概述
ModelScope,簡稱MS,魔搭社區,由阿里巴巴達摩院推出的一個多任務、多模態的預訓練模型開放平臺,提供模型下載與運行、數據集管理、在線推理體驗、開發者社區交流等一站式服務,支持多種主流框架(如PyTorch、Transformers)。整體上它的定位類似于HuggingFace(HF),但在多模態支持、國產模型整合和本地化適配方面做得更加貼近國內開發者的使用需求。
Web
https://modelscope.cn/home,很奇怪為啥不能注冊:
功能包括:模型庫、數據集、創空間、AIGC專區、文檔、社區(合集、論文、研習社
公告、競賽、交流區)、MCP廣場。

其中AIGC專區是一個大雜燴,功能定位類似于:ComfyUI、liblib、
模型下載及使用
下載模型的兩種方式:
# 命令行
modelscope download --model="Qwen/Qwen2.5-0.5B-Instruct" --local_dir ./model-dir
# Python SDK,支持更多個性化配置,如只下載特定文件、跳過某些組件等
from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-0.5B-Instruct', local_dir = './model-dir')
實例:
from modelscope import AutoModelForCausalLM, AutoTokenizermodel_name = "輸入本地文件夾路徑"
# 從預訓練模型加載因果語言模型和分詞器
# 模型會根據可用硬件自動選擇精度(torch_dtype="auto")并進行設備分配(device_map="auto")
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)# 構建對話歷史,包含系統角色和用戶角色的消息
messages = [{"role": "system", "content": "你是一個有用的助手"}, # 系統消息設定助手的行為模式{"role": "user", "content": "請簡單介紹一下大語言模型"}
]# 將對話歷史轉換為模型可接受的文本格式
text = tokenizer.apply_chat_template(messages,tokenize=False, # 表示不直接分詞,而是保留文本形式add_generation_prompt=True # 添加模型特定的生成提示標記
)
# 使用分詞器將文本轉換為模型所需的張量格式,并移至與模型相同的設備
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)# 模型生成回答
generated_ids = model.generate(**model_inputs,max_new_tokens=512
)
# 從生成的token ID序列中提取出模型生成的部分(去掉輸入部分)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
# 將生成的token ID序列解碼為文本,并跳過特殊標記(如填充標記、結束標記等)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
MS Hub
即ModelScope的模型庫,共享機器學習模型、demo演示、數據集和數據指標的地方。
模型公開屬性:
- 公開模型:社區所有人可見、可下載;
- 非公開模型:私有模型,僅組織成員或模型所有者可見、可下載;
- 申請制模型:任意用戶均可在按照要求發起申請、并經模型所有者審批同意后可見、可下載。
MS-SWIFT
Scalable lightWeight Infrastructure for Fine-Tuning,魔搭社區推出的一套完整的輕量級量化、訓練、推理、評估、部署工具。支持200+LLM、15+多模態大模型、10+輕量化Tuners,支持消費級顯卡玩轉LLM和AIGC。
特性:
- 具備SOTA特性的Efficient Tuners:可結合LLM在商業級顯卡上實現輕量級訓練和推理。
- 使用MS Hub的Trainer:基于Transformers Trainer提供,支持LLM訓練,且能將訓練后的模型上傳到MS Hub中。
- 可運行的模型Examples:針對熱門大模型提供訓練腳本和推理腳本,同時針對熱門開源數據集提供預處理邏輯,可直接運行使用。
- 支持界面化訓練和推理:基于Gradio Web界面,簡化大模型全鏈路流程。
安裝
pip install ms-swift
# 或pip install git+https://github.com/modelscope/ms-swift.git,或
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .
微調數據集示例:
{"messages": [{"role": "user", "content": "浙江的省會在哪?"}, {"role": "assistant", "content": "<think>\nxxx\n</think>\n\n浙江的省會在杭州。"}]}
GRPO訓練數據集示例:
- LLM類型:
{"messages": [{"role": "user", "content": "What is your name?"}]}
- MLLM類型:
{"messages": [{"role": "user", "content": "<image><image>What is the difference between the two images?"}], "images": ["/xxx/y.jpg", "/xxx/z.png"]}
Lora微調
- 訓練顯存要求為22GB。
- 可指定
--dataset AI-ModelScope/alpaca-gpt4-data-zh來跑通實驗。 - 訓練命令:
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Qwen/Qwen3-8B \
--train_type lora \
--dataset '<dataset-path>' \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 4 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--packing true \
--user_liger_kernel true
GRPO訓練
硬件要求為70G*8,訓練命令:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
NPROC_PER_NODE=8 \
swift rlhf \
--rlhf_type grpo \
--model Qwen/Qwen3-8B \
--train_type full \
--dataset AI-MO/NuminaMath-TIR \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 2 \
--learning_rate 1e-6 \
--save_total_limit 2 \
--logging_steps 5 \
--output_dir output \
--gradient_accumulation_steps 1 \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--max_completion_length 4096 \
--vllm_max_model_len 8192 \
--reward_funcs accuracy \
--num_generations 16 \
--use_vllm true \
--vllm_gpu_memory_utilization 0.4 \
--sleep_level 1 \
--offload_model true \
--offload_optimizer true \
--gc_collect_after_offload true \
--deepspeed zero3 \
--num_infer_workers 8 \
--tensor_parallel_size 1 \
--temperature 1.0 \
--top_p 0.85 \
--report_to wandb \
--log_completions true \
--overlong_filter true
Megatron并行訓練
引入Megatron的并行技術來加速大模型的訓練,包括數據并行、張量并行、流水線并行、序列并行,上下文并行,專家并行。支持Qwen3等模型的預訓練和微調。
訓練命令:
NNODES=$WORLD_SIZE \
NODE_RANK=$RANK \
megatron sft \
--load Qwen3-30B-A3B-Base-mcore \
--dataset 'liucong/Chinese-DeepSeek-R1-Distill-data-110k-SFT' \
--tensor_model_parallel_size 2 \
--expert_model_parallel_size 8 \
--moe_grouped_gemm true \
--moe_shared_expert_overlap true \
--moe_aux_loss_coeff 0.01 \
--micro_batch_size 1 \
--global_batch_size 16 \
--packing true \
--recompute_granularity full \
--recompute_method uniform \
--recompute_num_layers 1 \
--train_iters 2000 \
--eval_iters 50 \
--finetune true \
--cross_entropy_loss_fusion true \
--lr 1e-5 \
--lr_warmup_iters 100 \
--min_lr 1e-6 \
--save megatron_output/Qwen3-30B-A3B-Base \
--eval_interval 200 \
--save_interval 200 \
--max_length 8192 \
--num_workers 8 \
--dataset_num_proc 8 \
--no_save_optim true \
--no_save_rng true \
--sequence_parallel true \
--use_flash_attn true
MS-EvalScope
開源模型評估框架,旨在為LLM和多模態模型提供統一、系統化的性能評估方案。具備高度的自動化和可擴展性,適用于研究機構、工業界以及模型開發者在模型驗證與性能對比場景中的廣泛需求。
特點
- 豐富的評測基準覆蓋:內置多種權威評測數據集,涵蓋中英文通用知識問答、數學推理、常識判斷、代碼生成等多個方向,支持多維度評估。
- 多樣的評估模式支持:提供單模型評估模式(Single)、基于基線的兩兩對比模式(Pairwise-Baseline)、全模型兩兩對比模式(Pairwise-All),滿足不同使用場景。
- 統一的模型接入接口:對不同類型的模型提供統一調用方式,兼容HF、本地部署模型及API遠程調用,降低模型集成復雜度。
- 評估流程高度自動化:實現評測任務全自動執行,包括客觀題自動打分、復雜問題使用評審模型輔助判定結果等,支持批量評估與日志記錄。
- 完善的可視化工具:支持生成詳細評估報告和圖表,展示模型在不同任務維度下的表現,便于橫向對比和性能分析。
- 多后端與評測能力擴展:可集成多個評測后端,支持從單模態到多模態、從語言建模到RAG端到端評測的全鏈路能力。
- 支持部署性能測試:提供服務端推理性能測試工具,涵蓋吞吐量、響應時延等關鍵指標,幫助評估模型部署實用性。
MS-Agent
GitHub,文檔,論文,ModelScopeGPT體驗地址,已停止維護,生成有問題。
MS-Agent是魔搭社區打造的開源多模態多智能體系統。
特點:
- 可定制且功能全面的框架,提供可定制化的引擎、數據集收集、工具檢索與注冊、存儲處理、定制模型訓練和應用開發等功能,可快速應用于實際場景。
- 以開源LLM為核心組件,支持各種文本或多模態大模型。
- 支持多樣化且全面的API開發。
架構
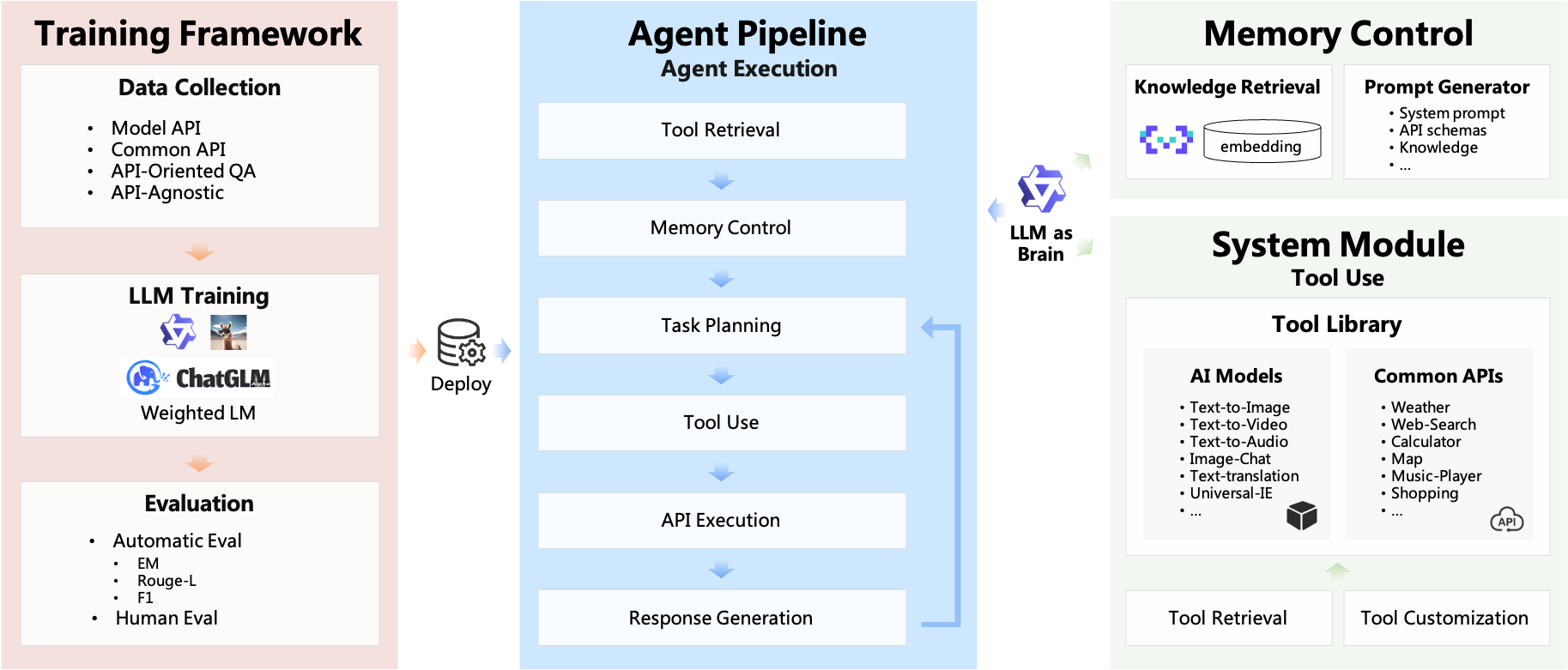
AgentExecutor對象包含以下組件:
LLM:負責處理輸入并決定調用哪些工具;tool_list:由代理可使用的工具組成的列表;PromptGenerator:將prompt_template、user_input、history、tool_list…整合為高效的提示;OutputParser:用于解析LLM響應,確定要調用的工具及其相應參數。
安裝
git clone https://github.com/modelscope/ms-agent.git
cd modelscope-agent && pip install -r requirements.txt
或:pip install modelscope_agent
文本轉語音工具:
from modelscope_agent.tools import ModelscopePipelineTool
from modelscope.utils.constant import Tasks
from modelscope_agent.output_wrapper import AudioWrapperclass TextToSpeechTool(ModelscopePipelineTool):default_model = 'damo/speech_sambert-hifigan_tts_zh-cn_16k'description = '文本轉語音服務,將文字轉換為自然而逼真的語音,可配置男聲/女聲'name = 'modelscope_speech-generation'parameters: list = [{'name': 'input','description': '要轉成語音的文本','required': True}, {'name': 'gender','description': '用戶身份','required': True}]task = Tasks.text_to_speechdef _remote_parse_input(self, *args, **kwargs):if 'gender' not in kwargs:kwargs['gender'] = 'man'voice = 'zhibei_emo' if kwargs['gender'] == 'man' else 'zhiyan_emo'kwargs['parameters'] = voicekwargs.pop('gender')return kwargsdef _parse_output(self, origin_result, remote=True):audio = origin_result['output_wav']return {'result': AudioWrapper(audio)}
文本地址解析工具
from modelscope_agent.tools import ModelscopePipelineTool
from modelscope.utils.constant import Tasksclass TextAddressTool(ModelscopePipelineTool):default_model = 'damo/mgeo_geographic_elements_tagging_chinese_base'description = '地址解析服務,針對中文地址信息,識別出里面的元素,包括省、市、區、鎮、社區、道路、路號、POI、樓棟號、戶室號等'name = 'modelscope_text-address'parameters: list = [{'name': 'input','description': '用戶輸入的地址信息','required': True}]task = Tasks.token_classificationdef _parse_output(self, origin_result, *args, **kwargs):final_result = {}for e in origin_result['output']:final_result[e['type']] = e['span']return final_result
集成LangChain:
from modelscope_agent.tools import LangchainTool
from langchain_community.tools import ShellTool, ReadFileTool# 包裝一下
shell_tool = LangchainTool(ShellTool())
print(shell_tool(commands=["echo 'Hello World!'", "ls"]))
數據集
MSAgent-Bench:綜合性工具數據集,包含59.8萬個對話,涵蓋模型API、通用API、面向API的QA對、API無關指令。
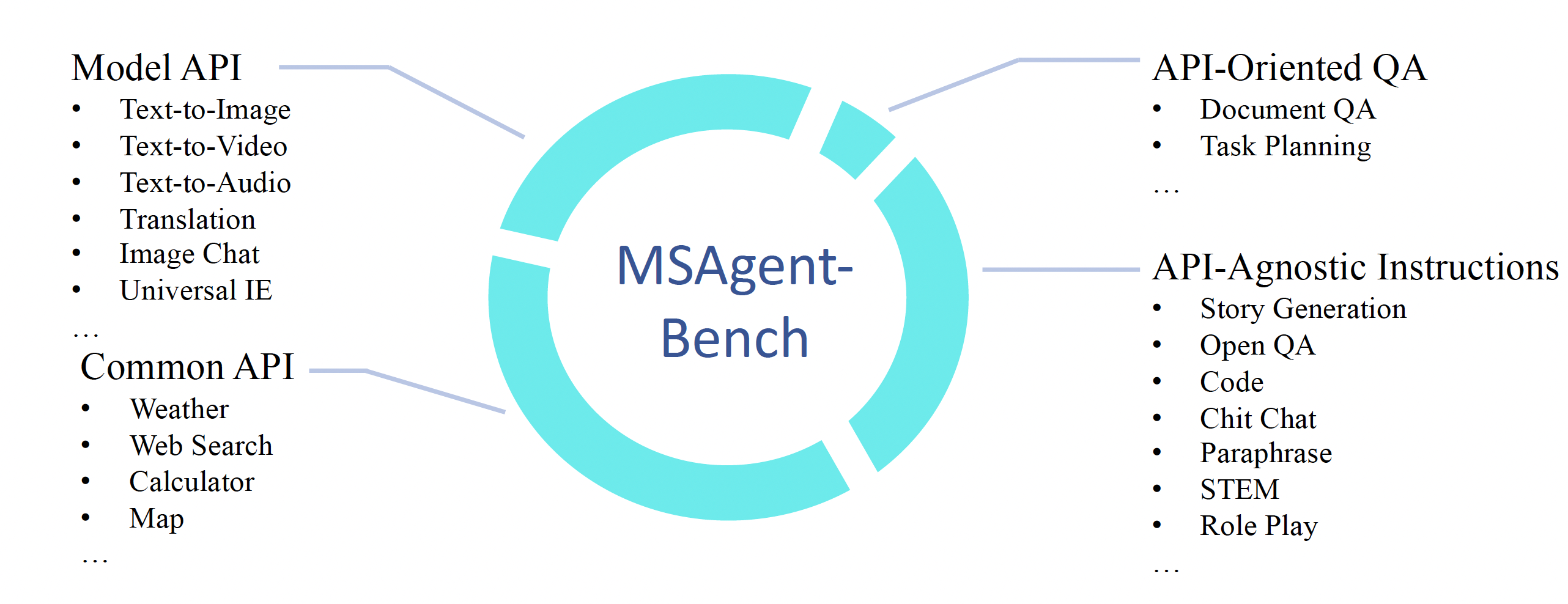
評估包含下面四個維度:
- 插件調用的準確率:識別
api_name是否正確; - 插件url的準確率:URL地址是否正確;
- 插件傳入參數的準確率:parameters對應參數是否正確;
- 插件整體的準確率:生成的Function Calling是否完全正確,整個JSON可以被加載的格式。
MSAgent-MultiRole:在MSAgent-Bench基礎上,增加多角色扮演數據集,提升開源LLM作為中樞來做多角色扮演實現多角色聊天的能力。
下載方式:
- 頁面下載
- SDK
import ast
from modelscope.msdatasets import MsDatasetds = MsDataset.load('damo/MSAgent-Bench', split='train') # or split='validation'
one_ds = next(iter(ds))
print(one_ds)
# to parse conversations value
conv = one_ds['conversations']
conv = ast.literal_eval(conv)
print(conv[0]['from'])
print(conv[0]['value'])
參考
- MSAgent-Bench


——多肽+蛋白質一級結構)

)




Modbus)


)
- Weblogic SSRF漏洞)


)

)
