混合檢索(Hybrid Search)是一種結合了 稀疏向量(Sparse Vectors) 和 密集向量(Dense Vectors) 優勢的先進搜索技術。旨在同時利用稀疏向量的關鍵詞精確匹配能力和密集向量的語義理解能力,以克服單一向量檢索的局限性,從而在各種搜索場景下提供更準確、更魯棒的檢索結果。
在本節中,我們將首先分析這兩種核心向量的特性,然后探討它們如何融合,最后通過milvus實現混合檢索。
一、稀疏向量 vs 密集向量
為了更好地理解混合檢索,首先需要厘清兩種向量的本質區別。
1.1 稀疏向量
稀疏向量,也常被稱為“詞法向量”,是基于詞頻統計的傳統信息檢索方法的數學表示。它通常是一個維度極高(與詞匯表大小相當)但絕大多數元素為零的向量。它采用精準的“詞袋”匹配模型,將文檔視為一堆詞的集合,不考慮其順序和語法,其中向量的每一個維度都直接對應一個具體的詞,非零值則代表該詞在文檔中的重要性(權重)。這類向量的典型代表是 TF-IDF 和 BM25,其中,BM25 是目前最成功、應用最廣泛的稀疏向量計分算法之一,其核心公式如下:
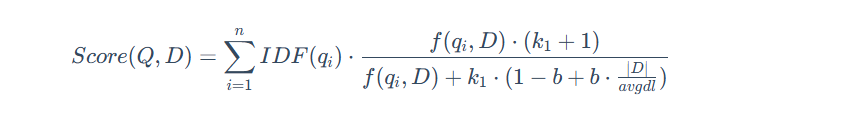

這種方法的優點是可解釋性極強(每個維度都代表一個確切的詞),無需訓練,能夠實現關鍵詞的精確匹配,對于專業術語和特定名詞的檢索效果好。然而,其主要缺點是無法理解語義,例如它無法識別“汽車”和“轎車”是同義詞,存在“詞匯鴻溝”。
1.2 密集向量
密集向量,也常被稱為“語義向量”,是通過深度學習模型學習到的數據(如文本、圖像)的低維、稠密的浮點數表示。這些向量旨在將原始數據映射到一個連續的、充滿意義的“語義空間”中來捕捉“語義”或“概念”。在理想的語義空間中,向量之間的距離和方向代表了它們所表示概念之間的關系。一個經典的例子是 vector(‘國王’) - vector(‘男人’) + vector(‘女人’) 的計算結果在向量空間中非常接近 vector(‘女王’),這表明模型學會了“性別”和“皇室”這兩個維度的抽象概念。它的典型代表包括 Word2Vec、GloVe、以及所有基于 Transformer 的模型(如 BERT、GPT)生成的嵌入(Embeddings)。
其主要優點是能夠理解同義詞、近義詞和上下文關系,泛化能力強,在語義搜索任務中表現卓越。但其缺點也同樣明顯:可解釋性差(向量中的每個維度通常沒有具體的物理意義),需要大量數據和算力進行模型訓練,且對于未登錄詞(OOV)1的處理相對困難。
1.3 實例對比
稀疏向量表示:
稀疏向量的核心思想是只存儲非零值。例如,一個8維的向量 [0, 0, 0, 5, 0, 0, 0, 9],其大部分元素都是零。用稀疏格式表示,可以極大地節約空間。常見的稀疏表示法有兩種:
字典 / 鍵值對 (Dictionary / Key-Value): 這種方式將非零元素的 索引 (0-based) 作為鍵,值 作為值。上面的向量可以表示為:

坐標列表 (Coordinate list - COO): 這種方式通常用一個元組 (維度, [索引列表], [值列表]) 來表示。上面的向量可以表示為:

這種格式在 SciPy 等科學計算庫中非常常見。
假設在一個包含5萬個詞的詞匯表中,“西紅柿”在第88位,“炒”在第666位,“蛋”在第999位,它們的BM25權重分別是1.2、0.8、1.5。那么它的稀疏表示(采用字典格式)就是:

如果采用坐標列表(COO)格式,它會是這樣:

這兩種格式都清晰地記錄了文檔的關鍵信息,但它們的局限性也很明顯:如果我們搜索“番茄炒雞蛋”,由于“番茄”和“西紅柿”是不同的詞條(索引不同),模型將無法理解它們的語義相似性。
密集向量表示:
與稀疏向量不同,密集向量的所有維度都有值,因此使用數組 [] 來表示是最直接的方式。一個預訓練好的語義模型在讀取“西紅柿炒蛋”后,會輸出一個低維的密集向量:

這個向量本身難以解讀,但它在語義空間中的位置可能與“番茄雞蛋面”、“洋蔥炒雞蛋”等菜肴的向量非常接近,因為模型理解了它們共享“雞蛋類菜肴”、“家常菜”、“酸甜口味”等核心概念。因此,當我們搜索“蛋白質豐富的家常菜”時,即使查詢中沒有出現任何原文關鍵詞,密集向量也很有可能成功匹配到這份菜譜。
二、混合檢索
通過上文可以看出稀疏向量和密集向量各有千秋,那么將它們結合起來,實現優勢互補,就成了一個不錯的選擇。混合檢索便是基于這個思路,通過結合多種搜索算法(最常見的是稀疏與密集檢索)來提升搜索結果相關性和召回率。
主要目標:解決單一檢索技術的局限性。例如,關鍵詞檢索無法理解語義,而向量檢索則可能忽略掉必須精確匹配的關鍵詞(如產品型號、函數名等)。混合檢索旨在同時利用稀疏向量的精確性和密集向量的泛化性,以應對復雜多變的搜索需求。
2.1 技術原理與融合方法
混合檢索通常并行執行兩種檢索算法,然后將兩組異構的結果集融合成一個統一的排序列表。以下是兩種主流的融合策略:
2.1.1 倒數排序融合 (Reciprocal Rank Fusion, RRF)
RRF 不關心不同檢索系統的原始得分,只關心每個文檔在各自結果集中的排名。其思想是:一個文檔在不同檢索系統中的排名越靠前,它的最終得分就越高。
其計分公式為:
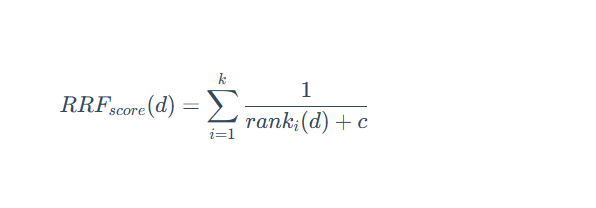

2.1.2 加權線性組合
這種方法需要先將不同檢索系統的得分進行歸一化(例如,統一到 0-1 區間),然后通過一個權重參數 α 來進行線性組合。
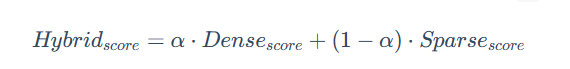
通過調整 α 的值,可以靈活地控制語義相似性與關鍵詞匹配在最終排序中的貢獻比例。例如,在電商搜索中,可以調高關鍵詞的權重;而在智能問答中,則可以側重于語義。
2.2 優勢與局限

三、代碼實踐:通過 Milvus 實現混合檢索
實踐是檢驗真理的唯一標準?。接下來使用 Milvus 來實現一個完整的混合檢索流程,從定義 Schema、插入數據,到執行查詢。
3.1 步驟一:定義 Collection
在上一章中我們實現了多模態圖文檢索,現在還是同樣的步驟先創建一個 Collection。
import json
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
import numpy as np
from pymilvus import connections, MilvusClient, FieldSchema, CollectionSchema, DataType, Collection, AnnSearchRequest, RRFRanker
from pymilvus.model.hybrid import BGEM3EmbeddingFunction# 1. 初始化設置
COLLECTION_NAME = "dragon_hybrid_demo"
MILVUS_URI = "http://localhost:19530" # 服務器模式
DATA_PATH = "../../data/C4/metadata/dragon.json" # 相對路徑
BATCH_SIZE = 50# 2. 連接 Milvus 并初始化嵌入模型
print(f"--> 正在連接到 Milvus: {MILVUS_URI}")
connections.connect(uri=MILVUS_URI)print("--> 正在初始化 BGE-M3 嵌入模型...")
ef = BGEM3EmbeddingFunction(use_fp16=False, device="cpu")
print(f"--> 嵌入模型初始化完成。密集向量維度: {ef.dim['dense']}")# 3. 創建 Collection
milvus_client = MilvusClient(uri=MILVUS_URI)
if milvus_client.has_collection(COLLECTION_NAME):print(f"--> 正在刪除已存在的 Collection '{COLLECTION_NAME}'...")milvus_client.drop_collection(COLLECTION_NAME)fields = [FieldSchema(name="pk", dtype=DataType.VARCHAR, is_primary=True, auto_id=True, max_length=100),FieldSchema(name="img_id", dtype=DataType.VARCHAR, max_length=100),FieldSchema(name="path", dtype=DataType.VARCHAR, max_length=256),FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=256),FieldSchema(name="description", dtype=DataType.VARCHAR, max_length=4096),FieldSchema(name="category", dtype=DataType.VARCHAR, max_length=64),FieldSchema(name="location", dtype=DataType.VARCHAR, max_length=128),FieldSchema(name="environment", dtype=DataType.VARCHAR, max_length=64),FieldSchema(name="sparse_vector", dtype=DataType.SPARSE_FLOAT_VECTOR),FieldSchema(name="dense_vector", dtype=DataType.FLOAT_VECTOR, dim=ef.dim["dense"])
]# 如果集合不存在,則創建它及索引
if not milvus_client.has_collection(COLLECTION_NAME):print(f"--> 正在創建 Collection '{COLLECTION_NAME}'...")schema = CollectionSchema(fields, description="關于龍的混合檢索示例")# 創建集合collection = Collection(name=COLLECTION_NAME, schema=schema, consistency_level="Strong")print("--> Collection 創建成功。")# 創建索引print("--> 正在為新集合創建索引...")sparse_index = {"index_type": "SPARSE_INVERTED_INDEX", "metric_type": "IP"}collection.create_index("sparse_vector", sparse_index)print("稀疏向量索引創建成功。")dense_index = {"index_type": "AUTOINDEX", "metric_type": "IP"}collection.create_index("dense_vector", dense_index)print("密集向量索引創建成功。")collection = Collection(COLLECTION_NAME)
collection.load()
print(f"--> Collection '{COLLECTION_NAME}' 已加載到內存。")

fields字段類型分析:
- pk: 主鍵設計,auto_id=True 讓 Milvus 自動生成唯一標識,避免主鍵沖突
- 標量字段: 7個VARCHAR字段用于存儲元數據,max_length 根據實際數據分布優化存儲
- 稀疏向量: SPARSE_FLOAT_VECTOR 類型,存儲關鍵詞權重
- 密集向量: FLOAT_VECTOR 類型,固定1024維,存儲語義特征
3.2 步驟二:BGE-M3 雙向量生成
這里使用 BGE-M3 作為向量生成器,它能夠同時生成稀疏向量和密集向量。
3.2.1 數據加載與預處理
if collection.is_empty:print(f"--> Collection 為空,開始插入數據...")with open(DATA_PATH, 'r', encoding='utf-8') as f:dataset = json.load(f)docs, metadata = [], []for item in dataset:parts = [item.get('title', ''),item.get('description', ''),item.get('location', ''),item.get('environment', ''),]docs.append(' '.join(filter(None, parts)))metadata.append(item)Collection 此時已加載到內存但為空狀態。通過 is_empty 檢查避免重復插入。多字段文本合并中每個實體對應一個完整的數據記錄。
3.2.2 向量生成
print("--> 正在生成向量嵌入...")
embeddings = ef(docs)
print("--> 向量生成完成。")# 獲取兩種向量
sparse_vectors = embeddings["sparse"] # 稀疏向量:詞頻統計
dense_vectors = embeddings["dense"] # 密集向量:語義編碼
3.2.2 向量生成
print("--> 正在生成向量嵌入...")
embeddings = ef(docs)
print("--> 向量生成完成。")# 獲取兩種向量
sparse_vectors = embeddings["sparse"] # 稀疏向量:詞頻統計
dense_vectors = embeddings["dense"] # 密集向量:語義編碼3.2.3 Collection 批量數據插入為每個字段準備批量數據
# 為每個字段準備批量數據
img_ids = [doc["img_id"] for doc in metadata]
paths = [doc["path"] for doc in metadata]
titles = [doc["title"] for doc in metadata]
descriptions = [doc["description"] for doc in metadata]
categories = [doc["category"] for doc in metadata]
locations = [doc["location"] for doc in metadata]
environments = [doc["environment"] for doc in metadata]# 插入數據
collection.insert([img_ids, paths, titles, descriptions, categories, locations, environments,sparse_vectors, dense_vectors
])
collection.flush()
字段映射: 嚴格按照 Schema 定義的字段順序插入,9個字段(7個標量+2個向量)
flush() 作用: 強制將內存緩沖區數據寫入磁盤,使數據立即可搜索
最終狀態: Collection 包含6個Entity,索引層使用稀疏向量的 SPARSE_INVERTED_INDEX 和密集向量的 AUTOINDEX
3.3 步驟三:實現混合檢索
最后使用 milvus 中封裝好的 RRF 排序算法來完成混合檢索:
3.3.1 查詢向量生成
# 6. 執行搜索
search_query = "懸崖上的巨龍"
search_filter = 'category in ["western_dragon", "chinese_dragon", "movie_character"]'
top_k = 5print(f"\n{'='*20} 開始混合搜索 {'='*20}"
print(f"查詢: '{search_query}'")
print(f"過濾器: '{search_filter}'")# 生成查詢向量
query_embeddings = ef([search_query])
dense_vec = query_embeddings["dense"][0]
sparse_vec = query_embeddings["sparse"]._getrow(0)3.3.2 混合檢索執行
使用 RRF 算法進行混合檢索,通過 milvus 封裝的 RRFRanker 實現。RRFRanker的核心參數是 k 值(默認60),用于控制 RRF 算法中的排序平滑程度。
其中 k 值越大,排序結果越平滑;越小則高排名結果的權重越突出
# 定義搜索參數
search_params = {"metric_type": "IP", "params": {}}# 先執行單獨的搜索
print("\n--- [單獨] 密集向量搜索結果 ---")
dense_results = collection.search([dense_vec],anns_field="dense_vector",param=search_params,limit=top_k,expr=search_filter,output_fields=["title", "path", "description", "category", "location", "environment"]
)[0]for i, hit in enumerate(dense_results):print(f"{i+1}. {hit.entity.get('title')} (Score: {hit.distance:.4f})")print(f" 路徑: {hit.entity.get('path')}")print(f" 描述: {hit.entity.get('description')[:100]}...")

print("\n--- [單獨] 稀疏向量搜索結果 ---")
sparse_results = collection.search([sparse_vec],anns_field="sparse_vector",param=search_params,limit=top_k,expr=search_filter,output_fields=["title", "path", "description", "category", "location", "environment"]
)[0]for i, hit in enumerate(sparse_results):print(f"{i+1}. {hit.entity.get('title')} (Score: {hit.distance:.4f})")print(f" 路徑: {hit.entity.get('path')}")print(f" 描述: {hit.entity.get('description')[:100]}...")

print("\n--- [混合] 稀疏+密集向量搜索結果 ---")
# 創建 RRF 融合器
rerank = RRFRanker(k=60)# 創建搜索請求
dense_req = AnnSearchRequest([dense_vec], "dense_vector", search_params, limit=top_k)
sparse_req = AnnSearchRequest([sparse_vec], "sparse_vector", search_params, limit=top_k)# 執行混合搜索
results = collection.hybrid_search([sparse_req, dense_req],rerank=rerank,limit=top_k,output_fields=["title", "path", "description", "category", "location", "environment"]
)[0]# 打印最終結果
for i, hit in enumerate(results):print(f"{i+1}. {hit.entity.get('title')} (Score: {hit.distance:.4f})")print(f" 路徑: {hit.entity.get('path')}")print(f" 描述: {hit.entity.get('description')[:100]}...")

)










)

深度解析)

)


