參考視頻:1小時速通 - 從強化學習到RLHF - 簡介_嗶哩嗶哩_bilibili
強化學習RL
RL的核心就是智能體Agent 與 環境Environment的交互。
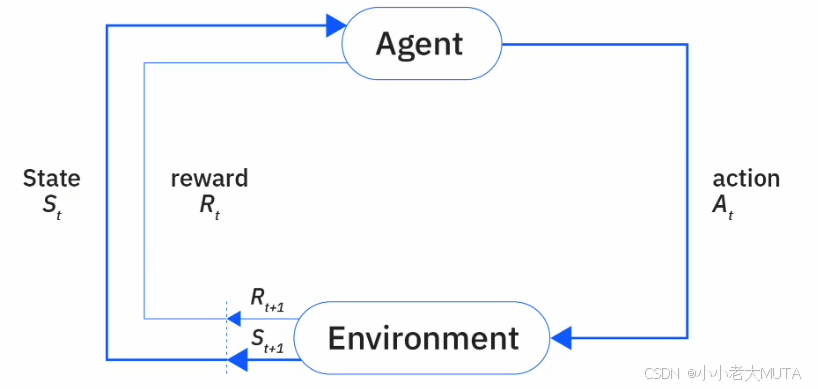
- 狀態(State,s):環境在某一時刻的描述,表示當前情境。
- 動作(Action,a):智能體基于狀態做出的選擇或行為。
- 獎勵(Reward,r):環境對智能體動作的反饋,用于評價動作好壞。
- 策略(Policy,π):智能體選擇動作的策略,通常是狀態到動作的映射函數。
- 價值函數(Value Function):評估某一狀態或狀態-動作對的長期價值,幫助智能體判斷哪些狀態或動作更有利。
- 環境轉移概率(Transition Probability):環境狀態轉移的概率分布,描述給定當前狀態和動作后,環境變到下一個狀態的可能性。
RL的核心目標就是:學習一個最優策略π*,最大化從當前時刻開始未來累計獲得的獎勵期望,通常表示為最大化期望折扣累計獎勵:
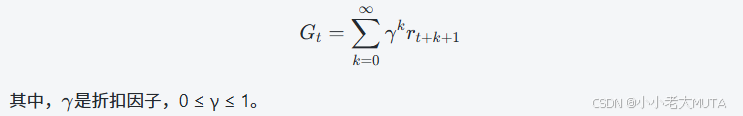
整體訓練流程
初始化:
初始化環境,設定初始狀態?s0?。
初始化策略π(例如隨機策略)及價值函數。
交互采樣(采集經驗):
智能體根據當前狀態?stst??和策略 π 選擇動作?atat?。
環境根據動作執行,反饋獎勵?rt+1?和下一個狀態?st+1。
智能體將元組?(st,at,rt+1,st+1)存入經驗池(某些算法使用)。
策略和價值函數更新:
根據采集的經驗,智能體調整策略和/或價值函數,以更好地預測未來獎勵,改進決策。
迭代訓練:
重復交互采樣和參數更新過程,通過不斷試錯和學習,策略逐漸完善,智能體表現提升。
終止條件:
達到預設的訓練步數或收斂標準。
智能體學習到滿意的最優或近似最優策略。
動態規劃Dynamic Prigramming
動態規劃是傳統RL的一種經典方法。
動態規劃方法是假設環境模型完全一致,也就是假設轉移概率函數?p(s′,r∣s,a) 是已知的,即:
給定當前狀態?s?和動作?a,我們完全知道環境轉移到下一個狀態?s′?并獲得獎勵?r?的概率分布。
RL的目標是希望Agent能夠去到獲得獎勵?r 高的狀態或動作。這意味著,智能體要了解當前策略下哪些狀態或動作的獎勵較高,并且逐步改進策略,選擇那些能帶來更大獎勵的路徑。
智能體通過評估當前策略的價值,知道“哪里好”,然后調整策略,去“更好”的地方。
DP的核心步驟
策略評估(Policy Evaluation)
- 計算當前策略在各個狀態下的價值函數(Value Function),即在遵循該策略時從該狀態開始能期望獲得的累計回報。
- 這一步是利用環境的轉移概率和獎勵函數,通過貝爾曼期望方程迭代求解或解析計算得到。
策略改進(Policy Improvement)
- 根據策略評估得到的價值函數,調整策略使其更優:在每個狀態選擇那個能獲得最大價值的動作,即讓策略“去到有最大價值的地方”。
- 這一步保證策略在每次改進后都是更好的。
和01背包問題的關聯
最近在刷leecode算法題,一看到DP就想到了01背包。

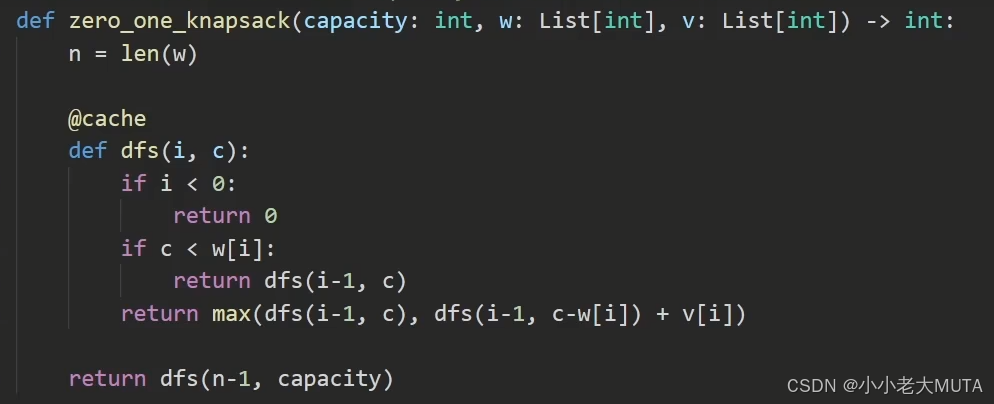
dp[i][w]=前i個物品,在容量為w的情況下的最大價值
- 通過遞推式(狀態轉移方程)逐步求解,最終得到最優解。
- 這個動態規劃過程是確定性和靜態的,狀態轉移和價值計算都是確定的,沒有涉及概率或環境交互。
DP數組的寫法:
def zero_one_knapsack(capacity: int, w: List[int], v: List[int]) -> int:n = len(w)# dp[i][c] 表示前 i 個物品(0-based),容量為 c 時的最大價值dp = [[0] * (capacity + 1) for _ in range(n)]# 初始化第一件物品(i=0)的狀態for c in range(w[0], capacity + 1):dp[0][c] = v[0]# 狀態轉移for i in range(1, n):for c in range(capacity + 1):if c < w[i]:dp[i][c] = dp[i-1][c]else:dp[i][c] = max(dp[i-1][c], dp[i-1][c - w[i]] + v[i])return dp[n-1][capacity]遞歸的寫法:
RL中的DP用來求解最優策略,考慮的是決策過程中的狀態轉移和獎勵,但狀態轉移和獎勵是隨機性的,由環境模型?p(s′,r∣s,a)?給出。
這里的動態規劃不只是單純求最大價值,而是求解貝爾曼方程,計算狀態價值函數?Vπ(s),然后基于價值函數進行策略改進。
動態規劃的核心是利用狀態轉移概率和獎勵函數的期望來迭代計算價值函數,這是一個多階段的序貫決策問題,狀態和動作之間的轉移關系類似于馬爾可夫決策過程(MDP)的框架,而不只是單純的一維或二維數組轉移。
通過貝爾曼方程表達狀態價值函數
狀態價值函數 vπ(s) 表示在策略 π 下,從狀態 s 開始,未來能夠獲得的期望累計獎勵(通常帶折扣因子)的期望值:

貝爾曼方程用遞歸的形式表達vπ?(s):
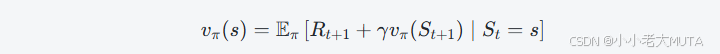
當前狀態的價值等于:從當前狀態采取策略 π 選擇動作得到的即時獎勵 Rt+1,加上折扣后的下一狀態的期望價值 vπ(St+1)。
這個地方可以通過01背包的遞歸寫法理解。

貝爾曼方程假設了已知環境動態(轉移概率和獎勵分布),也就是已知從當前狀態s,采取動作a后轉移到下一個狀態s′并獲得獎勵r的概率。
貝爾曼方程成立的“理想環境”是指:
狀態轉移概率、獎勵完全已知
環境嚴格滿足馬爾可夫性(狀態轉移只依賴當前狀態和動作,不依賴歷史)
狀態/動作空間有限且可遍歷
獎勵函數明確
在現實強化學習場景中,這些條件往往難以全部滿足:
- 環境模型未知:無法直接計算?p(s′,r∣s,a)。
- 狀態空間巨大甚至連續,無法窮舉。
- 狀態觀測不完全或環境非馬爾可夫。
所以我們用貝爾曼方程作為理論基礎,但算法上常常采用采樣、逼近、估計等方式處理。
- Monte Carlo Methods
- Q-learning
- Temporal Difference (TD)
- Policy Gradient / REINFORCE algorithm
Policy Gradient策略梯度方法
用貝爾曼方程表達狀態價值函數進而求解最大化期望折扣累計獎勵的策略。
但是貝爾曼方程滿足需要的條件很難達到,所以有了很多其他策略。
策略梯度方法是直接以最大化期望累計回報為目標,通過對策略參數進行優化,計算目標函數關于策略參數的梯度,并用梯度上升法更新。
實現直接優化策略而不是“間接”通過估計值函數。
?策略梯度方法分為:
- 純策略梯度法(如REINFORCE)只用采樣的獎勵,不顯式用貝爾曼方程。
- 高級策略梯度法(如Actor-Critic、A2C、A3C等)會引入價值函數(critic),用貝爾曼方程逼近(如TD誤差),減少方差、提升效率。
策略梯度公式通常如下:
![]()
- 其中?Qπ(s,a)就是貝爾曼方程定義的動作價值函數,它的準確估計往往依賴貝爾曼方程或其近似(如用TD方法估計)。
RL in LLMs
LLM問題的RL形式:
這部分內容的核心是:把語言模型的生成過程看作一個馬爾可夫決策過程(MDP),用強化學習框架進行建模和優化。
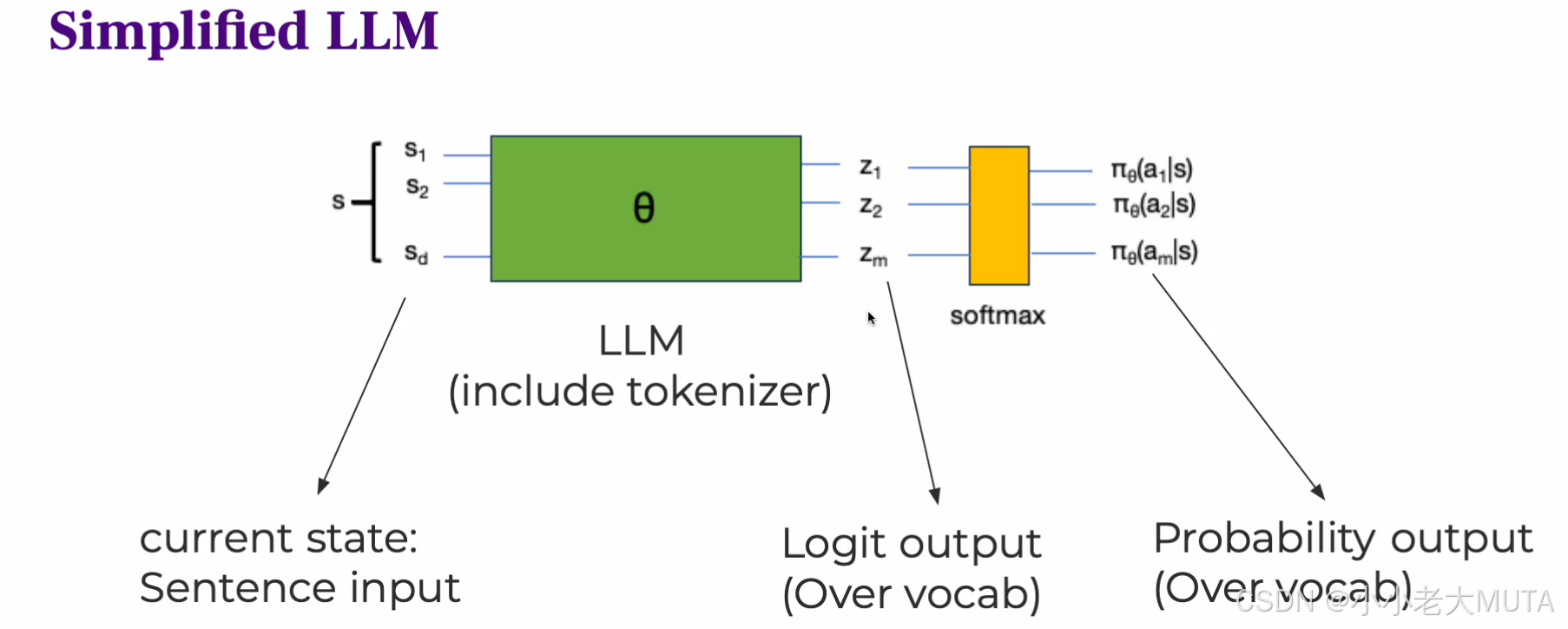

狀態state
- 初始狀態?S0?是提示詞(prompt),即輸入給模型的上下文。
- 隨著生成過程,狀態不斷更新,StS表示當前提示詞 + 已生成的所有token,也就是說狀態包含了從初始到當前時間步生成的全部信息,作為決策依據。
動作空間action space
- 動作空間是詞匯表(vocabulary),每一步動作是從詞匯表中選擇一個token。
- 動作?At?是在時間步?t?生成的具體token。
策略Policy
- 策略是模型的輸出概率分布,也就是大語言模型(LLM)在給定當前上下文?St 時,生成下一個token?At?的概率。
- 用參數?θ?表示模型的參數(比如transformer的權重)。
- 通過softmax把模型的logit 輸出?zi 轉化為概率。
回合終止(Episode end)
-
當生成了特殊token?
<|end of text|>?時,回合結束。 -
整個生成過程視為一個完整的episode。
獎勵Reward
- 假設對每個生成的完整句子都能得到一個獎勵信號(比如從人類反饋得到的評分,或者自動指標)。
- 強化學習目標是最大化期望累計獎勵。
| 組成要素 | 對應RL元素 | 說明 |
|---|---|---|
| Prompt + 已生成tokens | 狀態?St | 當前上下文,全信息 |
| Token vocabulary | 動作空間?A | 每步選擇一個token作為動作 |
| 生成下一個token的概率分布 | 策略?πθ? | LLM輸出的softmax概率分布 |
| 生成過程 | Episode | 直到結束token,構成一個完整episode |
| 句子質量評價 | 獎勵函數?R | 反饋生成句子的好壞,指導學習 |
RLHF 基于人類反饋的強化學習
RLHF是在強化學習框架中引入人類反饋作為獎勵信號的強化學習方法。
通過人類專家或用戶對智能體行為的評價(正向或負向反饋),來訓練或指導策略,使其行為更符合人類期望。
| 方面 | 強化學習(RL) | 基于人類反饋的強化學習(RLHF) |
|---|---|---|
| 獎勵信號來源 | 預定義的環境獎勵函數(明確、可計算) | 不直接用環境獎勵,獎勵來自人類反饋訓練的獎勵模型 |
| 目標 | 最大化環境定義的累積獎勵 | 最大化符合人類偏好的累積獎勵 |
| 訓練過程 | 智能體與環境交互,用環境獎勵更新策略 | 智能體與環境交互,用人類反饋訓練的獎勵模型指導策略 |
| 適用場景 | 多用于有明確目標和環境反饋的問題 | 多用于人類主觀評價難以明確表達的任務,如文本生成 |
| 關鍵挑戰 | 設計合適的獎勵函數 | 收集高質量的人類反饋,訓練準確的獎勵模型 |
RLHF的整體流程:
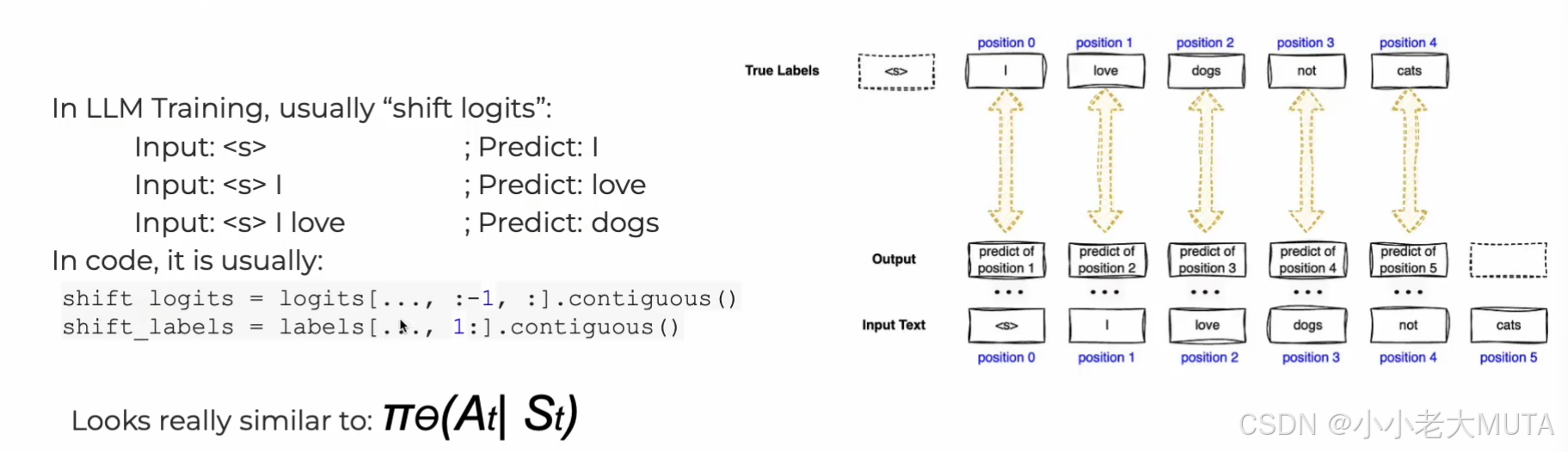
1. 監督微調(Supervised Fine-Tuning,SFT)
目的:通過有標注的示例(人類書寫的示范回答)對基礎預訓練模型進行微調。
步驟:
- 收集大量人類撰寫的問答對(Prompt + 理想回答)。
- ?使用監督學習(最大似然估計)訓練模型生成更符合人類示范風格的回答。
結果:模型初步具備生成較高質量回答的能力。
如上圖,整個流程就像是給定之前的單詞(state),預測下一個單詞(action)
訓練:
<prompter>表示提問者(用戶)的身份角色。<assistant>表示回答者(模型)的身份角色。<|endoftext|>表示這條對話的結束。推理:模型從
<assistant>開始,預測接下來合理的回答內容。
2. 訓練獎勵模型(Reward Model,RM)
目的:從人類反饋數據中訓練一個模型,能夠給模型生成的回答打分,表示人類對回答的偏好程度。
步驟:
- 收集大量人類評分數據,通常是偏好對比:給出兩個模型回答,讓人類選擇更好的那個。(偏好數據)
- 訓練獎勵模型,使其能對任意回答給出一個“獎勵分數”,反映人類偏好。
模型:獎勵模型通常是基于基礎語言模型的編碼器+回歸頭,輸出一個標量分數。
意義:這個模型是RL訓練階段的“代理獎勵函數”,替代難以明確定義的人工獎勵。
采用對比學習的思想,定義損失函數:
- r??(x,y)?是獎勵模型對輸入-回答對的評分。
- σ?是sigmoid函數,將分數差轉換成概率。
- 期望是對數據集中的所有偏好對進行平均。
直觀理解:鼓勵獎勵模型給更優回答更高分,使得?r?(x,yw)>r?(x,yl)。
3. 基于獎勵模型的強化學習(Policy Optimization)
目的:用強化學習算法,以獎勵模型的評分為優化目標,進一步提升模型策略。
技術細節:
- 使用策略梯度算法,如PPO(Proximal Policy Optimization)。
- ?訓練時,智能體(語言模型)采樣回答,獎勵模型給出評分,策略據此調整參數。
限制:同時用KL散度約束限制新策略與原策略差異,保證穩定性防止過擬合獎勵模型。
結果:模型輸出更符合人類偏好、質量更高、更安全。
RLHF中的策略優化(Policy Optimization)方法
在RLHF中,第三步,用強化學習算法,以獎勵模型的評分為優化目標,調整參數。
這中間的優化過程,就需要使用一些策略優化算法。
經典方法如下:
| 方法 | 關鍵點 | 備注 |
|---|---|---|
| PPO | 穩定性強,利用Critic和Advantage | OpenAI主流選擇 |
| GRPO | 基于組內相對表現,KL約束 | 適合多策略協作 |
| DPO | 無需獎勵模型,直接優化偏好數據 | 簡化訓練流程 |
PPO(Policy Proximity Optimation)
這部分公式推導詳看:
PPO原理詳解 | 公式推導-CSDN博客
PPO的訓練過程(偽代碼)-CSDN博客
PPO的核心思想就是:
優化新策略時,不要讓其與舊策略差異過大(Proximity),保持“接近性”以保證穩定和安全。
Proximity 指的是:每次策略更新時,限制新策略和舊策略之間的變化幅度。
如果策略變化太大,可能會導致模型行為不穩定或者性能急劇下降。因此,PPO用剪切(clipping)或KL散度等技術來約束策略更新。
PPO-Clip的算法流程

輸入:
- 初始策略參數?θ0
- 初始價值函數參數??0 (價值函數用于評估當前狀態/動作的“好壞”,為優勢函數計算提供依據)
主循環:


- Importance sampling:通過概率比校正數據分布,兼容on-policy和小范圍off-policy。
- Advantage:策略更新主導方向。
- Clip函數:保證鄰近性,訓練穩定。

RL-->RLHF-->PPO
RL:在傳統強化學習中,通過最大化累計獎勵,也就是價值函數,進而優化策略函數。
RLHF:通過引入獎勵模型,給模型輸出進行打分,從而量化模型輸出的好壞。獎勵模型替代了RL中環境真實獎勵,通過最大化模型評分,直接優化策略函數。
如果是直接純策略梯度例如Reinforce方法,就沒有價值函數;如果是高級策略梯度法(如Actor-Critic)會引入價值函數(critic),減少策略梯度方差,用貝爾曼方程逼近(如TD誤差)。
PPO:在RLHF的基礎上,為了提升訓練的問題,首先引入了clip或者KL散度,保證了每次策略更新幅度有限,不要離舊策略太遠。然后優化策略使用的actor-critic,所以實質上還是通過引入價值函數的策略優化方法,去優化獎勵模型,從而優化策略函數。
在策略梯度更新的過程中,原本是最大化獎勵,為了訓練的問題,引入了基線,這個過程合并成了優勢函數(獎勵-當前策略期望獲得的累計回報)。
而優勢函數通過一系列變換,其實可以用價值函數表示。
所以整體本質上, PPO是在優化價值函數和獎勵函數,進而優化策略函數。
-
RLHF = RL + 人工獎勵模型
-
PPO = 為RLHF設計的穩定策略優化算法
-
Actor-Critic + PPO clip機制 = 高效且穩定的策略訓練
-
優勢函數 = 價值函數和獎勵信號結合的關鍵橋梁
這里有一個很容易理解錯誤的點就是,其實RL中所指的價值函數和PPO中所致的價值函數不完全一致:
雖然他們的定義和數學意義是一樣的,都是期望累計回報函數:
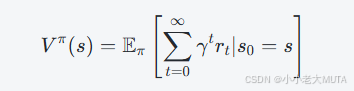
但是兩者的用途和訓練方式有所不同:
- 傳統RL中,價值函數是策略改進過程中的中間環節,主要用來評價策略。
- Actor-Critic中,價值函數是輔助網絡,主要作用是平滑策略梯度,降低方差,并通過與Actor協同訓練實現策略優化。
Actor-Critic策略梯度方法
Actor-Critic是RL中一種兼具策略優化和價值i評估的“策略梯度方法”,結合了兩類方法的優點:
- Actor(策略網絡):負責決策,輸出在每個狀態下采取各個動作的概率(策略),參數記為?θ;
- Critic(價值網絡):負責評估當前策略的好壞,估算當前狀態的價值(或狀態-動作價值),參數記為??。
Critic負責“評分”,Actor負責“改進行為”。
原理:
強化學習的目標是最大化期望累計回報,策略梯度法是直接對策略參數求導來求得最大期望累計回報的參數。
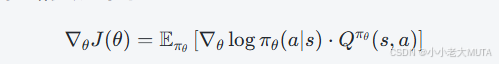
直接用實際回報![]() 估計會有很大的方差,訓練不穩定,價值函數就用來降低方差(就是baseline),也就是用價值函數來表達優勢函數。
估計會有很大的方差,訓練不穩定,價值函數就用來降低方差(就是baseline),也就是用價值函數來表達優勢函數。
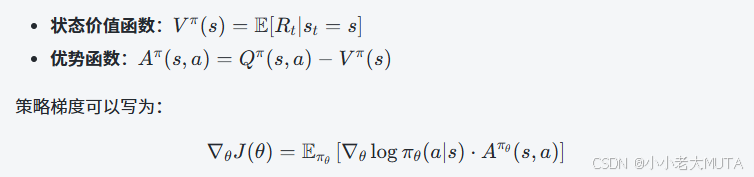
所以Actor-Critic結構就是:
- Actor:輸出策略?πθ(a∣s)(通常是softmax或高斯分布參數)。
- Critic:估算?V?(s) 或?Q?(s,a)。
Critic幫助估算優勢函數(Advantage),指導Actor的更新。
偽代碼如下:
for iteration in range(total_iterations):# 1. 用當前策略與環境交互,收集經驗(batch)batch = collect_experience(policy=actor, env=env)# 2. 更新Criticfor (s_t, a_t, r_t, s_{t+1}) in batch:target = r_t + gamma * V_phi(s_{t+1})loss_C = (V_phi(s_t) - target) ** 2Critic優化(loss_C, phi)# 3. 計算優勢Advantage = target - V_phi(s_t)# 4. 更新Actorloss_A = -log_pi_theta(a_t | s_t) * AdvantageActor優化(loss_A, theta)
Crtic價值函數的更新:
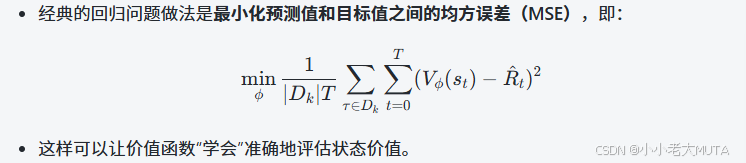
GRPO (Group Relative Policy Optimization)
GRPO是在PPO基礎上的一種改進,重點在于將獎勵和優勢函數的計算基于一組(group)內部的歸一化比較,而不是全局的絕對獎勵。這在某些任務中,比如多樣本、多目標、多任務的情形,能緩解獎勵尺度不一致的問題,增強訓練穩定性和泛化能力。
將PPO 和 GRPO 兩個目標函數公式放在一起對比:
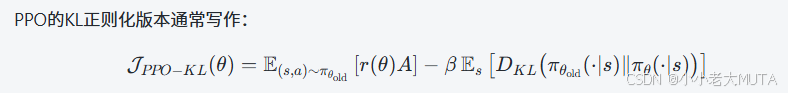




GPRO在PPO的基礎上,做了以下改動:
1.?多輸出組優化:一次采樣一組大小為G的輸出?{oi},對組內平均目標求期望。
2.?優勢函數Ai采用組內獎勵歸一化:
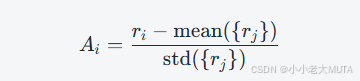
我們對比PPO 和 GRPO的公式發現,PPO 只是用了一個正則化手段,要是是KL散度要么是Clip(Clip用的最多);但是在GRPO公式中,既有Clip又有KL散度計算。Why?
- clip機制的作用:限制單步策略概率比?
在?[1??,1+?] 范圍內波動,防止策略在某一步驟驟變。
- KL散度的作用:直接限制新舊策略整體分布的差異,理論上更嚴謹、整體更穩定,但計算和調控相對復雜。
GRPO中的設計:
- clip裁剪:對單個輸出的概率比進行限制,防止單個輸出概率跳變過大。
- KL散度正則:對整個策略分布(針對組輸出)進行整體正則,控制新策略與參考策略(不一定是舊策略)之間的分布差異。
GRPO針對的是多輸出組的采樣和優化,優勢函數是組內歸一化相對優勢,這帶來:
- 獎勵尺度和樣本間差異更復雜,clip限制單個樣本的局部更新幅度,防止極端概率比出現。
- 整體策略分布的控制更加關鍵,KL散度限制策略整體分布的更新幅度,防止整體策略遷移過大。
DPO Direct Preference Optimization
這部分公式推導可詳看:DPO原理 | 公式推導-CSDN博客
DPO的核心思想:直接優化模型生成結果的偏好概率,不依賴傳統單獨訓練的獎勵模型。
LLM本身被“隱式”視為獎勵模型,模型直接通過人類偏好數據來調整生成策略。
其目標是最大化模型生成更偏好輸出的概率,相當于“最大化偏好的對數似然”。
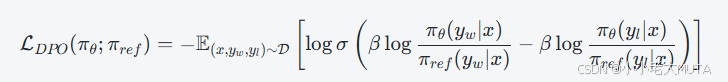

公式含義
- 計算當前模型生成優選輸出跟參考模型生成優選輸出的對數概率比,減去對應的劣選輸出的對數概率比。
- 通過Sigmoid函數,將該差異轉化為一個概率值,表示當前策略更偏好生成?yw而非?yl??的置信度。
- 對數之后取負期望,等價于最大化“當前模型在偏好對上的正確排序概率”,即訓練模型使其更傾向于生成被偏好的輸出。






Spring Cloud Alibaba 2023.x:微服務接口文檔統一管理與聚合)

)
,Y Pos(Y位置))
)








