Hive讀寫文件機制
1.SerDe是什么?

-
SerDe是Hive中的一個概念,代表著“序列化/反序列化” (
Serializer/Deserializer)。 -
SerDe在Hive中是用來處理數據如何在Hive與底層存儲系統(例如HDFS)之間進行轉換的機制。
-
在Hive中,數據通常以某種特定的格式存儲在文件中,如文本文件、Parquet文件、ORC文件等。
-
SerDe允許Hive將數據在內存和文件之間進行轉換,即將數據序列化為文件格式以便存儲,或者從文件中讀取數據并反序列化為內存中的數據結構以便查詢。
-
SerDe定義了如何將數據編碼為字節流,并且在需要時將字節流解碼為原始數據格式。它負責解釋數據的結構,以便Hive能夠理解文件中存儲的數據。
-
SerDe通常與Hive表的列進行關聯,用于指定每列數據的序列化和反序列化方法。
-
Hive提供了一些內置的SerDe,如TextSerDe用于處理文本數據,LazySimpleSerDe用于處理以行分隔符分隔的文本數據,AvroSerDe用于處理Avro格式的數據等。

- 此外,用戶也可以編寫自定義的SerDe以滿足特定的數據格式要求。通過使用適當的SerDe,Hive能夠與各種數據格式進行交互,從而實現數據的存儲、查詢和分析。

2.SerDe語法
在Hive中,定義SerDe通常是通過創建表時的ROW FORMAT子句來實現的。

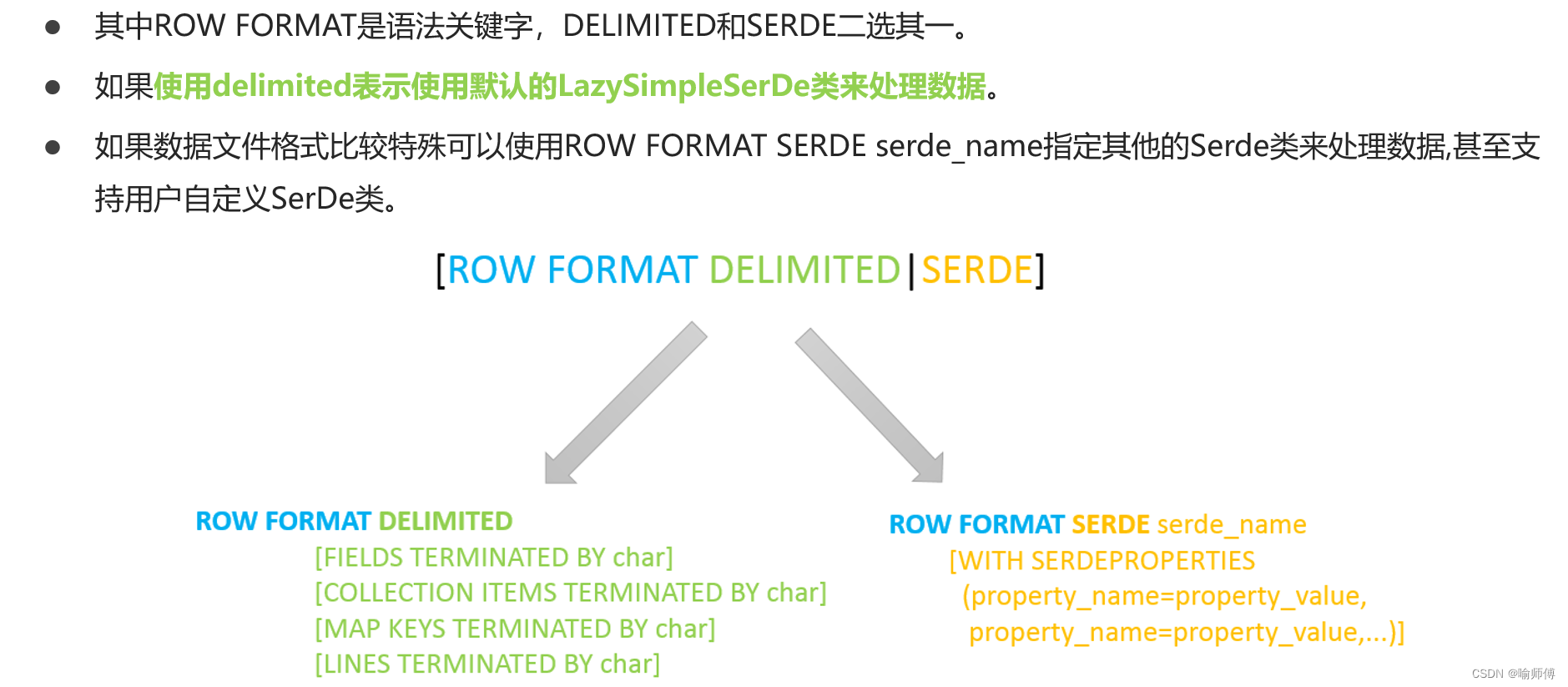
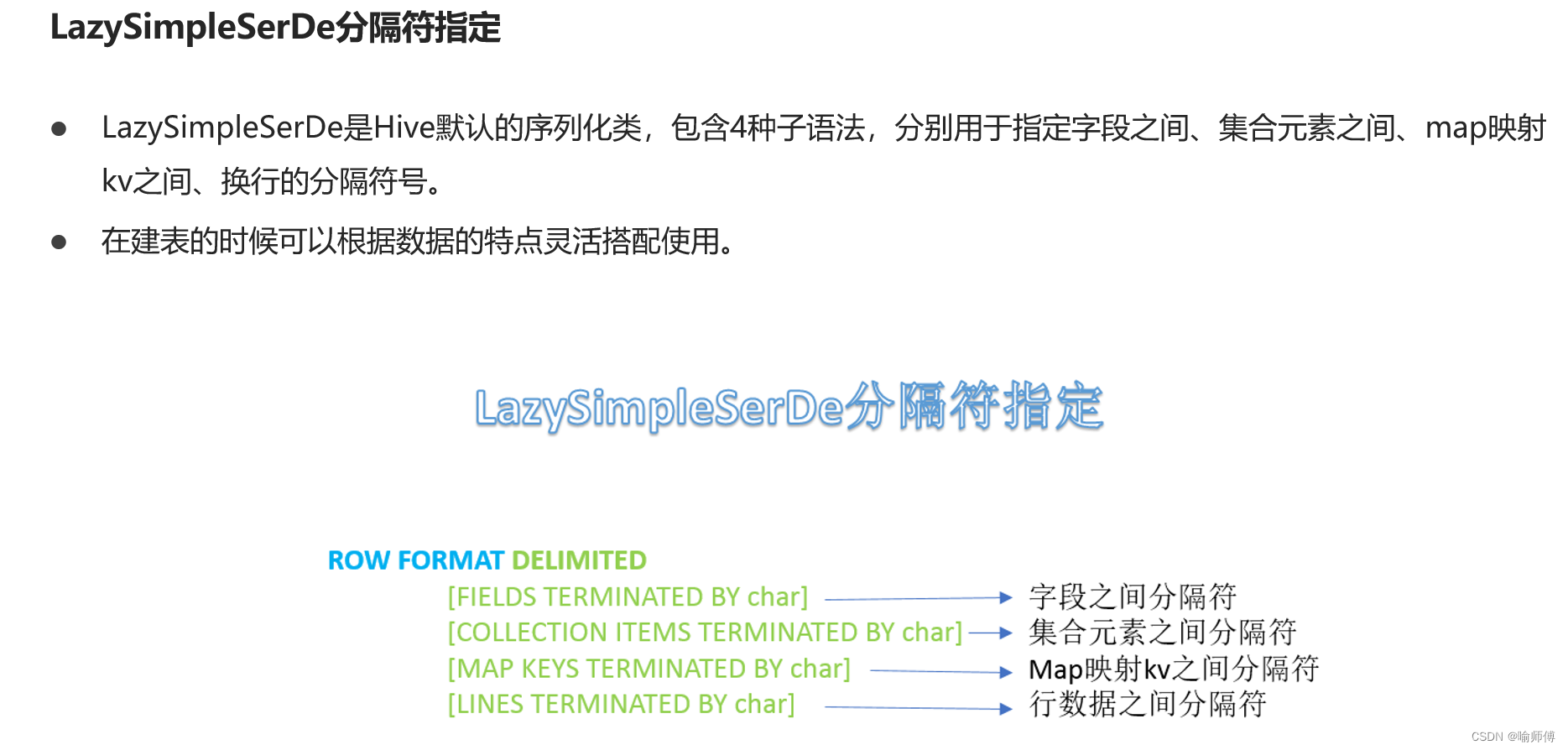
CREATE [EXTERNAL] TABLE table_name (column1 data_type,column2 data_type,...
)
[PARTITIONED BY (partition_column1 data_type, partition_column2 data_type, ...)]
[CLUSTERED BY (clustered_column_name1, clustered_column_name2, ...) INTO num_buckets BUCKETS]
[ROW FORMAT SERDE 'serde_class_name' [WITH SERDEPROPERTIES (...)]]
[STORED AS file_format]
[LOCATION 'hdfs_path']
[TBLPROPERTIES (...)];
關于SerDe的語法部分為:
ROW FORMAT SERDE 'serde_class_name': 指定使用的SerDe類名。這里serde_class_name是SerDe的實現類名。[WITH SERDEPROPERTIES (...)]: 可選項,用于指定SerDe的屬性。這些屬性可以根據具體的SerDe進行設置,比如"field.delim"='\t'表示字段的分隔符是制表符。
示例:
CREATE TABLE my_table (id INT,name STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ("field.delim" = ","
)
STORED AS TEXTFILE;
在這個示例中,創建了一個名為my_table的表,包含兩列id和name。使用內置的LazySimpleSerDe來處理文本數據,設置字段分隔符為逗號。表的數據將以文本文件的形式存儲。






(C語言))
)




)

——繼承,final關鍵字)




