note
- 模型架構:延續 Ovis 系列創新的結構化嵌入對齊設計。
Ovis2.5 由三大組件構成:動態分辨率 ViT 高效提取視覺特征,Ovis 視覺詞表模塊實現視覺與文本嵌入的結構對齊,最后由強大的 Qwen3 作為語言基座,處理多模態嵌入并生成文本輸出。 - 訓練策略:采用更精細的五階段訓練范式,從基礎的視覺預訓練、多模態預訓練、大規模指令微調,到利用DPO和GRPO等算法進行偏好對齊和推理能力強化,循序漸進構建模型能力。同時,通過多模態數據打包和混合并行等優化,實現了3-4倍的端到端訓練加速。
- 數據工程:Ovis2.5的數據規模相比Ovis2增加了50%,重點聚焦視覺推理、圖表、OCR、Grounding等關鍵方向。尤其是合成了大量與Qwen3深度適配的“思考(thinking)”數據,有效激發了模型的反思與推理潛能。
文章目錄
- note
- 一、多模態理解Ovis2.5模型
- 1. 原生分辨率感知:看得清,看得全
- 2. 深度推理能力:引入可選的“思考模式”
- 3. SOTA性能表現:登頂開源模型榜單
- 4. 高效訓練架構:速度與規模兼得
- 二、模型架構
- 三、模型訓練
- 第一階段:VET預訓練 (視覺基礎啟蒙)
- 第二階段:多模態預訓練 (圖文對話入門)
- 第三階段:多模態指令微調 (能力全面拓展)
- 第四階段:多模態 DPO (與人類對齊)
- 第五階段:多模態強化學習 (推理能力沖刺)
- 四、模型評測
- Reference
一、多模態理解Ovis2.5模型
論文名稱:Ovis2.5 Technical Report
第一作者:阿里 - Ovis Team
論文鏈接:https://arxiv.org/pdf/2508.11737
最新日期:2025年8月15日
github:https://github.com/AIDC-AI/Ovis.git
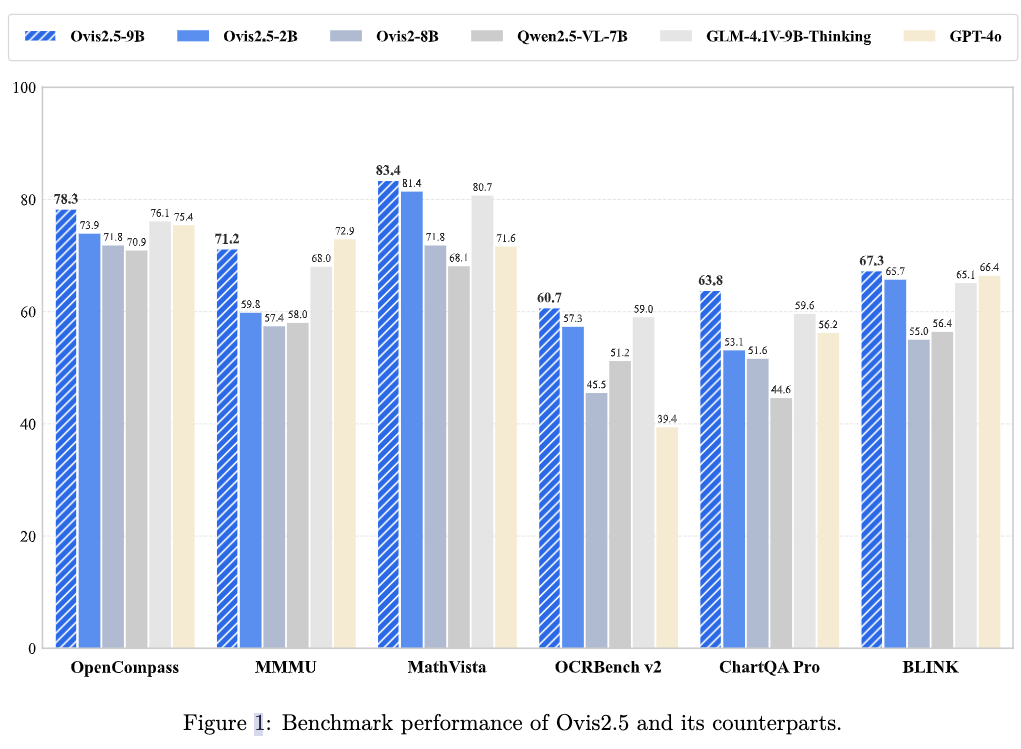
主流模型痛點:一是“視力不佳”,在處理復雜圖表或高清大圖時,往往需要把圖片切成小塊,像通過一根吸管看世界,丟失了全局信息;二是“思維線性”,習慣于一步到位的“思維鏈”(Chain-of-Thought),缺乏自我反思和糾錯的能力,遇到復雜問題容易“一條道走到黑”。
1. 原生分辨率感知:看得清,看得全
Ovis2.5最大的革新之一,就是整合了原生分辨率視覺變換器(NaViT)。這意味著它不再需要將圖片“大卸八塊”,而是可以直接處理任意原始尺寸和長寬比的圖像。這就像從一個定焦鏡頭升級到了一個能自由變焦、擁有超廣角的全能相機,無論是精細的圖表數據點還是復雜的全局頁面布局,都能一覽無余。
2. 深度推理能力:引入可選的“思考模式”
為了突破線性思維的局限,Ovis2.5在訓練中引入了一種特殊的“反思式”數據,教會模型在回答前進行自我檢查和修正。這個能力在推理時以一個可選的“思考模式”(Thinking Mode)開放給用戶。對于簡單問題,可以關閉它追求速度;對于復雜難題,可以開啟它,讓模型“多想一會兒”,以延遲換取更高的準確率。
3. SOTA性能表現:登頂開源模型榜單
Ovis2.5-9B在權威的OpenCompass多模態綜合排行榜上,以78.3分的平均成績,登頂40B參數規模以下的開源模型榜首。更令人印象深刻的是,其2B版本也取得了73.9的高分,在同量級模型中一騎絕塵,完美詮釋了“小模型,大性能”的理念。
4. 高效訓練架構:速度與規模兼得
如此強大的模型背后,是一套高效的訓練基礎設施。通過多模態數據打包和混合并行等優化技術,Ovis2.5的端到端訓練速度提升了3到4倍,為模型快速迭代和擴展提供了堅實的基礎。
二、模型架構
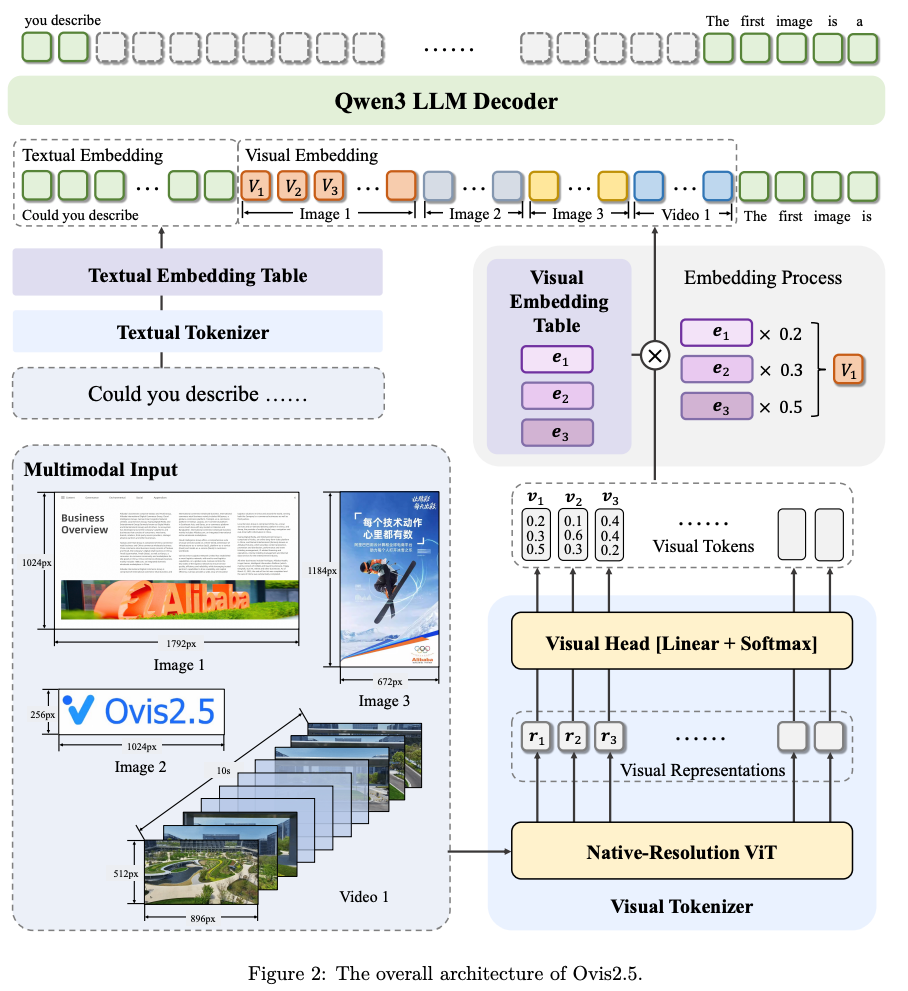
模型架構:延續 Ovis 系列創新的結構化嵌入對齊設計。
Ovis2.5 由三大組件構成:動態分辨率 ViT 高效提取視覺特征,Ovis 視覺詞表模塊實現視覺與文本嵌入的結構對齊,最后由強大的 Qwen3 作為語言基座,處理多模態嵌入并生成文本輸出。
訓練策略:采用更精細的五階段訓練范式,從基礎的視覺預訓練、多模態預訓練、大規模指令微調,到利用DPO和GRPO等算法進行偏好對齊和推理能力強化,循序漸進構建模型能力。同時,通過多模態數據打包和混合并行等優化,實現了3-4倍的端到端訓練加速。
數據工程:Ovis2.5的數據規模相比Ovis2增加了50%,重點聚焦視覺推理、圖表、OCR、Grounding等關鍵方向。尤其是合成了大量與Qwen3深度適配的“思考(thinking)”數據,有效激發了模型的反思與推理潛能。
三、模型訓練
訓練數據示例:
問題:[一個復雜的數學問題]
回答:
<think>
好的,我們來分析這個問題。首先,我需要識別出所有的已知條件...
第一步,我嘗試用公式A來計算,得到結果X。
等一下,我檢查一下這個結果。似乎公式A在這里的應用前提不滿足,這會導致錯誤。
我應該換個思路,使用公式B。
好的,用公式B重新計算第一步... 這樣就合理了。
接下來進行第二步...
</think>
[最終的、經過修正的解題步驟和答案]
第一階段:VET預訓練 (視覺基礎啟蒙)
? 目標:教會模型最基礎的“看圖識物”,即訓練好VET這個“視覺詞典”。
? 方法:使用海量“圖像-標題”數據對。為保證學習穩定,此階段會凍結視覺編碼器的大部分參數,只微調最后幾層和VET。分辨率較低,且暫時關閉。
第二階段:多模態預訓練 (圖文對話入門)
? 目標:打通視覺和語言的連接,讓模型具備基礎的對話和理解能力。
? 方法:開放所有模塊的參數進行全量訓練,并引入OCR、定位等更多樣的任務。關鍵是,大幅提升了支持的圖像分辨率,并全面啟用了,為處理復雜視覺任務打下基礎。
第三階段:多模態指令微調 (能力全面拓展)
? 目標:讓模型學會聽懂并執行各種復雜的指令,并掌握深度推理能力。
? 方法:在這一階段,訓練數據變得極其豐富,包括單圖、多圖、視頻、純文本等多種模態。最重要的是,正式引入了帶有<think>...</think>標簽的反思式推理數據,開始培養模型的“思考模式”。
第四階段:多模態 DPO (與人類對齊)
? 目標:讓模型的輸出更符合人類的偏好和價值觀。
? 方法:采用當前主流的直接偏好優化(Direct Preference Optimization, DPO)技術。通過學習人類對不同回答的偏好數據(哪個回答更好,哪個更差),對模型進行微調,使其言行舉止更像一個可靠的助手。
第五階段:多模態強化學習 (推理能力沖刺)
? 目標:在已對齊的基礎上,進一步拔高模型的邏輯推理上限。
? 方法:使用組相對策略優化(Group Relative Policy Optimization, GRPO),在大量可驗證答案的推理任務(如數學題)上進行強化學習。此階段會凍結視覺模塊,將全部優化資源集中在LLM的“大腦”上,進行最后的推理能力沖刺。
四、模型評測
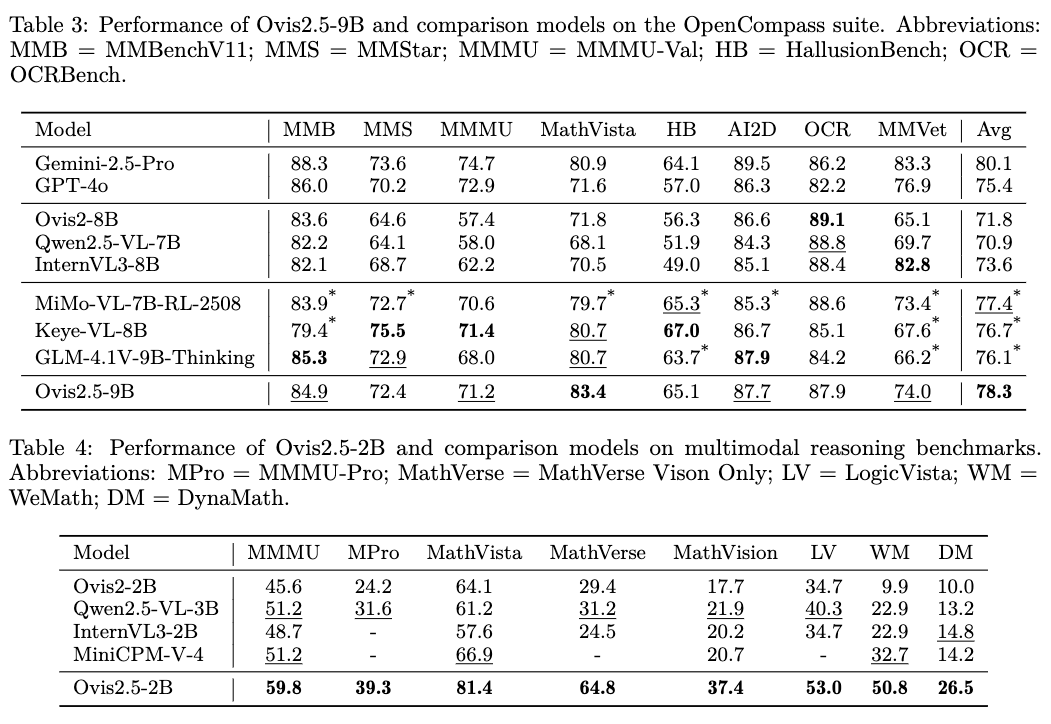
OpenCompass是一個綜合性的多模態能力評測套件,涵蓋了從常識問答、幻覺評估到專業學科推理的8個主流基準。? Ovis2.5-9B:取得了78.3分的驚人成績,不僅遠超其前代Ovis2-8B(71.8分),也超過了包括GLM-4.1V-9B-Thinking(76.1分)、Keye-VL-8B(76.7分)在內的所有同級別開源對手。
Ovis2.5-2B:以73.9分的成績,刷新了2B級別模型的SOTA記錄,甚至超過了許多體量遠大于它的模型,展現出極高的效率。
Reference
[1] 登頂開源榜首,阿里Ovis2.5深度解讀,多模態模型如何擁有原生視覺與深度思考能力?
[2] 阿里國際Ovis2.5重磅發布:以小博大,刷新開源模型性能新高度
[3] 論文名稱:Ovis2.5 Technical Report
第一作者:阿里 - Ovis Team
論文鏈接:https://arxiv.org/pdf/2508.11737
最新日期:2025年8月15日
github:https://github.com/AIDC-AI/Ovis.git

)

)










)

深度解析)

)