論文鏈接:https://openaccess.thecvf.com/content/CVPR2022/papers/An_Killing_Two_Birds_With_One_Stone_Efficient_and_Robust_Training_CVPR_2022_paper.pdf
代碼鏈接:insightface/recognition/arcface_torch at master · deepinsight/insightface · GitHub
背景
使用基于百萬規模的數據集和基于margin的softmax損失函數來學習區分性的embeddings是當前人臉識別的SOTA方法。然而,全連接層的內存和計算成本隨著訓練集中ID數量的增加而線性增加。此外,大規模訓練數據存在類間沖突(同一個人被分成不同ID)和長尾分布的問題。
傳統FC
將傳統的FC層應用在大規模的數據集上時,存在以下缺陷:
1、gradient confusion under interclass conflict
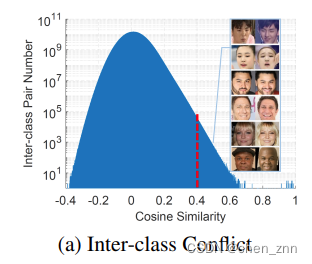
WebFace42M里有很多不同類別對之間的余弦相似度大于0.4,這表明類間沖突仍然存在于這些清洗過的數據集中。直接優化的話會導致gradient confusion(同一個人的特征非常相似卻要掰成兩個ID)
2、centers of tail classes undergo too many passive updates
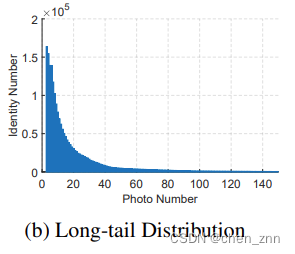
每個iteration都優化圖片數量很少的id,可能會導致負優化
3、the storage and calculation of the FC layer can easily exceed current GPU capabilities
PartialFC
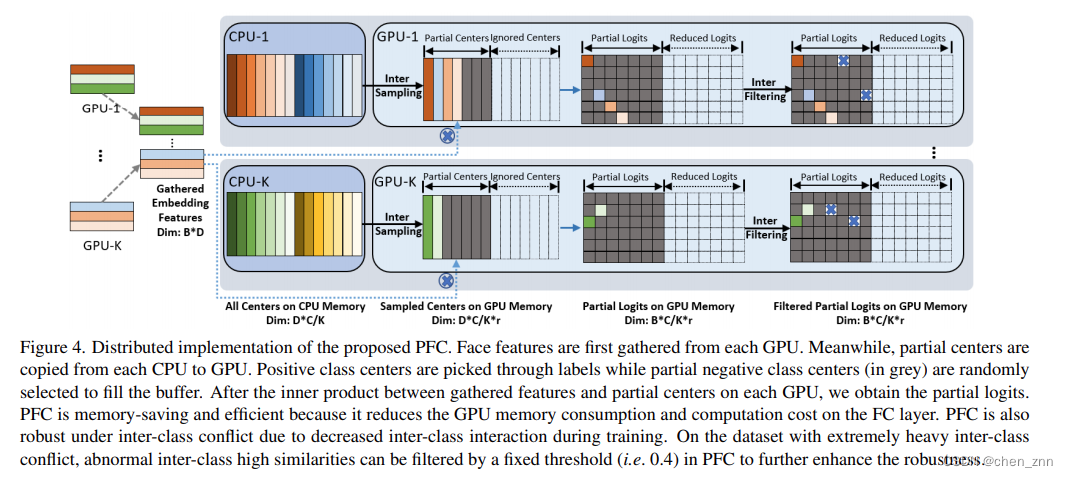
在訓練期間仍然維護所有類別中心,但只隨機采樣一小部分負類別中心來計算基于margin的softmax損失,而不是在每次迭代中使用所有負類別中心。更具體地說,首先從每個GPU收集embeddings和標簽,然后將組合的特征和標簽分布到所有GPU。為了平衡每個GPU的內存使用和計算成本,為每個GPU設置了一個內存緩沖區(下面代碼中的perm)。內存緩沖區的大小由類別總數和負類別中心的采樣率決定。在每個GPU上,首先通過標簽選擇正類中心并放入緩沖區,然后隨機選擇一小部分負類中心(負類中心的數量為self.sample_rate * self.num_local)填充緩沖區的其余部分,
def sample(self, labels, index_positive):"""This functions will change the value of labelsParameters:-----------labels: torch.Tensorpassindex_positive: torch.Tensorpassoptimizer: torch.optim.Optimizerpass"""with torch.no_grad():positive = torch.unique(labels[index_positive], sorted=True).cuda()if self.num_sample - positive.size(0) >= 0:perm = torch.rand(size=[self.num_local]).cuda()perm[positive] = 2.0index = torch.topk(perm, k=self.num_sample)[1].cuda()index = index.sort()[0].cuda()else:index = positiveself.weight_index = indexlabels[index_positive] = torch.searchsorted(index, labels[index_positive])return self.weight[self.weight_index]隨后,使用選出的樣本中心去與特征相乘并計算基于margin的softmax損失。
PFC在DDP框架下的流程圖如下圖所示,
整體代碼如下,
class PartialFC_V2(torch.nn.Module):"""https://arxiv.org/abs/2203.15565A distributed sparsely updating variant of the FC layer, named Partial FC (PFC).When sample rate less than 1, in each iteration, positive class centers and a random subset ofnegative class centers are selected to compute the margin-based softmax loss, all classcenters are still maintained throughout the whole training process, but only a subset isselected and updated in each iteration... note::When sample rate equal to 1, Partial FC is equal to model parallelism(default sample rate is 1).Example:-------->>> module_pfc = PartialFC(embedding_size=512, num_classes=8000000, sample_rate=0.2)>>> for img, labels in data_loader:>>> embeddings = net(img)>>> loss = module_pfc(embeddings, labels)>>> loss.backward()>>> optimizer.step()"""_version = 2def __init__(self,margin_loss: Callable,embedding_size: int,num_classes: int,sample_rate: float = 1.0,fp16: bool = False,):"""Paramenters:-----------embedding_size: intThe dimension of embedding, requirednum_classes: intTotal number of classes, requiredsample_rate: floatThe rate of negative centers participating in the calculation, default is 1.0."""super(PartialFC_V2, self).__init__()assert (distributed.is_initialized()), "must initialize distributed before create this"self.rank = distributed.get_rank()self.world_size = distributed.get_world_size()self.dist_cross_entropy = DistCrossEntropy()self.embedding_size = embedding_sizeself.sample_rate: float = sample_rateself.fp16 = fp16self.num_local: int = num_classes // self.world_size + int(self.rank < num_classes % self.world_size)self.class_start: int = num_classes // self.world_size * self.rank + min(self.rank, num_classes % self.world_size)self.num_sample: int = int(self.sample_rate * self.num_local)self.last_batch_size: int = 0self.is_updated: bool = Trueself.init_weight_update: bool = Trueself.weight = torch.nn.Parameter(torch.normal(0, 0.01, (self.num_local, embedding_size)))# margin_lossif isinstance(margin_loss, Callable):self.margin_softmax = margin_losselse:raisedef sample(self, labels, index_positive):"""This functions will change the value of labelsParameters:-----------labels: torch.Tensorpassindex_positive: torch.Tensorpassoptimizer: torch.optim.Optimizerpass"""with torch.no_grad():positive = torch.unique(labels[index_positive], sorted=True).cuda()if self.num_sample - positive.size(0) >= 0:perm = torch.rand(size=[self.num_local]).cuda()perm[positive] = 2.0index = torch.topk(perm, k=self.num_sample)[1].cuda()index = index.sort()[0].cuda()else:index = positiveself.weight_index = indexlabels[index_positive] = torch.searchsorted(index, labels[index_positive])return self.weight[self.weight_index]def forward(self,local_embeddings: torch.Tensor,local_labels: torch.Tensor,):"""Parameters:----------local_embeddings: torch.Tensorfeature embeddings on each GPU(Rank).local_labels: torch.Tensorlabels on each GPU(Rank).Returns:-------loss: torch.Tensorpass"""local_labels.squeeze_()local_labels = local_labels.long()batch_size = local_embeddings.size(0)if self.last_batch_size == 0:self.last_batch_size = batch_sizeassert self.last_batch_size == batch_size, (f"last batch size do not equal current batch size: {self.last_batch_size} vs {batch_size}")_gather_embeddings = [torch.zeros((batch_size, self.embedding_size)).cuda()for _ in range(self.world_size)]_gather_labels = [torch.zeros(batch_size).long().cuda() for _ in range(self.world_size)]_list_embeddings = AllGather(local_embeddings, *_gather_embeddings)distributed.all_gather(_gather_labels, local_labels)embeddings = torch.cat(_list_embeddings)labels = torch.cat(_gather_labels)## 選出落在本進程對應的類別范圍內的數據labels = labels.view(-1, 1)index_positive = (self.class_start <= labels) & (labels < self.class_start + self.num_local)## 標簽不在本類別段的, 將其類別標簽設為-1labels[~index_positive] = -1## 將類別ID平移到原點(因為不同進程都會初始化對應的self.weight, 若不平移回去, 則label與self.weight中的index會對應不上)labels[index_positive] -= self.class_startif self.sample_rate < 1:weight = self.sample(labels, index_positive)else:weight = self.weightwith torch.cuda.amp.autocast(self.fp16):norm_embeddings = normalize(embeddings)norm_weight_activated = normalize(weight)logits = linear(norm_embeddings, norm_weight_activated)if self.fp16:logits = logits.float()logits = logits.clamp(-1, 1)logits = self.margin_softmax(logits, labels)loss = self.dist_cross_entropy(logits, labels)return loss實驗結果
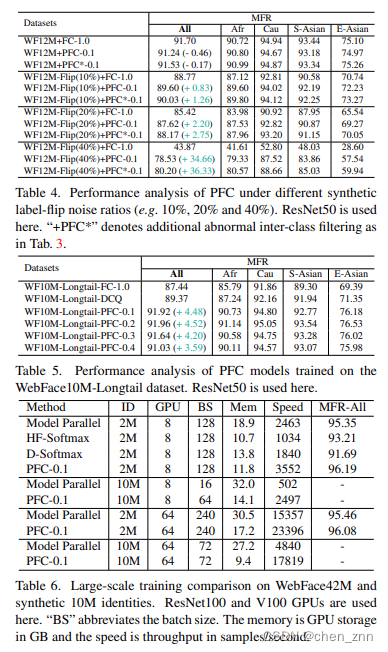
將PFC替換掉傳統FC后,模型在WebFace(包括4m、12m、42m)上的性能會有所提升,
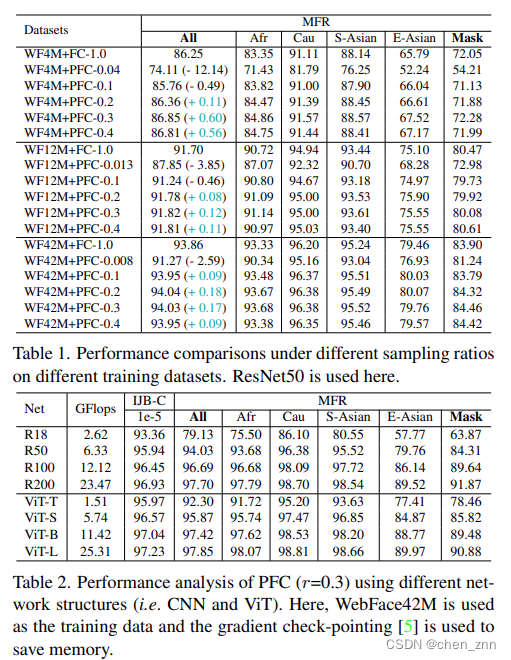

?消融實驗的結果如下,
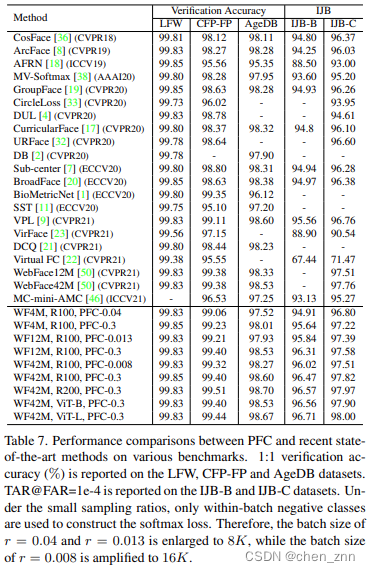
與SOTA方法的性能對比如下,?
結論與討論
結論
作者提出了一種用于在大規模數據集上訓練人臉識別模型的方法——Partial FC (PFC)。在PFC的每次迭代中,僅選擇一小部分類別中心來計算基于邊際的softmax損失,這樣可以顯著減少類間沖突的概率、尾類中心的被動更新頻率以及計算需求。通過廣泛的實驗,作者驗證了所提出的PFC的有效性、魯棒性和高效性。
局限性
盡管在WebFace上訓練的PFC模型在高質量測試集上取得了不錯的結果,但在人臉分辨率較低或低光照條件下拍攝的人臉上,PFC模型的表現可能較差。





)


)

2)

)






