參考筆記
下面給出一個巨佬學習風變pyhton基礎語法和爬蟲精進的筆記(鏈接)
風變編程筆記(一)-Python基礎語法
風變編程筆記(二)-Python爬蟲精進
技術總結
request + BeautifulSoup
selenium + BeautifulSoup
練習0-1:文章下載
import requests
res=requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/exercise/HTTP%E5%93%8D%E5%BA%94%E7%8A%B6%E6%80%81%E7%A0%81.md')
files=res.text
print(files)
myfiles=open('myfiles.txt','w+')
myfiles.write(files)
myfiles.close()
練習0-2:圖像下載
import requests
res=requests.get('https://res.pandateacher.com/2019-01-12-15-29-33.png')
pic = res.content
photo = open('ppt1.jpg','wb')
#新建了一個文件ppt.jpg,這里的文件沒加路徑,它會被保存在程序運行的當前目錄下。
#圖片內容需要以二進制wb讀寫。你在學習open()函數時接觸過它。
photo.write(pic)
#獲取pic的二進制內容
photo.close()
練習0-3:音頻下載
import requests
rec=requests.get('https://static.pandateacher.com/Over%20The%20Rainbow.mp3')
req=rec.content
mymusic=open('mymusic1.mp3','wb')
mymusic.write(req)
mymusic.close()
練習1-1:我的書苑我做主
必做:
修改網頁標題
增加至少一本書的描述
修改網頁底部
選做:
修改已有書籍的描述
增加多本書的描述
自由地在HTML文檔上修改任意內容
<html><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8"><title>這個書苑不太冷5.0</title><style>a {text-decoration: none;}body {margin: 0;width:100%;height: 100%;}#header {background-color:#0c1f27;color:#20b2aa;text-align:center;padding:15px;}#nav {line-height:60px;background-color:#e0f2f0;width:80px;padding:30px;position: absolute;left: 0;top:0;bottom: 0;}#footer {background-color:#0c1f27;color:#20b2aa;clear:both;text-align:center;padding:35px;}#main {margin-left: 140px;padding-left: 150px;padding-right: 220px;overflow: scroll;}#article {display: flex;position: relative;}.catlog{font-size:20px;color:black;font-family: sans-serif;}.title {color:#20b2aa;font-size:20px;}.img {width: 185px;height: 266px;}</style></head><body><div id="header"><h1 style="font-size:50px;">這個書苑不太冷</h1></div><div id="article"><div id="nav"><a href="#type1" class="catlog">科幻小說</a><br><a href="#type2" class="catlog">人文讀物</a><br><a href="#type3" class="catlog">技術參考</a><br></div><div id="main"><div class="books"><h2><a name="type1">科幻小說</a></h2><a href="https://book.douban.com/subject/27077140/" class="title">《奇點遺民》</a><p class="info">本書精選收錄了劉宇昆的科幻佳作共22篇。《奇點遺民》融入了科幻藝術吸引人的幾大元素:數字化生命、影像化記憶、人工智能、外星訪客……劉宇昆的獨特之處在于,他寫的不是科幻探險或英雄奇幻,而是數據時代里每個人的生活和情感變化。透過這本書,我們看到的不僅是未來還有當下。</p> <img class="img" src="https://img3.doubanio.com/view/subject/l/public/s29492583.jpg"><br/><br/><hr size="1"></div><div class="books"><h2><a name="type2">人文讀物</a></h2><a href="https://book.douban.com/subject/26943161/" class="title">《未來簡史》</a><p class="info">未來,人類將面臨著三大問題:生物本身就是算法,生命是不斷處理數據的過程;意識與智能的分離;擁有大數據積累的外部環境將比我們自己更了解自己。如何看待這三大問題,以及如何采取應對措施,將直接影響著人類未來的發展。</p> <img class="img" src="https://img3.doubanio.com/view/subject/l/public/s29287103.jpg"><br/><br/><hr size="1"></div><div class="books"><h2><a name="type3">技術參考</a></h2><a href="https://book.douban.com/subject/25779298/" class="title">《利用Python進行數據分析》</a><p class="info">本書含有大量的實踐案例,你將學會如何利用各種Python庫(包括NumPy、pandas、matplotlib以及IPython等)高效地解決各式各樣的數據分析問題。由于作者Wes McKinney是pandas庫的主要作者,所以本書也可以作為利用Python實現數據密集型應用的科學計算實踐指南。本書適合剛剛接觸Python的分析人員以及剛剛接觸科學計算的Python程序員。</p> <img class="img" src="ttps://img3.doubanio.com/view/subject/l/public/s27275372.jpg"><br/><br/><hr size="1"></div></div></div><div id="footer">Copyright ? ForChange 風變科技</div></body>
</html>
第2關:這個書苑不太冷(靜態網頁)
目標網址:https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html
即爬取這個書苑不太冷網站中每本書的類型、名字、鏈接和簡介的文字
# 調用requests庫
import requests
# 調用BeautifulSoup庫
from bs4 import BeautifulSoup
# 返回一個response對象,賦值給res
res =requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
# 把res解析為字符串
html=res.text
# 把網頁解析為BeautifulSoup對象
soup = BeautifulSoup( html,'html.parser')
# 通過匹配屬性class='books'提取出我們想要的元素
items = soup.find_all(class_='books')
# 遍歷列表items
for item in items: # 在列表中的每個元素里,匹配標簽<h2>提取出數據 kind = item.find('h2') # 在列表中的每個元素里,匹配屬性class_='title'提取出數據 title = item.find(class_='title') # 在列表中的每個元素里,匹配屬性class_='info'提取出數據 brief = item.find(class_='info') # 打印書籍的類型、名字、鏈接和簡介的文字print(kind.text,'\n',title.text,'\n',title['href'],'\n',brief.text)
練習2-1:博客爬蟲
目標網址:https://wordpress-edu-3autumn.localprod.oc.forchange.cn/all-about-the-future_04/


import requests
from bs4 import BeautifulSoupres=requests.get('https://wordpress-edu-3autumn.localprod.oc.forchange.cn/all-about-the-future_04/')
html=res.text
soup=BeautifulSoup(html,'html.parser')
Aitems=soup.find(class_='comment-list')#用find找出大的地址
items=Aitems.find_all('article')#在大的地址中用find_all來找出小地址的列表for item in items:user1=item.find('b') # user1=item.find(class_='fn')comment1=item.find(class_='comment-content')print('評論者',user1.text,'\n','評論',comment1.text)練習2-2:書店尋寶
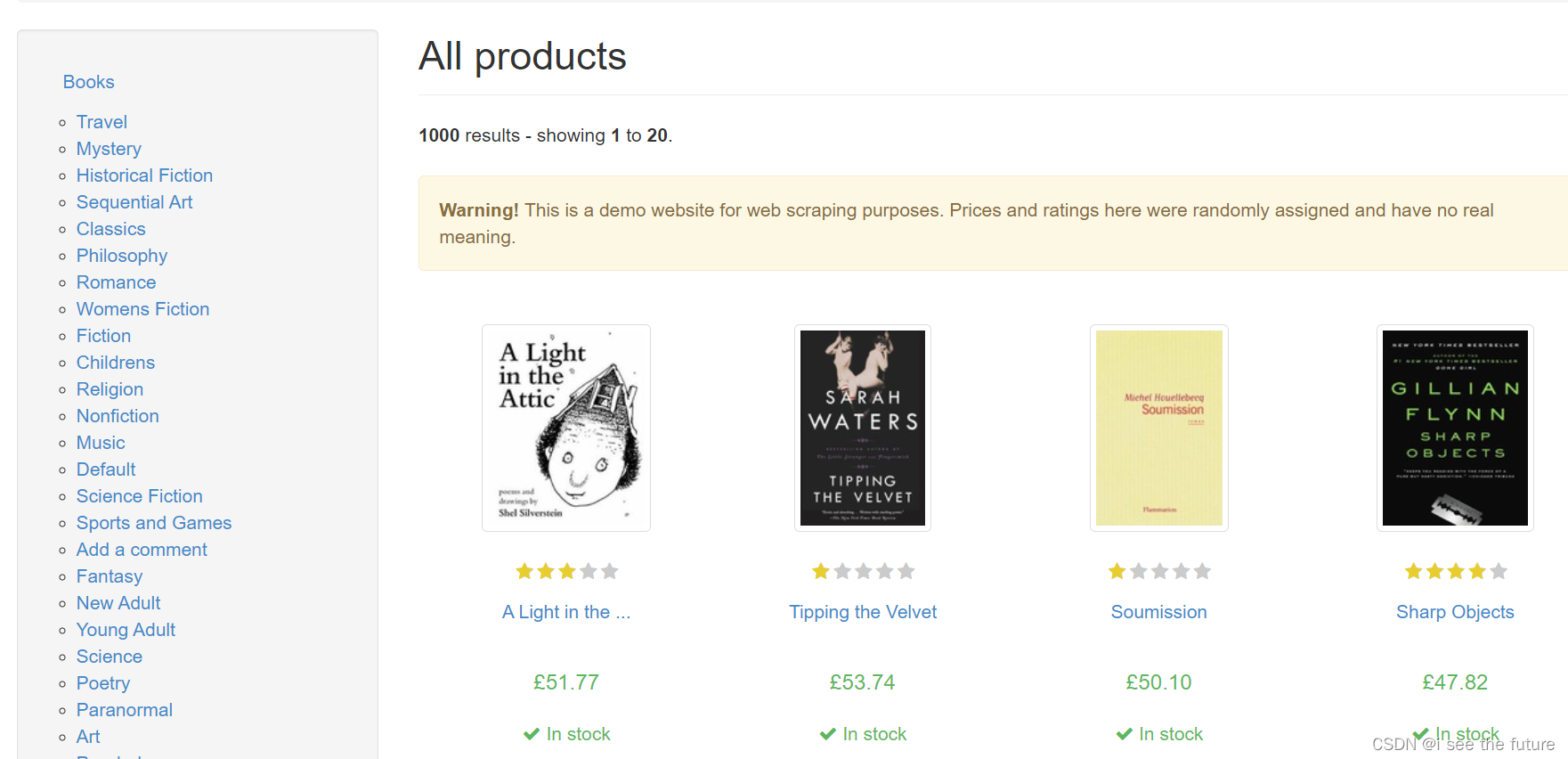
目標網址:http://books.toscrape.com/


import requests
from bs4 import BeautifulSoupres=requests.get('http://books.toscrape.com/')
html=res.text
soup=BeautifulSoup(html,'html.parser')
items=soup.find('ul',class_='nav nav-list').find('li').find('ul').find_all('li')'''
for item in items:fenlei=item.find('a')print((fenlei.text).strip())with open('doc3.doc','a+') as doc3:doc3.write((fenlei.text).strip())doc3.write('\n')
'''item_book=soup.find('ol',class_='row').find_all('li')
#print(item_book)for item in item_book:item_name=item.find('article',class_='product_pod').find('h3').find('a')item_price=item.find('article',class_='product_pod').find('div',class_='product_price').find('p',class_='price_color')item_rate=item.find('article',class_='product_pod').find('p')
# print(item_rate['class'][1])
# print(item_name['title'],'\t')
# print(item_price.text)
# print(item_name['title'],'\t',item_price.text)print(item_name['title'],'\t',item_price.text,'\t',item_rate['class'][1])
練習2-3:博客文章
目標網址:https://wordpress-edu-3autumn.localprod.oc.forchange.cn/
import requests
from bs4 import BeautifulSoupres=requests.get('https://wordpress-edu-3autumn.localprod.oc.forchange.cn/')
html=res.text
soup=BeautifulSoup(html,'html.parser')
Aitems=soup.find(id='main')#用find找出大的地址
items=Aitems.find_all('article')#在大的地址中用find_all來找出小地址的列表for item in items:item1=item.find(class_="entry-title") item2=item.find(class_='entry-date published')item3=item.find('h2').find('a')['href']print('標題',item1.text,'\n','時間',item2.text,'\n','鏈接',item3)
第3關:下廚房
目標網址:https://www.xiachufang.com/explore/
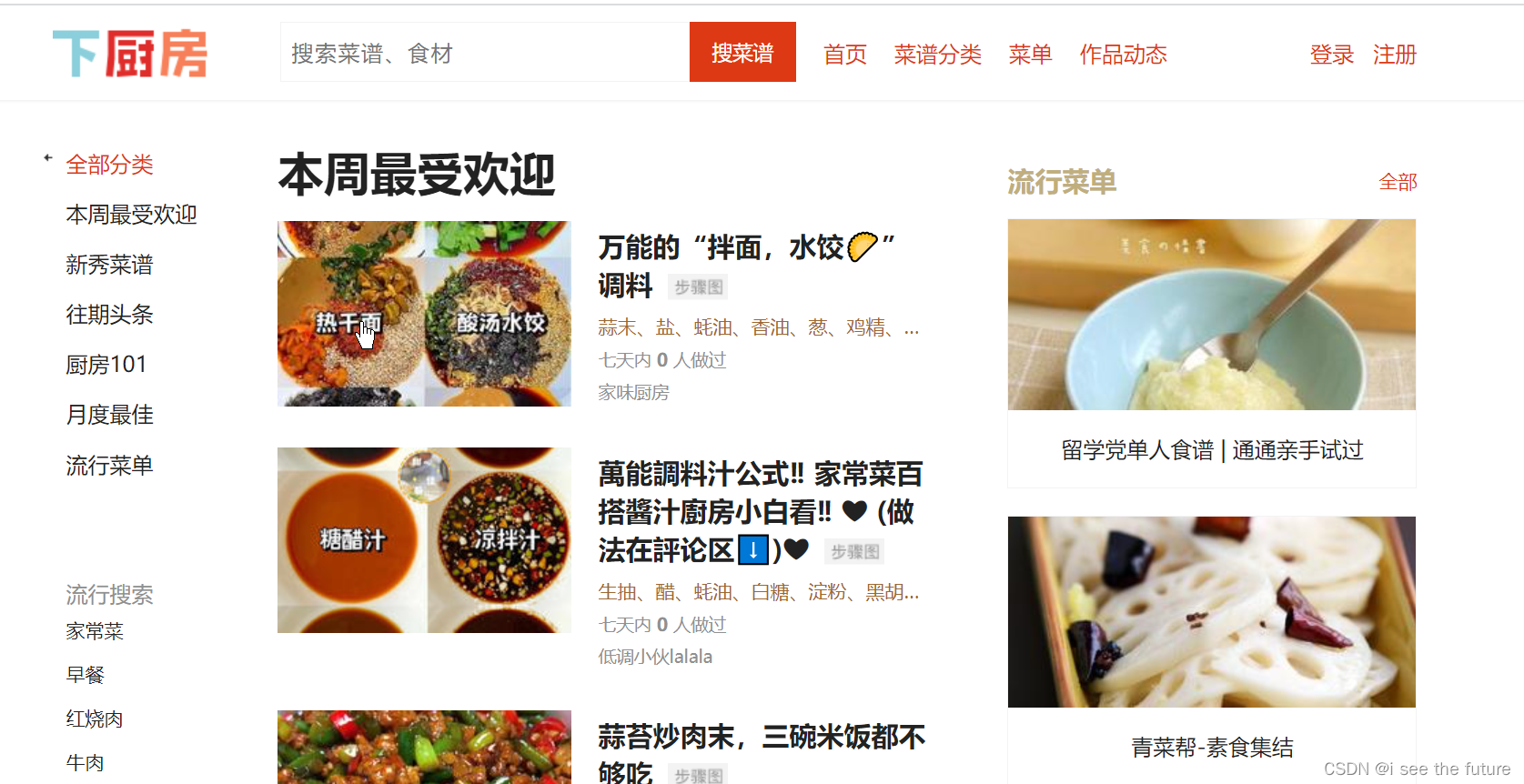
寫一個循環,提取當前頁面的所有菜名、URL、食材,并將它存入列表。其中每一組菜名、URL、食材是一個小列表,小列表組成一個大列表。
# 引用requests庫
import requests
# 引用BeautifulSoup庫
from bs4 import BeautifulSoup# 獲取數據
res_foods = requests.get('http://www.xiachufang.com/explore/')
# 解析數據
bs_foods = BeautifulSoup(res_foods.text,'html.parser')
# 查找最小父級標簽
list_foods = bs_foods.find_all('div',class_='info pure-u')# 創建一個空列表,用于存儲信息
list_all = []for food in list_foods:# 提取第0個父級標簽中的<a>標簽tag_a = food.find('a')# 菜名,使用[17:-13]切掉了多余的信息name = tag_a.text[17:-13]# 獲取URLURL = 'http://www.xiachufang.com'+tag_a['href']# 提取第0個父級標簽中的<p>標簽tag_p = food.find('p',class_='ing ellipsis')# 食材,使用[1:-1]切掉了多余的信息ingredients = tag_p.text[1:-1]# 將菜名、URL、食材,封裝為列表,添加進list_alllist_all.append([name,URL,ingredients])# 打印
print(list_all)
我的做法:順便下載圖片(大同小異)
import requests
from bs4 import BeautifulSoupheaders = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',# 標記了請求從什么設備,什么瀏覽器上發出}res=requests.get('https://www.xiachufang.com/explore/',headers=headers)
html=res.text
soup=BeautifulSoup(html,'html.parser')
Aitems=soup.find(class_='normal-recipe-list')#用find找出大的地址
items=Aitems.find_all('li')#在大的地址中用find_all來找出小地址的列表item_list = []for item in items:item1=item.find(class_="name") .text.replace('\n\n ','').replace('\n \n\n','').replace('\n','').replace('\n','')item2=item.find(class_='ing ellipsis').text.replace('\n','').replace('\n','').replace('\n','')item3=item.find('a')['href']item4=item.find('img')['data-src']item_list.append([item1,item2,'https://www.xiachufang.com/'+item3])print('菜名',item1,'\n','材料',item2,'\n','鏈接',item3,'圖片鏈接',item4)res=requests.get(item4)pic = res.contentphoto = open(item1+'.jpg','wb')photo.write(pic) photo.close()
#print(item_list)
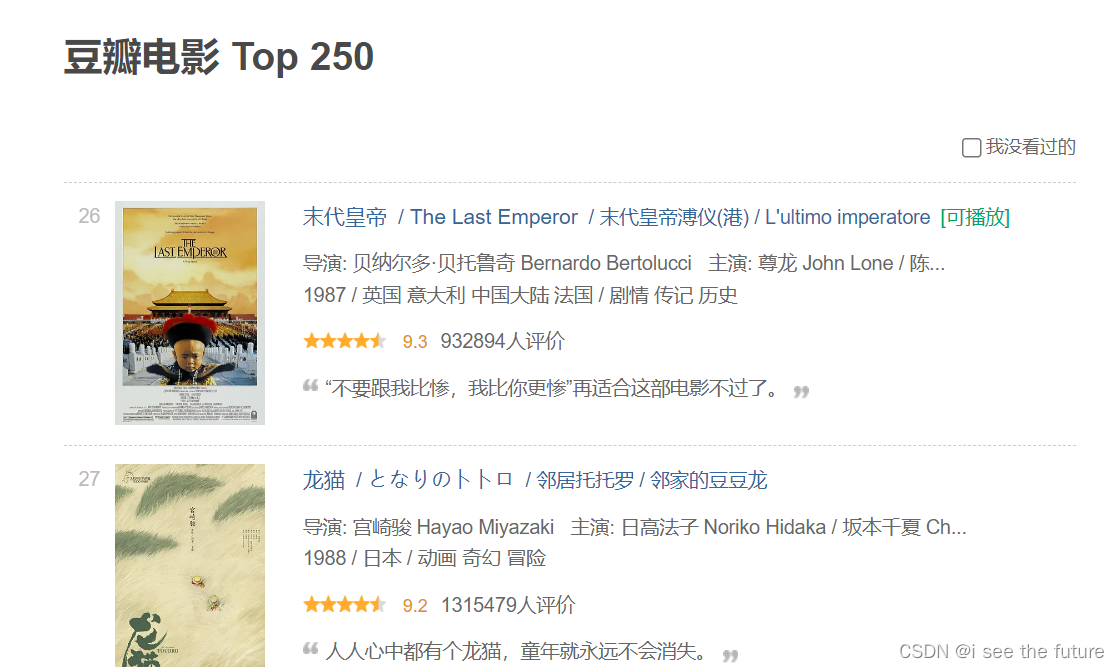
練習3-1:豆瓣電影爬蟲
目標網址:https://movie.douban.com/top250?start=25&filter=

import requests, bs4# 為躲避反爬機制,偽裝成瀏覽器的請求頭
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}for x in range(10):url = 'https://movie.douban.com/top250?start=' + str(x*25) + '&filter='res = requests.get(url, headers=headers)bs = bs4.BeautifulSoup(res.text, 'html.parser')bs = bs.find('ol', class_="grid_view")for titles in bs.find_all('li'):num = titles.find('em',class_="").text#查找序號title = titles.find('span', class_="title").text#查找電影名tes = titles.find('span',class_="inq").text#查找推薦語comment = titles.find('span',class_="rating_num").text#查找評分url_movie = titles.find('a')['href']print(num + '.' + title + '——' + comment + '\n' + '推薦語:' + tes +'\n' + url_movie)
我的答案(差不多)
import requests
from bs4 import BeautifulSoupheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
for i in range(0,10):url = 'https://movie.douban.com/top250?start='+ str(i*25) +'&filter='res=requests.get(url=url,headers=headers)html=res.textsoup=BeautifulSoup(html,'html.parser')Aitems=soup.find(class_='grid_view')#用find找出大的地址items=Aitems.find_all('li')#在大的地址中用find_all來找出小地址的列表item_list = []for item in items:item0=item.find('em').textitem1=item.find('span', class_="title").textitem2=item.find('a')['href']if item.find(class_='inq'): item3=item.find(class_='inq').textelse:item3=''item4=item.find(class_='rating_num').text#item_list.append([item1,item2,item3])print('序號',item0,'\n','電影名',item1,'\n','鏈接',item2,'\n','推薦語',item3,'\n','評分',item4)
練習3-1B:豆瓣電影爬蟲(非風變)
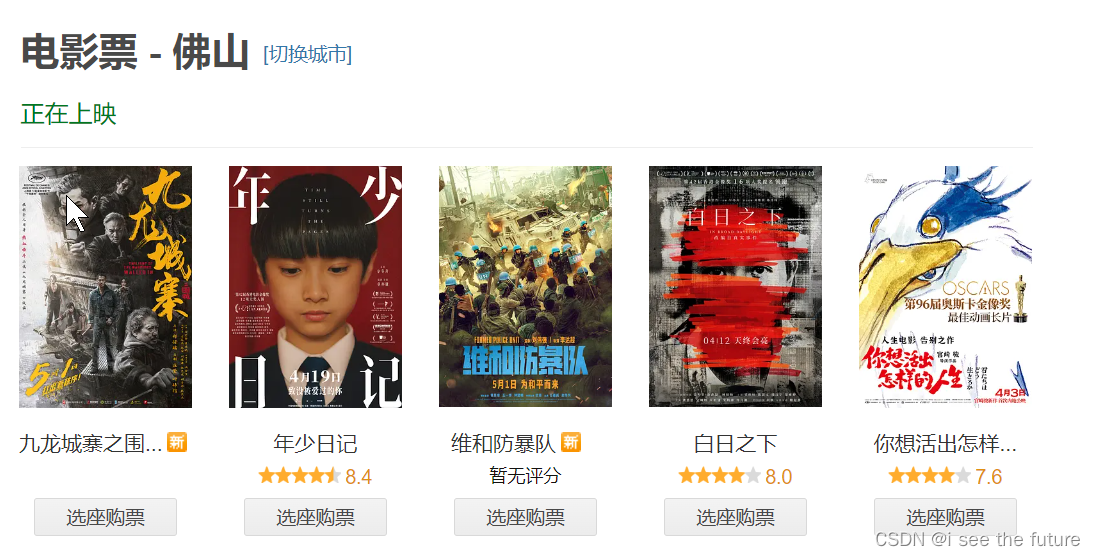
目標網址:https://movie.douban.com/cinema/nowplaying/foshan/
import requests
from bs4 import BeautifulSoupheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
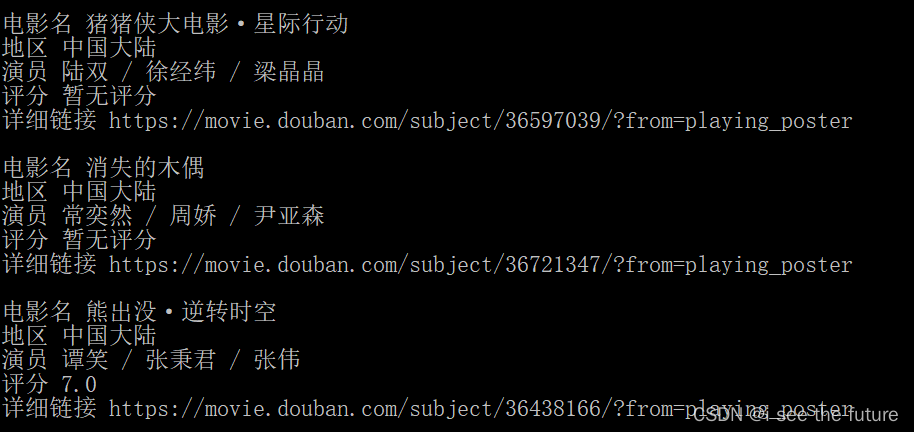
for i in range(0,1):url = 'https://movie.douban.com/cinema/nowplaying/foshan/'res=requests.get(url=url,headers=headers)html=res.textsoup=BeautifulSoup(html,'html.parser')Aitems=soup.find('ul',class_='lists')#用find找出大的地址items=Aitems.find_all('li',class_="list-item")#在大的地址中用find_all來找出小地址的列表item_list = []for item in items:item0=item['data-title']item1=item['data-region']item2=item['data-actors']item3=item.find('li',class_="srating").text.replace('\n','')item4=item.find('a',class_="ticket-btn")['href']print('\n','電影名',item0,'\n','地區',item1,'\n','演員',item2,'\n','評分',item3,'\n','詳細鏈接',item4)
練習3-2:一鍵下電影(風變網址已變更)

1.步驟一
“輸名字”,學過基礎課的同學一定可以想到,用input()就可以啦。
2.步驟二
”搜索結果頁面“ 這里面涉及到一個坑,我們要一起填上。輸入不同的電影名,觀察搜索結果頁面的URL:
《無名之輩》的搜索結果URL:http://s.ygdy8.com/plus/s0.php?typeid=1&keyword=%CE%DE%C3%FB%D6%AE%B1%B2
《神奇動物》的搜索結果URL:http://s.ygdy8.com/plus/s0.php?typeid=1&keyword=%C9%F1%C6%E6%B6%AF%CE%EF
《狗十三》 的搜索結果URL:http://s.ygdy8.com/plus/s0.php?typeid=1&keyword=%B9%B7%CA%AE%C8%FD
觀察URL,不難發現:http://s.ygdy8.com/plus/s0.php?typeid=1&keyword= 這些都是一樣的,只不過不同的電影名對應URL后面加了一些我們看不懂的字符,請閱讀以下代碼,注意注釋哦:
a= '無名之輩'
b= a.encode('gbk')
# 將漢字,用gbk格式編碼,賦值給b
print(quote(b))
# quote()函數,可以幫我們把內容轉為標準的url格式,作為網址的一部分打開#%CE%DE%C3%FB%D6%AE%B1%B2
中文 - gbk - url - 拼接
3.步驟三 + 步驟四
”進入下載頁面“ 與 “找到下載鏈接” 就是解析網頁定位啦,利用find() 和 find_all(),都是你會的內容,加油呀~
練習3-2B:一鍵下電影(新網址–利用Selenium+BS解決)
目標網址:https://www.dygod.net/
import requests
from bs4 import BeautifulSoup
from urllib.parse import quote,unquote
from selenium import webdriver
import os
import time#movie_name = input('請輸入電影名')
movie_name = '怦然心動'# Selenium模擬人工進入
chromedriver = r"C:/Program Files (x86)/Google/Chrome/Application/chromedriver.exe" #這里寫本地的chromedriver 的所在路徑
os.environ['webdriver.Chrome.driver'] = chromedriver #調用chrome瀏覽器
driver = webdriver.Chrome(chromedriver)
driver.maximize_window()
driver.get('https://www.dygod.net/')
time.sleep(1)item1 = driver.find_element_by_name('keyboard')
item1.send_keys(movie_name)
time.sleep(1)item2 = driver.find_element_by_name('Submit')
item2.click()
time.sleep(1)
print('Submit')# 解析新網頁
page_sourse = driver.page_source
#print('page_sourse',page_sourse)
soup=BeautifulSoup(page_sourse,'html.parser')
#print('soup',soup)
Aitems=soup.find('div',class_='co_content8').find_all('table')
#print('Aitems',Aitems)for item in Aitems:item1 = item.find('a',class_="ulink").textitem2 = item.find('a',class_="ulink")['href']print('\n','電影名',item1,'\n','鏈接',item2)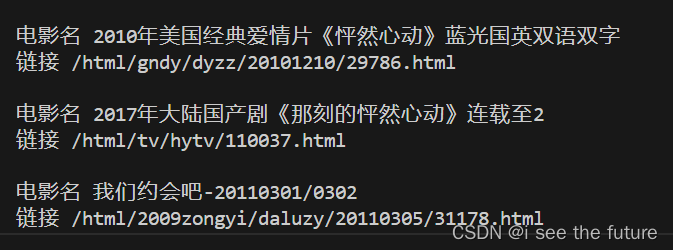
第4關:尋找周杰倫(QQ音樂網頁已變更,原代碼失效)
目標網站:https://y.qq.com/
# 引用requests庫
import requests
# 調用get方法,下載這個字典
res_music = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=60997426243444153&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=20&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
# 使用json()方法,將response對象,轉為列表/字典
json_music = res_music.json()
# 一層一層地取字典,獲取歌單列表
list_music = json_music['data']['song']['list']
# list_music是一個列表,music是它里面的元素
for music in list_music:# 以name為鍵,查找歌曲名print(music['name'])# 查找專輯名print('所屬專輯:'+music['album']['name'])# 查找播放時長print('播放時長:'+str(music['interval'])+'秒')# 查找播放鏈接print('播放鏈接:https://y.qq.com/n/yqq/song/'+music['mid']+'.html\n\n')

——定時任務管理)



)


)








)
