmon 等人,2016 年)等眾多機器學習任務中取得了不俗的表現。然而,由于神經網絡具有很強的適應任何噪聲標簽的能力,眾所周知,訓練數據中的一小部分錯誤標簽樣本會嚴重影響模型的性能。特別是,Zhang 等人(2017)的研究表明,標準卷積神經網絡可以以任意比例的噪聲標簽擬合整個訓練數據,并最終導致測試數據的泛化效果不佳。因此,問題的關鍵在于如何在訓練數據中存在錯誤標簽樣本的情況下仍能穩健地訓練深度神經網絡。
一種典型的方法是使用 "loss修正",根據估計的噪聲修正訓練樣本的loss過渡矩陣(Zhang 等人,2017;Goldberger & BenReuven,2017;Patrini 等人,2017;Chang 等人,2017)。如圖 1(a)所示,每個迷你批次中所有樣本的前向或后向損失都會被修正,隨后反向傳播以更新網絡。然而,由于噪聲轉換矩陣難以估計,網絡不可避免地會積累因錯誤校正而產生的誤差,尤其是在類數或誤標樣本數較多時(Jiang 等,2018;Han 等,2018)。
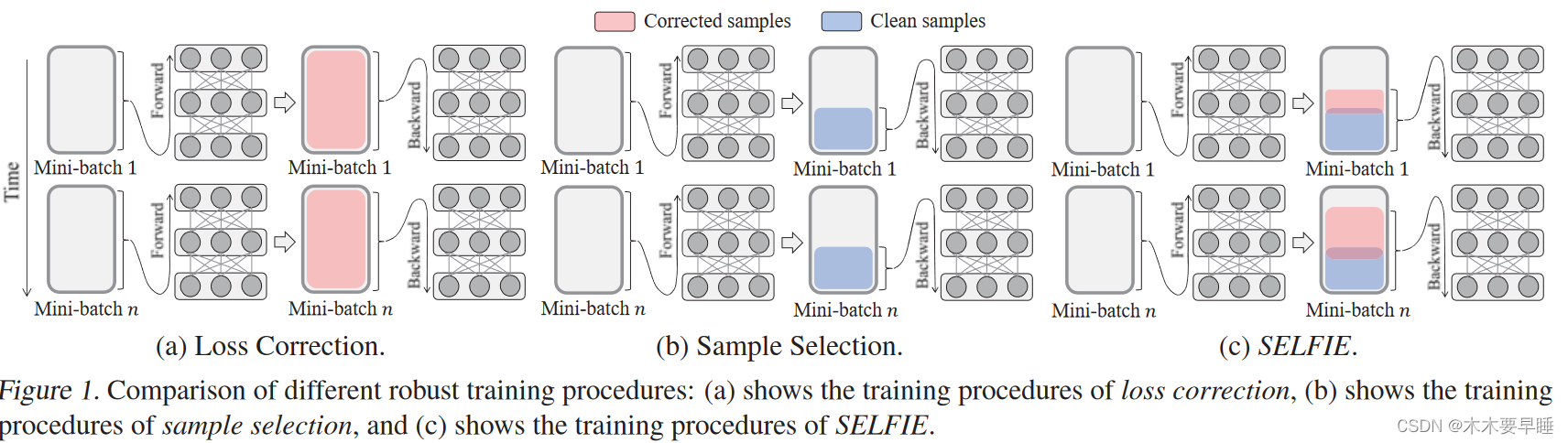
為了擺脫錯誤修正,最近的許多研究都采用了 "樣本選擇",即從訓練數據中過濾出真實標簽樣本(Kumar 等,2010;Jiang 等,2018;Han 等,2018)。他們根據前向損失從迷你批次中識別出干凈樣本,并用它們來更新網絡,如圖 1(b) 所示。在實踐中,Han 等人(2018 年)的研究表明,在極高噪聲數據上,對干凈樣本進行訓練比校正整個樣本的性能要好得多。然而,專注于選定的干凈樣本會偏向于容易樣本,從而忽略大量有用的硬樣本,而這些樣本會使網絡更加準確和魯棒(Shrivastava 等人,2016 年;Chang 等人,2017 年;Lin 等人,2018 年)。因此,為了在有噪聲的標簽上進行更穩健的訓練,我們建議翻新不干凈的樣本?




)

的維度)
)
)

![51 單片機[2-1]:點亮一個LED](http://pic.xiahunao.cn/51 單片機[2-1]:點亮一個LED)
)


)


)

)