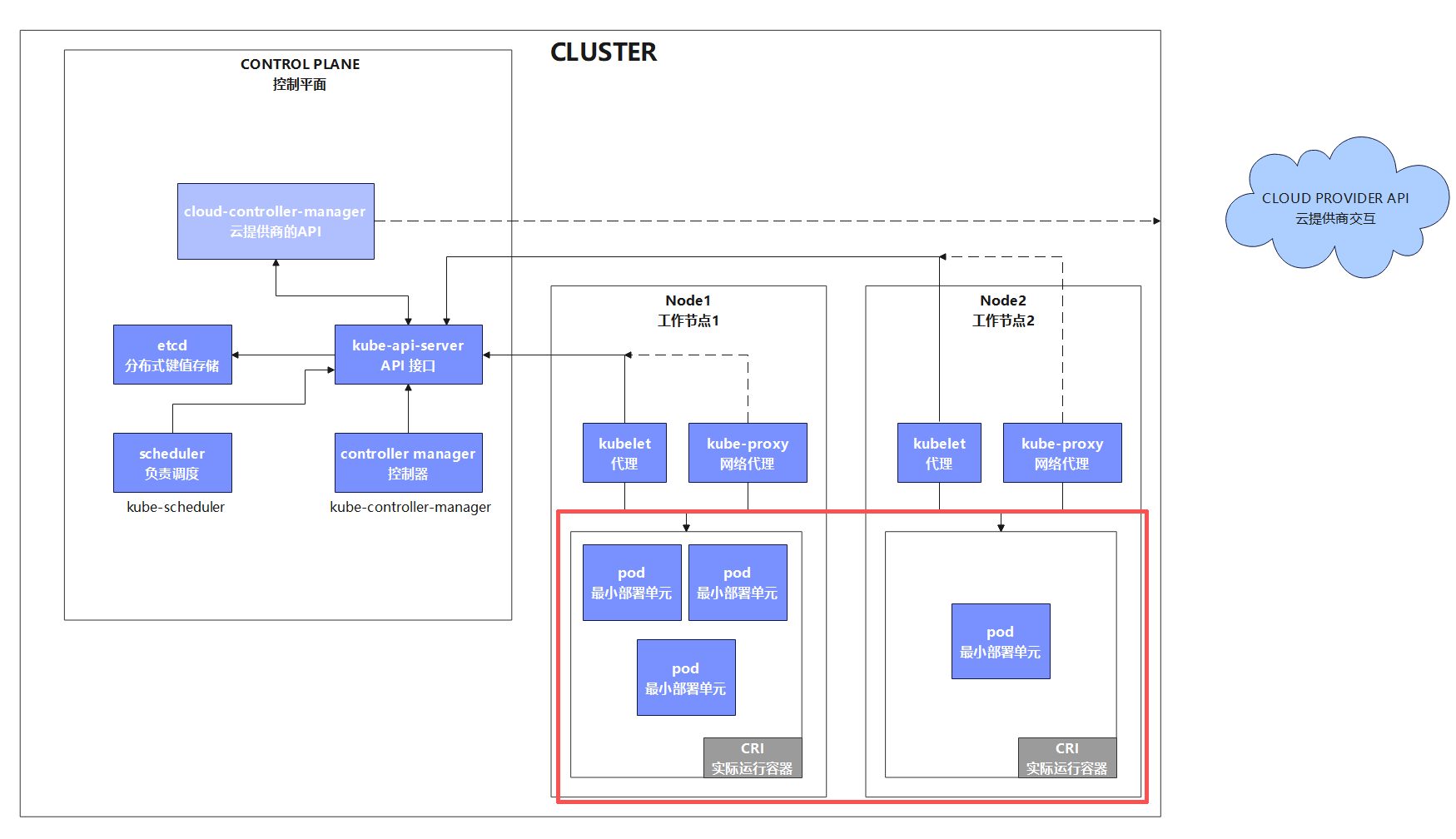
1 K8s核心資源Pod
1.1 Pod是什么?
官方文檔:Pod | Kubernetes
Pod 是 Kubernetes(k8s)中最小的部署與調度單元,并非直接運行容器,而是對一個或多個 “緊密關聯” 容器的封裝。
核心特點可簡單總結為 3 點:
- 容器的 “組合包”:通常包含 1 個主容器(業務核心,如 Web 服務),也可包含輔助容器(如日志收集、監控代理),所有容器共享 Pod 的資源。
- 共享基礎環境:同一 Pod 內的容器共享網絡命名空間(用
localhost就能互相通信,無需跨網絡)和存儲卷(可共用文件目錄),相當于 “在同一臺迷你主機上運行”。 - 短暫且被管理:Pod 本身是 “一次性” 的(故障、重啟后會生成新 Pod,IP 會變),不會自行修復,需依賴 k8s 的控制器(如 Deployment、StatefulSet)來管理其創建、擴縮容和故障恢復。
白話解釋:
? ? 可以把 pod 看成是一個“豌豆莢”,里面有很多“豆子”(容器)。一個豌豆莢里的豆子,它們吸收著 共同的營養成分、肥料、水分等,Pod 和容器的關系也是一樣,Pod 里面的容器共享 pod 的網絡、存儲等。
1.1.1 Pod如何管理多個容器
在 Kubernetes 中,Pod 管理多個容器的核心邏輯是 “協同調度、資源共享、生命周期綁定”,具體通過以下方式實現:
-
共享基礎環境
同一 Pod 內的所有容器共享網絡命名空間(相同的 IP 地址、端口空間)和存儲卷(Volume):- 網絡:容器間可通過
localhost直接通信(如localhost:8080訪問同一 Pod 內的另一個容器),但需注意端口不沖突;對外表現為一個整體,共享 Pod 的 IP。 - 存儲:Pod 中定義的 Volume(如臨時目錄
emptyDir、持久化存儲PersistentVolume)可被所有容器掛載,實現數據共享(如日志容器讀取主容器產生的日志文件)。
- 網絡:容器間可通過
-
生命周期綁定
多個容器的生命周期與 Pod 強綁定:- 同時調度:Pod 被調度到某個節點后,其內所有容器會在同一節點啟動。
- 整體管理:Pod 刪除時,所有容器同時終止;Pod 重啟(如節點故障重建)時,所有容器重新創建。
- 重啟策略統一:Pod 通過
restartPolicy(如Always、OnFailure)定義容器故障時的重啟規則,適用于所有容器。
-
啟動與依賴控制
若容器間有啟動順序或依賴關系,可通過以下機制控制:- Init 容器:在應用容器啟動前運行的 “初始化容器”,完成前置任務(如配置加載、依賴檢查),所有 Init 容器成功退出后,應用容器才會啟動。
- 探針(Probe):通過
livenessProbe(存活探針)、readinessProbe(就緒探針)檢測容器狀態,確保容器按預期運行后再對外提供服務。
-
資源隔離與分配
每個容器可單獨設置資源請求(resources.requests)和限制(resources.limits),Pod 會匯總這些需求向 Kubernetes 申請資源,確保容器間資源使用不沖突(如避免某容器耗盡內存影響其他容器)。
1.1.2?Pod網絡
Pod 網絡核心可總結為:
- 每個 Pod 有唯一集群內 IP,作為其網絡身份;
- 同一 Pod 內容器共享網絡命名空間,通過
localhost直接通信; - 集群內 Pod 間可直接用 IP 互通(無 NAT),依賴 CNI 插件實現跨節點通信;
- Pod 訪問外部靠節點 SNAT,外部訪問 Pod 需通過 Service 作為穩定入口。
1.1.3?Pod存儲
創建 Pod 的時候可以指定掛載的存儲卷。 POD 中的所有容器都可以訪問共享卷,允許這些容器共享數據。 Pod 只要掛載持久化數據卷,Pod 重啟之后數據還是會存在的。
1.2 Pod工作方式
在 K8s 中,所有的資源都可以使用一個 yaml 文件來創建,創建 Pod 也可以使用 yaml 配置文件。或者使用 kubectl run 在命令行創建 Pod。
1.2.1 自主式 Pod
所謂的自主式 Pod,就是直接定義一個 Pod 資源,如下:
apiVersion: v1
kind: Pod
metadata:name: nginx-testnamespace: defaultlabels:app: nginx
spec:containers:- name: nginxports:- containerPort: 80image: nginximagePullPolicy: IfNotPresent# 更新資源清單
kubectl apply -f pod-nginx.yaml# 查看pod是否創建成功
kubectl get pods -o wide -l app=nginx自主式Pod存在一個問題,加入不小心刪除了Pod,那么就徹底被刪除了,不會再創建一個新的Pod,這如果在生產環境中有非常大的風險,用控制器管理最好。
kubectl delete pods nginx-testkubectl get pods -l app=nginx
#結果為空說明pod已經被刪除了1.2.2 控制器管理的Pod
常見的管理 Pod 的控制器:Replicaset、Deployment、Job、CronJob、Daemonset、Statefulset。 控制器管理的 Pod 可以確保 Pod 始終維持在指定的副本數運行。 如,通過 Deployment 管理 Pod
vim nginx-deploy.yamlapiVersion: v1
kind: Deployment
metadata:name: nginx-testlabels:app: nginx-deploy
spec:selector:matchLabels:app: nginxreplicas: 2 # 副本數為2template:metadata:labels:app: nginx
spec:containers:- name: my-nginximage: nginximagePullPolicy: IfNotPresentports:- containerPort: 80# 更新資源清單文件
kubectl apply -f nginx-deploy.yaml# 查看Deployment
kubectl get deploy -l app=nginx-deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-test 2/2 2 2 16s#查看 Replicaset
kubectl get rs -l app=nginx
NAME DESIRED CURRENT READY AGE
nginx-test-75c685fdb7 2 2 2 71s#查看 pod
kubectl get pods -o wide -l app=nginx
NAME READY STATUS IP
nginx-test-85c885fdb7-6d4lx 1/1 Running 10.190.102.69
nginx-test-85c885fdb7-9s95h 1/1 Running 10.190.102.68#刪除nginx-test-85c885fdb7-9s95h這個 podkubectl delete pods nginx-test-85c885fdb7-9s95h
kubectl get pods -o wide -l app=nginxNAME READY STATUS IP
nginx-test-85c885fdb7-6d4lx 1/1 Running 10.190.102.69
nginx-test-85c885fdb7-6s95h 1/1 Running 10.190.102.68# 發現重新創建了一個新的pod nginx-test-85c885fdb7-6s95h
通過上面可以發現通過 deployment 管理的 pod,可以確保 pod 始終維持在指定副本數量.
2 命名空間(namespace)
2.1 什么是命名空間?
在 Kubernetes 中,命名空間(Namespace)是用于對集群內資源進行邏輯隔離的機制,核心作用是在共享同一 K8s 集群的場景下,避免資源名稱沖突、區分環境或團隊,方便管理和權限控制。
核心特點:
-
資源隔離:同一命名空間內的資源名稱必須唯一,但不同命名空間可以有同名資源(如兩個命名空間都能有叫 “nginx” 的 Pod)。
-
環境 / 團隊劃分:通常用于隔離不同環境(如
dev開發、test測試、prod生產)或不同團隊的資源,避免互相干擾。 -
權限控制:可通過 RBAC(基于角色的訪問控制)為不同命名空間設置獨立的權限規則(如只允許某團隊操作
dev命名空間)。
常見默認命名空間:
-
default:未指定命名空間時,資源默認創建于此。 -
kube-system:K8s 系統組件(如 kube-proxy、調度器)所在的命名空間。 -
kube-public:所有用戶可見的公共資源(通常用于存儲集群信息)。
簡單說,命名空間就像集群內的 “虛擬分區”,讓多場景共享集群時更有序。
2.2 namespace 應用場景
-
環境隔離:區分 dev(開發)、test(測試)、prod(生產)環境,避免相互干擾;
-
團隊 / 項目隔離:為多團隊 / 項目劃分 “資源池”,防止資源名沖突與誤操作;
-
資源配額控制:結合 ResourceQuota,限制各場景 / 團隊的 CPU、內存等資源上限;
-
權限精細化控制:結合 RBAC,讓不同角色僅能操作指定 Namespace 的資源,保障安全;
-
臨時場景隔離:為實驗、POC 等臨時需求創建 Namespace,用完一鍵刪除,清理高效。
核心是通過邏輯隔離,實現集群資源的有序管理與安全共享。
2.3 namespace 使用案例
# 創建一個命名空間
kubectl create ns test# 切換命名空間
kubectl config set-context --current --namespace=kube-system
# 切換了命名空間后,kubectl get pods 如果不指定-n,查看的就是kube-system命名空間的資源# 查看哪些資源屬于命名空間級別的
kubectl api-resources --namespaced=true
2.4 namespace資源限額
kubectl config set-context --current -namespace=default# namespace 是命名空間,里面有很多資源,那么我們可以對命名空間資源做個限制,防止該命名空間
部署的資源超過限制。vim namespace-quota.yamlapiVersion: v1
kind: ResourceQuota
metadata: name: mem-cpu-quota namespace: test
spec: hard: requests.cpu: "2" requests.memory: 2Gi limits.cpu: "4" limits.memory: 4Gi#創建的 ResourceQuota 對象將在 test 名字空間中添加以下限制:
每個容器必須設置內存請求(memory request),內存限額(memory limit),cpu 請求(cpu
request)和 cpu 限額(cpu limit)。
所有容器的內存請求總額不得超過 2GiB。
所有容器的內存限額總額不得超過 4 GiB。
所有容器的 CPU 請求總額不得超過 2 CPU。
所有容器的 CPU 限額總額不得超過 4CPU。
3 標簽(Label)
3.1 什么是標簽
標簽是附加在對象(如 Pod、Node 等)上的鍵值對,用于標識、分類對象,可動態添加或修改。核心作用是通過標簽選擇器篩選、關聯對象(如 Service 關聯 Pod、Deployment 管理 Pod 等),是 K8s 中對象管理和關聯的基礎機制。
3.2 給pod資源打標簽
給 Pod 打標簽有兩種方式:創建時指定標簽,或為已存在的 Pod 添加 / 修改標簽。
1. 創建 Pod 時指定標簽(推薦)
apiVersion: v1
kind: Pod
metadata:name: my-podlabels: # 這里定義標簽app: nginxenv: productionversion: v1
spec:containers:- name: nginximage: nginx:latest創建 Pod:kubectl apply -f pod.yaml
2. 為已存在的 Pod 添加 / 修改標簽
使用?kubectl label?命令:
# 給名為my-pod的Pod添加標簽(如添加"team=backend")
kubectl label pods my-pod team=backend# 若標簽已存在,需加--overwrite強制修改
kubectl label pods my-pod env=test --overwrite
3. 驗證標簽
# 查看Pod的標簽
kubectl get pod my-pod --show-labels# 篩選帶有特定標簽的Pod(如app=nginx)
kubectl get pods -l app=nginx
標簽可用于篩選 Pod、關聯 Service/Deployment 等,是 K8s 對象管理的重要工具。
3.3 查看資源標簽
在 Kubernetes 中,查看資源標簽的常用方式是通過?kubectl?命令,支持查看單個資源、所有資源的標簽,或篩選帶有特定標簽的資源。
1. 查看資源的所有標簽(最常用)
使用?--show-labels?選項,可顯示指定資源的所有標簽:
# 查看所有 Pod 的標簽
kubectl get pods --show-labels# 查看單個Pod的標簽
kubectl get pods nginx-pod --show-labels# 查看所有 Node(節點) 的標簽
kubectl get nodes --show-labels# 查看所有 Deployment 的標簽
kubectl get deployment --show-labels2. 篩選帶有特定標簽的資源
使用?-l?選項,可按標簽篩選資源(支持?=、!=?等條件):
# 查看標簽為 app=nginx 的所有Pod
kubectl get pods -l app=nginx# 查看標簽為 env!=production 的所有Pod
kubectl get pods -l env!=production# 查看同時帶有 app=nginx和version=v1的所有Pod
kubectl get pods -l app=nginx,version=v13. 查看資源的詳細標簽信息
使用?describe?命令,可在資源詳情的?Metadata.Labels?部分查看標簽:
# 查看某個 Pod的詳細信息(包含標簽)
kubectl describe pod my-pod# 查看某個 Node 的詳細信息(包含標簽)
kubectl describe node node1通過以上命令,可快速查看、篩選 Kubernetes 各類資源的標簽,方便進行資源管理和關聯操作。
4 Pod資源清單詳細解讀
Pod 資源清單(YAML/JSON 格式)是定義 Kubernetes Pod 運行規范的核心配置文件,包含了 Pod 的元數據、運行容器、資源需求、網絡、存儲等關鍵信息。以下是對 Pod 資源清單主要字段的詳細解讀(以 YAML 為例):
基礎結構框架
一個完整的 Pod 清單通常包含 4 個頂級字段(缺一不可):
apiVersion: v1 # API 版本
kind: Pod # 資源類型
metadata: # 元數據(標識信息)...
spec: # 規格(核心配置,定義 Pod 如何運行)...4.1 頂級字段
-
apiVersion: v1
指定 Kubernetes API 版本。Pod 是核心資源,穩定版本為?v1(其他資源可能有不同版本,如?apps/v1)。 -
kind: Pod
聲明資源類型為 Pod(Kubernetes 中還有 Deployment、Service 等其他類型)。
4.2?metadata:元數據(標識與屬性)
用于唯一標識 Pod 并附加額外信息,常見字段:
metadata:name: my-pod # Pod 名稱(必填,在命名空間內唯一,只能包含字母、數字、-、_、.)namespace: default # 所屬命名空間(默認是 default,用于資源隔離,可選)labels: # 標簽(鍵值對,用于篩選和關聯其他資源,如 Service/Deployment)app: nginxenv: productionannotations: # 注解(鍵值對,用于存儲非標識性元數據,如運維備注、工具配置)description: "This is a nginx pod"managed-by: "kubectl"uid: "xxxx-xxxx-xxxx" # 自動生成的唯一 ID(創建后由 K8s 分配,無需手動設置)4.3?spec:核心規格(定義 Pod 運行規則)
這是 Pod 配置的核心,包含容器、資源、網絡、存儲等關鍵信息。
4.3.1?容器配置(spec.containers)
Pod 由一個或多個容器組成,containers?是必填列表,每個容器的配置如下:
spec:containers:- name: nginx-container # 容器名稱(在 Pod 內唯一,必填)image: nginx:1.23 # 容器鏡像(必填,格式:倉庫地址/鏡像名:標簽,默認拉取 latest)imagePullPolicy: IfNotPresent # 鏡像拉取策略(可選,默認 IfNotPresent)# - Always:每次都拉取鏡像;# - IfNotPresent:本地有則用本地,否則拉取;# - Never:只使用本地鏡像,不拉取ports: # 容器端口配置(可選,用于聲明端口,不直接暴露到集群)- containerPort: 80 # 容器內監聽的端口(必填,僅用于標識)hostPort: 8080 # 主機映射端口(可選,不推薦,可能導致端口沖突)protocol: TCP # 協議(默認 TCP,可選 UDP/SCTP)name: http # 端口名稱(可選,用于區分多個端口)command: ["/bin/sh"] # 容器啟動命令(可選,覆蓋鏡像默認命令)args: ["-c", "echo hello"] # 啟動命令參數(可選,配合 command 使用)env: # 環境變量(可選,注入容器內的環境變量)- name: APP_ENV # 環境變量名稱value: "production" # 直接設值- name: DB_PASSWORD # 從 Secret 中獲取值(更安全)valueFrom:secretKeyRef:name: db-secret # Secret 名稱key: password # Secret 中的鍵resources: # 資源需求與限制(可選,影響調度和資源分配)requests: # 申請的最小資源(調度時參考,確保節點有足夠資源)cpu: "100m" # 100m = 0.1 CPU 核心memory: "128Mi" # 128 兆內存limits: # 資源上限(容器不能超過此限制,否則可能被終止)cpu: "500m"memory: "256Mi"volumeMounts: # 掛載存儲卷(可選,將 spec.volumes 定義的存儲掛載到容器內)- name: data-volume # 要掛載的卷名稱(需與 spec.volumes 中名稱一致)mountPath: /usr/share/nginx/html # 容器內掛載路徑readOnly: false # 是否只讀(默認 false)livenessProbe: # 存活探針(可選,檢測容器是否"存活",失敗則重啟容器)httpGet:path: / # 探測路徑port: 80 # 探測端口initialDelaySeconds: 5 # 容器啟動后延遲多久開始探測(秒)periodSeconds: 10 # 探測間隔(秒,默認 10)readinessProbe: # 就緒探針(可選,檢測容器是否"就緒",失敗則從 Service 移除)httpGet:path: /readyport: 80initialDelaySeconds: 3periodSeconds: 5securityContext: # 容器級安全上下文(可選,如運行用戶、權限)runAsUser: 1000 # 容器內進程的 UIDrunAsGroup: 3000 # 容器內進程的 GIDallowPrivilegeEscalation: false # 是否允許提權(默認 true)4.3.2 初始化容器(spec.initContainers)
在應用容器(containers)啟動前運行的容器,用于初始化工作(如拉取配置、等待依賴),執行完后退出(必須成功退出,否則 Pod 卡在?Init?狀態)。配置格式與?containers?一致:
spec:initContainers:- name: init-configimage: busybox:1.35command: ["wget", "-O", "/config/index.html", "http://config-server/index"]volumeMounts:- name: data-volumemountPath: /config4.3.3 存儲卷(spec.volumes)
定義 Pod 可使用的存儲卷(供容器掛載),支持多種類型(如臨時存儲、主機路徑、配置文件等):
spec:volumes:- name: data-volume # 卷名稱(供 volumeMounts 引用)emptyDir: {} # 臨時存儲(Pod 生命周期內存在,刪除后數據丟失)- name: host-path-volumehostPath: # 主機路徑(掛載節點上的文件/目錄,不推薦生產環境)path: /var/logtype: Directory- name: config-volumeconfigMap: # 掛載 ConfigMap(配置文件)name: nginx-config # ConfigMap 名稱- name: secret-volumesecret: # 掛載 Secret(敏感信息,如密碼)secretName: db-credentialsPod 資源清單通過?metadata?定義標識信息,通過?spec?詳細配置容器運行規則(包括鏡像、資源、網絡、存儲、調度策略等)。理解這些字段是編寫、調試 Pod 配置的基礎,也是使用 Kubernetes 部署應用的核心技能。
4.3.4 調度與節點選擇
控制 Pod 被調度到哪個節點:
spec:nodeSelector: # 節點選擇器(簡單匹配,僅支持等于)disk: ssd # 調度到帶有 label "disk=ssd" 的節點affinity: # 親和性規則(更靈活的調度策略)nodeAffinity: # 節點親和性(傾向/必須調度到滿足條件的節點)requiredDuringSchedulingIgnoredDuringExecution: # 硬親和性(必須滿足)nodeSelectorTerms:- matchExpressions:- key: envoperator: Invalues: [production]preferredDuringSchedulingIgnoredDuringExecution: # 軟親和性(優先滿足)- weight: 100preference:matchExpressions:- key: zoneoperator: Invalues: [zone-1]podAntiAffinity: # Pod 反親和性(避免與特定 Pod 調度到同一節點)preferredDuringSchedulingIgnoredDuringExecution:- weight: 100podAffinityTerm:labelSelector:matchExpressions:- key: appoperator: Invalues: [database]topologyKey: "kubernetes.io/hostname" # 按節點隔離tolerations: # 污點容忍(允許 Pod 調度到有特定污點的節點)- key: "node-type"operator: "Exists"effect: "NoSchedule"5 節點選擇器(nodeSelector)
在 Kubernetes 中,節點選擇器(nodeSelector)?是一種簡單的調度策略,用于將 Pod 限制在具有特定標簽的節點上運行。它通過匹配節點的標簽(Labels)來實現 Pod 與節點的綁定,是最基礎的節點調度方式。
核心作用
讓 Pod 只能被調度到擁有指定標簽的節點上,確保 Pod 運行在符合預期的節點(如特定硬件、環境或功能的節點)。
5.1 為節點添加標簽
首先需要給目標節點打上特定標簽(若已有標簽可跳過):
# 語法:kubectl label nodes <節點名稱> <標簽鍵>=<標簽值>
kubectl label nodes node-1 env=production # 給節點 node-1 打標簽 env=production
kubectl label nodes node-2 hardware=gpu # 給節點 node-2 打標簽 hardware=gpu驗證節點標簽:
kubectl get nodes --show-labels # 查看所有節點的標簽
kubectl describe node node-1 | grep Labels # 查看單個節點的標簽5.2 在 Pod 中配置 nodeSelector
在 Pod 的資源清單中,通過?spec.nodeSelector?字段指定需要匹配的節點標簽,Pod 會被調度到所有標簽完全匹配的節點上。
apiVersion: v1
kind: Pod
metadata:name: my-pod
spec:containers:- name: nginximage: nginx:latestnodeSelector: # 節點選擇器:僅調度到同時滿足以下標簽的節點env: production # 匹配標簽 env=productionhardware: gpu # 匹配標簽 hardware=gpu# 查看pod調度到哪個節點
kubectl get pods -o wideNAME READY STATUS RESTARTS
my-pod 1/1 Running 0 node2創建 Pod 后,Kubernetes 調度器會自動將其分配到符合標簽條件的節點。
特點與限制
- 優點:簡單直觀,適合基礎的節點篩選場景。
- 限制:
- 僅支持精確匹配(標簽鍵和值必須完全一致),不支持?
!=、In、NotIn?等復雜邏輯。 - 是 “硬性要求”:如果沒有匹配標簽的節點,Pod 會一直處于?
Pending?狀態(調度失敗)。
- 僅支持精確匹配(標簽鍵和值必須完全一致),不支持?
適用場景
- 將 Pod 調度到特定環境的節點(如?
env=production?或?env=test)。 - 將需要特殊硬件的 Pod 調度到對應節點(如?
hardware=gpu?或?disk=ssd)。
如果需要更靈活的調度策略(如 “優先調度到某類節點”“避免調度到某類節點” 等),可以使用?節點親和性(Node Affinity)?替代 nodeSelector。
6 污點和容忍度
6.1 node 節點親和性(Node Affinity)
在 Kubernetes 中,節點親和性(Node Affinity)?是一種比?nodeSelector?更靈活的 Pod 調度策略,用于根據節點的標簽(Labels)控制 Pod 被調度到哪些節點上。它支持更復雜的匹配邏輯(如 “包含”“不包含”“存在” 等),并分為 “硬性要求” 和 “軟性偏好” 兩種類型,滿足不同調度場景的需求。
核心作用
讓 Pod 按照自定義規則 “主動選擇” 合適的節點(基于節點標簽),既可以強制要求必須滿足某些條件,也可以優先選擇符合條件的節點(不強制)。
節點親和性的兩種類型
節點親和性通過?spec.affinity.nodeAffinity?配置,分為以下兩種:
| 類型 | 關鍵字 | 含義 | 特點 |
|---|---|---|---|
| 硬親和性 | requiredDuringSchedulingIgnoredDuringExecution | 必須滿足的條件,否則 Pod 無法調度(一直處于 Pending 狀態) | 強制約束,類似 “我必須吃飯,不吃飯就會餓” |
| 軟親和性 | preferredDuringSchedulingIgnoredDuringExecution | 優先滿足的條件,不滿足也可以調度到其他節點 | 柔性偏好,類似 “最好是現在吃飯,晚一點吃也沒事” |
匹配表達式(Operator)
節點親和性通過?matchExpressions?定義匹配規則,支持多種操作符(比?nodeSelector?更靈活):
| 操作符 | 含義 | 示例 |
|---|---|---|
In | 節點標簽的值必須在指定列表中 | key: "env",?values: ["prod", "test"]?→ 匹配?env=prod?或?env=test |
NotIn | 節點標簽的值必須不在指定列表中 | key: "env",?values: ["dev"]?→ 不匹配?env=dev |
Exists | 節點必須存在指定標簽(不校驗值) | key: "gpu"?→ 只要節點有?gpu?標簽(無論值是什么) |
DoesNotExist | 節點必須不存在指定標簽 | key: "disk"?→ 節點不能有?disk?標簽 |
Gt | 節點標簽的值(數字)必須大于指定值 | key: "cpu-cores",?values: ["4"]?→ 匹配?cpu-cores>4 |
Lt | 節點標簽的值(數字)必須小于指定值 | key: "memory-gb",?values: ["32"]?→ 匹配?memory-gb<32 |
配置示例
假設需要將 Pod 調度到 “生產環境(env=prod)的節點,且優先選擇 SSD 磁盤(disk=ssd)的節點”,配置如下:
apiVersion: v1
kind: Pod
metadata:name: affinity-pod
spec:containers:- name: nginximage: nginx:latestaffinity: # 親和性配置nodeAffinity:# 硬親和性:必須滿足的條件requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms: # 多個條件組(滿足任意一組即可)- matchExpressions: # 條件組內的多個表達式(需同時滿足)- key: envoperator: Invalues: ["prod"] # 節點必須有 env=prod 標簽# 軟親和性:優先滿足的條件preferredDuringSchedulingIgnoredDuringExecution:- weight: 100 # 權重(0-100,數值越大優先級越高)preference:matchExpressions:- key: diskoperator: Invalues: ["ssd"] # 優先選擇 disk=ssd 的節點
- 硬親和性確保 Pod 只能調度到?
env=prod?的節點(不滿足則無法調度); - 軟親和性讓調度器在滿足硬親和性的節點中,優先選擇?
disk=ssd?的節點(若無則選擇其他?env=prod?節點)。
與其他調度策略的區別
| 策略 | 特點 | 適用場景 |
|---|---|---|
nodeSelector | 僅支持精確匹配(key=value) | 簡單的標簽匹配場景 |
| 節點親和性 | 支持復雜匹配(In/Exists?等),分硬 / 軟親和性 | 需靈活條件的調度(如 “必須在生產環境,優先用 SSD”) |
| 污點(Taints)+ 容忍度(Tolerations) | 節點主動排斥 Pod,Pod 需 “容忍” 才能被調度 | 節點隔離(如 “GPU 節點只允許 AI 任務調度”) |
典型使用場景
- 環境隔離:強制 Pod 只能在?
env=prod?節點運行(硬親和性)。 - 資源偏好:優先將計算密集型 Pod 調度到?
cpu=high?的節點(軟親和性)。 - 硬件依賴:必須將需要 GPU 的 Pod 調度到?
gpu=true?的節點(硬親和性)。
節點親和性通過靈活的匹配規則和軟硬約束,讓 Pod 調度更符合實際業務需求,是 Kubernetes 中控制節點選擇的核心機制之一。
6.2 Pod節點親和性(Pod Affinity)
在 Kubernetes 中,Pod 親和性(Pod Affinity)?是一種基于已運行 Pod 的標簽來調度新 Pod 的策略。它用于控制新 Pod 與集群中已存在的 Pod 之間的 “位置關系”—— 即新 Pod 應該和哪些 Pod 調度到同一位置(親和),或應該遠離哪些 Pod(反親和)。
與 “節點親和性(Node Affinity)” 基于節點標簽調度不同,Pod 親和性基于其他 Pod 的標簽調度,更適合控制服務之間的關聯關系(如 “前端 Pod 和后端 Pod 盡量在同一節點”“數據庫 Pod 盡量分散在不同節點”)。
核心概念
- Pod 親和性(Pod Affinity):新 Pod 傾向于與 “具有特定標簽的已有 Pod” 調度到同一拓撲域(如同一節點、同一機房等)。
- Pod 反親和性(Pod Anti-Affinity):新 Pod 傾向于與 “具有特定標簽的已有 Pod” 調度到不同拓撲域,避免集中部署。
拓撲域(Topology Domain):通過?topologyKey?定義,通常是節點的標簽(如?kubernetes.io/hostname?表示 “同一節點”,topology.kubernetes.io/zone?表示 “同一可用區”),用于劃分 “位置范圍”。
類型與配置
Pod 親和性 / 反親和性也分為 “硬性要求” 和 “軟性偏好” 兩種類型,配置位于?spec.affinity.podAffinity?或?spec.affinity.podAntiAffinity?字段:
| 類型 | 關鍵字 | 含義 |
|---|---|---|
| 硬約束 | requiredDuringSchedulingIgnoredDuringExecution | 必須滿足條件,否則 Pod 無法調度 |
| 軟約束 | preferredDuringSchedulingIgnoredDuringExecution | 優先滿足條件,不滿足也可調度到其他位置 |
匹配規則
通過?labelSelector?匹配目標 Pod 的標簽,語法與節點親和性類似,支持?In/NotIn/Exists?等操作符。
配置示例
1. Pod 親和性(讓新 Pod 與目標 Pod 在同一節點)
需求:新的?frontend?Pod 盡量與已有的?app=backend?Pod 調度到同一節點(降低網絡延遲)。
apiVersion: v1
kind: Pod
metadata:name: frontend-podlabels:app: frontend
spec:containers:- name: frontendimage: nginx:latestaffinity:podAffinity: # Pod 親和性配置preferredDuringSchedulingIgnoredDuringExecution: # 軟約束(優先滿足)- weight: 80 # 權重(0-100)podAffinityTerm:labelSelector:matchExpressions:- key: appoperator: Invalues: ["backend"] # 匹配標簽為 app=backend 的已有 PodtopologyKey: "kubernetes.io/hostname" # 拓撲域:同一節點(按主機名劃分)
2. Pod 反親和性(讓新 Pod 與目標 Pod 不在同一節點)
需求:新的?db?Pod 必須與其他?app=db?Pod 調度到不同節點(避免單點故障)。
apiVersion: v1
kind: Pod
metadata:name: db-pod-2labels:app: db
spec:containers:- name: dbimage: mysql:5.7affinity:podAntiAffinity: # Pod 反親和性配置requiredDuringSchedulingIgnoredDuringExecution: # 硬約束(必須滿足)- labelSelector:matchExpressions:- key: appoperator: Invalues: ["db"] # 匹配標簽為 app=db 的已有 PodtopologyKey: "kubernetes.io/hostname" # 拓撲域:不同節點(按主機名劃分)
- 若集群中已有?
app=db?的 Pod 運行在節點 A,新的?db-pod-2?會被調度到節點 B、C 等(不會再到節點 A)。 - 若所有節點都已有?
app=db?的 Pod,新 Pod 會因不滿足硬約束而處于?Pending?狀態。
關鍵參數:topologyKey
topologyKey?是節點的標簽鍵,用于定義 “同一位置” 的范圍,常見取值:
kubernetes.io/hostname:同一節點(最常用)。topology.kubernetes.io/zone:同一可用區。topology.kubernetes.io/region:同一地域。
例如,topologyKey: "topology.kubernetes.io/zone"?表示 “親和 / 反親和范圍是同一可用區”,而非同一節點。
適用場景
- 服務就近部署:前端與后端 Pod 用親和性調度到同一節點,減少網絡延遲。
- 高可用分散:數據庫、緩存等核心組件用反親和性分散到不同節點 / 可用區,避免單點故障。
- 資源隔離:不同團隊的 Pod 用反親和性調度到不同節點,避免資源競爭。
與節點親和性的區別
| 特性 | 節點親和性(Node Affinity) | Pod 親和性(Pod Affinity) |
|---|---|---|
| 依賴對象 | 節點的標簽 | 其他 Pod 的標簽 |
| 調度依據 | 節點本身的屬性(如硬件、環境) | 已有 Pod 的分布位置 |
| 核心作用 | 讓 Pod 選擇符合條件的節點 | 讓 Pod 與其他 Pod 保持特定位置關系 |
Pod 親和性通過關聯已有 Pod 的分布,實現更精細化的調度策略,是構建高可用、高性能集群的重要工具。
6.3 污點(Taints)
6.3.1 為什么需要污點?
假設有一個 Kubernetes 集群,里面有兩類節點:
-
普通節點:只有 CPU,供一般應用使用;
-
特殊節點:帶 GPU,專門給 AI 訓練任務用。
如果不做任何限制,普通應用的 Pod 可能會被調度到 GPU 節點上,導致 GPU 資源被浪費(普通應用用不到 GPU)。
這時候就需要一種機制:讓 GPU 節點 “主動拒絕” 普通 Pod,只允許 AI 任務的 Pod 進來。這種 “主動拒絕” 的規則,就是污點。
6.3.2 污點是什么?
污點是給節點(Node)?打上的 “排斥性標記”,格式是?key=value:effect,由三部分組成:
-
key:污點的名字(比如?dedicated、env); -
value:污點的具體值(比如?gpu、prod,可選,可空); -
effect:排斥的 “力度”,決定如何拒絕 Pod(核心!)。
重點:effect 的三種 “排斥力度”
| effect 類型 | 通俗解釋 | 例子場景 |
|---|---|---|
NoSchedule | 不準新 Pod 進來,但已經在節點上的 Pod 可以繼續運行。 | GPU 節點只允許新的 AI Pod 進來,老 Pod 不動 |
PreferNoSchedule | 盡量不讓新 Pod 進來(非強制),如果實在沒其他節點,也能進來。 | 某個節點性能較差,盡量不調度新 Pod,但不絕對禁止 |
NoExecute | 不準新 Pod 進來,且已經在節點上的舊 Pod 也會被趕走(如果舊 Pod 沒 “通行證”)。 | 節點要維護了,先把上面的 Pod 趕走,再禁止新 Pod 進來 |
6.3.3 怎么操作污點?
1. 給節點添加污點
語法:kubectl taint nodes <節點名> <key>=<value>:<effect>
比如給名為?node-gpu-1?的節點添加一個 “禁止普通 Pod 調度” 的污點:
kubectl taint nodes node-gpu-1 dedicated=gpu:NoSchedule
含義:節點?node-gpu-1?現在有一個污點?dedicated=gpu:NoSchedule,表示 “只允許能容忍這個污點的 Pod 調度進來”。
2. 查看節點的污點
想知道節點上有哪些污點,用?describe?命令:
kubectl describe node node-gpu-1 | grep Taints
如果看到?Taints: dedicated=gpu:NoSchedule,說明污點添加成功。
3. 刪除節點的污點
語法:在污點后面加一個?-,比如刪除上面添加的污點:
kubectl taint nodes node-gpu-1 dedicated=gpu:NoSchedule-
6.3.4 總結:污點的核心作用
污點是節點的 “主動防御機制”,通過?effect?控制對 Pod 的排斥力度:
-
NoSchedule:擋新 Pod,保舊 Pod; -
NoExecute:擋新 Pod,趕舊 Pod; -
PreferNoSchedule:盡量擋新 Pod,不絕對。
配合容忍度,就能實現 “節點專用化”“環境隔離”“節點維護” 等場景,讓集群資源調度更合理。
6.4 容忍度(Tolerations)
污點是節點的 “排斥規則”,但如果某個 Pod 確實需要用到這個節點(比如 AI 任務需要 GPU),就需要給 Pod 一個 “通行證”——容忍度(Tolerations)。
6.4.1 容忍度的配置
容忍度定義在 Pod 配置中,聲明 “我能容忍節點的某個污點”。例如,給 AI 任務的 Pod 加一個容忍度,匹配節點的?dedicated=gpu:NoSchedule?污點:
apiVersion: v1
kind: Pod
metadata:name: ai-training-pod
spec:containers:- name: ai-workerimage: ai-training-imagetolerations: # 容忍度配置- key: "dedicated" # 匹配污點的 keyoperator: "Equal" # 精確匹配value: "gpu" # 匹配污點的 valueeffect: "NoSchedule" # 匹配污點的 effecttolerationSeconds: 30 # 僅對effect=NoExecute有效:被驅逐前的寬限期(秒)
1.?key:要 “容忍” 的污點的名字
必須和節點上污點的key完全一致。比如節點污點是dedicated=gpu:NoSchedule,那么容忍度的key必須是dedicated。
2.?operator:匹配方式(關鍵!)
有兩種匹配方式,決定了容忍度如何匹配污點:
operator: "Equal":精確匹配。需要容忍度的value和污點的value完全一致(比如污點是dedicated=gpu,容忍度value必須是gpu)。operator: "Exists":只要存在就匹配。不關心污點的value是什么,只要節點有這個key和effect的污點,就允許調度(此時value字段可以省略)。
3.?value:污點的值
只有當operator: "Equal"時才需要填,且必須和節點污點的value完全一致。如果operator: "Exists",可以不寫value。
4.?effect:要 “容忍” 的污點的排斥力度
必須和節點污點的effect完全一致(NoSchedule/PreferNoSchedule/NoExecute)。比如節點污點是NoSchedule,容忍度的effect也必須是NoSchedule。
5.?tolerationSeconds:寬限期(僅用于NoExecute)
當節點污點是NoExecute(會驅逐沒有容忍度的 Pod)時,這個字段表示:如果 Pod 有容忍度,會在多少秒后再被驅逐(給 Pod 留時間處理收尾工作)。默認不填的話,會立即驅逐。
6.4.2?實戰示例:給 Pod 配置容忍度
假設節點node-gpu有污點dedicated=gpu:NoSchedule,配置兩個 Pod 的容忍度,看看效果。
示例 1:用Equal精確匹配
# ai-pod.yaml
apiVersion: v1
kind: Pod
metadata:name: ai-pod
spec:containers:- name: ai-workerimage: tensorflow/tensorflow # 需要GPU的AI任務tolerations:- key: "dedicated" # 匹配污點的keyoperator: "Equal" # 精確匹配value: "gpu" # 匹配污點的valueeffect: "NoSchedule" # 匹配污點的effect創建 Pod:kubectl apply -f ai-pod.yaml
結果:這個 Pod 會被正常調度到node-gpu節點(因為容忍度完全匹配污點)。
示例 2:用Exists簡化匹配
如果節點污點的value可能變化(比如有時是gpu,有時是nvidia-gpu),但key始終是dedicated,可以用Exists匹配:
# ai-pod-simple.yaml
apiVersion: v1
kind: Pod
metadata:name: ai-pod-simple
spec:containers:- name: ai-workerimage: tensorflow/tensorflowtolerations:- key: "dedicated" # 只看key是否存在operator: "Exists" # 不關心valueeffect: "NoSchedule" # 匹配effect# 這里省略了value,因為Exists不需要
創建 Pod 后,無論節點污點的value是gpu還是nvidia-gpu,這個 Pod 都能被調度到node-gpu上。
反例:沒有容忍度的 Pod
# normal-pod.yaml
apiVersion: v1
kind: Pod
metadata:name: normal-pod
spec:containers:- name: nginximage: nginx # 普通應用,不需要GPU# 沒有配置任何容忍度創建 Pod 后,會發現它一直處于Pending狀態(調度失敗),因為它沒有 “通行證”,被node-gpu的污點拒絕了。
6.4.3?容忍度的常見場景
-
訪問專用節點:比如 GPU 節點、高性能計算節點,只有帶容忍度的 Pod 才能使用。
-
節點維護時不被驅逐:如果節點加了
NoExecute污點(用于維護),給需要持續運行的 Pod 配置容忍度,可以避免被驅逐。 -
靈活匹配動態污點:用
operator: "Exists"可以匹配同一key下不同value的污點,減少配置復雜度。
6.4.4?總結:容忍度的核心邏輯
-
容忍度是 Pod 的 “通行證”,用來匹配節點的污點;
-
必須滿足:
key和effect與污點完全一致; -
operator: Equal需要value也一致,operator: Exists忽略value; -
沒有容忍度的 Pod,會被有對應污點的節點拒絕。
未完待續.............







——自定義坐標系(北京 54、西安 80、2000 坐標系))











