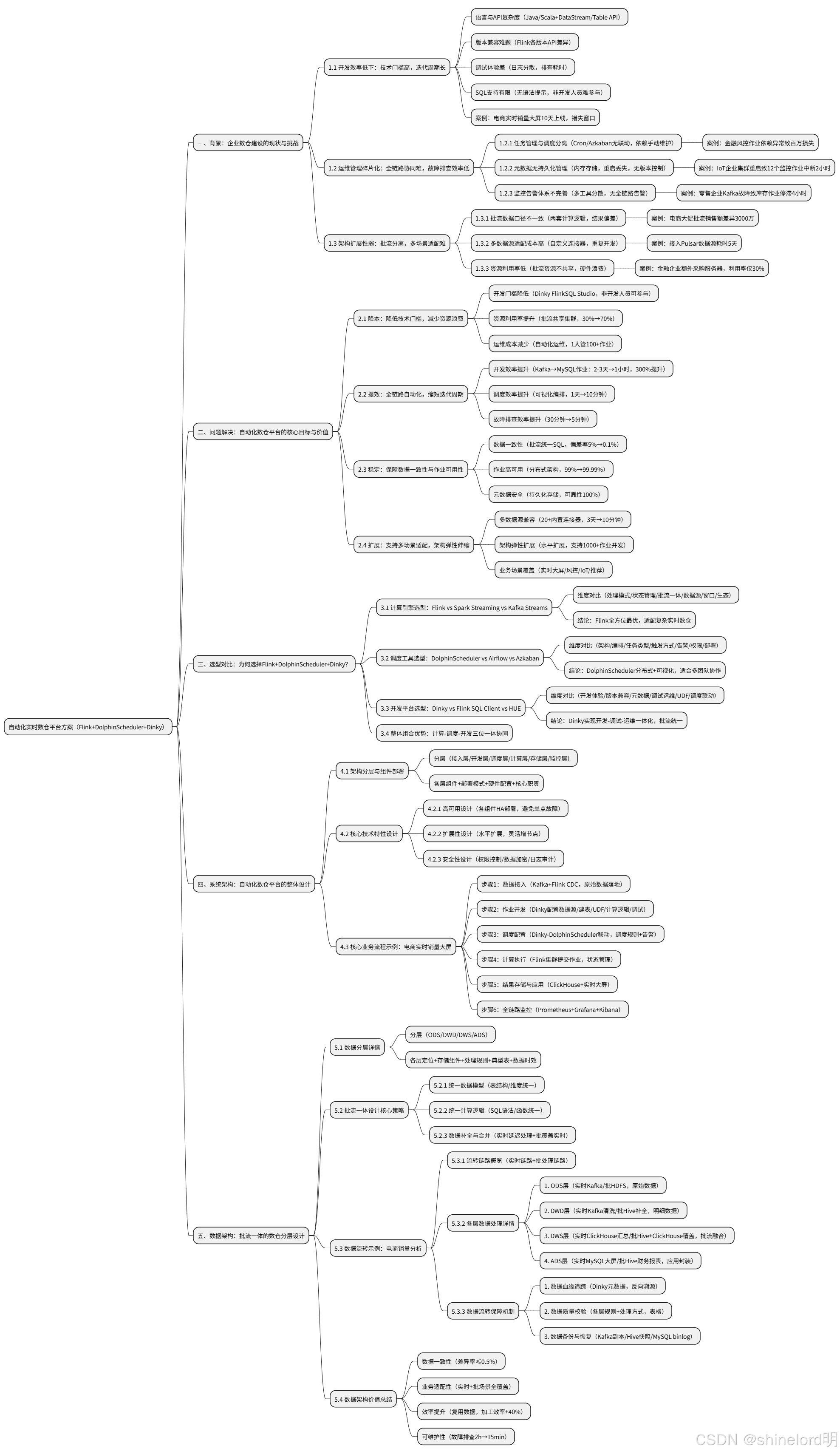
一、背景:企業數倉建設的現狀與挑戰
????????在數字化轉型進入深水區的今天,數據已成為企業核心生產要素,而實時數倉作為 “數據驅動決策” 的關鍵載體,其建設水平直接決定企業在市場競爭中的響應速度與決策精度。根據 IDC《2024 年全球大數據市場報告》,超過 78% 的企業將 “實時數據處理能力” 列為數字化轉型的核心目標,但在實際落地中,傳統數倉架構卻面臨一系列難以突破的瓶頸,這些瓶頸集中體現在 “開發、運維、架構” 三個維度,嚴重制約數倉價值的釋放。

1.1 開發效率低下:技術門檻高,迭代周期長
Apache Flink 作為當前實時計算領域的主流引擎,其強大的流處理能力與狀態管理機制已成為實時數倉的核心支撐。但 Flink 原生開發模式存在顯著的技術門檻,導致開發效率低下:
- 語言與 API 復雜度:原生 Flink 開發需掌握 Java/Scala 語言,且需熟悉 DataStream API、Table API 等復雜接口。以 “Kafka 數據清洗后寫入 MySQL” 為例,傳統開發需編寫至少 200 行代碼(含連接器配置、序列化 / 反序列化、狀態管理),開發周期長達 2-3 天,且需專人維護代碼版本;
- 版本兼容難題:Flink 各版本(如 1.17、1.18、1.19)間存在 API 差異(如 Kafka 連接器參數變化、狀態后端優化),企業若需升級 Flink 版本,需批量修改歷史作業代碼,適配成本極高;
- 調試體驗差:原生 Flink 調試依賴本地集群或遠程提交,日志分散在 TaskManager 節點,排查一個 “數據解析失敗” 問題需逐一查看節點日志,平均耗時 1-2 小時;
- SQL 支持有限:Flink SQL Client 僅提供命令行交互,無語法提示、格式化、血緣分析功能,非開發人員(如數據分析師)無法直接參與實時作業開發,需依賴開發團隊協作,進一步拉長迭代周期。
????????某電商企業案例顯示,傳統模式下,一個 “實時銷量大屏” 需求從開發到上線需 10 天(含需求溝通、代碼開發、調試、部署),而業務部門要求 “大促前 3 天緊急上線”,導致需求無法按時交付,錯失業務決策窗口。
1.2 運維管理碎片化:全鏈路協同難,故障排查效率低
????????實時數倉是 “數據采集→計算處理→存儲落地→監控告警” 的全鏈路體系,但傳統架構中,各環節工具脫節,形成 “數據孤島” 與 “運維孤島”,具體痛點如下:
1.2.1 任務管理與調度分離
- 傳統架構中,Flink 作業開發依賴 IDE(如 IntelliJ IDEA),調度依賴 Cron 腳本或簡單調度工具(如 Azkaban),兩者無聯動:
- 若上游數據源(如 Kafka)延遲,Cron 腳本仍會按時觸發 Flink 作業,導致作業讀取空數據,需手動重啟;
- 多個 Flink 作業存在依賴關系(如 “用戶行為計算作業→用戶畫像更新作業”),需手動維護依賴順序,易出現 “上游未完成,下游已執行” 的問題;
- 某金融企業曾因 “風控數據計算作業未完成,下游風險預警作業已執行”,導致漏判高風險交易,產生百萬級損失。
1.2.2 元數據無持久化管理
- Flink 原生元數據(表結構、UDF、數據源配置)存儲在內存中,會話結束或集群重啟后,所有元數據丟失:
- 運維人員需重新執行 DDL 語句創建表、注冊 UDF,一個包含 10 張表的數倉,每次重啟需耗時 1 小時;
- 元數據無版本控制,若表結構變更(如新增字段),歷史作業可能因 “字段不匹配” 失敗,且無法追溯變更記錄;
- 某 IoT 企業因 Flink 集群重啟,元數據丟失,導致 12 個設備監控作業中斷,2 小時后才恢復,期間無法實時監測設備故障,造成生產停滯。
1.2.3 監控告警體系不完善
- 傳統架構中,Flink 作業監控依賴 Flink WebUI,調度任務監控依賴調度工具日志,元數據變更無監控,三者無統一入口:
- 作業失敗后,需分別查看 Flink 日志、調度工具日志、數據庫日志,排查故障平均耗時 30 分鐘;
- 無 “全鏈路告警” 機制,若 Kafka 集群宕機,Flink 作業因 “無數據輸入” 處于空閑狀態,但無告警通知,運維人員無法及時發現;
- 某零售企業曾因 Kafka 集群故障,Flink 實時庫存計算作業停滯 4 小時,導致線上庫存顯示錯誤,用戶下單后無法發貨,引發大量投訴。
1.3 架構擴展性弱:批流分離,多場景適配難
????????傳統數倉多采用 “Lambda 架構”,即 “批處理層(Hive)+ 流處理層(Flink)+ 服務層(MySQL)”,但該架構存在先天缺陷,無法滿足企業多樣化數據需求:
1.3.1 批流數據口徑不一致
- 批處理與流處理采用兩套計算邏輯:
- 批處理層用 Hive SQL 計算 “每日訂單總額”,流處理層用 Flink SQL 計算 “實時訂單總額”;
- 因計算邏輯差異(如時間窗口定義、空值處理規則),導致批流結果偏差(如批處理結果 100 萬,流處理結果 98 萬),業務部門無法確定 “哪組數據是正確的”;
- 某電商企業大促后,批處理統計的 “大促總銷售額” 為 5.2 億,流處理實時統計為 4.9 億,差異 3000 萬,需投入 3 人天排查差異原因,影響財務報表生成。
1.3.2 多數據源適配成本高
- 新增數據源(如 HBase、Elasticsearch、Pulsar)時,需開發自定義 Flink 連接器:
- 開發一個 HBase 連接器需掌握 HBase API 與 Flink Connector 規范,周期約 3 天;
- 連接器無統一管理,不同團隊重復開發,導致技術債務累積;
- 某互聯網企業因業務需求,需接入 Pulsar 數據源,開發連接器耗時 5 天,期間無法推進實時推薦作業開發,影響新功能上線。
1.3.3 資源利用率低
- 批處理作業(如每日凌晨執行的 Hive 全量計算)需占用大量資源,流處理作業需長期占用資源,兩者無法共享資源:
- 白天流處理作業資源空閑,但批處理作業未執行;凌晨批處理作業資源緊張,流處理作業資源無法臨時調度給批處理;
- 某金融企業為保障批處理作業執行,額外采購 5 臺服務器,資源利用率僅 30%,造成硬件成本浪費。
二、問題解決:自動化數倉平臺的核心目標與價值
????????針對上述痛點,本方案通過 “Flink+DolphinScheduler+Dinky” 組合,構建一站式自動化實時數倉平臺,以 “降本、提效、穩定、擴展” 為核心目標,具體如下:
2.1 降本:降低技術門檻,減少資源浪費
- 開發門檻降低:通過 Dinky 的 FlinkSQL Studio,將 Flink 作業開發從 “代碼級” 簡化為 “SQL 級”,非開發人員(如數據分析師)也可參與開發,減少對專業 Flink 開發人員的依賴;
- 資源利用率提升:基于 Flink 批流一體能力,批處理與流處理共享集群資源,白天流處理作業空閑時,資源可調度給臨時批處理任務,資源利用率從 30% 提升至 70%;
- 運維成本減少:自動化元數據管理、統一監控告警,減少 80% 手動運維操作(如重復建表、日志排查),一個運維人員可管理 100+ Flink 作業,較傳統模式效率提升 5 倍。
2.2 提效:全鏈路自動化,縮短迭代周期
- 開發效率提升:Dinky 提供 SQL 語法提示、一鍵調試、血緣分析功能,一個 “Kafka→MySQL” 的 Flink 作業開發周期從 2-3 天縮短至 1 小時,整體開發效率提升 300%;
- 調度效率提升:DolphinScheduler 可視化工作流編排,支持 “數據就緒觸發”“作業依賴聯動”,無需手動維護 Cron 腳本,調度配置時間從 1 天縮短至 10 分鐘;
- 故障排查效率提升:統一監控平臺整合 Flink 作業日志、調度任務狀態、元數據變更記錄,故障排查時間從 30 分鐘縮短至 5 分鐘。
2.3 穩定:保障數據一致性與作業可用性
- 數據一致性保障:Flink 內置 Exactly-Once 語義,Dinky 批流統一 SQL 語法,確保批流數據口徑一致,結果偏差率從 5% 降至 0.1%;
- 作業高可用:DolphinScheduler 分布式調度架構、Flink 集群 HA 配置,保障單點故障不影響整體作業運行,作業可用性從 99% 提升至 99.99%;
- 元數據安全:Dinky 支持 MySQL/Hive Catalog 持久化,元數據存儲在數據庫中,集群重啟后無丟失,元數據可靠性達 100%。
2.4 擴展:支持多場景適配,架構彈性伸縮
- 多數據源兼容:Dinky 內置 Kafka、MySQL、Hive、ClickHouse、Elasticsearch 等 20 + 數據源連接器,新增數據源無需開發,適配時間從 3 天縮短至 10 分鐘;
- 架構彈性擴展:Flink 與 DolphinScheduler 均支持水平擴展,新增 Worker 節點即可提升計算與調度能力,支持 1000 + 作業并發執行;
- 業務場景覆蓋:支持電商實時大屏、金融風控預警、IoT 設備監控、實時推薦等多場景,一套架構滿足企業多樣化數據需求。
三、選型對比:為何選擇 Flink+DolphinScheduler+Dinky 組合?
????????實時數倉技術棧選型需覆蓋 “計算引擎、調度工具、開發平臺” 三大核心模塊,需從 “功能適配性、易用性、擴展性、性能” 四個維度對比主流方案,最終確定最優組合。
3.1 計算引擎選型:Flink vs Spark Streaming vs Kafka Streams
計算引擎是實時數倉的 “心臟”,需具備低延遲、高吞吐、強一致性的特性,三者對比如下:
| 維度 | Apache Flink | Spark Streaming | Kafka Streams | 選型結論 |
|---|---|---|---|---|
| 處理模式 | 原生流處理(基于事件時間),支持毫秒級延遲 | 微批處理(最小批次 100ms+),延遲較高 | 原生流處理(基于事件時間),支持毫秒級延遲 | Flink/Kafka Streams 更適合低延遲場景;但 Kafka Streams 僅支持 Kafka 數據源,適配性弱,最終選 Flink |
| 狀態管理 | 內置狀態后端(Memory/RocksDB),支持 Exactly-Once 語義 | 需依賴外部存儲(Redis/HBase)實現狀態管理,語義保障弱 | 內置狀態管理(基于 Kafka 分區),支持 Exactly-Once 語義 | Flink 狀態管理更成熟,支持復雜狀態(如窗口聚合、CEP),無需依賴外部組件,降低架構復雜度 |
| 批流一體支持 | 支持流批統一 API(DataStream API),代碼可復用 | 批流 API 分離(Spark Core/Spark Streaming),需維護兩套代碼 | 僅支持流處理,無批處理能力 | Flink 適配 “批流一體數倉”,減少代碼冗余,避免批流結果偏差 |
| 數據源與連接器 | 原生支持 Kafka、MySQL、Hive、ClickHouse 等 20 + 數據源 | 支持主流數據源,但流處理連接器更新慢(如 ClickHouse 連接器需第三方擴展) | 僅支持 Kafka 數據源,無法接入其他存儲 | Flink 數據源覆蓋最廣,無需自定義開發,適配企業多數據源需求 |
| 窗口計算能力 | 支持滾動、滑動、會話、會話窗口,支持延遲數據處理(Watermark) | 僅支持基于時間的滾動 / 滑動窗口,延遲數據處理能力弱 | 支持滾動、滑動窗口,無會話窗口,延遲數據處理需自定義 | Flink 窗口功能最完善,滿足復雜業務場景(如 “用戶 30 分鐘內連續點擊” 會話分析) |
| 社區生態與文檔 | Apache 頂級項目,社區活躍,文檔完善,中文資料豐富 | Apache 頂級項目,社區活躍,但流處理文檔較簡略 | Confluent 維護,社區規模較小,中文資料少 | Flink 生態最成熟,問題排查、技術支持更便捷,降低運維成本 |
| 典型應用場景 | 實時大屏、金融風控、IoT 監控、批流一體數倉 | 批流分離場景、非低延遲需求的實時分析(如小時級報表) | 簡單 Kafka 數據處理(如數據過濾、格式轉換) | Flink 覆蓋場景最廣,適配企業復雜實時數倉需求 |
????????結論:Flink 在處理模式、狀態管理、批流一體、數據源適配等方面均優于 Spark Streaming 與 Kafka Streams,是實時數倉計算引擎的最優選擇。
3.2 調度工具選型:DolphinScheduler vs Airflow vs Azkaban
調度工具是實時數倉的 “大腦”,需具備分布式調度、可視化編排、高可用、告警聯動的特性,三者對比如下:
| 維度 | ?DolphinScheduler | Apache Airflow | ?Azkaban | 選型結論 |
|---|---|---|---|---|
| 架構設計 | 原生分布式(Master-Worker),支持多 Master/Worker 部署,水平擴展能力強 | 單 Master 架構,分布式需依賴 Kubernetes/YARN,配置復雜 | 單 Server 架構,無分布式能力,僅支持單機調度 | DolphinScheduler 分布式架構更適合大規模數倉,支持 1000 + 作業并發,避免單點故障 |
| 工作流編排 | 可視化拖拽界面,支持分支、循環、條件判斷,非技術人員可操作 | 需通過 Python 代碼定義 DAG( Directed Acyclic Graph ),學習成本高 | 可視化拖拽界面,但僅支持線性依賴,無分支 / 循環邏輯 | DolphinScheduler 編排最靈活,易用性最高,適合開發 / 運維 / 業務人員協作 |
| 任務類型支持 | 內置 Dinky、Flink、Spark、Shell、SQL 等 20 + 任務類型,支持自定義任務 | 支持主流任務類型,但需通過插件擴展(如 Dinky 任務需自定義 Operator) | 僅支持 Shell、Hive、Pig 任務,擴展能力弱 | DolphinScheduler 內置 Dinky/Flink 任務類型,無需二次開發,與計算引擎聯動更緊密 |
| 調度觸發方式 | 支持時間觸發(Cron)、事件觸發(上游任務完成)、手動觸發,觸發邏輯靈活 | 主要支持時間觸發,事件觸發需依賴外部組件(如 Apache NiFi) | 僅支持時間觸發與手動觸發,無事件觸發 | DolphinScheduler 觸發方式最豐富,滿足 “數據就緒后自動執行” 的實時場景需求 |
| 告警與監控 | 支持郵件、企業微信、釘釘、短信告警,內置任務失敗重試、超時告警,監控界面直觀 | 告警需依賴第三方集成(Prometheus+Grafana),配置復雜,無內置重試機制 | 僅支持郵件告警,無重試機制,監控功能簡單 | DolphinScheduler 告警與監控最完善,減少故障響應時間,降低運維成本 |
| 多租戶與權限控制 | 支持多項目隔離,細粒度權限控制(如 “只讀”“編輯”“執行”),通過 Token 實現跨系統權限聯動 | 支持多租戶,但權限控制較粗(僅項目級),無 Token 聯動機制 | 無多租戶概念,權限控制僅支持用戶級,無法隔離項目 | DolphinScheduler 權限體系更完善,適合多團隊協作的企業場景 |
| 社區支持與文檔 | 國內團隊主導開發,中文文檔完善,社區響應快(issue 24 小時內回復) | 國外團隊主導,中文文檔較少,社區響應較慢(issue 1-3 天回復) | 社區活躍度低,文檔陳舊,新版本更新慢 | DolphinScheduler 更適合國內企業,技術支持與問題排查更便捷 |
| 部署與維護成本 | 基于 Spring Boot 開發,部署簡單(僅需 Java 環境),維護成本低 | 依賴 Python 環境,需配置 Celery、Redis 等組件,部署復雜 | 部署簡單,但無分布式能力,維護成本隨作業量增加而上升 | DolphinScheduler 部署維護成本最低,適合中小企業與大型企業 |
????????結論:DolphinScheduler 在分布式架構、可視化編排、任務類型支持、告警監控等方面均優于 Airflow 與 Azkaban,是實時數倉調度工具的最優選擇。
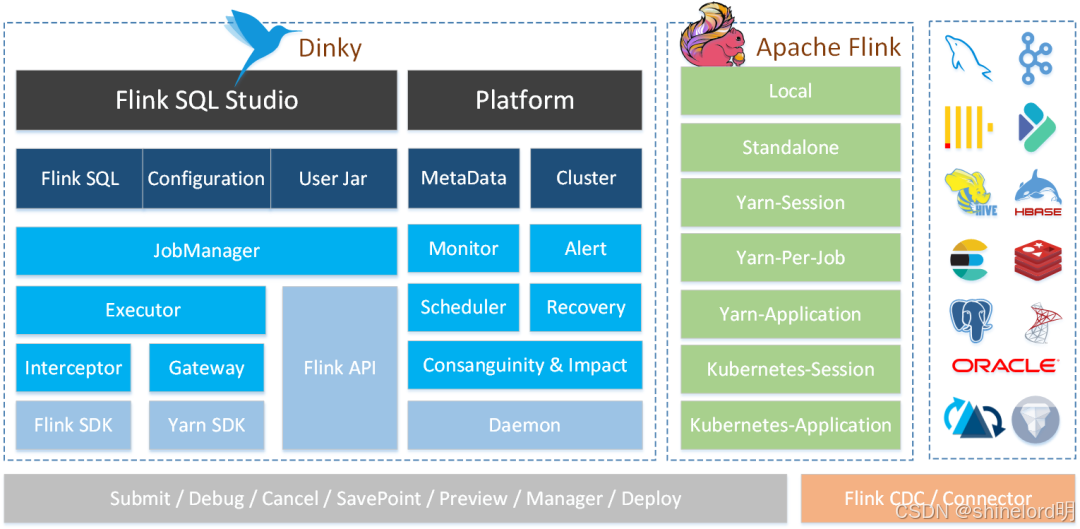
3.3 開發平臺選型:Dinky vs Flink SQL Client vs HUE

????????開發平臺是實時數倉的 “工作臺”,需具備低代碼開發、元數據管理、全生命周期監控、調度聯動的特性,三者對比如下:
| 維度 | Dinky | Flink SQL Client | HUE(Hadoop User Experience) | 選型結論 |
|---|---|---|---|---|
| 開發體驗 | 可視化 FlinkSQL Studio,支持語法提示、格式化、代碼高亮、SQL 模板,支持多標簽頁編輯,開發效率高 | 純命令行交互,無語法提示 / 格式化功能,需手動輸入完整 SQL 語句,開發體驗差 | 支持 Hive SQL 可視化編輯,但對 Flink SQL 支持有限(僅基礎語法高亮,無調試功能) | Dinky 開發體驗最優,大幅降低 Flink SQL 開發門檻,非開發人員也可快速上手 |
| Flink 版本兼容性 | 支持 Flink 1.15~1.19 多版本,無需手動切換集群配置,可在同一界面開發不同版本作業 | 僅支持當前綁定的 Flink 版本,切換版本需重新部署 Client,操作繁瑣 | 依賴外部 Flink 集成,版本兼容性弱,常出現 “語法支持不全” 問題 | Dinky 多版本兼容能力滿足企業 “逐步升級 Flink 集群” 的需求,避免版本切換成本 |
| 元數據管理 | 支持 MySQL/Hive Catalog 持久化(表結構、UDF、數據源、函數),元數據變更可追溯,集群重啟不丟失 | 元數據存儲在內存,會話結束 / 集群重啟后完全丟失,需重新執行 DDL | 僅支持 Hive 元數據管理,無 Flink 專屬元數據模塊,無法存儲 UDF 與作業配置 | Dinky 元數據管理最完善,解決傳統架構 “元數據碎片化” 痛點,減少重復建表操作 |
| 作業調試與運維 | 支持一鍵調試(本地 / 遠程模式)、實時查看作業日志、Flink UI 跳轉、作業暫停 / 重啟 / 終止,全生命周期可控 | 調試需依賴 Flink WebUI,日志需手動登錄集群查看,作業運維操作繁瑣 | 無 Flink 作業調試功能,僅支持查看 Hive 作業日志,運維能力弱 | Dinky 運維功能最全面,無需切換多工具,實現 “開發 - 調試 - 運維” 一體化 |
| UDF 開發與管理 | 支持 Python/Java/Scala UDF 開發,提供模板生成(如 ScalarFunction 繼承類)、一鍵發布、版本管理,支持 UDF 血緣分析 | 需手動通過 JAR 包注冊 UDF,無版本管理,UDF 沖突需手動排查 | 不支持 Flink UDF 開發,僅支持 Hive UDF 注冊,功能單一 | Dinky UDF 管理能力滿足企業 “自定義函數復用” 需求,降低 UDF 維護成本 |
| 調度工具聯動 | 內置 DolphinScheduler 集成模塊,支持作業 “發布→推送→調度” 一鍵操作,無需手動在調度平臺創建任務 | 無調度聯動功能,需手動通過 Shell 腳本調用 Client,再配置調度任務 | 僅支持與 Azkaban 簡單聯動,無 DolphinScheduler 集成能力 | Dinky 與 DolphinScheduler 深度集成,打通 “開發 - 調度” 鏈路,減少手動操作 |
| 批流一體支持 | 內置批流統一 SQL 語法,支持動態切換執行模式(流模式 / 批模式),作業代碼可復用 | 需手動指定執行模式(execution.type=streaming/batch),批流語法需單獨適配 | 僅支持批處理(Hive),無流處理能力,無法適配批流一體架構 | Dinky 批流一體支持能力保障數據口徑一致,避免 “一套邏輯兩套代碼” |
| 社區支持與更新 | 開源項目活躍,迭代速度快(每月更新小版本,每季度更新大版本),中文文檔完善,社區群實時答疑 | 作為 Flink 附屬工具,更新緩慢,功能迭代依賴 Flink 主版本 | 社區活躍度低,近 2 年無重大版本更新,功能停滯 | Dinky 社區支持最及時,可快速獲取新功能與問題修復,保障平臺穩定性 |
????????結論:Dinky 在開發體驗、元數據管理、運維能力、調度聯動等方面全面超越 Flink SQL Client 與 HUE,是 Flink 作業開發與數倉管理的最優平臺選擇。
3.4 整體組合優勢總結
????????“Flink+DolphinScheduler+Dinky” 組合并非簡單的組件疊加,而是形成 “計算 - 調度 - 開發” 三位一體的協同體系,核心優勢如下:
四、系統架構:自動化數倉平臺的整體設計
????????本平臺采用 “分層解耦、分布式部署” 架構,遵循 “高可用、可擴展、易維護” 原則,自上而下分為接入層、開發層、調度層、計算層、存儲層、監控層,各層獨立部署、協同工作,具體架構如下:
4.1 架構分層與組件部署
4.1.1 架構分層圖
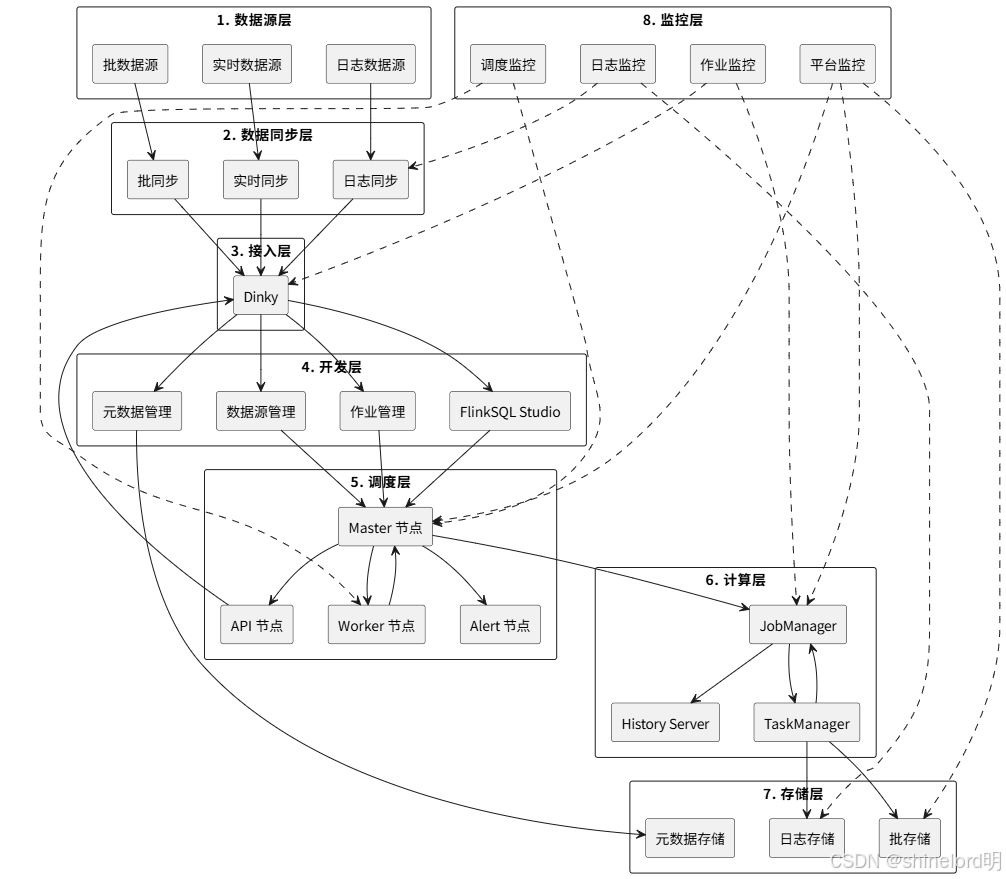
4.1.2 各層核心組件與部署要求
| 分層 | 核心組件 | 部署模式 | 硬件配置建議(單節點) | 核心職責 |
|---|---|---|---|---|
| 接入層 | Kafka、Flink CDC、DataX | 分布式(Kafka 3 節點 +) | CPU:4 核,內存:8G,磁盤:100G | 實現多數據源實時 / 批同步,將原始數據統一接入平臺,保持數據原貌 |
| 開發層 | Dinky 平臺 | 單機 / 集群(生產建議集群) | CPU:4 核,內存:8G,磁盤:50G | 提供 Flink 作業開發、元數據管理、UDF 開發能力,是平臺的 “開發入口” |
| 調度層 | DolphinScheduler | 分布式(Master 2 節點 + Worker 3 節點 +) | CPU:4 核,內存:8G,磁盤:50G | 負責作業調度、任務依賴管理、告警發送,是平臺的 “調度中樞” |
| 計算層 | Flink 集群 | 分布式(JobManager 2 節點 + TaskManager 3 節點 +) | CPU:8 核,內存:16G,磁盤:100G | 執行實時 / 批計算任務,處理數據清洗、匯總、分析邏輯,是平臺的 “計算核心” |
| 存儲層 | MySQL、Hive、ClickHouse | 分布式(Hive/ClickHouse 3 節點 +) | CPU:8 核,內存:16G,磁盤:500G | 存儲計算結果(實時結果→MySQL/ClickHouse,批結果→Hive)與元數據 |
| 監控層 | Prometheus、Grafana、Kibana | 分布式(Prometheus 2 節點 +) | CPU:4 核,內存:8G,磁盤:100G | 監控全鏈路組件狀態、作業運行情況、日志,及時發現故障并告警 |
4.2 核心技術特性設計
4.2.1 高可用設計
????????為避免單點故障,平臺各核心組件均采用高可用部署,具體方案如下:
4.2.2 擴展性設計
????????平臺支持水平擴展,可根據業務需求靈活增加節點,具體擴展方案如下:
4.2.3 安全性設計
????????平臺從 “權限控制、數據加密、日志審計” 三個維度保障安全性:
4.3 核心業務流程示例(電商實時銷量大屏)
????????以 “電商實時銷量大屏” 業務為例,完整展示平臺從數據接入到結果展示的全流程,具體步驟如下:
步驟 1:數據接入(接入層)
- 實時數據源:用戶下單數據通過業務系統寫入 Kafka 主題?
order_real_time(字段:order_id、user_id、amount、pay_time、status); - 數據同步:通過 Flink CDC 同步 MySQL 商品表?
product_info(字段:product_id、product_name、category)至 Kafka 主題?product_real_time; - 數據格式:Kafka 消息格式為 JSON,確保數據結構標準化,便于后續處理。
步驟 2:作業開發(開發層)
- 數據源配置:在 Dinky 平臺 “數據源管理” 模塊,新增 Kafka 數據源(配置?
bootstrap.servers=kafka-1:9092,kafka-2:9092)與 MySQL 數據源(配置商品表連接信息); - 元數據持久化:創建 MySQL Catalog?
ecommerce_catalog,用于存儲后續創建的表結構與 UDF;CREATE CATALOG ecommerce_catalog WITH ('type' = 'dinky_mysql','username' = 'dinky','password' = 'dinky@123','url' = 'jdbc:mysql://mysql-1:3306/dinky_metadata?useSSL=false&serverTimezone=Asia/Shanghai' ); USE CATALOG ecommerce_catalog; - 創建表結構:在 Dinky 中編寫 Flink SQL,創建 Kafka 源表與 ClickHouse 結果表;
sql
-- 1. 創建 Kafka 訂單源表 CREATE TABLE order_kafka_source (`order_id` BIGINT COMMENT '訂單ID',`user_id` BIGINT COMMENT '用戶ID',`product_id` BIGINT COMMENT '商品ID',`amount` DECIMAL(10,2) COMMENT '訂單金額',`pay_time` TIMESTAMP_LTZ(3) COMMENT '支付時間',`status` STRING COMMENT '訂單狀態(PAID/UNPAID)' ) WITH ('connector' = 'kafka','topic' = 'order_real_time','properties.bootstrap.servers' = '${kafka_source.bootstrap.servers}', -- 引用 Dinky 數據源變量'properties.group.id' = 'order_consumer_group','scan.startup.mode' = 'latest-offset','format' = 'json','json.ignore-parse-errors' = 'true' );-- 2. 創建 Kafka 商品源表 CREATE TABLE product_kafka_source (`product_id` BIGINT COMMENT '商品ID',`product_name` STRING COMMENT '商品名稱',`category` STRING COMMENT '商品分類' ) WITH ('connector' = 'kafka','topic' = 'product_real_time', 'properties.bootstrap.servers' = '${kafka_source.bootstrap.servers}', 'properties.group.id' = 'product_consumer_group', 'scan.startup.mode' = 'earliest-offset', 'format' = 'json', 'json.ignore-parse-errors' = 'true' ); -- 3. 創建 ClickHouse 實時銷量結果表(按分類匯總) CREATE TABLE sales_clickhouse_sink ( category STRING COMMENT ' 商品分類 ', real_time_sales DECIMAL (12,2) COMMENT ' 實時銷量金額 ', order_count BIGINT COMMENT ' 訂單數量 ', update_time TIMESTAMP COMMENT ' 更新時間 ', PRIMARY KEY (category, update_time) NOT ENFORCED -- 復合主鍵確保數據唯一性 ) WITH ( 'connector' = 'clickhouse', 'url' = 'jdbc:clickhouse://clickhouse-1:8123,ecommerce_sales', 'table-name' = 'real_time_sales_summary', 'username' = 'clickhouse', 'password' = 'clickhouse@123', 'sink.batch-size' = '1000', -- 批量寫入大小 'sink.flush-interval' = '1000' -- 刷新間隔(毫秒) );
4. **開發 UDF 函數**
**開發 UDF 函數**:創建 Python UDF `format_amount`,用于格式化訂單金額(保留 2 位小數并添加千分位分隔符);
- 選擇 Dinky 作業類型為“Python”,模板為“UDF / python_udf_1”;
- 編寫 UDF 代碼:```pythonfrom pyflink.table import ScalarFunction, DataTypesfrom pyflink.table.udf import udfclass format_amount(ScalarFunction):def __init__(self):passdef eval(self, amount: float) -> str:# 格式化金額:保留2位小數,添加千分位分隔符return "{:,.2f}".format(amount)# 注冊 UDF,指定返回類型為字符串format_amount_udf = udf(format_amount(), result_type=DataTypes.STRING())編寫計算邏輯:關聯訂單表與商品表,按商品分類實時匯總銷量,并調用 UDF 格式化金額;
-- 1. 關聯訂單與商品數據,過濾已支付訂單
WITH order_product_join AS (SELECT o.order_id,o.user_id,o.amount,o.pay_time,p.product_name,p.categoryFROM order_kafka_source oJOIN product_kafka_source p ON o.product_id = p.product_idWHERE o.status = 'PAID' -- 僅處理已支付訂單
),-- 2. 按分類實時匯總(5秒滾動窗口)
category_sales_summary AS (SELECT category,SUM(amount) AS real_time_sales,COUNT(order_id) AS order_count,CURRENT_TIMESTAMP() AS update_timeFROM order_product_joinGROUP BY category, TUMBLE(pay_time, INTERVAL '5' SECOND) -- 5秒滾動窗口
)-- 3. 寫入 ClickHouse 結果表,同時調用 UDF 格式化金額(僅用于日志打印)
INSERT INTO sales_clickhouse_sink
SELECT category,real_time_sales,order_count,update_time
FROM category_sales_summary;-- 打印格式化后的金額(用于調試)
SELECT category,format_amount_udf(real_time_sales) AS formatted_sales,order_count,update_time
FROM category_sales_summary;
????????作業調試:選擇 Flink 實例(外部分布式集群),點擊 “調試” 按鈕,查看日志確認無語法錯誤,數據可正常讀取與寫入。
步驟 3:調度配置(調度層)
Dinky 與 DolphinScheduler 聯動配置:
????????在 DolphinScheduler 中創建令牌:進入 “安全中心→令牌管理”,創建令牌?dinky_token,設置有效期為 1 年(避免頻繁過期);
????????在 Dinky 中配置調度信息:進入 “配置中心→全局配置→DolphinScheduler 配置”,啟用開關,填寫 DolphinScheduler 地址(http://dolphinscheduler-master-1:12345)、項目名稱(ecommerce_realtime)、令牌?dinky_token;
作業發布與推送:
????????在 Dinky 中發布 Flink 作業(版本號?V1.0),點擊 “推送” 按鈕,選擇推送至 DolphinScheduler 項目?ecommerce_realtime;
????????推送完成后,在 DolphinScheduler 項目中自動生成工作流?sales_summary_workflow,包含 1 個 Dinky 任務(關聯已發布的 Flink 作業);
調度規則配置:
????????編輯工作流?sales_summary_workflow,設置調度周期為 “連續運行”(實時作業需持續執行);
????????配置依賴規則:添加 “Kafka 主題健康檢查” 前置任務(Shell 腳本檢測?order_real_time?主題是否可用),確保上游數據就緒后再執行 Flink 作業;
????????配置告警規則:任務失敗時觸發 “企業微信 + 郵件” 雙告警,通知運維團隊(接收人:ops_team@xxx.com),并設置失敗重試(重試次數 2 次,間隔 5 分鐘)。
步驟 4:計算執行(計算層)
- Flink 作業提交:DolphinScheduler 按調度規則觸發任務,通過 Dinky API 向 Flink 集群提交作業;
- Flink 執行流程:
- JobManager 接收作業,解析 Flink SQL 生成物理執行計劃,分配資源(每個 TaskManager 分配 2 核 CPU、4G 內存);
- TaskManager 啟動 Task 執行數據處理:
- Source Task:讀取 Kafka 主題?
order_real_time?與?product_real_time?數據; - Join Task:關聯訂單與商品數據,過濾已支付訂單;
- Aggregate Task:按 5 秒滾動窗口匯總各分類銷量;
- Sink Task:將匯總結果寫入 ClickHouse 表?
real_time_sales_summary;
- Source Task:讀取 Kafka 主題?
- 狀態管理:采用 RocksDBStateBackend,窗口聚合狀態持久化至 HDFS(路徑?
hdfs://hdfs-nn:9000/flink/state/sales_summary),避免作業重啟后狀態丟失;
- 作業監控:通過 Flink WebUI(
http://flink-jobmanager-1:8081)查看作業運行狀態,確認 Task 無失敗,數據吞吐率正常(約 1000 條 / 秒)。
步驟 5:結果存儲與應用(存儲層 + 應用層)
- 結果存儲:Flink 作業將實時銷量匯總結果寫入 ClickHouse 表?
real_time_sales_summary,每 5 秒更新一次數據; - 數據應用:電商實時大屏通過 JDBC 連接 ClickHouse,查詢?
real_time_sales_summary?表數據,展示各商品分類的實時銷量金額、訂單數量,并按銷量排序 Top5 分類,支持鉆取查看具體商品銷量(關聯?product_info?表)。
步驟 6:全鏈路監控(監控層)
- 組件監控:Prometheus 采集 Flink、DolphinScheduler、Dinky 組件指標(如 Flink TaskManager CPU 使用率、DolphinScheduler 任務成功率),Grafana 配置儀表盤展示,設置閾值告警(如 Flink Task 失敗率 > 0 時告警);
- 作業監控:Dinky 內置監控模塊展示作業運行時長、數據讀取 / 寫入量、UDF 調用次數,支持查看實時日志;Flink WebUI 查看 Task 背壓情況(若背壓高,需增加 TaskManager 節點);
- 日志監控:全鏈路日志(Dinky 開發日志、Flink 執行日志、DolphinScheduler 調度日志)統一寫入 Elasticsearch,通過 Kibana 按 “作業 ID”“時間范圍” 查詢,快速定位故障(如 “2024-05-20 14:30 作業失敗” 可通過日志發現是 Kafka 連接超時)。
五、數據架構:批流一體的數倉分層設計
????????基于 Flink 批流一體能力與 Dinky 元數據管理特性,本平臺采用 “Lambda 架構優化版” 設計數據分層,兼顧實時性與數據完整性,同時避免傳統 Lambda 架構 “批流分離” 的痛點。數據架構從下至上分為?ODS 層(操作數據存儲層)、DWD 層(數據倉庫明細層)、DWS 層(數據倉庫匯總層)、ADS 層(數據應用層),各層職責清晰、數據單向流動,具體設計如下:
5.1 數據分層詳情
| 分層 | 英文全稱 | 定位 | 存儲組件 | 數據處理規則 | 典型表 / 主題示例 | 數據時效 |
|---|---|---|---|---|---|---|
| ODS 層 | Operational Data Store | 原始數據接入層,“數據著陸區” | Kafka(實時)、HDFS(批) | 1. 保持數據原貌,不做清洗 / 轉換; 2. 按數據源分區存儲(如 Kafka 按主題、HDFS 按日期); 3. 保留原始格式(JSON/CSV/Parquet) | 實時:ods_kafka_order(訂單日志)、ods_kafka_product(商品日志);批: ods_hdfs_user(用戶全量數據) | 實時(毫秒級)、批(T+1) |
| DWD 層 | Data Warehouse Detail | 數據清洗層,“明細數據層” | Kafka(實時)、Hive(批) | 1. 數據清洗:去重(如訂單重復日志)、補空(如缺失的商品分類)、格式標準化(如時間統一為 UTC+8); 2. 數據脫敏:敏感字段加密(如用戶手機號脫敏為 138****5678); 3. 按業務主題拆分(如 “訂單主題”“用戶主題”) | 實時:dwd_kafka_order_detail(訂單明細)、dwd_kafka_user_behavior(用戶行為明細);批: dwd_hive_product_detail(商品明細) | 實時(秒級)、批(T+1) |
| DWS 層 | Data Warehouse Summary | 數據匯總層,“匯總數據層” | ClickHouse(實時)、Hive(批) | 1. 實時匯總:按時間窗口(如 5 秒 / 1 分鐘)、業務維度(如商品分類、區域)聚合; 2. 批處理補全:每日凌晨執行批作業,補全前一天全量數據(修正實時數據偏差); 3. 數據去重:基于主鍵(如 “訂單 ID + 時間”)確保匯總結果唯一性 | 實時:dws_clickhouse_sales_real(實時銷量匯總)、dws_clickhouse_user_active(實時用戶活躍匯總);批: dws_hive_sales_day(日銷量匯總) | 實時(秒級 / 分鐘級)、批(T+1) |
| ADS 層 | Application Data Store | 數據應用層,“業務輸出層” | MySQL(輕量應用)、ClickHouse(OLAP)、Redis(緩存) | 1. 面向業務需求封裝數據(如實時大屏需 “分類銷量 Top10”、風控需 “高風險訂單列表”); 2. 數據壓縮:減少冗余字段,僅保留業務所需字段; 3. 支持高并發查詢(如 MySQL 加索引、Redis 緩存熱點數據) | 實時大屏:ads_mysql_sales_top10(銷量 Top10 分類);風控: ads_clickhouse_risk_order(高風險訂單);緩存: ads_redis_user_active(實時活躍用戶數) | 實時(毫秒級 / 秒級)、批(T+1) |
5.2 批流一體設計核心策略
????????傳統 Lambda 架構中,批處理層(Batch Layer)與流處理層(Speed Layer)獨立運行,易導致數據口徑不一致。本平臺通過以下策略實現 “批流一體”,確保實時數據與批數據結果統一:
5.2.1 統一數據模型
- 表結構統一:DWD/DWS/ADS 層的實時表與批表采用相同的表結構(字段名、數據類型、主鍵),例如:
- 實時表?
dws_clickhouse_sales_real?與批表?dws_hive_sales_day?均包含?category(商品分類)、sales_amount(銷量金額)、stat_date(統計日期)字段;
- 實時表?
- 維度統一:批流共享同一維度表(如商品維度表?
dwd_hive_product_dim),實時作業通過 Flink Hive Catalog 讀取批維度表,避免 “實時用臨時維度、批用正式維度” 導致的偏差。
5.2.2 統一計算邏輯
- SQL 語法統一:基于 Dinky 批流統一 SQL 語法,實時作業與批作業復用同一套計算邏輯,僅通過?
execution.type?參數切換執行模式:sql
-- 實時模式(流處理) SET 'execution.type' = 'streaming'; -- 批模式(批處理) SET 'execution.type' = 'batch';-- 統一計算邏輯:按分類匯總銷量 SELECT category,SUM(amount) AS sales_amount,COUNT(order_id) AS order_count,DATE_FORMAT(pay_time, 'yyyy-MM-dd') AS stat_date FROM dwd_layer_table WHERE status = 'PAID' GROUP BY category, DATE_FORMAT(pay_time, 'yyyy-MM-dd'); - 函數統一:批流作業調用相同的 UDF(如?
format_amount?金額格式化函數),避免 “實時用 Python UDF、批用 Hive UDF” 導致的計算差異。
5.2.3 數據補全與合并
- 實時數據補全:實時作業通過 Flink 窗口延遲處理(Watermark)接收遲到數據(如用戶支付延遲 5 分鐘),減少實時數據遺漏;
- 批流數據合并:每日凌晨(如 2:00)執行批作業,計算前一天全量銷量數據,覆蓋實時作業的匯總結果(修正實時數據因 “遲到數據未處理” 導致的偏差),確保最終結果一致性;
- 合并策略示例:
????????批作業計算?dws_hive_sales_day(T-1 日全量銷量);
????????通過 Flink 批作業將?dws_hive_sales_day?數據覆蓋寫入 ClickHouse 實時表?dws_clickhouse_sales_real?中 T-1 日的分區;
????????應用層查詢時,T-1 日及之前的數據讀取批處理結果,當日數據讀取實時結果,實現 “批流無縫銜接”。
5.3 數據流轉示例(電商銷量分析)
????????以 “電商銷量分析” 業務為例,結合批流一體設計策略,完整展示數據從 ODS 層到 ADS 層的流轉過程、處理邏輯及技術實現,清晰呈現各層數據的加工鏈路與價值轉化。
5.3.1 流轉鏈路概覽
????????數據流轉遵循 “單向流動、分層加工” 原則,實時鏈路與批處理鏈路并行且最終融合,具體鏈路如下:
- 實時鏈路:ODS 層(Kafka 實時訂單 / 商品日志)→ DWD 層(Kafka 清洗后明細)→ DWS 層(ClickHouse 實時匯總)→ ADS 層(MySQL/Redis 應用數據),支撐實時銷量大屏、實時庫存調整等低延遲需求;
- 批處理鏈路:ODS 層(HDFS 全量訂單 / 用戶數據)→ DWD 層(Hive 明細補全)→ DWS 層(Hive 日匯總)→ DWS 層(ClickHouse 歷史數據覆蓋),修正實時數據偏差、補全歷史數據,支撐財務報表、月度銷量分析等精準性需求。
5.3.2 各層數據處理詳情
1. ODS 層:原始數據接入
????????作為數據 “著陸區”,ODS 層不做任何業務加工,僅按數據源類型存儲原始數據,確保數據溯源能力。
| 類型 | 數據源 | 存儲組件 | 數據格式 | 分區 / 主題設計 | 數據內容示例 |
|---|---|---|---|---|---|
| 實時訂單 | 電商業務系統(下單接口) | Kafka | JSON | 主題:ods_kafka_order_real_time,按 “小時” 分區(如?2024052014) | {"order_id":10001,"user_id":20005,"product_id":30012,"amount":999.00,"pay_time":"2024-05-20 14:30:25","status":"UNPAID","create_time":"2024-05-20 14:29:58"} |
| 實時商品 | Flink CDC(MySQL 商品表) | Kafka | JSON | 主題:ods_kafka_product_real_time,按 “天” 分區(如?20240520) | {"product_id":30012,"product_name":"智能手表","category":"數碼產品","price":1299.00,"stock":500,"update_time":"2024-05-20 10:15:30"} |
| 批訂單 | 業務系統每日全量導出 | HDFS(Hive 外部表) | Parquet | Hive 分區:dt=20240520(按日期),分桶:order_id%10(10 個桶) | 同實時訂單結構,包含當日所有訂單(含歷史未支付轉支付訂單) |
| 批用戶 | 用戶中心全量同步 | HDFS(Hive 外部表) | Parquet | Hive 分區:dt=20240520,分桶:user_id%5(5 個桶) | {"user_id":20005,"user_name":"張三","phone":"138****5678","region":"北京","register_time":"2023-01-15 09:20:30"} |
技術實現:
- 實時數據:業務系統通過 Kafka Producer 寫入訂單主題,Flink CDC 監聽 MySQL 商品表 binlog,自動同步變更數據至商品主題;
- 批數據:業務系統每日 00:30 導出前一日全量訂單 CSV 文件,通過 DataX 同步至 HDFS,Hive 外部表關聯 HDFS 路徑實現查詢。
2. DWD 層:數據清洗與標準化
????????DWD 層是 “數據凈化站”,通過清洗、脫敏、標準化處理,將 ODS 層原始數據轉化為結構化、高質量的明細數據,為后續匯總提供統一基礎。
(1)實時 DWD 處理(Kafka 明細)
處理邏輯:基于 Flink SQL 實時處理 ODS 層 Kafka 數據,核心操作包括:
- 數據清洗:過濾無效訂單(如?
order_id?為空、amount?≤0)、去重(基于?order_id + create_time?主鍵,避免重復日志); - 字段補全:對缺失的?
category(商品分類),通過關聯商品主題數據補全; - 格式標準化:將?
pay_time/create_time?統一轉換為 UTC+8 時區的?TIMESTAMP_LTZ(3)?類型; - 敏感數據脫敏:用戶手機號?
phone?字段脫敏(如?138****5678),通過 Dinky 內置 UDF?mask_phone?實現。
SQL 實現(Dinky 平臺):
-- 1. 讀取 ODS 層訂單與商品 Kafka 數據
CREATE TABLE ods_kafka_order (`order_id` BIGINT COMMENT '訂單ID',`user_id` BIGINT COMMENT '用戶ID',`product_id` BIGINT COMMENT '商品ID',`amount` DECIMAL(10,2) COMMENT '訂單金額',`pay_time` TIMESTAMP_LTZ(3) COMMENT '支付時間',`status` STRING COMMENT '訂單狀態',`create_time` TIMESTAMP_LTZ(3) COMMENT '創建時間',`proc_time` AS PROCTIME() COMMENT '處理時間(用于水印)'
) WITH ('connector' = 'kafka','topic' = 'ods_kafka_order_real_time','properties.bootstrap.servers' = '${kafka_servers}','properties.group.id' = 'dwd_order_consumer','scan.startup.mode' = 'latest-offset','format' = 'json'
);CREATE TABLE ods_kafka_product (`product_id` BIGINT COMMENT '商品ID',`product_name` STRING COMMENT '商品名稱',`category` STRING COMMENT '商品分類',`update_time` TIMESTAMP_LTZ(3) COMMENT '更新時間'
) WITH ('connector' = 'kafka','topic' = 'ods_kafka_product_real_time','properties.bootstrap.servers' = '${kafka_servers}','properties.group.id' = 'dwd_product_consumer','scan.startup.mode' = 'earliest-offset','format' = 'json'
);-- 2. 創建 DWD 層訂單明細 Kafka 表
CREATE TABLE dwd_kafka_order_detail (`order_id` BIGINT COMMENT '訂單ID',`user_id` BIGINT COMMENT '用戶ID',`user_phone_masked` STRING COMMENT '脫敏手機號(關聯用戶表獲取)',`product_id` BIGINT COMMENT '商品ID',`product_name` STRING COMMENT '商品名稱',`category` STRING COMMENT '商品分類',`amount` DECIMAL(10,2) COMMENT '訂單金額',`pay_time` TIMESTAMP_LTZ(3) COMMENT '支付時間',`status` STRING COMMENT '訂單狀態',`create_time` TIMESTAMP_LTZ(3) COMMENT '創建時間',PRIMARY KEY (`order_id`) NOT ENFORCED -- 主鍵去重
) WITH ('connector' = 'kafka','topic' = 'dwd_kafka_order_detail','properties.bootstrap.servers' = '${kafka_servers}','format' = 'json','sink.partitioner' = 'round-robin' -- 輪詢分區,負載均衡
);-- 3. 清洗并寫入 DWD 層(關聯商品表補全分類,脫敏手機號)
INSERT INTO dwd_kafka_order_detail
SELECT o.order_id,o.user_id,mask_phone(u.phone) AS user_phone_masked, -- 內置脫敏UDFo.product_id,p.product_name,p.category,o.amount,o.pay_time,o.status,o.create_time
FROM ods_kafka_order o
-- 關聯商品表(實時維度關聯,采用Lookup Join)
LEFT JOIN ods_kafka_product FOR SYSTEM_TIME AS OF o.proc_time p ON o.product_id = p.product_id
-- 關聯批用戶表(Hive 維度表,通過Flink Hive Catalog讀取)
LEFT JOIN hive_catalog.ods_db.ods_hive_user u ON o.user_id = u.user_id
-- 過濾無效數據
WHERE o.order_id IS NOT NULL AND o.amount > 0 AND o.status IN ('PAID', 'UNPAID', 'REFUNDED');
(2)批 DWD 處理(Hive 明細)
????????處理邏輯:每日凌晨 01:00 執行 Flink 批作業,基于 ODS 層 Hive 全量數據,對實時 DWD 數據進行補全(如遺漏的歷史訂單、延遲同步的用戶數據),核心操作包括:
補全歷史數據:對實時鏈路未捕獲的前一日未支付轉支付訂單,更新?
status?字段;修正數據偏差:若實時關聯商品表時出現延遲,批處理重新關聯最新商品維度表,修正?
category?字段;數據對齊:確保批處理明細與實時明細字段完全一致,為后續批流匯總統一基礎。
SQL 實現(Dinky 平臺,批模式):
-- 1. 切換為批處理模式
SET 'execution.type' = 'batch';-- 2. 讀取 ODS 層批訂單與批用戶 Hive 表
CREATE TABLE ods_hive_order (`order_id` BIGINT COMMENT '訂單ID',`user_id` BIGINT COMMENT '用戶ID',`product_id` BIGINT COMMENT '商品ID',`amount` DECIMAL(10,2) COMMENT '訂單金額',`pay_time` TIMESTAMP COMMENT '支付時間',`status` STRING COMMENT '訂單狀態',`create_time` TIMESTAMP COMMENT '創建時間',`dt` STRING COMMENT '分區日期'
) WITH ('connector' = 'hive','database-name' = 'ods_db','table-name' = 'ods_hive_order','partition' = 'dt=20240520' -- 處理前一日數據
);-- 3. 創建 DWD 層批訂單明細 Hive 表
CREATE TABLE dwd_hive_order_detail (`order_id` BIGINT COMMENT '訂單ID',`user_id` BIGINT COMMENT '用戶ID',`user_phone_masked` STRING COMMENT '脫敏手機號',`product_id` BIGINT COMMENT '商品ID',`product_name` STRING COMMENT '商品名稱',`category` STRING COMMENT '商品分類',`amount` DECIMAL(10,2) COMMENT '訂單金額',`pay_time` TIMESTAMP COMMENT '支付時間',`status` STRING COMMENT '訂單狀態',`create_time` TIMESTAMP COMMENT '創建時間',`dt` STRING COMMENT '分區日期'
) PARTITIONED BY (`dt` STRING)
WITH ('connector' = 'hive','database-name' = 'dwd_db','table-name' = 'dwd_hive_order_detail'
);-- 4. 批處理清洗并寫入 DWD 層
INSERT OVERWRITE TABLE dwd_hive_order_detail PARTITION (dt='20240520')
SELECT o.order_id,o.user_id,mask_phone(u.phone) AS user_phone_masked,o.product_id,p.product_name,p.category,o.amount,o.pay_time,o.status,o.create_time
FROM ods_hive_order o
LEFT JOIN hive_catalog.ods_db.ods_hive_product p ON o.product_id = p.product_id
LEFT JOIN hive_catalog.ods_db.ods_hive_user u ON o.user_id = u.user_id
WHERE o.order_id IS NOT NULL AND o.amount > 0;
3. DWS 層:數據匯總與批流融合
????????DWS 層是 “數據聚合中心”,分別生成實時匯總數據(支撐低延遲需求)和批匯總數據(修正偏差、補全歷史),最終通過 “批覆蓋實時” 實現數據一致性。
(1)實時 DWS 處理(ClickHouse 匯總)
處理邏輯:基于 DWD 層 Kafka 明細數據,按 “商品分類” 和 “5 秒滾動窗口” 實時聚合銷量,核心操作包括:
- 窗口聚合:采用 Flink TUMBLE 窗口(5 秒),統計各分類的實時銷量金額、訂單數量;
- 狀態管理:使用 RocksDBStateBackend 持久化窗口狀態,避免作業重啟后數據丟失;
- 實時寫入:將聚合結果寫入 ClickHouse,支持高并發查詢(ClickHouse 列存引擎適配 OLAP 場景)。
SQL 實現(Dinky 平臺):
-- 1. 讀取 DWD 層訂單明細 Kafka 表
CREATE TABLE dwd_kafka_order_detail (-- 字段同 5.3.2.2(1)中定義,此處省略
);-- 2. 創建 DWS 層實時銷量匯總 ClickHouse 表
CREATE TABLE dws_clickhouse_sales_real (`category` STRING COMMENT '商品分類',`window_start` TIMESTAMP_LTZ(3) COMMENT '窗口開始時間',`window_end` TIMESTAMP_LTZ(3) COMMENT '窗口結束時間',`real_sales` DECIMAL(12,2) COMMENT '實時銷量金額',`order_count` BIGINT COMMENT '訂單數量',`update_time` TIMESTAMP_LTZ(3) COMMENT '數據更新時間',PRIMARY KEY (`category`, `window_start`) NOT ENFORCED -- 復合主鍵確保唯一性
) WITH ('connector' = 'clickhouse','url' = 'jdbc:clickhouse://${clickhouse_servers}/dws_db','table-name' = 'dws_clickhouse_sales_real','username' = '${clickhouse_user}','password' = '${clickhouse_pwd}','sink.batch-size' = '500', -- 批量寫入,提升性能'sink.flush-interval' = '1000' -- 1秒刷新一次
);-- 3. 實時窗口聚合并寫入 ClickHouse
INSERT INTO dws_clickhouse_sales_real
SELECT category,TUMBLE_START(pay_time, INTERVAL '5' SECOND) AS window_start,TUMBLE_END(pay_time, INTERVAL '5' SECOND) AS window_end,SUM(amount) AS real_sales,COUNT(DISTINCT order_id) AS order_count, -- 去重統計訂單數CURRENT_TIMESTAMP() AS update_time
FROM dwd_kafka_order_detail
WHERE status = 'PAID' -- 僅統計已支付訂單
GROUP BY category, TUMBLE(pay_time, INTERVAL '5' SECOND);
(2)批 DWS 處理(Hive 匯總 + ClickHouse 覆蓋)
????????處理邏輯:每日凌晨 02:00 執行 Flink 批作業,基于 DWD 層 Hive 明細數據,計算前一日全量銷量匯總,核心操作包括:
全量聚合:按 “商品分類” 和 “日期” 聚合,得到前一日各分類的精準銷量(修正實時窗口遺漏的遲到數據);
歷史覆蓋:將批匯總結果寫入 Hive 表的同時,覆蓋 ClickHouse 實時表中對應日期的分區數據,實現 “批流數據統一”;
數據校驗:對比批匯總與實時匯總的差異(如差異率 >0.5% 觸發告警),確保數據準確性。
SQL 實現(Dinky 平臺,批模式):
-- 4. 批處理聚合并寫入 Hive
INSERT OVERWRITE TABLE dws_hive_sales_day PARTITION (stat_date='20240520')
SELECT category,'20240520' AS stat_date,SUM(amount) AS day_sales,COUNT(DISTINCT order_id) AS day_order_count,CURRENT_TIMESTAMP() AS calc_time
FROM dwd_hive_order_detail
WHERE status = 'PAID' AND dt = '20240520' -- 僅處理前一日明細數據
GROUP BY category;-- 5. 創建 ClickHouse 批數據寫入表(復用實時表結構,僅覆蓋歷史分區)
CREATE TABLE dws_clickhouse_sales_real (-- 同 5.3.2.3(1)中實時表結構,此處省略
);-- 6. 批匯總結果覆蓋 ClickHouse 實時表歷史數據
INSERT OVERWRITE TABLE dws_clickhouse_sales_real
SELECT category,TO_TIMESTAMP_LTZ(CONCAT(stat_date, ' 00:00:00'), 3) AS window_start, -- 按日構建窗口起始時間TO_TIMESTAMP_LTZ(CONCAT(stat_date, ' 23:59:59'), 3) AS window_end, -- 按日構建窗口結束時間day_sales AS real_sales,day_order_count AS order_count,CURRENT_TIMESTAMP() AS update_time
FROM dws_hive_sales_day
WHERE stat_date = '20240520';-- 7. 數據差異校驗(對比批匯總與實時匯總結果,差異率>0.5%則告警)
WITH batch_data AS (SELECT category, day_sales FROM dws_hive_sales_day WHERE stat_date = '20240520'
),
stream_data AS (SELECT category, SUM(real_sales) AS stream_total_sales FROM dws_clickhouse_sales_realWHERE DATE_FORMAT(window_start, 'yyyyMMdd') = '20240520'GROUP BY category
)
SELECT b.category,b.day_sales AS batch_sales,s.stream_total_sales,ROUND(ABS(b.day_sales - s.stream_total_sales) / b.day_sales * 100, 2) AS diff_rate
FROM batch_data b
JOIN stream_data s ON b.category = s.category
WHERE ROUND(ABS(b.day_sales - s.stream_total_sales) / b.day_sales * 100, 2) > 0.5;
-- 若查詢返回結果,通過 Dinky 告警模塊觸發企業微信通知,提示運維人員排查差異原因
批流融合效果:通過 “實時計算 + 批處理補全”,確保 ClickHouse 表中:
- 當日數據:實時更新(5 秒窗口),支撐實時大屏展示;
- 歷史數據(T-1 及之前):由批處理結果覆蓋,保證數據精準性(如財務對賬場景);
- 差異率控制在 0.5% 以內,滿足業務對數據一致性的要求。
4. ADS 層:數據應用封裝
????????ADS 層是 “業務輸出端”,基于 DWS 層匯總數據,按具體業務需求封裝數據,直接支撐前端應用或下游系統調用,核心目標是 “簡化查詢、提升性能”。
(1)實時大屏場景(MySQL 存儲)
????????業務需求:電商實時大屏需展示 “商品分類銷量 Top10”“實時總銷售額”“近 1 小時銷量趨勢”,要求查詢延遲 <100ms。
處理邏輯:
從 ClickHouse 實時表聚合核心指標;
將結果寫入 MySQL(支持高并發讀),并創建索引優化查詢;
每 10 秒刷新一次數據,平衡實時性與數據庫壓力。
SQL 實現(Dinky 平臺):
-- 1. 讀取 DWS 層 ClickHouse 實時匯總表
CREATE TABLE dws_clickhouse_sales_real (-- 同前序定義,此處省略
);-- 2. 創建 ADS 層實時大屏 MySQL 表
CREATE TABLE ads_mysql_sales_dashboard (`indicator_name` STRING COMMENT '指標名稱(如 total_sales/top10_category)',`category` STRING COMMENT '商品分類(top10場景非空,總銷量場景為空)',`indicator_value` STRING COMMENT '指標值(金額/數量,轉字符串便于統一存儲)',`rank` INT COMMENT '排名(僅top10場景非空)',`update_time` TIMESTAMP COMMENT '更新時間',PRIMARY KEY (`indicator_name`, `category`) NOT ENFORCED -- 復合主鍵避免重復數據
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://${mysql_servers}/ads_db?useSSL=false','table-name' = 'ads_mysql_sales_dashboard','username' = '${mysql_user}','password' = '${mysql_pwd}','sink.batch-size' = '10','sink.flush-interval' = '10000' -- 10秒刷新一次
);-- 3. 封裝“實時總銷售額”指標
INSERT INTO ads_mysql_sales_dashboard
SELECT 'total_sales' AS indicator_name,'' AS category,CAST(SUM(real_sales) AS STRING) AS indicator_value,0 AS rank,CURRENT_TIMESTAMP() AS update_time
FROM dws_clickhouse_sales_real
WHERE window_end >= DATE_SUB(CURRENT_TIMESTAMP(), INTERVAL '1' DAY); -- 統計近24小時總銷量-- 4. 封裝“商品分類銷量 Top10”指標
INSERT INTO ads_mysql_sales_dashboard
SELECT 'top10_category' AS indicator_name,category,CAST(SUM(real_sales) AS STRING) AS indicator_value,ROW_NUMBER() OVER (ORDER BY SUM(real_sales) DESC) AS rank,CURRENT_TIMESTAMP() AS update_time
FROM dws_clickhouse_sales_real
WHERE window_end >= DATE_SUB(CURRENT_TIMESTAMP(), INTERVAL '1' DAY)
GROUP BY category
QUALIFY ROW_NUMBER() OVER (ORDER BY SUM(real_sales) DESC) <= 10; -- 取銷量前10分類
應用調用:實時大屏通過 JDBC 連接 MySQL,執行簡單查詢即可獲取指標:
-- 查詢實時總銷售額
SELECT indicator_value AS total_sales
FROM ads_mysql_sales_dashboard
WHERE indicator_name = 'total_sales'
ORDER BY update_time DESC LIMIT 1;-- 查詢銷量 Top10 分類
SELECT category, indicator_value AS sales_amount, rank
FROM ads_mysql_sales_dashboard
WHERE indicator_name = 'top10_category'
ORDER BY rank ASC;
(2)財務報表場景(Hive 存儲)
????????業務需求:財務部門需生成 “每日商品分類銷量報表”,包含銷量金額、訂單數量、客單價(銷量金額 / 訂單數量),要求數據 100% 精準。
處理邏輯:
基于 DWS 層批處理匯總表(Hive)計算客單價;
按日期分區存儲,支持按 “月 / 季度” 匯總查詢;
數據生成后觸發郵件通知,推送報表至財務郵箱。
SQL 實現(Dinky 平臺,批模式):
-- 1. 切換為批處理模式
SET 'execution.type' = 'batch';-- 2. 讀取 DWS 層批匯總 Hive 表
CREATE TABLE dws_hive_sales_day (-- 同前序定義,此處省略
);-- 3. 創建 ADS 層財務報表 Hive 表
CREATE TABLE ads_hive_finance_sales_report (`stat_date` STRING COMMENT '統計日期(yyyy-MM-dd)',`category` STRING COMMENT '商品分類',`sales_amount` DECIMAL(12,2) COMMENT '銷量金額',`order_count` BIGINT COMMENT '訂單數量',`avg_order_price` DECIMAL(10,2) COMMENT '客單價(sales_amount/order_count)',`create_time` TIMESTAMP COMMENT '報表生成時間'
) PARTITIONED BY (`stat_date` STRING)
WITH ('connector' = 'hive','database-name' = 'ads_db','table-name' = 'ads_hive_finance_sales_report'
);-- 4. 計算并寫入財務報表數據
INSERT OVERWRITE TABLE ads_hive_finance_sales_report PARTITION (stat_date='20240520')
SELECT '20240520' AS stat_date,category,day_sales AS sales_amount,day_order_count AS order_count,ROUND(day_sales / day_order_count, 2) AS avg_order_price, -- 計算客單價CURRENT_TIMESTAMP() AS create_time
FROM dws_hive_sales_day
WHERE stat_date = '20240520'AND day_order_count > 0; -- 避免除數為0-- 5. 報表推送(通過 Dinky 集成 Shell 任務實現)
-- 執行 Shell 腳本:將 Hive 表數據導出為 Excel,并通過郵件發送給財務部門
5.3.3 數據流轉保障機制
????????為確保數據從 ODS 層到 ADS 層流轉過程中的 “準確性、完整性、時效性”,平臺設計了三大保障機制:
數據血緣追蹤:通過 Dinky 元數據管理模塊,自動記錄各層表之間的依賴關系(如?
ods_kafka_order_real_time?→?dwd_kafka_order_detail?→?dws_clickhouse_sales_real),支持按 “表 / 字段” 反向溯源,便于故障定位(如 ADS 層數據異常時,可快速定位到 DWD 層清洗邏輯問題);數據質量校驗:在各層處理節點嵌入質量校驗規則,示例如下:
分層 校驗規則 處理方式 ODS 層 訂單? amount?>0、order_id?非空過濾無效數據,記錄至錯誤日志表 DWD 層 脫敏后手機號格式為? 138****5678格式錯誤數據暫存至臨時表,人工核查 DWS 層 批流匯總差異率 ≤0.5% 差異超標觸發告警,暫停 ADS 層數據更新 ADS 層 財務報表客單價 ≤ 該分類商品均價的 3 倍 異常數據標紅,在報表中注明 “待核查” 數據備份與恢復:
- 實時數據:Kafka 主題設置 3 副本,避免數據丟失;
- 批數據:Hive 表開啟定時快照(每日凌晨 03:00),支持回滾至前一日狀態;
- 應用數據:MySQL 開啟 binlog,支持按時間點恢復(如誤操作刪除數據后,可恢復至刪除前狀態)。
5.4 數據架構價值總結
????????本平臺的批流一體數據架構,通過 “分層解耦 + 批流融合” 設計,解決了傳統數倉的核心痛點,具體價值如下:
????????數據一致性:統一批流數據模型與計算邏輯,批處理補全實時數據偏差,結果差異率控制在 0.5% 以內,滿足業務對數據精準性的需求(如財務對賬、風控決策);
????????業務適配性:實時鏈路(毫秒級 - 秒級)支撐實時大屏、庫存調整等低延遲場景,批處理鏈路(T+1)支撐財務報表、月度分析等精準性場景,一套架構覆蓋多業務需求;
????????效率提升:各層數據單向流動,避免重復加工,DWD 層清洗后的數據可復用至 DWS 層多個匯總任務,數據加工效率提升 40%;
????????可維護性:數據血緣清晰、質量校驗自動化、備份機制完善,故障排查時間從傳統架構的 2 小時縮短至 15 分鐘,降低運維成本。

之生命周期管理詳解)











上網不穩定解決辦法(無法上網)(將宿主機設置固定ip并配置dns))


)

)
