1. 進程和線程的區別?創建線程的代價比創建進程小嗎?
- 進程是資源分配和調度的基本單位;線程是 CPU 調度的基本單位。
- 進程有獨立的地址空間,線程共享進程地址空間。
- 創建/銷毀進程開銷大,線程開銷小。
- 是的,因為不需要分配獨立地址空間。
2. 線程共享哪些資源?
- 地址空間(代碼段、數據段、堆等)
- 打開的文件
- 全局變量
- 信號處理器
- 不共享:棧、寄存器、程序計數器。
3. 用戶線程與內核線程區別?
- 用戶線程(User-level):用戶態管理,切換快,但內核不可見,一個阻塞會導致整個進程阻塞。
- 內核線程(Kernel-level):內核直接調度,支持多核并行,但切換開銷大。
4. 進程的五種狀態?哪些事件會引起新的進程創建?
新建(new)、就緒(ready)、運行(running)、阻塞(waiting)、終止(terminated)。
- 系統初始化
- 用戶請求(如執行程序)
- 創建系統調用(fork)
- 批處理作業調度
5. 進程上下文切換是什么?線程上下文切換呢?
保存和恢復進程的 CPU 環境(寄存器、PC、內存映射等),開銷大。
保存/恢復線程的寄存器、棧指針等,不涉及地址空間切換,開銷小。
6. CPU 如何調度進程? 常見調度算法?
- 調度目標:公平性、高吞吐量、低響應時間。
- 常見調度算法:
- 先來先服務 (FCFS)
- 思想:誰先到就先執行,按進入就緒隊列的順序來。
- 優點:簡單、公平,易于實現。
- 缺點:長作業會讓后面的短作業等待很久(“護航效應”)。
- 短作業優先 (SJF)
- 思想:優先調度執行時間短的作業。
- 優點:平均等待時間最短,效率高。
- 缺點:需要預知運行時間;對長作業不公平,可能一直得不到執行。
- 高響應比優先 (HRRN)
- 思想:綜合考慮等待時間和運行時間,公式:
- 響應比=(等待時間+運行時間)/運行時間
- 優點:兼顧長短作業,避免短作業獨占 CPU。
- 缺點:實現稍復雜,需要動態計算。
- 時間片輪轉 (RR)
- 思想:每個進程分配一個時間片,時間片到沒執行完就放回隊列,輪流調度。
- 優點:公平,適合分時系統,響應快。
- 缺點:時間片過小 → 頻繁切換開銷大;過大 → 退化成 FCFS。
- 優先級調度
- 思想:給每個進程設優先級,優先級高的先執行。
- 優點:靈活,可以滿足任務的不同緊急性。
- 缺點:可能導致低優先級進程長期得不到執行(饑餓現象)。
- 多級反饋隊列 (MFQ,最常用)
- 思想:綜合前面幾種算法的優點。
- 按優先級分多個隊列,高優先級先執行。
- 新進程先進入高優先級隊列,時間片短;如果沒執行完,就降到低一級隊列,時間片更長。
- 長作業慢慢“下沉”,短作業一般能在上層快速完成。
- 優點:公平、靈活,適合通用操作系統。
- 缺點:實現復雜,參數(隊列數、時間片長短)不好調。
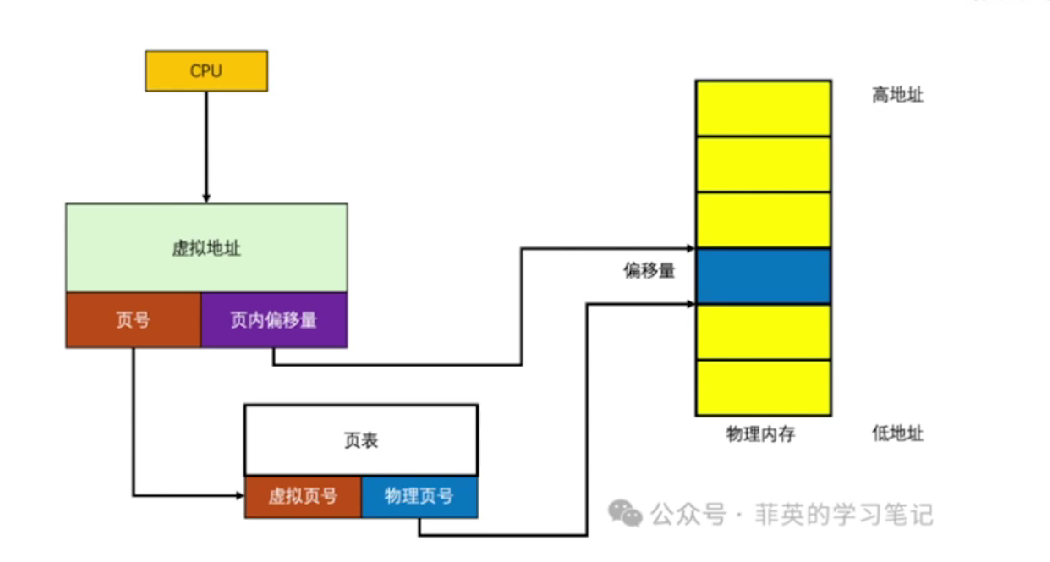
7. 分頁與分段的區別?
- 分頁(Paging)
按固定大小劃分:整個邏輯空間切成頁,物理內存切成頁框。
頁可以 不連續 地存放在物理內存中。
優點:
消除外部碎片,內存利用率高
方便虛擬內存和置換
缺點:
邏輯連續性在物理上不保證
代碼、數據可能被分散到不同頁上
分頁把邏輯空間劃分為頁,物理內存劃分為頁框,通過頁表實現邏輯頁到物理頁框的映射。頁表存在內存里,為了加速地址轉換引入了快表(TLB);為減少大頁表的內存消耗,引入了多級頁表;進一步可以用反向頁表+哈希查找來優化空間和效率。程序看到的都是虛擬地址,運行時通過頁表機制映射為物理地址。
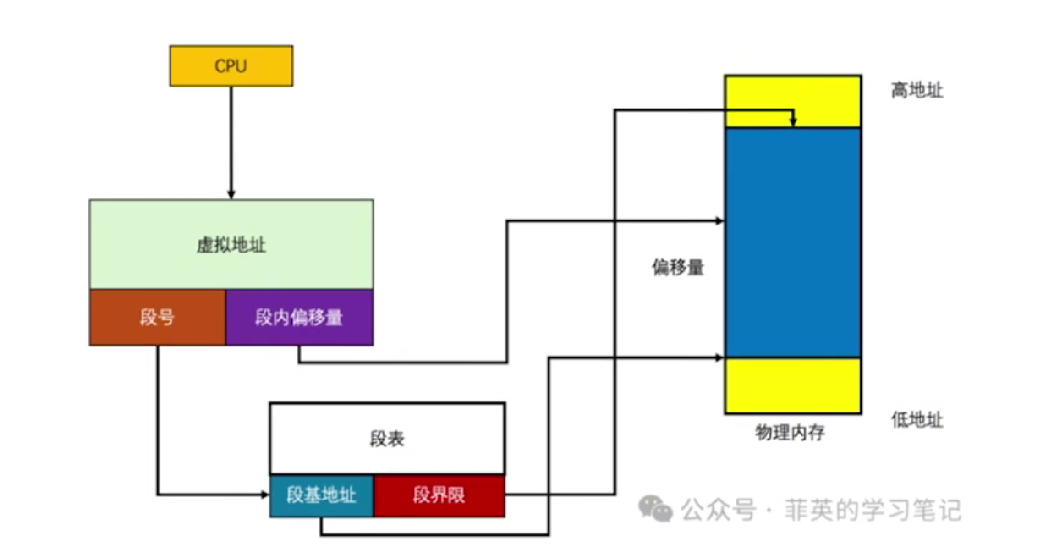
- 分段(Segmentation)
按邏輯模塊劃分:代碼段、數據段、棧段、堆等。
每段在物理內存中 連續存放。
優點:
邏輯清晰,符合程序結構
易于保護(不同段可設置不同權限)
可以共享整個段(如只讀代碼段)
缺點:
可能產生 外部碎片
需要連續內存空間
分段是按程序邏輯劃分內存,每段可變大小,地址由段號+段內偏移組成。段表記錄段基址和段長,實現邏輯地址 → 物理地址映射。
8. 虛擬內存原理?頁面置換算法?
虛擬內存(Virtual Memory)是操作系統將物理內存(RAM)與硬盤空間結合形成的二級存儲體系,通過創建分頁文件(如Windows的pagefile.sys)擴展可用內存容量。當物理內存不足時,系統自動將不活躍的數據轉移到硬盤,騰出空間供當前進程使用。??
把部分數據放在磁盤,需要時換入內存,不需要時換出。通過頁表+缺頁中斷實現。
TLB替換和虛擬內存換頁都用類似的策略(FIFO、LRU等),本質都是緩存替換思想。但TLB替換只在CPU內部緩存頁表映射,開銷小;虛擬內存換頁涉及把物理頁換出到磁盤,開銷大,需要處理缺頁中斷。
- FIFO(先進先出)
- LRU(最近最少使用)
- LFU(最不經常使用,頻率)
9. 什么是缺頁中斷?什么是 頁面抖動 ?
訪問頁面不在內存時觸發,由操作系統調入缺失頁。
缺頁率過高,頻繁調頁,CPU 時間大多浪費在換頁上。
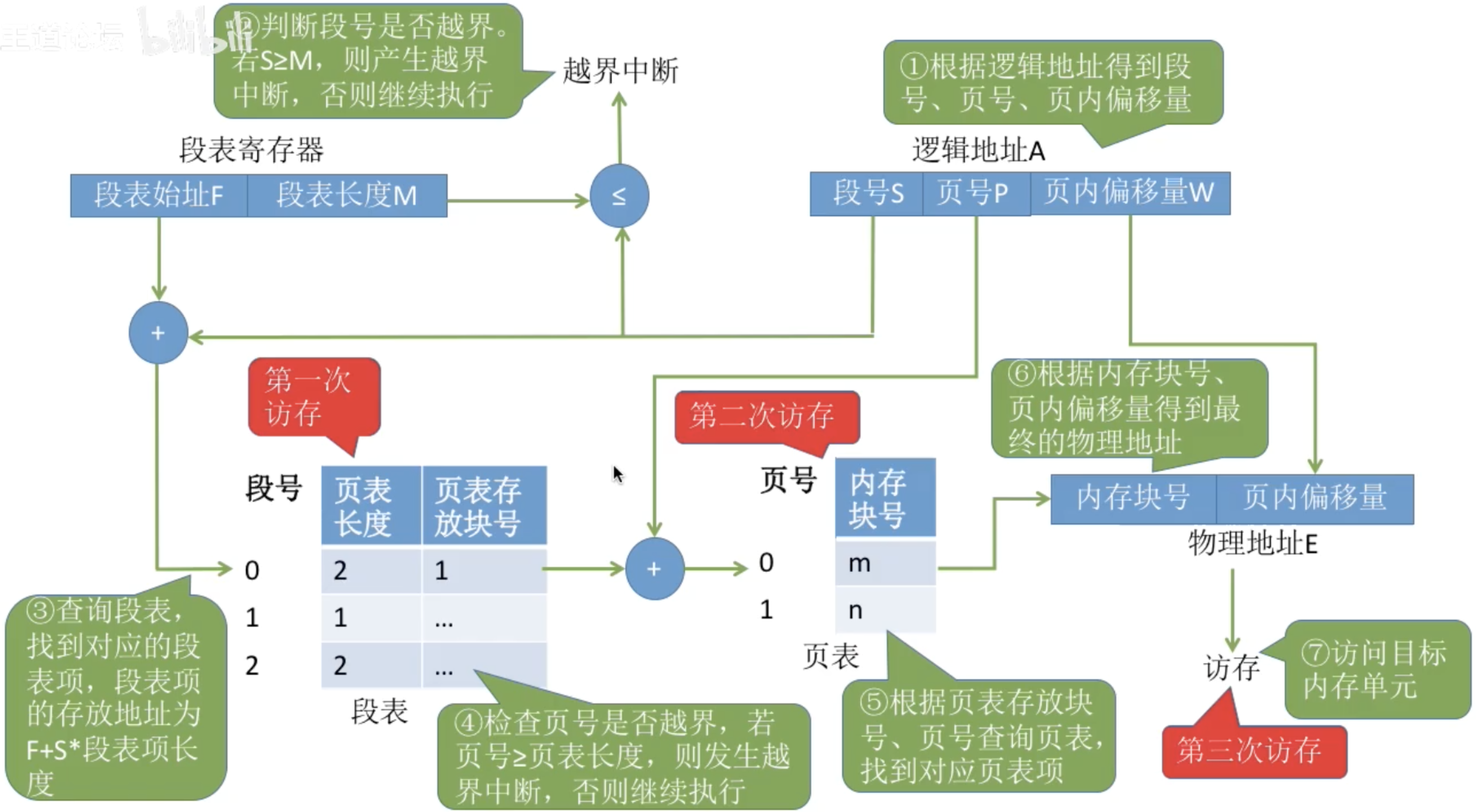
10. 段頁式管理是什么?
- 基礎是分頁
- 內存按固定大小頁框管理,邏輯頁連續,物理頁不連續
- 優點:內存利用率高,換入換出快,消除了外部碎片
- 加上段的概念
- 虛擬地址空間按邏輯模塊分段(代碼段、數據段、棧段)
- 每段有獨立段表 → 可單獨管理、保護和共享
- 段內再分頁 → 段內頁可以分散存放,仍然享受分頁優勢
- 邏輯和物理關系
- 邏輯上:段內連續,保持程序結構
- 物理上:段內頁不連續,提高內存利用率
- 支持虛擬內存換入換出,不影響段的保護和共享
11. 臨界區是什么?互斥 vs 同步 vs 異步 vs 并發?
進程/線程訪問共享資源的代碼片段。
- 互斥(Mutual Exclusion)
目的:防止多個線程/進程同時訪問共享資源導致沖突。
關鍵點:同一時間 只允許一個線程訪問資源
實現方式:鎖(synchronized、ReentrantLock)、信號量(Semaphore)等
例子:兩個線程同時往銀行賬戶存錢,需要加鎖保證金額正確
- 同步(Synchronous)
目的:保證操作按順序執行,協調多個任務
特點:
調用者 必須等待操作完成 才能繼續
可以是線程之間的同步,也可以是調用者與被調用者的同步
例子:
方法調用:int res = foo(); → 調用線程必須等 foo() 執行完再繼續
多線程同步:用 CountDownLatch、Barrier 等讓線程按順序執行
- 異步(Asynchronous)
特點:
調用者 不等待操作完成,可以繼續執行其他任務
操作結果通過回調、Future、Promise、事件通知等方式獲取
例子:
異步 HTTP 請求、異步消息隊列消費、CompletableFuture
- 并發(Concurrency)
定義:多個任務在同一時間段交替進行執行
特點:
不要求同時執行(同時執行是并行 Parallelism)
利用 CPU 時間片輪轉等機制交替執行
例子:
多線程訪問 CPU → 在時間上交錯執行
操作系統調度多個進程 → 并發處理
12. 如何實現線程間同步?常見同步問題?
線程間同步主要是為了保護共享資源,防止數據競爭。常用方法有:基于鎖的同步(synchronized、ReentrantLock)、信號量(Semaphore)、條件變量或阻塞隊列(wait/notify, BlockingQueue)、原子操作(Atomic 類或 CAS)、屏障/閉鎖(CountDownLatch, CyclicBarrier)等。根據場景選擇最合適的方式。
13. 死鎖是什么?死鎖條件?死鎖檢測和解除?預防死鎖的方式?
- 死鎖條件(必要條件):
- 互斥
- 占有并等待
- 不可剝奪
- 循環等待
- 避免死鎖:破壞上述條件之一。
- 預防死鎖:如一次性申請所有資源、資源有序分配。
- 死鎖檢測與解除:
- 檢測:通過資源分配圖、銀行家算法。
- 解除:撤銷進程或搶占資源。
- 死鎖定義:多個進程因競爭資源互相等待,無法繼續執行。
14. 資源分配圖
- 節點:
- 圓形:表示進程(P1, P2…)
- 方形 / 長方形:表示資源(R1, R2…)
- 邊:
- 請求邊(→):進程指向資源,表示進程請求該資源
- 分配邊(←):資源指向進程,表示資源已分配給該進程
- 無環 → 系統安全,無死鎖
- 有環(單實例資源) → 系統發生死鎖
- 有環(多實例資源) → 可能死鎖,需要進一步分析
- 單實例資源:每類資源在系統中只有一個可用單位。
- 例子:打印機、CPU、磁帶機
- 多實例資源:每類資源有多個單位可用。
- 例子:內存頁框、多個相同型號打印機、數據庫連接池
15. 什么是緩沖區?
緩沖區就是在生產者和消費者之間開的一塊臨時存儲區。生產者(快的)生成數據后不必等待消費者(慢的)處理完,直接放入緩沖區去做其他事情;消費者則可以按自己的速度從緩沖區取數據處理。這樣解決了速度不匹配的問題,同時避免了直接阻塞。
16. 中斷與輪詢的區別?中斷與系統調用區別?
輪詢是CPU主動周期性檢查設備狀態,低效且可能延遲;中斷是設備或事件主動通知CPU,CPU只在需要時處理,效率高、響應快。中斷機制是現代操作系統的主要I/O處理方式。
中斷是異步的,因為它的觸發時間不可預測,由外部設備或異常事件主動產生,不依賴CPU或程序主動調用。CPU在執行程序時,隨時可能被中斷打斷去執行中斷服務程序,因此中斷是異步的。
系統調用是用戶程序主動請求操作系統服務的過程,CPU 在系統調用指令處順序切換到內核態執行,不會突然中斷其他任務;調用完成后返回用戶態繼續執行原程序。與中斷不同,中斷是異步事件,會打斷 CPU 當前執行的程序
17. 文件的索引結構?
文件索引結構用于管理文件在磁盤上的塊分配,常見的有連續分配(簡單快速,但容易產生外部碎片)、鏈式分配(消除外部碎片,但隨機訪問慢)、索引分配(建立索引塊支持隨機訪問,可多級管理大文件。
a. (1) 連續分配(Contiguous Allocation)
- 文件占用磁盤上 連續的塊
- 優點:隨機訪問快,索引簡單
- 缺點:容易產生外部碎片,文件擴展困難
- 索引表示:
文件名 → 起始塊號 + 文件長度b. (2) 鏈式分配(Linked Allocation)
- 文件的每個塊包含 下一個塊的指針
- 優點:消除外部碎片,文件可動態增長
- 缺點:隨機訪問慢,需要順序遍歷
- 索引表示:
塊1 → 塊2 → 塊3 → … → 塊nc. (3) 索引分配(Indexed Allocation)
- 每個文件有一個 索引塊,記錄文件所有塊號
- 優點:支持隨機訪問,不要求連續空間
- 缺點:索引塊占用額外空間
- 多級索引:
- 單級:索引塊直接記錄文件塊號
- 多級:索引塊指向其他索引塊 → 支持大文件
- 示例:UNIX i-node
i-node:
直接塊 0~11 → 文件塊
一級間接塊 → 指向文件塊
二級間接塊 → 指向一級索引塊
三級間接塊 → 支持超大文件18. 僵尸進程與孤兒進程?
僵尸進程是子進程已退出,但父進程未回收其 PCB,導致占用少量系統資源;孤兒進程是父進程先退出,子進程仍在運行,系統會由 init 進程收養并回收。僵尸進程需要父進程主動回收,孤兒進程系統自動處理。
19. 熱備份與冷備份?
熱備份是在系統運行過程中進行備份,用戶可以繼續訪問系統,但需要考慮數據一致性問題;冷備份是在系統停機時備份,操作簡單、天然一致,但會中斷業務。熱備份適合高可用場景,冷備份適合低頻全量備份。
- 熱備份:
- 數據庫正在處理用戶請求,同時用快照或日志復制數據
- MySQL InnoDB 在線備份、Oracle RMAN 在線備份
- 冷備份:
- 停掉數據庫服務 → 復制整個數據庫文件
- 簡單、可靠,但會造成服務停機
20. 常用的編譯優化技術
a. (1) 代碼生成優化
- 常量折疊(Constant Folding)
- 編譯期計算常量表達式
- 示例:
int a = 3 + 4;→ 編譯器直接生成int a = 7;
- 常量傳播(Constant Propagation)
- 將已知常量替換到表達式中,提高編譯效率
- 冗余代碼消除(Dead Code Elimination)
- 刪除永遠不會執行或結果不影響程序的代碼
b. (2) 循環優化
- 循環展開(Loop Unrolling)
- 減少循環控制開銷,提高執行效率
- 循環交換(Loop Interchange)
- 調整多重循環順序,提高緩存命中率
- 循環合并/拆分(Loop Fusion/Splitting)
- 合并相似循環減少開銷,或拆分循環提高并行性
c. (3) 數據流優化
- 公共子表達式消除(Common Subexpression Elimination, CSE)
- 避免重復計算同一表達式
- 強度降低(Strength Reduction)
- 用位運算或加法替換乘法/除法等昂貴操作
- 寄存器分配優化(Register Allocation)
- 盡量將頻繁訪問的變量放入寄存器
d. (4) 內存與訪問優化
- 內存對齊與緩存優化
- 調整數據布局,提高 CPU cache 命中率
- 延遲加載(Lazy Evaluation)
- 只有真正需要時才計算或訪問數據
e. (5) 函數與調用優化
- 內聯展開(Function Inlining)
- 減少函數調用開銷
- 尾遞歸優化(Tail Recursion Optimization)
- 將尾遞歸轉換為循環,減少棧空間
f. (6) 并行與向量化優化
- 自動向量化(SIMD)
- 編譯器將循環或操作轉為并行向量指令
- 多線程/并行優化
- 利用 CPU 多核加速循環或獨立計算


















![[嵌入式][stm32h743iit6] 野火繁星stm32h743iit6開發板使用學習記錄](http://pic.xiahunao.cn/[嵌入式][stm32h743iit6] 野火繁星stm32h743iit6開發板使用學習記錄)
