背景意義
隨著城市化進程的加快,公共交通系統的需求日益增加,公交車作為城市交通的重要組成部分,其運行效率和安全性直接影響到城市的交通狀況和居民的出行體驗。因此,公交車的維護和管理顯得尤為重要。在這一背景下,公交車部件的實例分割技術應運而生,成為提升公交車管理智能化水平的重要手段。通過對公交車各個部件進行精準的實例分割,可以實現對公交車狀態的實時監控,及時發現潛在的故障和安全隱患,從而提高公交車的運行安全性和可靠性。
本研究旨在基于改進的YOLOv11模型,構建一個高效的公交車部件實例分割系統。YOLO(You Only Look Once)系列模型因其快速和準確的特性,廣泛應用于目標檢測和實例分割任務。YOLOv11作為該系列的最新版本,具備更強的特征提取能力和更高的檢測精度,適合處理復雜的公交車部件圖像數據。我們將利用一個包含1000張公交車部件圖像的數據集,數據集中涵蓋了門、車牌、車輪等8個類別的部件,提供了豐富的實例分割訓練樣本。
通過對該數據集的深入分析和處理,我們期望能夠提高模型在公交車部件實例分割任務中的表現,進而為公交車的智能監控和管理提供技術支持。此外,研究成果不僅有助于公交車行業的智能化發展,也為其他交通工具的部件監測提供了借鑒,推動整個交通領域的技術進步。因此,本項目的研究具有重要的理論意義和廣泛的應用前景。
圖片效果
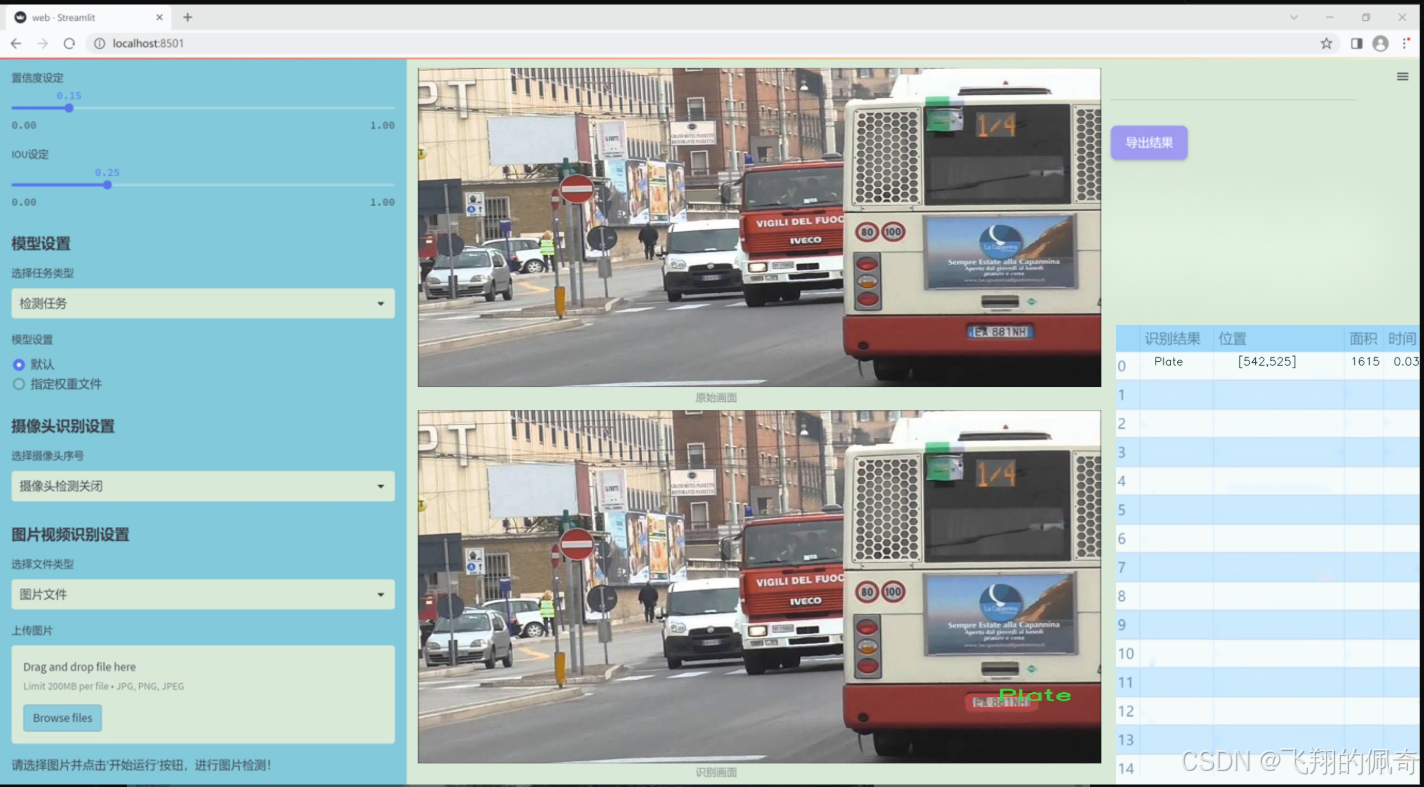
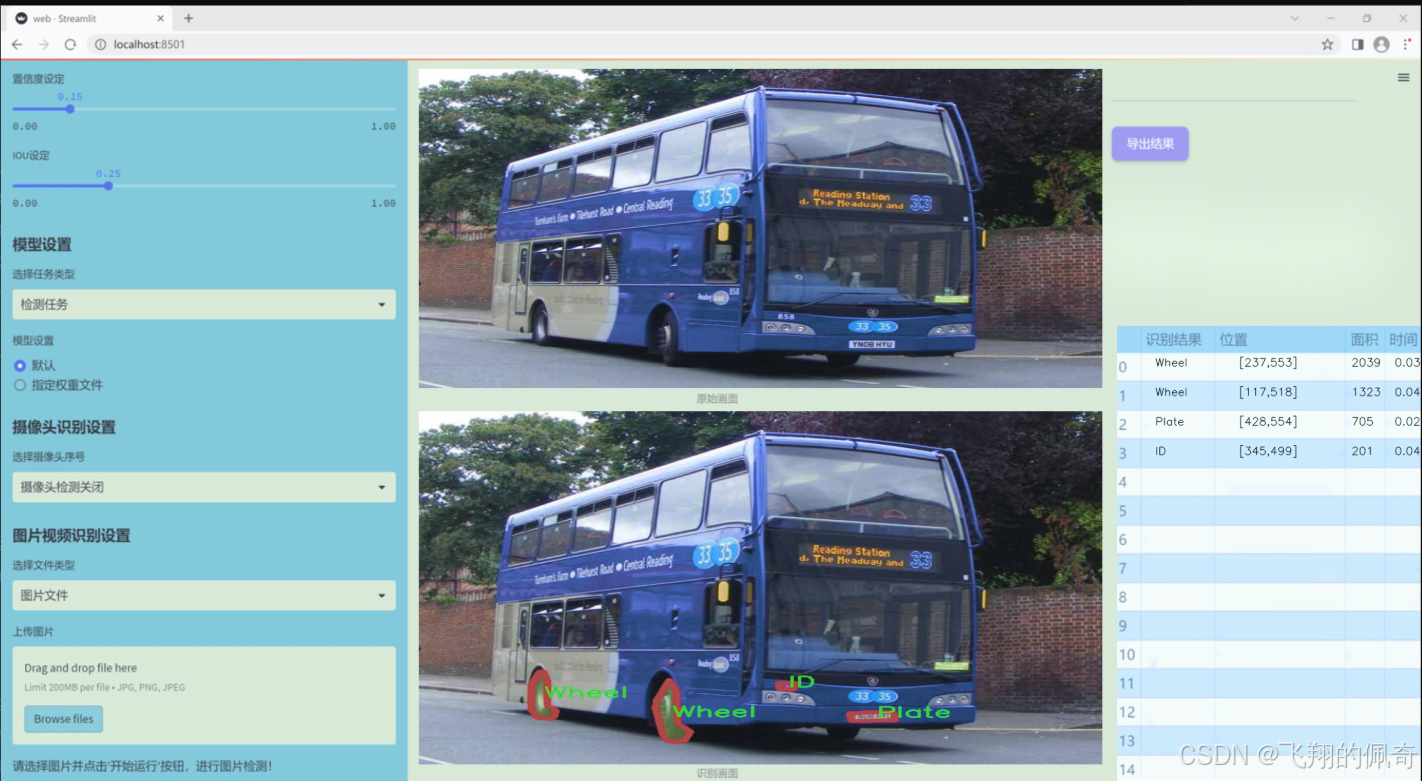
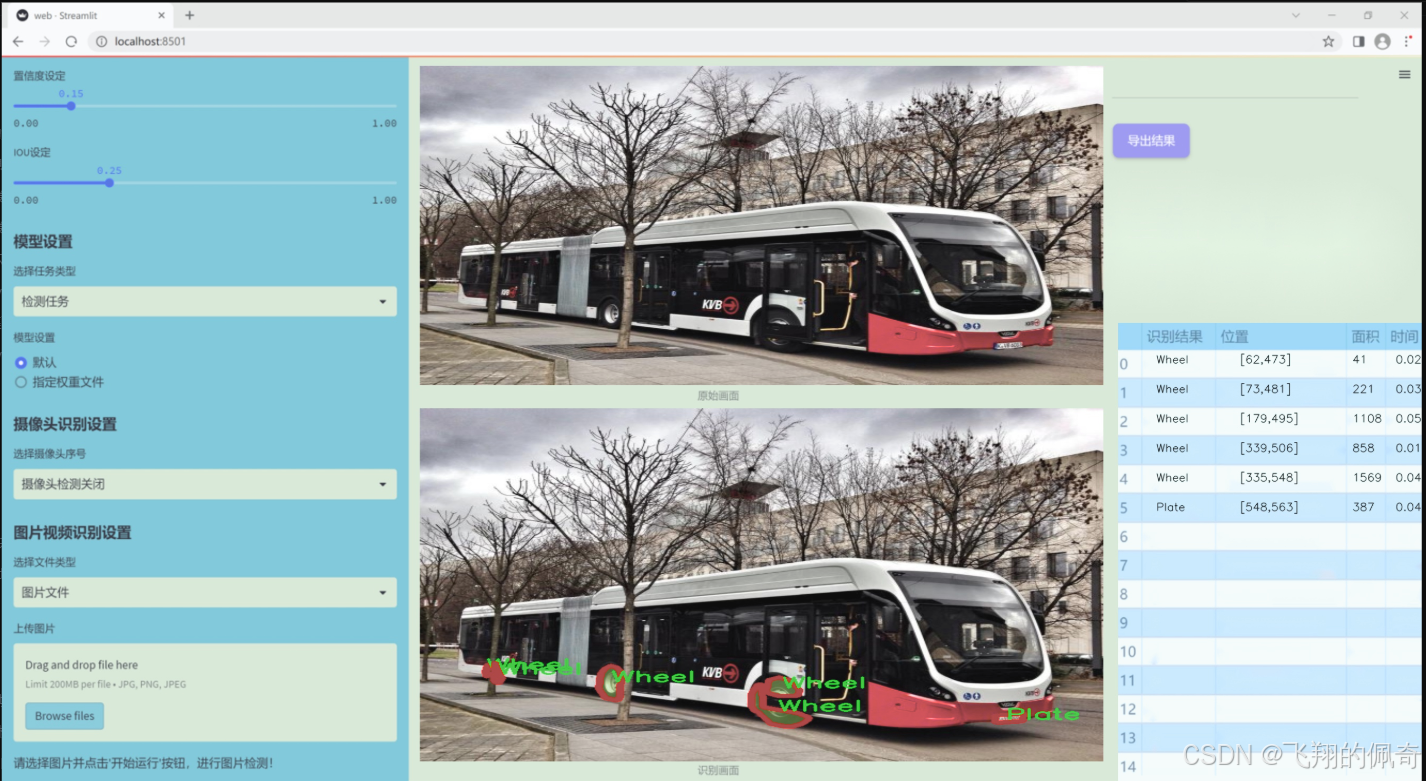
數據集信息
本項目數據集信息介紹
本項目所使用的數據集名為“BusPartsSegmentation”,旨在為改進YOLOv11的公交車部件實例分割系統提供支持。該數據集專注于公交車的關鍵部件,涵蓋了四個主要類別,分別是“Door”(門)、“ID”(標識牌)、“Plate”(車牌)和“Wheel”(輪胎)。這些類別的選擇不僅反映了公交車的基本構造特征,也為實例分割任務提供了豐富的標注信息。
在數據集的構建過程中,我們收集了大量公交車的圖像,確保涵蓋不同品牌、型號及顏色的公交車,以增強模型的泛化能力。每個圖像均經過精細標注,確保每個部件的邊界清晰可辨。通過對公交車各個部件的精確標注,數據集能夠有效支持模型在復雜場景下的學習,提升其對公交車部件的識別和分割能力。
此外,數據集的多樣性也為模型訓練提供了堅實的基礎。我們確保數據集中包含了不同光照條件、天氣狀況和拍攝角度下的公交車圖像,這將有助于模型在實際應用中應對各種環境變化。通過對這些數據的充分利用,模型能夠更好地理解公交車部件的形狀、顏色和位置,從而實現更高精度的實例分割。
總之,“BusPartsSegmentation”數據集不僅為YOLOv11的改進提供了必要的訓練素材,也為未來公交車相關研究提供了寶貴的數據支持。通過對該數據集的深入分析和應用,我們期望能夠推動公交車部件實例分割技術的發展,為智能交通系統的實現奠定基礎。





核心代碼
以下是經過簡化和注釋的核心代碼部分:
import torch
import torch.nn.functional as F
def build_selective_scan_fn(selective_scan_cuda: object = None, mode=“mamba_ssm”):
“”"
構建選擇性掃描函數的工廠函數。
參數:
selective_scan_cuda: CUDA實現的選擇性掃描函數
mode: 模式選擇
"""class SelectiveScanFn(torch.autograd.Function):@staticmethoddef forward(ctx, u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False, return_last_state=False):"""前向傳播函數,計算選擇性掃描的輸出。參數:ctx: 上下文對象,用于保存狀態u: 輸入張量delta: 變化率張量A, B, C: 權重張量D: 可選的額外張量z: 可選的門控張量delta_bias: 可選的偏置delta_softplus: 是否使用softplus激活return_last_state: 是否返回最后狀態返回:輸出張量或輸出和最后狀態的元組"""# 確保輸入張量是連續的if u.stride(-1) != 1:u = u.contiguous()if delta.stride(-1) != 1:delta = delta.contiguous()if D is not None:D = D.contiguous()if B.stride(-1) != 1:B = B.contiguous()if C.stride(-1) != 1:C = C.contiguous()if z is not None and z.stride(-1) != 1:z = z.contiguous()# 調用CUDA實現的前向函數out, x, *rest = selective_scan_cuda.fwd(u, delta, A, B, C, D, z, delta_bias, delta_softplus)# 保存必要的張量以用于反向傳播ctx.save_for_backward(u, delta, A, B, C, D, z, delta_bias, x)# 返回輸出或輸出和最后狀態last_state = x[:, :, -1, 1::2] # 獲取最后狀態return out if not return_last_state else (out, last_state)@staticmethoddef backward(ctx, dout):"""反向傳播函數,計算梯度。參數:ctx: 上下文對象,包含前向傳播中保存的狀態dout: 輸出的梯度返回:輸入張量的梯度"""# 從上下文中恢復保存的張量u, delta, A, B, C, D, z, delta_bias, x = ctx.saved_tensors# 調用CUDA實現的反向函數du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda.bwd(u, delta, A, B, C, D, z, delta_bias, dout, x)return du, ddelta, dA, dB, dC, dD, None, ddelta_bias, Nonedef selective_scan_fn(u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False, return_last_state=False):"""封裝選擇性掃描函數的調用。參數:u, delta, A, B, C, D, z, delta_bias, delta_softplus, return_last_state: 同上"""return SelectiveScanFn.apply(u, delta, A, B, C, D, z, delta_bias, delta_softplus, return_last_state)return selective_scan_fn
示例使用
selective_scan_fn = build_selective_scan_fn()
代碼說明:
build_selective_scan_fn: 這是一個工廠函數,用于創建選擇性掃描的前向和反向傳播函數。
SelectiveScanFn: 這是一個自定義的PyTorch自動求導函數,包含前向和反向傳播的實現。
forward: 計算選擇性掃描的輸出,并保存需要在反向傳播中使用的張量。
backward: 計算輸入張量的梯度,使用保存的張量和輸出的梯度進行計算。
selective_scan_fn: 封裝了對SelectiveScanFn的調用,提供一個簡單的接口。
這個簡化版本保留了選擇性掃描的核心邏輯,并提供了詳細的中文注釋以幫助理解每個部分的功能。
這個程序文件 test_selective_scan.py 主要用于實現和測試一個選擇性掃描(Selective Scan)功能,通常在深度學習和序列建模中使用。文件中包含了多個函數和類,以下是對其主要內容的逐步講解。
首先,文件導入了一些必要的庫,包括 torch、torch.nn.functional、pytest 等。torch 是 PyTorch 的核心庫,提供了張量操作和深度學習的基本功能。
接下來,定義了一個函數 build_selective_scan_fn,它接受一個 CUDA 選擇性掃描的實現和一些參數,返回一個選擇性掃描的函數。這個函數內部定義了一個 SelectiveScanFn 類,繼承自 torch.autograd.Function,用于實現前向和反向傳播的計算。
在 SelectiveScanFn 類中,forward 方法實現了選擇性掃描的前向計算。它接收多個輸入參數,包括 u、delta、A、B、C 等,分別代表不同的輸入張量。該方法首先確保輸入張量是連續的,并根據輸入的維度進行適當的重排。然后,它調用 CUDA 實現的前向函數,計算輸出,并保存必要的中間狀態以供反向傳播使用。
backward 方法實現了反向傳播的計算。它根據前向計算中保存的狀態,計算各個輸入的梯度,并返回這些梯度。這里的實現考慮了多種模式(如 mamba_ssm、ssoflex 等),每種模式對應不同的 CUDA 實現。
此外,文件中還定義了兩個參考實現函數 selective_scan_ref 和 selective_scan_ref_v2,它們使用純 PyTorch 實現選擇性掃描的邏輯。這些參考實現用于在測試中與 CUDA 實現的結果進行比較,以確保功能的正確性。
接下來,文件中定義了一個 selective_scan_fn 函數,它調用之前構建的選擇性掃描函數,并處理返回值的類型轉換。
在文件的最后部分,設置了一些參數和測試用例,并使用 pytest 框架定義了一個測試函數 test_selective_scan。這個測試函數使用不同的輸入配置,驗證選擇性掃描函數的輸出與參考實現的一致性,并檢查梯度的正確性。
整體來看,這個程序文件實現了選擇性掃描的功能,并通過測試確保了其正確性和性能,適用于深度學習中的序列數據處理。
10.4 repvit.py
以下是經過簡化和注釋的核心代碼部分:
import torch
import torch.nn as nn
from timm.models.layers import SqueezeExcite
def _make_divisible(v, divisor, min_value=None):
“”"
確保所有層的通道數是8的倍數。
:param v: 輸入值
:param divisor: 除數
:param min_value: 最小值
:return: 可被divisor整除的值
“”"
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v: # 確保不減少超過10%
new_v += divisor
return new_v
class Conv2d_BN(nn.Sequential):
“”"
包含卷積層和批歸一化層的組合模塊。
“”"
def init(self, in_channels, out_channels, kernel_size=1, stride=1, padding=0, dilation=1, groups=1):
super().init()
# 添加卷積層
self.add_module(‘conv’, nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias=False))
# 添加批歸一化層
self.add_module(‘bn’, nn.BatchNorm2d(out_channels))
@torch.no_grad()
def fuse_self(self):"""融合卷積層和批歸一化層為一個卷積層。"""conv, bn = self._modules.values()# 計算融合后的權重和偏置w = bn.weight / (bn.running_var + bn.eps)**0.5w = conv.weight * w[:, None, None, None]b = bn.bias - bn.running_mean * bn.weight / (bn.running_var + bn.eps)**0.5# 創建新的卷積層fused_conv = nn.Conv2d(w.size(1) * conv.groups, w.size(0), w.shape[2:], stride=conv.stride, padding=conv.padding, dilation=conv.dilation, groups=conv.groups)fused_conv.weight.data.copy_(w)fused_conv.bias.data.copy_(b)return fused_conv
class RepViTBlock(nn.Module):
“”"
RepViT模塊,包含token混合和通道混合。
“”"
def init(self, inp, hidden_dim, oup, kernel_size, stride, use_se, use_hs):
super(RepViTBlock, self).init()
self.identity = stride == 1 and inp == oup # 判斷是否為恒等映射
if stride == 2:
# 下采樣路徑
self.token_mixer = nn.Sequential(
Conv2d_BN(inp, inp, kernel_size, stride, (kernel_size - 1) // 2, groups=inp),
SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),
Conv2d_BN(inp, oup, ks=1, stride=1, pad=0)
)
self.channel_mixer = nn.Sequential(
Conv2d_BN(oup, 2 * oup, 1, 1, 0),
nn.GELU() if use_hs else nn.GELU(),
Conv2d_BN(2 * oup, oup, 1, 1, 0)
)
else:
# 保持分辨率路徑
assert(self.identity)
self.token_mixer = nn.Sequential(
Conv2d_BN(inp, inp, 3, 1, 1, groups=inp),
SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),
)
self.channel_mixer = nn.Sequential(
Conv2d_BN(inp, hidden_dim, 1, 1, 0),
nn.GELU() if use_hs else nn.GELU(),
Conv2d_BN(hidden_dim, oup, 1, 1, 0)
)
def forward(self, x):return self.channel_mixer(self.token_mixer(x))
class RepViT(nn.Module):
“”"
RepViT模型,包含多個RepViTBlock。
“”"
def init(self, cfgs):
super(RepViT, self).init()
self.cfgs = cfgs # 配置參數
layers = []
input_channel = cfgs[0][2] # 第一個塊的輸入通道數
# 構建網絡層
for k, t, c, use_se, use_hs, s in self.cfgs:
output_channel = _make_divisible(c, 8)
exp_size = _make_divisible(input_channel * t, 8)
layers.append(RepViTBlock(input_channel, exp_size, output_channel, k, s, use_se, use_hs))
input_channel = output_channel
self.features = nn.ModuleList(layers)
def forward(self, x):for f in self.features:x = f(x)return x
def repvit_m2_3(weights=‘’):
“”"
構建RepViT模型的特定配置。
“”"
cfgs = [
# k, t, c, SE, HS, s
[3, 2, 80, 1, 0, 1],
# … 省略其他配置
]
model = RepViT(cfgs)
if weights:
model.load_state_dict(torch.load(weights)[‘model’])
return model
if name == ‘main’:
model = repvit_m2_3(‘repvit_m2_3_distill_450e.pth’) # 加載模型
inputs = torch.randn((1, 3, 640, 640)) # 隨機輸入
res = model(inputs) # 前向傳播
for i in res:
print(i.size()) # 輸出每層的尺寸
代碼注釋說明:
_make_divisible: 確保通道數是8的倍數,以便于后續處理。
Conv2d_BN: 定義了一個包含卷積和批歸一化的模塊,提供了融合功能以優化模型。
RepViTBlock: 該模塊實現了RepViT的基本構建塊,包含token混合和通道混合的邏輯。
RepViT: 該類構建了整個RepViT模型,包含多個RepViTBlock。
repvit_m2_3: 用于構建特定配置的RepViT模型,并可選擇加載預訓練權重。
通過這些注釋,代碼的結構和功能更加清晰易懂。
這個程序文件 repvit.py 實現了一個基于 RepVGG 結構的視覺模型,結合了深度學習中的卷積神經網絡(CNN)和注意力機制。文件中包含多個類和函數,用于構建和操作這個模型。
首先,文件導入了必要的庫,包括 PyTorch 和 NumPy,以及 timm 庫中的 SqueezeExcite 層。接著,定義了一個名為 replace_batchnorm 的函數,用于替換模型中的 BatchNorm 層為 Identity 層,以便在推理時加速計算。
接下來,定義了一個 _make_divisible 函數,確保每一層的通道數是可被 8 整除的,這對于某些模型的優化是必要的。
Conv2d_BN 類是一個自定義的模塊,結合了卷積層和 BatchNorm 層,并在初始化時對 BatchNorm 的權重進行常數初始化。該類還實現了一個 fuse_self 方法,用于將卷積層和 BatchNorm 層融合為一個卷積層,以提高推理速度。
Residual 類實現了殘差連接的功能,允許輸入和輸出相加,同時支持在訓練時進行隨機丟棄。它也實現了 fuse_self 方法,用于融合其內部的卷積層。
RepVGGDW 類實現了一個特定的卷積模塊,結合了深度可分離卷積和殘差連接。它的 forward 方法定義了前向傳播的計算過程,并實現了 fuse_self 方法以優化推理。
RepViTBlock 類則是模型的核心構建塊,結合了通道混合和令牌混合的操作。根據步幅的不同,構建不同的結構。
RepViT 類是整個模型的主類,負責構建模型的各個層。它接受一個配置列表,逐層構建網絡,并在 forward 方法中定義了輸入的前向傳播過程。switch_to_deploy 方法用于在推理階段替換 BatchNorm 層。
文件中還定義了多個函數(如 repvit_m0_9, repvit_m1_0 等),這些函數用于創建不同配置的 RepViT 模型,并可以加載預訓練的權重。
最后,在 main 塊中,程序創建了一個特定配置的模型實例,并對一個隨機輸入進行前向傳播,輸出每一層的特征圖大小。
整體而言,這個文件實現了一個靈活且高效的視覺模型,適用于圖像分類等任務,并通過模塊化設計使得模型的構建和修改變得更加方便。
源碼文件

源碼獲取
歡迎大家點贊、收藏、關注、評論啦 、查看👇🏻獲取聯系方式👇🏻



![[UT]記錄case中seq.start(sequencer)的位置變化帶來的執行行為的變化](http://pic.xiahunao.cn/[UT]記錄case中seq.start(sequencer)的位置變化帶來的執行行為的變化)
)

)












--從基本介紹,內部原理、應用場景、使用方法,常見問題和解決方案進行深度解析)