

用 Python 調用 Bright Data MCP Server:在 VS Code 中實現實時網頁數據抓取,本文介紹了Bright Data的Web MCP Server,這是一款能實現實時、結構化網頁數據訪問的API,適用于AI應用等場景。其支持靜態與動態網頁,前3個月每月提供5000次免費請求,有遠程托管和本地部署兩種方式。文章以在VS Code中用Python調用其API抓取Google搜索結果為例,詳解了準備工作、代碼編寫、參數說明等實戰流程,還提及該工具免維護代理池等技術亮點及使用限制。

一、引言:為什么AI時代需要高效的網頁數據訪問工具?
在大語言模型(LLM)和智能代理(Agent)快速發展的今天,"實時性"成為AI應用落地的關鍵瓶頸。想象一下:當你的AI助手需要回答"今天上海的天氣預警"或"某款產品的最新用戶評價"時,它必須依賴實時網頁數據才能給出準確答案——而靜態的訓練數據根本無法滿足這類需求。
傳統方案卻始終繞不開兩個痛點:
- 自建爬蟲需要維護代理池、處理驗證碼、應對網站反爬策略,成本高且穩定性差;
- 動態網頁(如JavaScript渲染的內容)難以抓取,普通API往往返回不完整的"殼數據"。
Bright Data的Web MCP Server(Model Context Protocol Server)正是為解決這些問題而生:它提供"即插即用"的網頁數據訪問能力,讓開發者無需關注爬蟲底層細節,只需調用API就能獲取結構化的實時數據,尤其適合AI應用、智能代理和自動化工作流。
二、Bright Data MCP Server簡介:開發者需要知道的核心信息
2.1 什么是MCP Server?
MCP Server是Bright Data推出的網頁數據訪問API,支持靜態網頁和動態網頁的數據抓取。無論是Google搜索結果、LinkedIn職位信息,還是需要JavaScript渲染的交互式頁面,都能通過簡單的API調用獲取結構化數據。
Bright Data MCP 以一站式解決方案助力 AI 模型與代理實時高效獲取公共 Web 數據,無論是靜態文本還是動態加載內容均可精準抓取,無需開發者自建復雜爬蟲架構或攻克反爬技術壁壘,通過集成化的技術架構與智能調度系統,讓 AI 輕松突破數據獲取技術瓶頸
√ 即插即用零代碼部署:標準化接口設計,無需搭建復雜爬蟲框架或編寫反反爬代碼,通過簡單配置即可接入全球網頁數據源
√ 動態數據全鏈路解析:針對現代網頁普遍采用 JavaScript 渲染、動態加載技術,MCP 內置智能解析引擎,自動識別頁面元素變化規律,精準抓取實時價格、評論更新等動態內容
√ 超規模穩定網絡支撐:依托 7200 萬個 IP、覆蓋 195 個國家的商用代理網絡,MCP 可實現每秒 17 萬次請求的高并發采集,每日處理 1PB 級網絡流量,同時保持 99.99% 的系統可用性
√ 合規安全智能防護:通過內置 AI 反指紋技術,MCP 自動模擬真實用戶行為,規避網站反爬機制;數據傳輸全程采用 TLS 加密,嚴格遵循 GDPR、CCPA 等國際數據法規,為企業數據安全與合規運營提供雙重保障
2.2 核心優勢
- 免維護底層:自帶代理池、自動解鎖地理限制、處理驗證碼和JavaScript渲染,開發者無需關心反爬細節;
- 靈活部署:支持遠程托管(推薦新手)和本地部署(適合高級定制);
- 多模式支持:可通過URL參數控制行為(如
unlocker解鎖限制、browser啟用瀏覽器渲染),支持SSE(Server-Sent Events)和標準HTTP請求; - 工具集成友好:無縫對接Python、LangChain、n8n等主流開發工具和自動化平臺。
2.3 免費額度
對于開發者來說,最具吸引力的是其免費政策:前3個月每月提供5000次免費請求,足夠滿足開發測試和輕量級應用需求。
三、實戰:在VS Code中用Python調用MCP API抓取Google搜索結果
下面以"實時抓取Google搜索結果"為例,詳解在VS Code中使用Python調用MCP Server的完整流程。
3.1 準備工作
-
注冊Bright Data賬號并獲取API Token
訪問Bright Data MCP Server官方頁面,登錄后在控制臺創建MCP項目,獲取API Token(類似abc123...的字符串)。
-
配置開發環境
- 確保已安裝Python 3.8+和VS Code;
- 安裝必要庫(
requests用于HTTP請求):
在VS Code終端執行:pip install requests
3.2 步驟1:編寫Python代碼(核心邏輯)
在VS Code中新建mcp_google_demo.py文件,代碼如下(含詳細注釋):
import requests
import json# 1. 配置基礎參數
API_TOKEN = "你的API Token" # 替換為實際Token
MCP_ENDPOINT = "https://mcp.brightdata.com" # 遠程托管端點
SEARCH_QUERY = "2025年AI行業趨勢" # 要搜索的關鍵詞# 2. 構造API請求參數
params = {"token": API_TOKEN,"url": f"https://www.google.com/search?q={SEARCH_QUERY}","browser": "true", # 啟用瀏覽器渲染(處理動態內容)"unlocker": "true", # 自動解鎖地理限制和反爬"format": "json" # 指定返回格式為JSON
}# 3. 發送請求并獲取響應
try:response = requests.get(MCP_ENDPOINT, params=params)response.raise_for_status() # 檢查請求是否成功result = response.json() # 解析JSON響應# 4. 處理并打印結果print("Google搜索結果抓取成功:")# 提取前3條結果(標題、鏈接、摘要)for i, item in enumerate(result.get("organic_results", [])[:3]):print(f"\n結果{i+1}:")print(f"標題:{item.get('title')}")print(f"鏈接:{item.get('url')}")print(f"摘要:{item.get('snippet')}")except requests.exceptions.RequestException as e:print(f"請求失敗:{e}")
except json.JSONDecodeError:print("響應格式錯誤,無法解析為JSON")
3.3 步驟2:關鍵參數說明
token:必填,用于身份驗證的API Token;url:目標網頁URL(此處為Google搜索鏈接,含關鍵詞);browser="true":啟用無頭瀏覽器渲染,確保動態加載的內容(如Google的異步搜索結果)被完整抓取;unlocker="true":自動繞過Google的反爬限制(如IP封鎖、地區限制)。
3.4 步驟3:運行代碼并查看結果
在VS Code終端執行:
python mcp_google_demo.py
成功運行后,將輸出類似以下的結構化結果(JSON格式示例):
{"organic_results": [{"title": "2025年AI行業發展趨勢報告 - 科技智庫","url": "https://test.com/ai-trends-2025","snippet": "2025年AI將在自動駕駛、醫療診斷等領域實現規模化落地,生成式AI市場規模預計突破千億..."},// 更多結果...],"total_results": 1280000,"processed_at": "2025-08-18T10:30:00Z"
}
3.5 處理動態網頁的核心邏輯
對于需要JavaScript渲染的頁面(如Google搜索結果、LinkedIn動態),MCP Server通過browser="true"參數啟用遠程瀏覽器環境,模擬真實用戶瀏覽行為:
- 自動執行頁面JavaScript;
- 等待動態內容加載完成后再抓取;
- 避免被網站識別為爬蟲(通過模擬真實設備指紋、瀏覽器特征)。
四、技術亮點:為什么MCP Server適合開發者?
-
零維護成本
無需自建代理池、處理驗證碼或更新反爬策略,MCP Server的底層基礎設施會自動適配網站變化。 -
高度可擴展
支持從單條請求到每秒數千次的大規模抓取,無需擔心服務器壓力。 -
無縫集成自動化工具
除了Python,還可與n8n(定時任務)、LangChain(AI Agent)等工具結合,例如:- 用n8n+MCP實現"每小時抓取行業新聞"的自動化流程;
- 結合LangChain構建"實時網頁問答Agent",讓LLM能直接調用MCP獲取最新信息。
-
靈活控制抓取行為
通過URL參數調整模式:pro=1:啟用高級模式(更精準的動態內容處理);geo:指定地理位置(如geo=us獲取美國地區數據)。
五、使用建議與限制說明
- 免費額度范圍:前3個月每月5000次請求,適合開發測試;團隊賬號的免費額度為多用戶共享。
- 付費說明:超出免費額度或使用
mcp_browser等高級功能會產生費用,具體可參考官方定價。 - 合規性:僅支持抓取公共領域數據,需遵守目標網站的robots協議和相關法律法規。
六、在線體驗
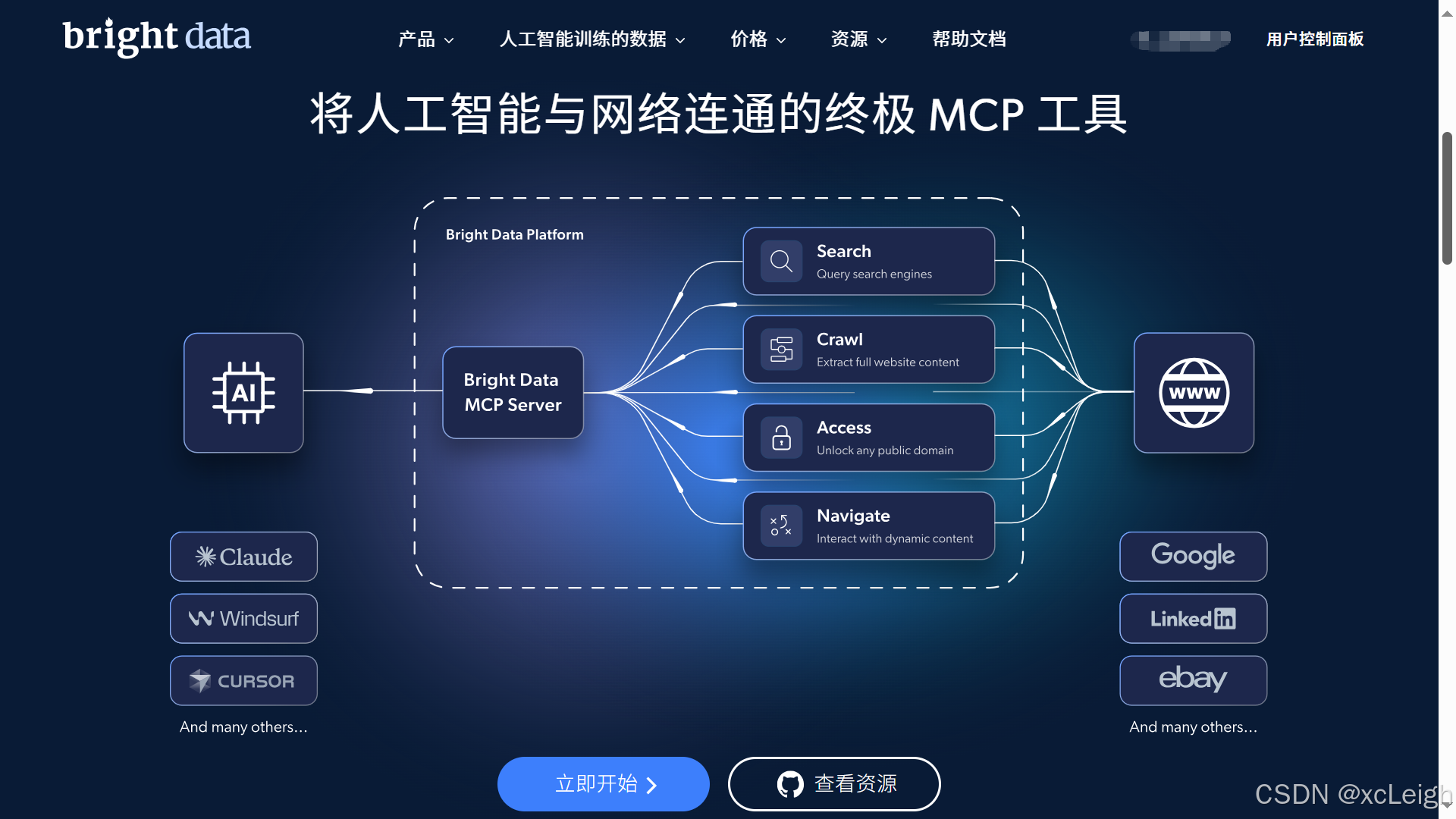
進入演示環境后,在界面中找到 “Try in Playground” 按鈕并點擊,進入到實際操作的 playground 區域。

在 playground 里,能看到多種工具選項,像 search_engine(可從谷歌、必應等搜索引擎抓取結果)、scrape_as_markdown(抓取單網頁并以 Markdown 格式返回內容)、scrape_as_html(抓取單網頁并以 HTML 格式返回內容)等。根據抓取亞馬遜商品數據的需求,選擇合適的工具。
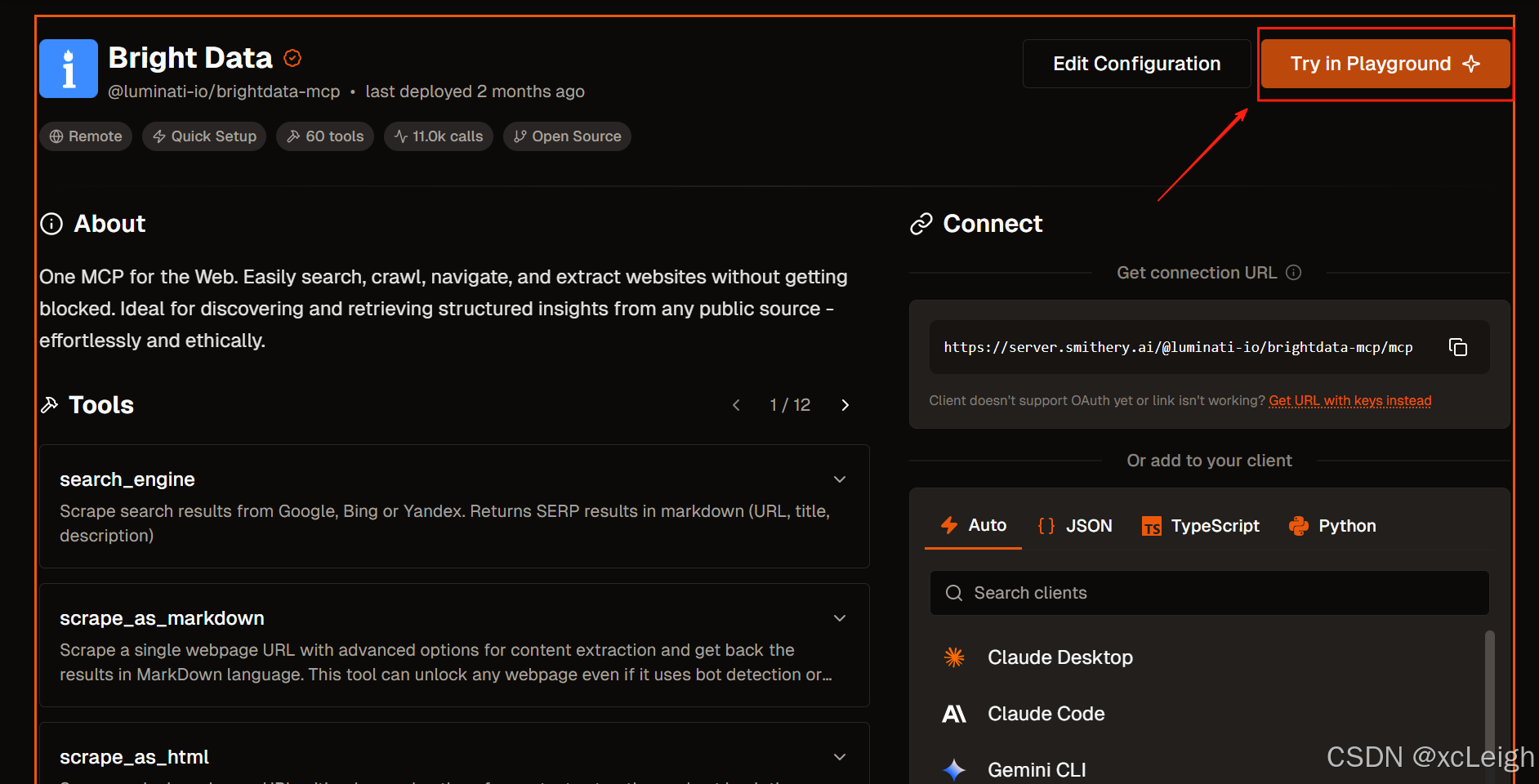
在輸入框中輸入類似 “幫我抓取亞馬遜商品折扣價大的衣服” 這樣的請求。此時,助手會進一步詢問你關注的亞馬遜站點(如美國、英國等)、具體服裝類型(如男裝、女裝等)以及是否有價格區間或品牌偏好等信息。
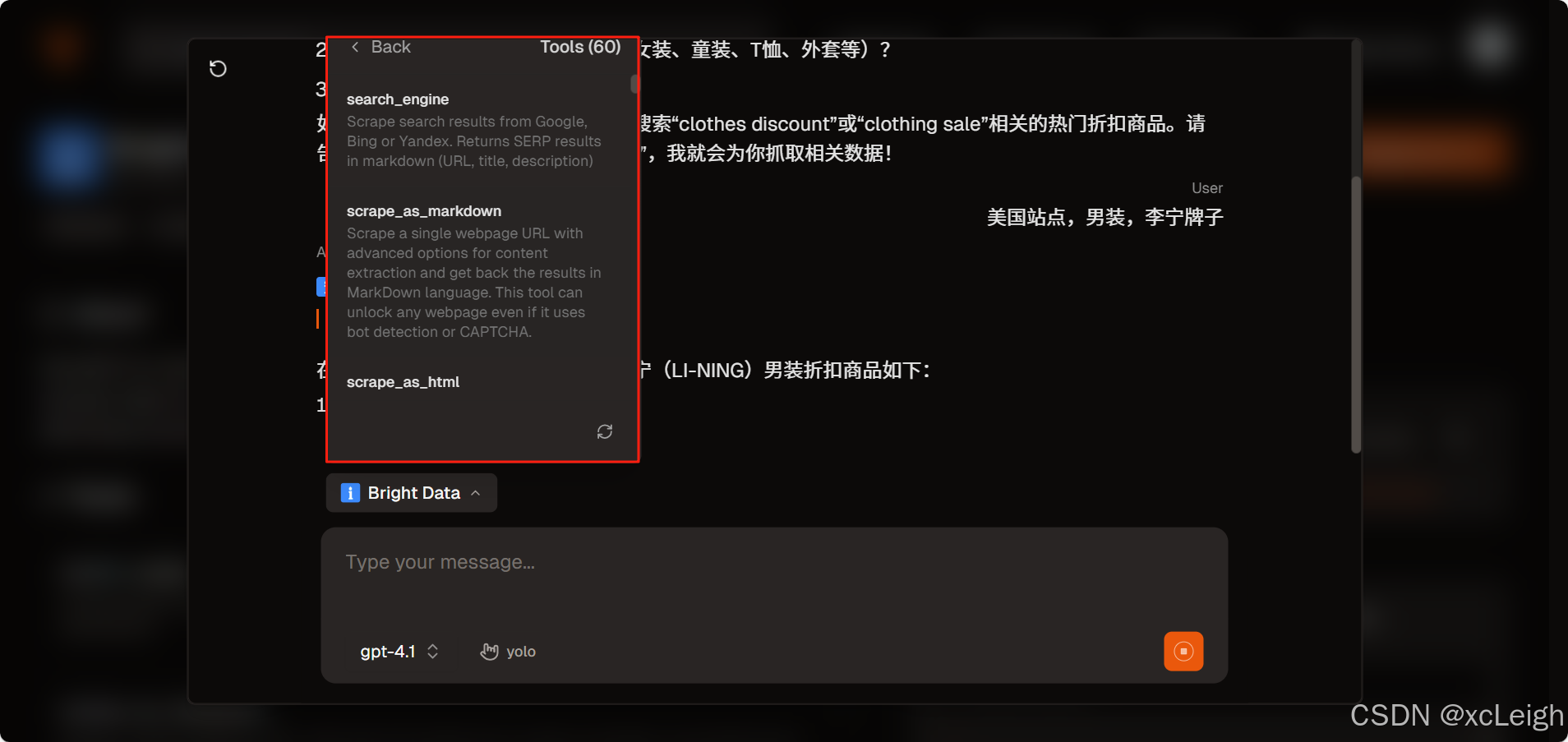
以抓取美國站點李寧男裝折扣商品為例,在你提供相關信息后,Bright Data 會快速為你返回抓取到的商品數據,包括商品名稱、價格、配送信息等內容,還會給出一些相關建議,比如關注促銷活動頁面或嘗試其他電商平臺獲取更多信息。


七、立即嘗試:獲取你的免費額度
訪問 Bright Data MCP Server,通過專屬鏈接注冊即可享受3個月免費額度(每月5000次請求)。無論是構建AI智能體、開發自動化工具,還是搭建數據管道,MCP Server都能幫你快速實現實時網頁數據訪問。

👆 快來領取你的武功秘籍!點擊領取 Bright Data MCP 服務器,送你每月免費額度!
聯系博主
????xcLeigh 博主,全棧領域優質創作者,博客專家,目前,活躍在CSDN、微信公眾號、小紅書、知乎、掘金、快手、思否、微博、51CTO、B站、騰訊云開發者社區、阿里云開發者社區等平臺,全網擁有幾十萬的粉絲,全網統一IP為 xcLeigh。希望通過我的分享,讓大家能在喜悅的情況下收獲到有用的知識。主要分享編程、開發工具、算法、技術學習心得等內容。很多讀者評價他的文章簡潔易懂,尤其對于一些復雜的技術話題,他能通過通俗的語言來解釋,幫助初學者更好地理解。博客通常也會涉及一些實踐經驗,項目分享以及解決實際開發中遇到的問題。如果你是開發領域的初學者,或者在學習一些新的編程語言或框架,關注他的文章對你有很大幫助。
????親愛的朋友,無論前路如何漫長與崎嶇,都請懷揣夢想的火種,因為在生活的廣袤星空中,總有一顆屬于你的璀璨星辰在熠熠生輝,靜候你抵達。
???? 愿你在這紛繁世間,能時常收獲微小而確定的幸福,如春日微風輕拂面龐,所有的疲憊與煩惱都能被溫柔以待,內心永遠充盈著安寧與慰藉。
????至此,文章已至尾聲,而您的故事仍在續寫,不知您對文中所敘有何獨特見解?期待您在心中與我對話,開啟思想的新交流。
???? 💞 關注博主 🌀 帶你實現暢游前后端!
???? 🏰 大屏可視化 🌀 帶你體驗酷炫大屏!
???? 💯 神秘個人簡介 🌀 帶你體驗不一樣得介紹!
???? 🥇 從零到一學習Python 🌀 帶你玩轉Python技術流!
???? 🏆 前沿應用深度測評 🌀 前沿AI產品熱門應用在線等你來發掘!
???? 💦 注:本文撰寫于CSDN平臺,作者:xcLeigh(所有權歸作者所有) ,https://xcleigh.blog.csdn.net/,如果相關下載沒有跳轉,請查看這個地址,相關鏈接沒有跳轉,皆是抄襲本文,轉載請備注本文原地址。

???? 📣 親,碼字不易,動動小手,歡迎 點贊 ? 收藏,如 🈶 問題請留言(或者關注下方公眾號,看見后第一時間回復,還有海量編程資料等你來領!),博主看見后一定及時給您答復 💌💌💌






——自定義坐標系(北京 54、西安 80、2000 坐標系))












)